
面向新型电力系统的电力大数据副本管理算法
2022-01-13 14:20丁斌袁博郑焕坤邢志坤王帆
电测与仪表 2022年1期
丁斌,袁博,郑焕坤,邢志坤,王帆
(1.国网河北省电力有限公司雄安新区供电公司,河北 保定 071700;2.华北电力大学,河北 保定 071000)
0 引 言
随着新型电力系统建设的不断加快,源网荷储负荷控制类业务迅速发展,用电数据信息呈指数增长[1-2],数据分析和处理在未来新型电力系统建设过程中发挥的作用越来越重要[3-4]。对于相对固定的电力基础设施[5],底层网络架构不能随意更改,因此,依托现有电力数据存储网络架构,满足未来电力业务对低时延数据处理的需求,对未来新型电力系统发展提出了更大的挑战[6-7]。针对带宽和数据中心(DC)位置分布受限的问题目前主要采用任务调度和数据副本管理两种策略进行解决[8]。但由于电力业务类型多样,应用场景多元化,数据处理差异性大,单纯采用任务调度进行数据之间的协调处理存在一定的困难,尽管通过数据副本管理能够有效感知底层数据业务类型,为应用程序提供底层支持[9],但目前大部分采用集中数据处理方式,许多电力数据应用程序由于带宽不足或延迟较长而导致效率低下[10-11]。因此,在数据并行计算框架下,基于数据中心的位置分布开发自适应存储管理是解决电力大数据处理问题的一种可行的、较好的解决方案。
在分布式数据中心,优化副本管理是除任务调度之外的另一重要解决方案,广泛应用于移动网络、节能管理、视频业务、社交网络等领域工作,虚拟机管理[12]。为了解决副本管理中的布局问题,文献[13]提出了一种基于K-List算法的调度机制,在保持低存储成本的同时优化文本访问延迟。文献[14]提出了一种基于拓扑感知的启发式算法,通过分析研究和实验来识别DCs中MapReduce的性能问题,并构建了一种最优副本数据管理方案,最小化数据访问成本。文献[15]提出了一种核奇异值分解稀疏算法,以提高电力行业智能电能表数据压缩比和分类精度,降低数据存储容量。文献[16]基于多线程和最大流量,提出了一种处理异构存储架构的最优副本选择算法,并与黑箱方式下的最大流量算法进行了比较,降低大量不必要的流计算,实现了更少的响应延迟。为了减少数据可用时间和数据访问时间,文献[17]开发了复制算法,该算法使用多个标准对副本的选择和放置进行决策。该算法考虑了多个参数,如存储容量、带宽和分布式站点的通信成本。
然而,上述这些研究大多集中在通用领域的数据优化上,针对分布式电力大数据系统的存储优化管理研究较少,无法有效地应用电力大数据存储。对此,提出了一种基于随机配置网络(Stochastic Configuration Network,SCN)的自适应副本管理系统(Prediction-based Adaptive Replica Management System,PARMS)充分考虑网络流量和数据中心(Data Center,DC)的地理分布,构建电力大数据自适应副本管理模型。同时,提出了一种基于C-means聚类的底层设备分类网络流量预测方法,有效完成数据库网络资源的实时评估。为有效提升电力大数据副本管理效率降低数据处理延时,提出了一种面向新型电力系统的数据存储和选择的副本管理算法,实现电力大数据副本的灵活存储和最优选择。最后,在相应省公司开展试点验证,该算法能够有效地处理电力大数据存储,降低数据处理延时。
