
采用核极限学习机的短期需水量预测模型
2022-01-22 03:22韩宏泉侯本伟
哈尔滨工业大学学报 2022年2期
韩宏泉,吴 珊,侯本伟
(北京工业大学 城市建设学部,北京 100124)
短期需水量预测模型在有限的预测区间(从1个月到1天不等)内进行需水量预测,预测时间步长通常控制在每天到每小时,其在给水系统的优化调度与日常管理中发挥着重要作用[1-2]。以往的短期需水量预测模型一般面向整个城市[3-6],预测步长多以小时和天为时间步长,主要应用于城市水量的供需平衡分析。近年来,随着硬件采集技术的发展,收集步长为1~15 min的观测数据成为可能,物联网、云计算等新技术也不断融入水务行业,期望从供水系统大数据的研究中挖掘出更多工程应用价值。在此背景下,在线调度、压力分区调控、漏损控制、爆管监测等供水系统工程对短期需水量预测提出了新的速度和时间尺度需求。
很多学者对需水量预测方法进行了研究,早期传统的统计学方法因易于理解和实施得到了大量的应用,然而,由于自身的局限性很多时候并不能达到良好的预测效果[2],例如,多元线性回归算法预设了特征与需水量之间的关系;指数平滑算法对其加权系数缺乏客观的识别方法;自回归移动平均算法要求时序数列是平稳的或者经差分处理后是平稳的,且本质上只能捕捉线性关系,而真实需水量的变化是非线性的,且具有随机性。近年来,机器学习方法被更多地应用于短期需水量预测中,机器学习方法是典型的数据驱动算法,通过历史数据来深入挖掘需水量与相关变量之间的关系,从而提高预测模型的稳定性和可靠性。其中,人工神经网络算法(artificial neural network,ANN)和支持向量回归算法(support vector regression,SVR)以及它们的扩展方法在文献中介绍最多[3-5],研究中也多使用二者与新提出的机器学习模型进行性能比较,从而对新模型进行评估。
除ANN与SVR外,极限学习机算法(extreme learning machine,ELM)由于比传统机器学习方法拥有更快的训练速度,近来也被应用于预测模型中,但其实际应用效果表现出一定的差异性[6-8]。Huang等[9]在ELM的基础上提出了核极限学习机(kernel-based extreme learning machine,KELM)算法,该算法继承了ELM较高的训练速度的优点的同时,被证明相比ELM具有更加稳定的性能并且有着与SVR相似的泛化能力[10],但该方法目前尚未在短期需水量预测领域得到更多尝试。
研究人员除了不断追求单独预测模型效率的提高外,近来更多地倾向于组合模型的研究[11-12],通过对两种或多种预测模型进行组合以形成优势互补,来提高整体预测效果。其中,傅里叶级数模型(Fourier series,FS)因实现简单且需要较少的训练数据而常用于与机器学习模型进行组合[13-14]。本研究充分利用数据信息,将短期需水量的预测步长控制在15 min,引入了KELM模型以提高短期需水量预测的速度,同时,提出了以KELM模型为初始预测模块叠加使用FS模块进行残差修正的组合模型(KELM+FS),以进一步提升预测精度。
1 方法原理
本研究提出的基于核极限学习机的短期需水量预测模型KELM通过对样本数据进行训练,建立起历史时刻需水量与目标时刻需水量之间的非线性关系,进而根据历史数据实现对目标时刻需水量的预测。模型为多维输入单维输出,输入特征为与目标时刻需水量数据高度相关的历史需水量数据,输出为目标时刻的需水量预测值。KELM+FS模型中的残差修正模块FS则利用傅里叶级数对KELM的预测值与观测值之间的差值进行建模,识别出残差序列中隐含的周期性规律,从而完成对未来时刻残差的推测,其输入为T个历史残差数据,输出为整个预测区间的残差序列。
1.1 极限学习机原理
ELM是在单隐含层前馈神经网络的基础上提出的。与传统单隐含层前馈神经网络使用梯度下降法迭代求解网络参数不同,ELM在训练过程中随机生成输入权值ω和偏置b且不再调整,将最优求解问题转化为简单的最小二乘求解问题,这使得ELM具有了更快的学习和运行速度[15]。应用中ELM的训练机理可以简单描述如下[6,15-16]:
假设给定训练样本{xi,yi|xi∈RD,i=1,…,n}(其中xi表示第i个样本的D维输入向量xi=[xi1,…,xiD],yi对应着第i个样本的观测数据),隐含层神经元数为k,根据ELM网络定义可以写出如下表达式:

