
连续型变量界值点敏感度分析的SAS宏程序*
2022-01-19 08:40:06昆明医科大学公共卫生学院流行病与卫生统计学系650500肖媛媛李晓梅何利平
中国卫生统计 2021年6期
昆明医科大学公共卫生学院流行病与卫生统计学系(650500) 肖媛媛 李晓梅 何利平 孟 琼
【提 要】 目的 探讨如何用SAS宏程序实现连续型变量不同截断值对研究结果影响的敏感度分析。方法 采用自行编制的SAS宏程序,结合具体实例,演示连续型变量界值点敏感度分析的实现及结果的呈现。结果 该SAS宏程序可以按照研究者不同分析目的及设计精度进行连续型变量不同截断值的敏感度分析。结论 当前研究所提供的SAS宏程序简洁灵活,可在涉及定量变量二分类处理的医学资料分析中推广应用,对研究结果的稳健性进行更为全面的评价。
连续型变量的分类转换在医学资料的统计分析实践中十分常见,尤其是根据某特定指标的取值将研究对象进行二分类(dichotomization)。常用的分类依据有两种:一是采用公认的医学参考值(medical reference value)来界定;而大多无参考值或无固定参考值的指标,则一般通过绘制受试者工作特征(receiver operating characteristic,ROC)曲线来确定最为适宜的截断点(cut-off point)[1-2]。
敏感度分析(sensitivity analysis)是经济学领域的一种常用研究方法,概括而言,其研究特定模型自变量(输入)的变动对因变量(输出)的影响[3]。由上不难看出,不论何种方法,对于连续型变量,用某一特定截断点取值或参考值区间将其判定为截然不同的两个分类显然会有些武断,从而导致对分类后分析结果可靠性的质疑。因此,十分有必要分析当界值点在其取值附近变动时,分析结果是否稳定,即对分析结果对于界值点取值变化进行敏感度分析。
由于连续型变量在其定义域内的任意区间均存在无穷多个取值,因此可行的敏感度分析策略一定是选择某个或某些区间内、一定精度下、有限但足够多个取值,分别探讨其对因变量的影响,这样的分析意图往往涉及次数庞大的迭代(iteration),借助现有的编程式统计分析软件(如SAS和R)方可便捷实现。但文献检索发现,目前尚无相关研究报道。本文将提出一种连续型变量界值点敏感度分析的SAS宏程序,并结合实例演示其分析结果,为推广敏感度分析在医学研究中的应用提供便利,也为提升医学研究分析结果的稳健性(robustness)提供有力工具。
设计思路

SAS宏程序
根据不同研究目的,本文提供多重线性回归模型(multiple linear regression model)、logistic回归模型(logistic regression model)、Cox比例风险模型(Cox proportional hazards model)、动态生存分析的Anderson-Gill计数过程模型(Anderson-Gill counting process model,AG模型)四种模型中连续型变量界值点敏感度分析的备选宏程序模块,读者也可依据SAS编程规则自行拓展至其他一般线性模型(generalized linear model)。
具体宏程序、备选模块及注释如下:
%macrosensitivity(start=,end=,interval=,);
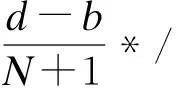
%do i=&start %to &end %by &interval;
data database2;
set database1;
if variable<=&i then group=0;
if variable>&i then group=1;
run;
/*注释:variable为拟进行敏感度分析的连续型变量,group为根据截断点产生的二分类变量,database1为初始数据库,database2为根据新的截断点调整生成的数据库*/
ods output ParameterEstimates=estimate1;/*注释:estimate1为模型拟合结果输出数据库*/
/*以下提供Cox比例风险模型和动态生存分析的AG模型两种模型中连续型变量界值点敏感度分析的宏程序备选模块,读者可根据分析需要,结合Cox比例风险模型的宏程序实现多重线性回归分析及logistic回归分析*/
/*Cox比例风险模型*/
proc phreg data=database2;
class var1 var2;
model(start end)*censor(0)=variable var1 var2 var3 var4 … varN;
run;
/*注释:variable为拟进行敏感度分析的连续型变量,var1~varN为Cox比例风险模型中的其他协变量*/
/*动态生存分析的AG模型*/
proc phreg data=database2 covs(aggregate)covm;
class var1 var2;
model(start end)*censor(0)=variable var1 var2 var3 var4 … varN;
id subject;
run;
/*注释:covs(aggregate)语句给出由Lin和Wei提出的稳健的夹心方差估计[5],model语句中,variable为拟进行敏感度分析的连续型变量,var1~varN为Cox比例风险模型中的其他协变量,id语句为夹心方差的调整依据,subject为研究对象的唯一识别编码*/
ods output close;
data estimate2;
set estimate1;
cutoff=&i;
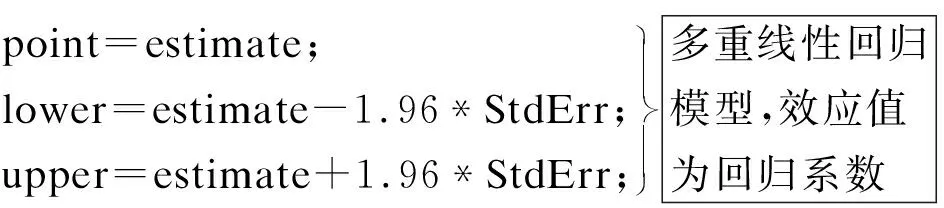

logistic回归模型,效应值为OR
Cox比例风险模型,效应值为HR
AG模型,效应值为HR
where Parameter=“variable” and StdErrRatio ne.;
keep point lower upper cutoff;
run;
/*注释:point,lower,upper分别是效应值点估计值、95%可信区间下限和上限*/
%if &i=&start %then %do;
data estimate3;
set estimate2;
%end;
%else %do;
proc append base=estimate3 data=estimate2;run;
%end;
/*注释:estimate3为最后输出的效应估计值及其95%可信区间汇总数据库*/
dm ′clear output′;
dm ′clear log′;
dm ′odsresults;clear′;
%end;
%mend;
宏程序分析结果示例