1 基于随机配置网络的电力大数据自适应副本管理系统
电力大数据处理中心采用标准的分层结构,遵循严格的数据分层,各数据中心通过专用高速数据链路进行连接。数据计算和资源存储的异构性导致各数据中心之间的网络拓扑和带宽相对稳定。大功率数据处理任务对数据中心(Data Center,DC)的计算和存储容量提出更大的挑战,大量不同容量的设备不断部署到中心,导致计算或存储服务器的性能存在明显的异构性。为了在相对固定的分布式数据中心上实现电力大数据的低延迟处理,提出了一种基于随机配置网络的自适应副本管理模型,如图1所示。集群中的跟踪守护进程和线程监视系统为GaExUnit收集运行信息;GaExUnit对日志进行再处理,转发给智能分析系统进行分析。根据智能分析系统的输出,GaExUnit中的副本管理组件运行算法来优化副本的放置和选择,而优化器执行最优指令。

图1 基于随机配置网络的自适应副本管理模型Fig.1 An adaptive replica management model based on randomly configured network
2 基于C-means聚类的底层设备分类网络流量预测模型
为有效应对大量不同类型底层终端电力设备接入,对网络数据流量的冲击、降低副本管理负担,提出了一种基于C-means聚类的底层设备分类网络流量预测模型,基于网络容量对底层设备进行分类,为副本和系统管理提供底层设备流量数据指标,同时依托深度学习模型和计算任务的应用信息,采用网络流量负载预测框架为副本管理提供近期可能的网络流量[18-19]。
2.1 基于C-means聚类的底层设备分类
针对计算服务器和存储服务器的异构性能所导致的可扩展性问题,采用基于模糊C-means的聚类算法将计算服务器和存储服务器划分为不同的逻辑组。
电力大数据系统结构可以简单地描述为一个有向图G=(V,E),其中顶点集合V=CN∪SN,CN={cn1,...,cni,...,cnnc}表示计算节点,SN={sn1,...,sni,...,snnc}表示数据存储节点(也称数据节点),E表示节点之间的传输网络链路。假设系统中有n个计算节点或数据节点,每个节点具有决定节点CPU速度、IPOS性能的属性。pfi,k(1≤k≤np,k∈N)为第i个节点的第k个属性。因此,第i个节点的所有属性都可以表示为一个向量。
PFi=(λ1pfi,1,...,λkpfi,k,...,λppfi,np),PFi∈Rnp
(1)
式中λ是第j个属性的系数,它将属性值的各个范围归一化为0~1。
将n个计算节点或存储节点的所有属性叠加,得到一个矩阵:
PF=(λkpfi,k),PFi∈Rnp
(2)
PF作为聚类算法的输入。它的输出是:
(3)
式中LCT或LST的下标表示节点集群,表示节点集群处理数据的能力。
2.2 基于SCN的网络流量预测模型
近年来,一些研究人员在基于数据并行计算的大数据处理系统中,采用应用级数据访问模式进行流量预测,取得了比传统预测算法更好的性能,与其他大数据处理平台相比,DC架构、数据采集方式以及电力大数据处理任务的执行得到有效规范。对此提出了一种基于SCN的网络流量预测模型,预测未来一段时间内的网络流量,如图2所示。
该模型主要由以下三部分组成:
(1)基于操作员执行时间拟合的SCN模型;