(1)

当ELM的输出结果能够以零误差逼近观测数据时,利用矩阵表达可以写为如下形式:
Hβ=Y
(2)
式中:H为隐含层输出矩阵,Y=[y1,…,yn]T为观测向量。
在ELM训练过程中,ω和b采取随机生成的方法确定,为计算网络的输出结果,β是唯一需要求解的参数[17]。
以最小训练误差和最小输出权的范数为求解目标,根据线性代数知识,方程(2)的最小范数最小二乘解为[18]
β=H+Y=(HTH)-1HTY
(3)
其中H+为隐含层输出矩阵H的Moore-Penrose广义逆矩阵。
1.2 核极限学习机原理
为了进一步简化ELM的应用,避免在确定隐含层神经元数时应用耗时的算法和随机分配权重的潜在缺点,Huang等[18]在ELM的基础上提出了KELM,KELM隐含层的映射不再采用g(*)这种简单的显式形式而是采用核矩阵确定,而且隐含层神经元数不再需要指定,在这种情况下KELM比ELM具有更稳定的性能,并且KELM与SVR具有相似的泛化能力[10]。KELM的机制在ELM的基础上可以描述如下[9,18-19]。
为增加模型的稳定性和泛化能力,在对β的求解中将引入一个正数C,并以最小训练误差和最小输出权的范数为求解目标[20],则有

(4)
式中:ei为训练误差,h(x)为隐含层特征映射函数。
(5)
此时β被计算为
β=HT(I/C+HHT)-1Y
(6)
对于KELM来说不必知道其映射函数的具体形式,而是构造隐式映射来代替,即构造核矩阵来代替HTH,则有
ΩELM=HHT
ΩELMi,j=h(xi)h(xj)=K(xi,xj)
(7)
最终网络输出结果可写为

(8)
式中:ΩELM为核矩阵,K(xi,xj)为核函数。在KELM中有多种核函数可供选择,比如线性核函数(linear)、多项式核函数(polynomial)、高斯径向基核函数(rbf)等[19]。图1中给出了ELM与KELM多维输入单维输出的经典结构,其中a为ELM的映射函数,b为KELM的映射函数。

