
混合交通下基于车联网的无线集群智能轨迹预测算法
2022-01-23 03:42韩银辉蒋明智
无线电工程 2022年1期
王 哲,韩银辉,蒋明智,袁 征,张 琳
(北京邮电大学 人工智能学院,北京 100876)
0 引言
自动驾驶技术能够有效提升交通安全和交通效率,近年来受到了广泛关注。然而,由于复杂的交通系统和仍不完善的地方法律法规的限制,未来很长一段时间,自动驾驶车辆和手动驾驶车辆并存的混合交通场景会在高速公路中占据主要地位[1]。为了解决自动驾驶车辆算法面对实时动态变化真实交通场景失效的问题,寻找一种有效可靠的方法预测手动驾驶车辆的轨迹变化成为如今学者们亟待解决的问题[2]。早期研究应用理论和数学公式开发了微观车辆轨迹变化模型,用于在各种复杂交通场景下预测自动驾驶车辆的轨迹[3],然而,此类模型无法在所有的车流量密度场景中取得很好的效果。Lin等人[4]使用模拟技术来估算车辆轨迹。该方法并没有在实际场景中进行测试,由于模拟环境中的车道变换频率与过程与实际交通场景情况不同,因此结果并不准确。袁娜等人[5]计算了车辆在车道变化的轨迹中引发的车身震动和周围车流量变化,使用一种改进的人工鱼群模型分析了车辆变道对交通安全的影响。然而,该研究并未充分考虑车道变化前后的微观交通参数,没有同时考虑碰撞风险和道路流量的影响。此外,许多研究只进行了目标车道上的车辆轨迹预测,而忽略了周围其他车道上车辆的影响[6]。
5G车联网和边缘计算技术的出现,车联网和传感器的快速发展为车车协同、车路协同系统提供了保障[7]。例如,龙银江等人[8]使用一种基于网络切片的联合资源分配算法实现了车联网场景下的低时延通信。车联网的发展使得学者们尝试分析并使用车车协同、车路协同系统中的关键技术优化城市中车辆通行安全和效率低下的问题[9],并且证明了多智能体集群学习能够更快速可靠地实现车联网场景下的深度学习任务。Jiang等人[10]在车联网场景中,基于边雾云架构,提出了一种多交叉口协同控制算法提升车辆通行效率。然而,现有车联网中多智能体研究并没有考虑车辆隐私数据保护,通信技术的不恰当使用极有可能造成电信诈骗等用户财产损失问题[11]。因此对于用户数据的保护也开始得到工业界和学术界的关注。学者们尝试使用联邦学习和区块链技术解决这一问题[12-13],基于联邦学习和区块链技术,Warnat等人提出了去中心化的集群智能学习框架Swarm Learning(SL)框架[14],并在医疗领域取得了卓越的效果。集群智能学习框架无需中央服务器,通过区块链网络共享参数,并在各个站点的私有数据上独立构建模型。然而,上述工作只在医疗影响场景下进行了测试,并没有在车联网中进行尝试与应用,同时,集群智能算法没有考虑车联网场景下车辆的移动性、不可靠的通信连接以及动态变化的驾驶环境。这些因素将给车联网场景下的模型训练带来一些新的挑战。本文中的混合交通下基于车联网的集群智能轨迹预测算法主要贡献点如下:
(1) 提出一种车联网场景下的集群智能轨迹预测(Swarm Learning-based Trajectory Prediction,SLTP)算法。使用去中心化的集群智能通信框架保障用户隐私数据的同时,获取周围手动驾驶车辆的历史轨迹信息并预测周围手动驾驶车辆的轨迹变化。
(2) 设计了基于Beta概率函数的权重预测策略并应用于集群学习的模型融合过程,解决车联网场景中因传输冗余数据导致的模型预测精度不高的问题。
(3) 使用美国高速公路行车数据集NGSIM (Next Generation Simulation)验证SLTP算法的有效性,与现有的基于长短时记忆(Long Short-Term Memory,LSTM)网络的轨迹预测方法相比较,验证SLTP算法的有效性。
1 集群智能轨迹预测算法
1.1 问题描述
假设在混合交通场景如图1所示,场景中存在编号个数为N的自动驾驶车辆。

图1 混合交通场景Fig.1 Mixed traffic scenario
由于车载GPS、雷达、摄像头和其他车载传感器可以获得环境周边手动驾驶车辆实时车辆轨迹数据,每辆自动驾驶车辆都可以建模为三维数组G=(V,P,E),其中:
(1)V={vi∣i∈{1,2,…}}表示所有车辆,vi表示道路上的编号为i的自动驾驶车辆。N=|V|表示道路上的所有自动驾驶车辆数目。
(2)P={pi∣vi∈V} 表示每辆自动驾驶车辆的轨迹数据,通过车载传感器获得,包括速度、加速度、方向和位置。
(3)E={ei∣vi∈V}表示环境矩阵,用于存储车辆周围的道路环境信息,即前后左右四个方向的车辆信息。道路环境矩阵中车辆vi的信息ei定义为:
(1)
式中,d(vi,vj)表示车辆vi和vj之间的欧式距离;R表示每辆车的可视范围。深度神经网络模型中的损失函数量化了算法对训练数据的建模效果是机器学习需要解决的根本问题。训练的目标是找到使损失函数最小化的最佳模型参数。机器学习中的损失函数大致可分为分类损失和回归损失。其中包括对数损失、聚焦损失、Kullback-Leibler散度、指数损失、铰链损失等,实验中使用均方误差作为车载模型的损失函数。车辆vi的损失函数fi(w)的表达式如下:
(2)

(3)
式中,Rm(i)是第i辆车的车载模型参数;Lm(k)是第k辆车的模型参数;γ是模型权重。集群学习过程中全局模型的损失函数被作为整个算法的目标函数:
(4)
1.2 基于Beta函数的模型融合权重预测策略
编号为i的自动驾驶车辆本地模型的可信值Ci,为了表示模型的有效性,使用编号为i-1的车辆节点传输模型作为参考模型计算当前车载模型的有效性预测P(ei)。车辆i根据模型有效性观测结果B计算和预测模型的有效性P(ei∣B),可推导为:
(5)
为了便于有效性值的表达和更新,使用Beta分布表示每个车载模型的有效性的概率,定义如下:
(6)
式中,p>0,q>0,p和q分别表示接收模型优于车载模型的次数和车载模型优于接收模型的次数,Γ(x)是伽马函数,其表达式为:

(7)
例如,假设ai和bi代表当前的积极和消极行为,而p和q代表初始的积极和消极行为。要更新可信度,相当于更新两个参数p和q,如下:
(8)
在没有先验知识的情况下初始化节点时,节点的可信度可以表示为(0,1)上的均匀分布,定义为:
P(x)=uni(0,1)=Beta(1,1)。
(9)
通过比较接收模型和车载模型的有效性,每辆自动驾驶车辆可以将接收到模型的有效性进行评估,即转化为有效模型次数和无效模型次数。假设在n轮通信中,每辆自动驾驶车辆进行模型训练和融合(p+q)次。通过比较模型的有效性,这些相互作用被描述为p次积极行为和q次消极行为。有了这些信息,每辆车可以在预测下一次模型融合时接收到模型的有效性。模型的有效概率定义为:
(10)
通过归一化接受模型和本地模型的权重系数,编号为i的自动驾驶车辆模型融合过程的权重定义为:
λ1∶λ2=Ce∶1。
(11)
1.3 集群学习模型融合过程
模型聚合过程中使用去中心化的集群学习框架保障用户数据安全。路侧单元作为模型聚合过程的参与者,均匀分布在道路两侧用于模型缓存。通过以下三个步骤的循环,多辆自动驾驶车辆协同通信,进行模型训练任务:
(1) 每辆自动驾驶车辆通过V2V通信以及传感器感知的方式收集周边环境中手动驾驶车辆的轨迹数据(如地理位置、速度、方向角等)并进行轨迹预测训练任务训练车载模型。
(2) 行驶过程中,彼此接近的自动驾驶车辆通过区块链技术通信,传递模型参数,预测接收模型和车载训练模型的权重系数,并进行模型聚合。
(3) 模型聚合后,头节点车辆将模型参数发送到路侧单元进行缓存处理。
一般来说,由于道路上车辆的快速流动性和驾驶目的的不确定性,不同自动驾驶车辆收集的周边手动驾驶车辆轨迹数据截然不同。通过评估并比较接收模型和车载模型的有效性,计算融合权重可以提升聚合模型效果,消除冗余用户数据造成的模型过拟合问题。算法1给出了基于集群学习的模型训练的全过程。

2 仿真验证
本节将介绍模拟设置,使用基于LSTM网络的轨迹预测方法作为基线方案[15]进行对比,对模型的预测效果,模型收敛速度进行比较。使用32 GB内存,i7-10700的CPU硬件测试平台,测试环境基于PyTorch3.9框架构建并在Ubuntu18.04系统中部署。自动驾驶车辆中的车载LSTM网络模型能够预测周围环境中手动驾驶车辆在5 s内的轨迹。完整的模型参数如表1所示。LSTM网络训练过程中时间步长设置为10。使用Adam优化器作为神经网络优化器。实验涉及的算法源码,以及相关训练和测试数据文件已经开源至GitHub平台。
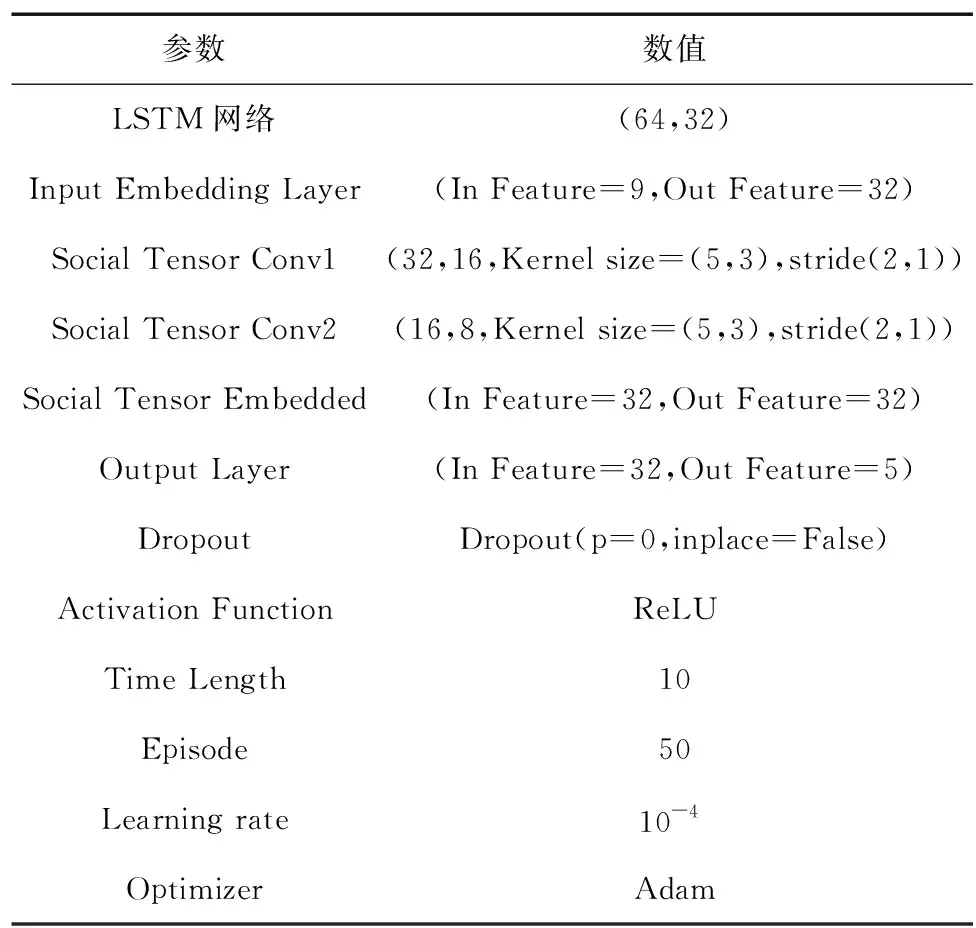
表1 算法和环境参数
2.1 实验设置
对于车联网中的集群学习,实验模拟定义了两种交通流密度:高交通流密度和低交通流密度。自动驾驶车辆数为16辆和5辆。使用NGSIM数据集验证SLTP算法的有效性。美国联邦公路管理局使用视频中目标检测的方式捕捉真实世界的交通信息制作NGSIM数据集,包括车辆速度、位置、加速度、车道等。作为高分辨率的真实世界车辆轨迹数据,NGSIM广泛用于探索轨迹预测过程的特征,并校准和验证轨迹预测模型[16]。