(2)从数据并行计算应用中提取DAG信息并计算出每个阶段的流量大小;
(3)对作业执行日志的时间序列分析,以找出作业执行顺序的某些模式。
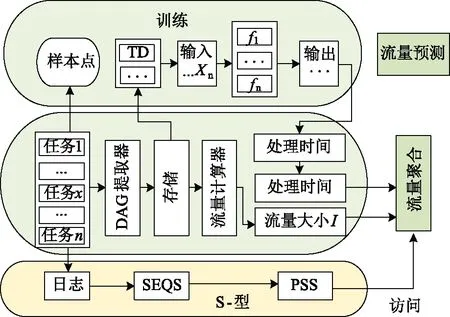
图2 网络流量预测模型Fig.2 Network traffic prediction model
定义1:任务描述符,工作节点执行的计算任务的描述符,记为:
TRC=〈IS,DT,Pri,WCID,JCID,CPU,Mem,OP〉
(4)
式中IS为整数表示的输入大小计算任务;DT为 CSG收集的数据的类型分类;Pri为调度因子,用于计算资源分配的CPU和Mem调度器;WCID为聚类算法的聚类数目;JCID为一个计算任务是处理器密集型、内存密集型还是输入输出(I/O)密集型;OP为数据的操作符号。
定义2:任务事件,操作符的描述符和需处理的数据量,记为enk。与 DCFs作为事件提供的运营商相关的事件ε={enk}的集合,k=1,…,ne。enk可以由元组{OP,IS}表示,元组由操作符OP和输入数据IS的大小组成。在任务处理过程中一次运行的任务事件的状态为RTE(EN),其中EN由任务事件组成,其持续时间表示为EN={(enk,tk)}。特别是,当任务事件完成时,tk值为零或为空。在时间t工作节点cni的状态可以表示为:
Si,t=RTE(i,(enk,tk,i),…,(ennc,tnc,i))
(5)
式中变量值在一段时间内的变化情况计算如下:
ΔSi,Δt=(Si,tΘSi,t‘),t=(RTE(i,(en1,Δti,1),…,(enne,Δti,ne)))
(6)
式中 Δt表示完成任务事件的剩余时间。
根据上述定义和公式,我们现在介绍基于SCN的拟合模型。与传统的机器学习方法或其他深度学习模型相比,SCN在实现可靠预测结果的同时,对系统引入的开销很小,系统输入和输出模型可近似表示为:
Xi,t=(t,TE,ΔSi,ΔT),Yi,t=tTE
(7)
作为我们预测框架的第二部分。除了为拟合模型提供操作日志,它还输出一个三元组(源、目标、流量大小)。基于这些信息,使用SCN模型来预测流量接入网络的时间。为了挖掘电力行业中的某些潜在的周期性,我们采用简单但高效的序列模式挖掘算法,作为网络流量预测框架的第三部分。
3 面向新型电力系统的电力大数据存储的副本管理算法
作为云存储软件系统的重要组成部分,副本管理技术在提高并发访问、数据的可靠性和可用性方面发挥着非常重要的作用。副本管理包括副本生成、副本删除、副本存储和副本选择[20],由于副本的存储方式和管理策略对于未来新型电力系统大数据存储产生的影响相对较大,对此文中着重对这两部分进行研究,并给出了对应的算法。
3.1 基于电力大数据的动态副本存储算法
在电力大数据系统中,相对固定的分布式控制系统之间的数据并行计算存在一些潜在模式或一定的周期性[21-22]。不同应用程序的数据访问频率差异性较大,导致数据块的冷热程度不同。因此,我们需要通过考虑副本因素和存储位置,针对副本存储以及如何选择副本做出最佳决策。
具有相同访问频率的数据块可能具有不同的流行度,并根据不同的计算任务而变化。每个数据块及其副本都与记录其访问流行度的时间戳队列相关联。数据块流行度可表示为:
(8)