图1 多维输入单维输出的ELM和KELM经典结构Fig.1 Typical structures of ELM and KELM with multidimensional input and one-dimensional output
1.3 傅里叶级数原理
傅里叶级数能够将周期信号或函数展开为一组不同频率三角函数的和,通过将周期内的历史时间序列数据拟合为傅里叶级数方程来实现对未来时刻数据的推断。假设一个周期由T个时刻组成,将此周期在[0,2π]区间内进行标准化,则有
(9)
此时傅里叶级数方程可以定义为
(10)
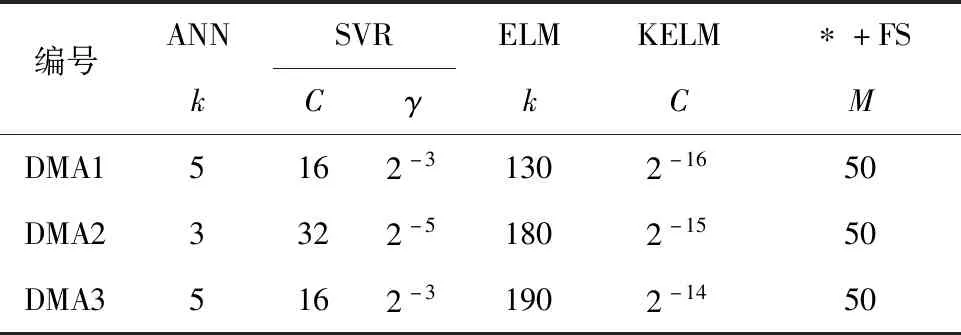
式中:tq为经过标准化的时刻;M为傅里叶多项式的级数,M 以观测值f(tq)与傅里叶级数方程估计值f*(tq)之间差值的二范数作为目标函数,傅里叶级数方程的系数可以通过最小二乘法确定[13]: (11) 本研究中,首先选定残差周期,将一个残差周期内的历史时刻进行标准化处理,然后根据式(11)的系数表达式,将周期内的残差序列值f(tq)以及标准化时刻tq依次代入式中,便可计算出相应的系数a0、ap和bp,从而实现傅里叶级数方程的拟合,继而根据残差序列所蕴含的周期性特征,可使用拟合好的傅里叶级数方程推测未来时刻的残差值。 本研究所提出的短期需水量预测模型是在预测区间为24 h,预测步长为15 min的条件下建立的。根据监测条件,观测数据每15 min进行一次采样,每24 h进行一次传输,即历史数据集每24 h进行一次更新。历史数据集的大小始终保持不变,采用移动窗口更新,即当增添最近96个时刻的观测数据的同时会删除最早的96个时刻的数据。 选择合适的输入特征对模型的建立十分重要。Guo[2]、Bakker[21]、Cutore等[22]在建立短期需水量预测模型时都仅选择历史需水量作为唯一输入特征,并且证明了在这一条件下可以实现可靠的预测。本研究同样使用历史需水量数据作为模型的唯一输入特征。 综合参考Guo[2]、Herrera[3]以及Odan等[13]的输入特征选择方案,并通过相关性分析和模型预测实验,最终选择{当前时刻,前1 d的目标时刻,前2 d的目标时刻,前1周的目标时刻}的用水需求数据作为模型的输入特征,即{Qt,Qt-95,Qt-191,Qt-671}。预测期间Qt-95,Qt-191和Qt-671使用对应的历史观测数据作为输入;在第1个目标时刻时,Qt使用对应的历史观测数据,从第2个目标时刻开始,Qt使用上一时刻的初始预测值作为下一时刻的特征输入。 1)收集并通过数据清洗对历史需水量数据进行预处理。 2)提取历史需水量数据的输入特征输入到预测模型中,通过KELM训练,建立历史需水量数据与下一时刻需水量数据之间的联系,从而实现KELM模型的建立。 KELM+FS的建立主要包括建立需水量初始预测模块和建立残差修正模块两部分。图2展示了模型建立的流程。其中需水量初始预测模块的构建步骤与KELM模型相同,不再赘述。主要建模步骤如下: 图2 KELM+FS模型建立流程Fig.2 Flow chart of KELM+FS model building 1)建立需水量初始预测模块。 2)通过建模训练的历史需水量数据、初始预测模块对训练数据拟合(预测)结果,获得初始预测模型对建模数据的的残差序列e=[e1,e2,…,eT]T。 (12) 4)计算目标时刻的最终需水量预测值: (13) 目前已有很多方法应用于需水量预测模型的性能评价,本研究采用已广为接受的指标作为模型的评价指标,其中包括用于评估预测精度的拟合优度(R2)[2,8,14]、平均绝对百分比误差(MAPE,EMAP)[2,14,23]以及用于评价计算速度的模型计算时间。具体计算公式如下: (14) (15) 采用某城市3个真实的独立计量区(DMA)历史需水量数据进行预测实验对提出的模型进行验证。这3个DMA的组成结构相似,大部分用户为居民用户,包含少量商业用户,属于典型的城市住宅区DMA。获取数据的时间范围为2019年6月1日—2019年7月30日,采样间隔为15 min。表1给出收集数据时间范围内这3个DMA的基本数据特征,其中DMA1的平均需水量最高,且相比具有更高的随机波动性;DMA2平均需水量最低;DMA3需水量数据变异系数最低。研究以2019年7月26日96个时刻的需水量数据作为测试数据,将其前55 d的数据通过特征提取后作为模型的建立数据,其中90%作为训练集,10%作为验证集。训练集与验证集用于寻找模型参数并建立模型,测试集则用于测试所建立模型的性能。 