2.2 实验结果和分析
目前还没有集群学习框架在车联网场景中的应用,对比方案使用基于LSTM网络对车辆进行轨迹预测的方法[15],以更好地评估SLTP算法的性能,实验中的轨迹预测误差结果和模型Loss函数下降曲线如图2和图3所示。

图2 轨迹预测误差Fig.2 Trajectory Prediction Error
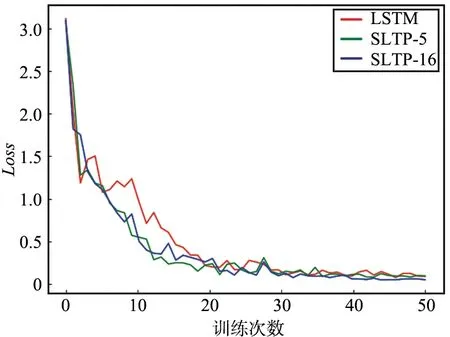
图3 模型Loss函数下降曲线Fig.3 Descending curve of Model Loss function
为了验证轨迹预测的准确性,实验设置了智能体数量为5,16的2种情况,来展示集群轨迹预测算法在不同智能体数目情况下的性能,为了进行相互比较,开展了2组对照训练实验。图2是训练过程中轨迹预测误差值情况,具体的实验数据如表2所示。从实验结果来看,随着智能体数量增加,SLTP算法可以表现出更好的性能,而LSTM网络的轨迹预测方法随着自动驾驶车辆数目的增加面对的大量冗余数据,模型收敛速度较慢,出现预测结果精度不高的情况。综上,体现了SLTP算法在轨迹预测准确性方面更具有优越性。
对于模型的收敛速度,实验同样使用上述两种交通流密度进行试验,以展示集群轨迹预测算法在不同智能体数目的情况下模型的收敛速度,图3展示的Loss值的变化情况,具体的实验数据如表2所示。从实验结果来看,随着智能体数量增加,SLTP算法可以有更快的收敛速度,这是因为通过文中提出的基于Beta概率函数的权重预测算法,对于效果不好的模型在集群模型聚合过程中给予更小的权重以抵消冗余经验数据的影响,从而实现同样计算开销情况下模型更快地收敛。综上,体现了SLTP算法在模型收敛速度上更具有优越性。

表2 综合预测性能数据
3 结束语
本文基于LSTM网络针对城市道路的混合交通场景提出了一种SLTP算法。自动驾驶车辆之间通过去中心化的集群学习保障用户数据安全。此外,为了解决车联网场景中的高移动性和数据冗余的问题,设计了模型聚合过程中的可信度权重预测算法,使得LSTM模型能够更快收敛。仿真结果表明,与基于LSTM网络对轨迹预测的方法相比,SLTP算法在同样的训练时间和通信开销内能够拥有更高的模型预测准确性和鲁棒性。未来的工作中将扩大集群学习实验规模,验证所提出算法在车联网场景中存在蓄意攻击车辆的情况下如何保护车辆隐私数据。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
纺织科学研究(2021年6期)2021-07-15
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
汽车维修技师(2019年7期)2020-01-16
军事运筹与系统工程(2019年4期)2019-09-11
汽车维修与保养(2019年3期)2019-06-19
信息化建设(2019年2期)2019-03-27
知识就是力量(2017年2期)2017-01-21