式中heatt+1(bi)为数据块bi在时刻t+1访问流行度的更新值;衰减函数log2(eλ(Tt+1-Tt))-2表示副本的访问流行度随时间的变化,冷却系数λ、k和f与k∈(0,1)和f∈(-1,1)的系数一致;Rt为在时刻t的访问次数;Ft为从SEQS开始的一段时间内I/O事件的预测序列中可能出现的访问次数;Z为归一化因子。
通过使用最大似然估计,访问因子被分配给SEQS的历史日志中的每个数据块。访问因子和流行度之间的关系可表示为:
(9)
式中Rep(bi)为数据块bi的访问因子;heatT(bi)为bi在T时刻的访问流行度;网络数据块评估参数θ∈Θ可表示为:
(10)
基于上述研究的网络流量预测模型和数据块流行度,提出了一种动态副本存储算法,通过优化分布式控制系统之间的网络传输来提高系统吞吐量和数据传输速率,具体算法流程如图3所示。
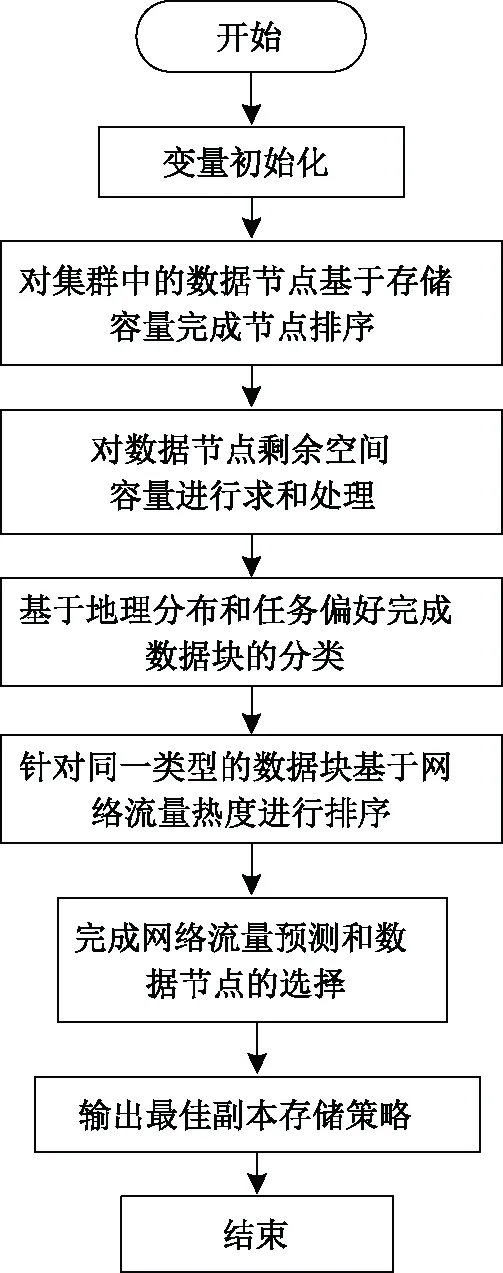
图3 基于电力大数据的动态副本存储算法Fig.3 Dynamic replica storage algorithm based on power big data
3.2 面向电力大数据云存储的副本选择算法
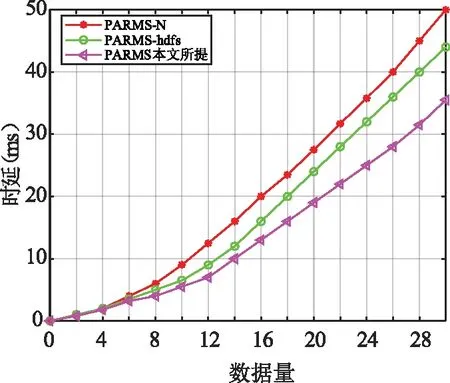
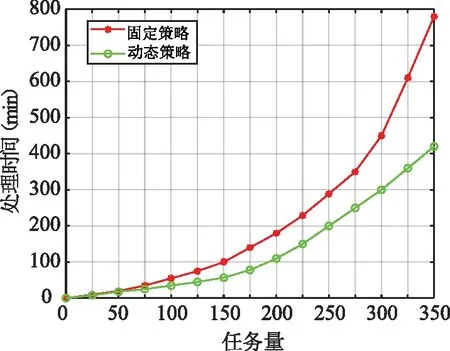
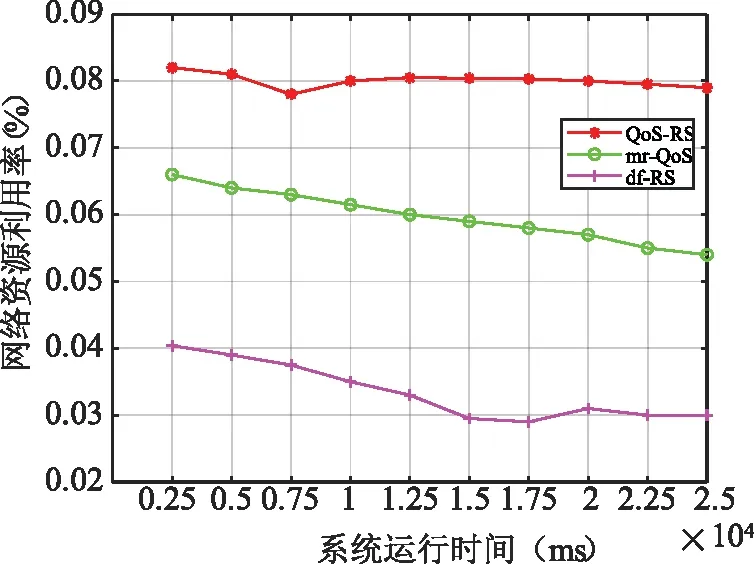
在副本存储之后,选择最佳副本满足数据处理需求的实时性,面对不同的应用场景是一个具有挑战性的问题。为了衡量副本的可维护性,我们选择了三个重要指标: 响应时间、网络流量负载和可靠性。根据给定计算任务的数据访问的服务质量(QoS)要求进行加权,即:w=(w1,w2,w3)w1+w2+w3=1(0 (1)选择矩阵:副本选择的可能性,表示为PM。假设给定计算任务的n个计算节点请求集合RC={rc1,rc2,...,rcnrs}和m个数据节点将副本保存为数据集RS={rs1,rs2,...,rsnrs}。n个计算节点的PM和m个数据块副本可表示为: PM=RCtRS=(pmi,j)nrc×nrs (11) 式中pmi,j=1表示计算节点rci通过数据节点j请求副本rsj,pmi,j=0表示不请求副本访问(1≤i≤nrc,1≤j≤nrs)。 (2)响应时间QoS1:节点间数据传输的性能主要由节点间网络传输容量决定。vi,j主要受整个NT的网络历史参数、网络NV的运行状态以及存储服务器L的IPOS影响,具体表达式如下: (12) 式中a′,β′和γ′分别为NT网络历史参数、网络NV的运行状态和存储服务器L的IPOS对应的影响因子。 因此响应时间的指标矩阵可以表示为: QoS1←(vi,j) (13) (3)网络流量负载QoS2:节点间的网络流量负载也是副本选择的一个重要因素。nli,j是网络流量负载评估指标,由当前网络流量负载 (KNL)和拟合模型fτ预测的未来网络流量负载荷(FNL)决定: (14) 式中μ(0≤μ≤1)网络流量负载系数,是通过检查历史数据设置的。因此,网络流量负载指标评估矩阵QoS2如下: QoS2=(nli,j)nrc×nrs (15) (16) 因此,可靠性的指标评估矩阵QoS3可表示为: (17) (5)目标函数的构建:不同的PMnrc×nrs值,具有的不同副本选择可能性。