表1 3个DMA的基本需水量数据信息Tab.1 Basic water demand data for three DMAs 为了对所提出的模型进行客观评估,引入了已被广泛使用的ANN模型、SVR模型,以及KELM的同源模型——ELM模型和添加了残差修正模块的组合模型一起参与性能测试。所有模型的建立均以MATLAB 2016b为平台,所用计算机CPU型号为 Inter Core i7-10510U,内存为16.0 GB。 其中ANN模型采用单层前馈架构构建,并使用广为接受的反向传播算法进行训练,其隐含层神经元数k为该模型主要待定参数,采用logn[24](n为训练样本数)和2D+1[25](D为输入特征维数)确定隐含层神经元的上下限,并通过试错法将产生最小泛化误差的神经元数确定为最优隐含层神经元数[26]。 有关SVR的理论已有很多研究人员进行过详细叙述,具体见文献[4,27-28]。建立该模型需要确定的主要参数有核函数、不敏感系数ε、惩罚因子C、核函数宽度系数γ。研究中选择径向基函数(RBF)作为核函数。不敏感系数ε选取平台默认值0.1,C和γ的取值分别设为{21,22,…,25}和{2-5,2-4,…,2-1}[19],于建模数据中使用网格搜索和5折交叉验证在取值范围内进行二者的组合寻优。 根据1.1节ELM基础原理,ELM模型待定参数为隐含层神经元数k和激活函数类型。参考Mouatadid等[6]对于ELM模型的训练方案,选取Sig作为激活函数,将k的取值设定为{10,20,…,200},使用试错法在泛化误差最小时获取k的最佳取值。 根据1.2节KELM基础原理可知,建立该模型需要确定的参数包括核函数、惩罚因子C。经过试验选定linear作为核函数,将惩罚因子C的取值设为{2-20,2-19,…,2-10}[9],使用试错法在泛化误差最小时获取最佳参数取值。 组合模型*+FS由初始预测模块和FS残差修正模块耦合而成,初始预测模块的参数确定方法与前述单独模型的方法一致。对于FS模块,Odan和Reis[13]在建立FS模型时指出按照每7 d为一个周期对傅里叶系数进行计算且每24 h进行一次更新是足够的,本研究采用与之相同的计算和更新策略,将FS模块一周期所包含的时刻数设为T=7×96=672,此时,傅里叶级数M应该满足M 表2给出了实验中各模型的主要参数取值。 表2 各单独模型的主要参数取值Tab.2 Main parameter values of each single model 表3给出不同模型对3个DMA进行连续24 h且步长为15 min的短期需水量预测评价结果。 3.3.1 KELM模型性能分析 对于预测日,步长为15 min的观测值曲线和各单独模型预测值曲线见图3。 KELM模型能够产生与SVR、ANN模型相似的精度。根据表3统计数据可知,研究所引入的KELM模型在3个DMA的预测测试中都产生了与广为应用的ANN和SVR相近的较高精度。以指标R2为例,ANN、SVR、KELM模型在3个DMA测试中评价结果的均值分别为0.96、0.96和0.97。观察图3也可以看出,KELM、ANN、SVR的预测曲线非常接近并且与观测值曲线趋势一致,同时较好地捕捉了曲线峰谷变化。 与ELM模型相比,KELM模型的表现更加稳定。ELM模型在3个DMA短期需水量测试中表现出了较大差异,如对历史需水量数据变异系数最高的DMA1进行预测时,其评价指标R2仅为0.76,EMAP也高达12%以上,而对其他两个DMA的测试中R2均达到了0.9以上;KELM模型则始终发挥稳定,R2保持在0.95以上。从图3中还可观察到相比其他单独模型,ELM在对波峰波谷(时刻30~ 35,时刻85~ 90)的识别中也明显不够准确。此外,从表3数据可以看出,增加修正模块FS后,原本精度较低的ELM模型,得到的周期性残差补偿更为明显,这也可从侧面说明,KELM模型相比ELM模型能够更多地识别周期性现象并将其耦合到自身的预测过程中。 表3 各预测模型在测试集中的评价结果Tab.3 Performance indicators of prediction models ontest set 图3 各单独模型预测值与观测值曲线Fig.3 Curves of predicted and observed values of each single model 除了在计算精度和稳定性方面表现优良外,KELM模型的更大优势体现在其计算速度上。KELM与ELM一样,在训练过程中不再调整隐含层参数,使得模型训练所需时间明显下降,其在3个DMA的预测实验中均未超过7 s,这也预示着其在产生与ANN、SVR相似的精度时只需花费二者平均时间的5%左右。 