对于本例,我们设置精度为1 IU/L。则选择上述宏程序模块3,提交如下宏程序执行语句:
%simulation(start=70,end=120,interval=1);
执行后输出的效应值及其95%可信区间汇总结果estimate3内容如表1所示。
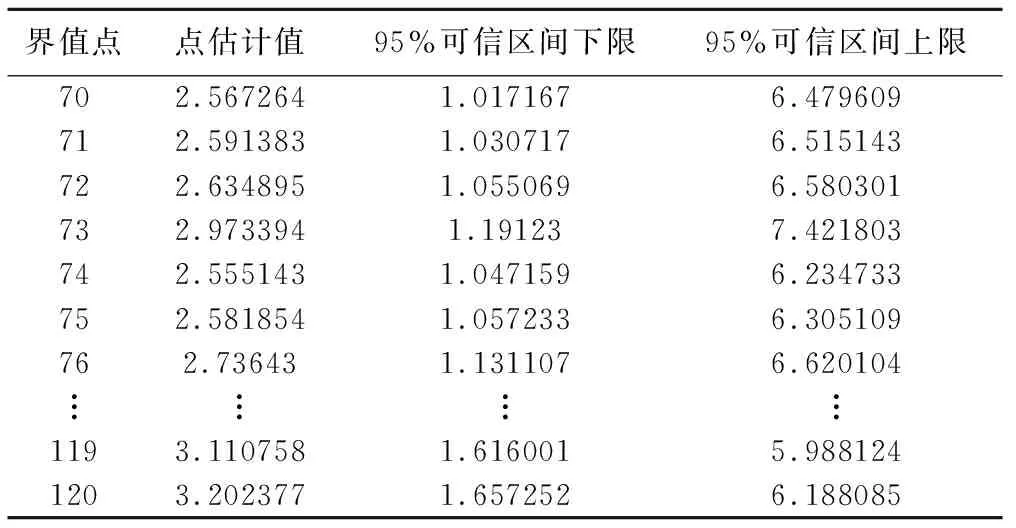
表1 汇总结果数据库内容
可以选择采用绘图软件如Sigmaplot等更好地直观展示敏感度分析结果,所绘制图形如下:
从图1不难看出:随着ALP截断点在70到120间变化,对于ALP较高的早期胰腺癌病人来说,其总体死亡风险基本上均显著高于ALP较低的病人。可以认为研究结果稳健性较好。
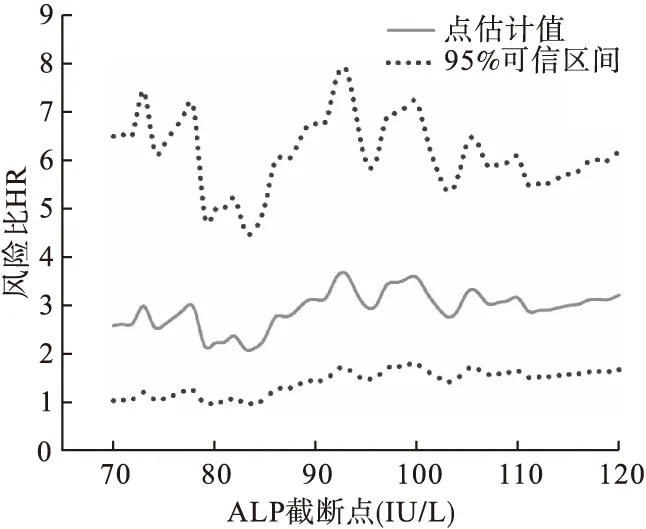
图1 不同ALP截断点敏感度分析结果
讨 论
广泛意义上的敏感度分析涵盖很多方面,除了本文研究内容所涉及的研究变量不同定义外,还包括探讨不同统计分析方法、实验流程变动、缺失值(missing data)及离群值(outliner)处理等对研究结果的影响[6]。由此不难看出,对于医学资料的统计分析而言,敏感度分析是十分必要的。但与之形成鲜明对比的是,目前在医学研究领域已发表的论文中,敏感度分析的使用比例却非常低。在一项2013年的研究中,Thabane等对64篇已发表的英文论文进行梳理,发现仅有13篇在统计分析中采用了任意形式的敏感度分析,占20.3%[7]。
针对敏感度分析在医学研究中应用不足、亟待推进的现状,本文根据医学资料统计分析实践中经常涉及对连续型变量根据某一截断值进行二分类处理的问题,提出了一种如何根据截断点的不同取值,对研究结果进行敏感度分析的SAS宏程序。该宏程序简洁、灵活,能根据研究人员的不同精度要求及分析意图执行敏感度分析,为提升医学研究统计分析结果的稳健性提供有力支持。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:07:36
智能制造(2021年4期)2021-11-04 08:54:44
中国循证儿科杂志(2021年6期)2021-03-12 09:27:38
华东师范大学学报(自然科学版)(2019年3期)2019-06-24 05:29:09
数学学习与研究(2018年20期)2018-01-07 01:31:52
汽车与安全(2016年5期)2016-12-01 05:22:03
深圳职业技术学院学报(2015年5期)2015-11-30 06:22:22
焊接(2015年9期)2015-07-18 11:03:53
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:02
机械工程师(2015年10期)2015-02-02 01:14:01