基于副本选择矩阵PMnrc×nrs和响应时间、网络流量负载、可靠性的指标评估矩阵QoS1、QoS2、QoS3构建对应的目标函数F1、F2、F3,具体表达形式如下: (18) 式中e是全1的向量,PM等价于PMnrc×nrs,F1(PM)、F2(PM)和F3(PM)分别为基于PMnrc×nrs的QoS1、QoS2和QoS3的值。 当PM一定时,每个目标函数达到最优时为最佳副本选择策略。同时,基于不同的应用场景可设置对应的响应时间、网络流量负载和可靠性的指标权重wi(i=1,2,3)。从而构建副本选择的总体目标函数。 F(PM)=F1(w1⊙PM)+F2(w2⊙PM)+ F3(w3⊙PM) (19) 这里有W=(wi,j)nrc×3,wj=(wi,j)nrc×1,(j=1,2,3)。因此,副本选择策略的最优解决方案是找到使目标函数F(PM)最大的最优副本选择矩阵PMoptimal,为解决上述问题,提出了一种面向电力大数据云存储的副本选择算法,具体流程如图4所示。 图4 面向电力大数据云存储的副本选择算法Fig.4 Replica selection algorithm orienting power big data cloud storage 为了验证所提的电力大数据副本管理策略的性能优势,选择某电力公司的数据平台进行仿真实验,首先基于实验环境设置仿真参数,然后,对所提出的整体电力大数据副本管理系统(PARMS)进行仿真,验证其在提高数据副本管理效率方面的优势,之后,分别对分布管理系统中所提出的动态副本存储算法和选择算法进行仿真,验证其性能优势。 基于分布式电力大数据处理系统进行算法仿真。采用通用的延迟感知任务调度策略[23-25]来跨地区的分布式控制系统调度数据并行计算任务。表1为仿真过程中地理分散的分布式控制系统节点之间的可用带宽,其中,L1为总部,L2为省分公司,L3为市分公司。 表1 分布式控制中心可用带宽Tab.1 Available bandwidth of distributed control center 仿真过程中的数据中心的处理任务主要包括实时线损计算、用户用电行为分析、用电异常监测报警等电力大数据系统中的常规任务或数据挖掘程序。实验平台用于计算任务的数据量约为550 G,来自电力大数据系统中不同地理分布的云系统,一些开放数据集也被引入PARMS系统进行测试,如表2所示。 表2 地理分布任务分配Tab.2 Geographical distribution of tasks 实验评估了通过所提出的副本管理策略减少的地理分布式控制系统上的读取延迟。图5为不同副本管理策略的数读取时间。从节点间延迟的测量数据来看,所提的动态副本处理策略(PARMS)明显优于传统固定动态分配方式(PARMS-hdfs)以及没有进行副本处理的方式(PARMS-N)。同时我们的副本管理策略实现了更好的性能,尽管读取时间仍以线性速率增长。然而,这对于数据传输是不可避免的,因为它受到网络带宽和磁盘传输速率的限制。总体而言,我们的算法在地理分布的分布式控制系统中的数据访问方面取得了明显的效果,更适用于跨区域分散的分布式控制系统进行电力大数据处理。 图5 三种副本管理策略的不同大小数据的 读取时间分析Fig.5 Reading time of different size data of three replica management strategies 利用网络流量的预测信息,PARMS可以优化副本的放置和选择,以提高效率。