为了测试KELM模型的泛化能力,使用KELM模型对3个DMA分别进行了连续5 d(2019年7月26日—2019年7月30日)的需水量预测实验,其中2019年7月26日、29日和30日为工作日,2019年7月27日和28日为休息日,训练模型时使用每个预测日前55 d数据提取特征后的90%作为训练集,10%作为验证集。表4给出了对应的评价结果,以R2为例,KELM模型在3个DMA中的平均精度为0.97、0.95和0.95,表现出良好的精度效果。图4给出了连续预测中步长为15 min的预测值与观测值曲线,预测值始终表现出与观测值非常一致的趋势,也较为准确地捕捉到了峰谷变化。此外,3个DMA工作日和休息日的EMAP平均值分别为4.47% 和4.55%,对于工作日与休息日的预测精度并无较大差别。可见,KELM模型在应对连续预测休息日与工作日的不同时能够表现出良好的泛化能力。 表4 KELM模型连续5 d预测的结果评价Tab.4 Performance indicators of KELM prediction model on five consecutive days 图4 KELM模型连续5 d的预测值与观测值曲线Fig.4 Curves of predicted and observed values of KELM model on five consecutive days 3.3.2 KELM+FS模型性能分析 测试结果表明,为KELM模型增加修正模块FS后,其精度得到了一定程度的提升。表3的统计数据显示,KELM+FS模型在对3个DMA的需水量预测实验中在所有模型中精度表现最佳,相比KELM模型,以EMAP指标为例,KELM+FS模型在3个DMA上的相对降幅分别为12.0%、17.2%和8.4%。事实上,增加修正模块后精度提高不仅限于KELM+FS模型,图5展示了所有单独模型及其组合模型的绝对百分比误差(APE,EAP)箱线图。可以看出,经过残差修正的模型相比对应的单独模型无论是在EAP的数值范围、平均值,还是中位数方面都有所下降,这也在一定程度上验证了研究中所应用的修正模块的确可以捕捉残差序列中蕴含的周期性特征,并将其补偿到最终预测结果中,发挥进一步降低单独模型误差的作用。 图5 各模型绝对百分比误差箱线图Fig.5 Boxplot of absolute percentage error of each model 综合来看,所提出的KELM+FS组合模型除拥有较高的预测精度外,在完成模型预测所花费的时间上同样极具优势,表现出高效预测性能。图6给出了所有模型在3个DMA中完成预测范围24 h,预测频率15 min的需水量预测的平均时间柱状图,可见作为耗时最短的KELM模型在添加修正模块后,尽管其时间消耗有所提高,但KELM+FS仍然比目前广为应用的ANN和SVR模型快了大约10倍,这一点使得该模型在需要同时对大量用户进行预测的情况下仍然具有难以忽视的实际应用潜力。 图6 各模型计算所需平均时间柱状图Fig.6 Bar chart of the average time required for each model 1)对短期需水量进行预测时,KELM模型计算精度与ANN模型、SVR模型相近(相对误差1.8%~5.5%),但KELM预测模型的建模时间为ANN、SVR模型建模时间的5%左右;相比极限学习机模型(ELM),KELM的预测性能更加稳定。 2)KELM模型具有较好的泛化能力,能够高效地实现连续日用水量预测,对工作日与休息日的用水量预测结果均达到较高的精度。 3)核极限学习机模型与傅里叶级数残差修正模块构成的组合预测模型KELM+FS,可以在不显著增加预测时间的前提下,提高KELM预测模型的精度。2 建模流程
2.1 输入特征选择
2.2 KELM模型建立步骤

2.3 KELM+FS模型建立步骤




2.4 评价指标
3 实例分析
3.1 数据描述

3.2 模型参数
3.3 结果分析






4 结 论
猜你喜欢
水土保持通报(2022年3期)2022-10-15北京航空航天大学学报(2022年8期)2022-08-31农业机械学报(2022年7期)2022-08-08科技风(2021年19期)2021-09-07少儿科技(2021年12期)2021-01-20数学学习与研究(2020年11期)2020-09-11陕西农业科学(2020年2期)2020-04-21数码世界(2019年8期)2019-08-15华东师范大学学报(自然科学版)(2019年3期)2019-06-24北京航空航天大学学报(2018年1期)2018-04-20