图6为 地理分布的分布式控制系统中任务完成时间。这表明与其他系统相比,所提出的副本管理系统更能处理电力大数据,使用PARMS进行优化后,作业完成时间减少了11.82%~12.56%。 图6 不同副本管理策略下系统内三种 任务的平均完成时间Fig.6 Average completion time of the three tasks in the system under different replica management strategies 这部分旨在通过使用副本存储策略和数据节点分类来评估分布式计算任务的执行结果。通过任务平均执行时间对仿真结果进行评估。在实验中,数据节点被分为三个逻辑存储区域,LST1、LST2和LST3(下标值越小,其关联节点的性能越好)。如图7所示,所提出的动态副本存储策略比固定副本策略执行作业的花费的平均运行时间要少。 图7 不同副本存储策略任务处理时延对比Fig.7 Comparison of task processing latency with different replica placement strategies 该实验验证了副本选择策略是否能够满足跨地理分布式 DC之间数据处理的多样性数据访问需求,分析了算法在系统运行时间内各时间段的网络资源利用的波动情况,数据库默认的副本选择策略表示为df-RS,相关基于QoS的策略表示为mr-QoS,文中提出的基于QoS的策略表示为QoS-RS。如图8所示。显然QoS-RS比df-RS和mr-QoS具有更好的网络利用率。 图8 副本选择策略的性能Fig.8 Performance of replica selection strategy 随着新型电力系统的快速发展,电力大数据的实时处理变得越来越重要。为了在有限带宽和相对固定的底层基础设施条件下实现低延迟处理,文中设计并实现了一个用于地理分布的电力大数据存储的自适应副本管理系统PARMS。设计了高效的副本管理方法来优化副本的放置和选择。在CSG的电力公司平台上进行了一系列实验。实验结果表明,所述的副本管理策略能够在一定程度上解决网络传输瓶颈,提高分布式电力大数据系统的计算吞吐量。使用PARMS时,地理分布的分布式控制系统的作业完成时间平均减少了12.19%。未来的工作将为PARMS开发自适应副本生成和删除机制,并进一步将副本管理策略与地理分布任务调度相结合。

4 仿真结果
4.1 仿真参数设置


4.2 副本管理策略性能评估

4.3 动态副本存储算法性能评估
4.4 副本选择算法性能评估
5 结束语
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
湖南电力(2022年3期)2022-07-07
舰船科学技术(2022年10期)2022-06-17
网络安全和信息化(2019年8期)2019-08-28
微型电脑应用(2019年8期)2019-08-22
计算机系统应用(2019年2期)2019-04-10
小型微型计算机系统(2018年3期)2018-03-27
北京航空航天大学学报(2017年7期)2017-11-24
制导与引信(2017年3期)2017-11-02
雷达与对抗(2015年3期)2015-12-09
