
基于深度学习的铸件缺陷检测方法*
2021-12-29 11:08:00于宏全袁明坤常建涛罗坤宇
电子机械工程 2021年6期
于宏全,袁明坤,常建涛,罗坤宇
(1. 中兴通讯股份有限公司,陕西西安 710114;2. 西安电子科技大学,陕西西安 710071)
引 言
铸造产品在工业领域应用广泛,在航空、船舶、车辆等生产制造中都具有很大的应用量[1],因此其质量问题也成为工业生产关注的重点。及时发现存在缺陷和质量不满足要求的铸造产品,不仅能节省宝贵的生产时间也可降低制造成本[2]。现今基于X射线技术的无损检测技术[3]广泛应用在铸件产品缺陷检测中,只需判断检测影像中是否存在缺陷便能够快速查找缺陷产品。但在工业领域,采用X射线技术的铸件无损检测主要采用人工检测的方式去查找产品缺陷,检测结果在很大程度上受检测人员的经验、技术能力、熟练度等多方面因素的影响,并且长时间的检测工作会造成检测人员视觉疲劳,导致检测结果存在偏差,质量检测误判率和漏判率过高,也难以提升检测效率。随着计算机视觉技术与深度学习理论的快速发展,已能够使用机器定位图像中的目标,初步实现与人工检测相同的功能,这为铸件缺陷检测提供了新的可行途径。在铸件缺陷检测中应用计算机视觉和深度学习技术[4-5],不仅可以实现铸件缺陷的快速检测,还能节省人力资源,降低由个人经验不足导致的不良影响,达到较高的检测准确率和检测速率,真正实现缺陷检测的智能化[6]。
目前,由于业务场景和研究对象不同,产品缺陷的检测方法也有所不同,但随着深度学习的发展,缺陷检测将逐渐由针对缺陷的直接图像处理转变为基于学习的缺陷检测。针对缺陷的直接图像处理是通过图像滤波、分割等方式,直接或间接在原始图像中将缺陷标记或凸显出来。文献[7]基于Butterworth滤波和虚光蒙版(Unsharp Masking, USM)锐化,使用迭代阈值分割方法实现了钛合金铸件图像缺陷的成功分割;文献[8]对图像子图中的灰度直方图进行分析,通过中位数降噪得到子图的分割阈值,并基于子图阈值实现了全局缺陷分割;文献[9]使用模糊C均值聚类实现对图像缺陷的识别;文献[10]采用聚类方式将由边缘分形特性提取出的缺陷边缘成功分割。基于学习的缺陷检测则是先通过提取图像中的关键特征,再采用机器学习或深度学习的方式建立缺陷检测模型,最后通过检测模型对图像特征的学习得到缺陷的类别或位置等预测结果。文献[11]通过提取工件表面缺陷的纹理特征和形状特征,完成对工件表面缺陷的检测;文献[12]通过提取多种铸件的缺陷特征,并使用集成学习方式完成缺陷的多类别分类;文献[13]尝试了多个不变矩特征的提取,并使用主要成分分析(Principal Component Analysis,PCA)法将多个不变矩特征降维至4个,之后通过降维特征,使用神经网络对缺陷进行了分类检测;文献[14]结合PCA与支持向量机实现了带钢表面缺陷的多类别检测;文献[15]通过分析缺陷形态关系,利用随机三角生成连续概率作为图像特征,实现了铸件缺陷不同类别的有效分类。随着深度学习的兴起,缺陷检测也逐渐向缺陷特征的自学习发展。文献[16]使用特征金字塔网络(Feature Pyramid Networks, FPN)对Faster R-CNN进行了改进并应用于汽车铝铸件缺陷检测,取得了理想的检测结果;文献[17]提出了基于Mask R-CNN的铸件缺陷检测方法,较好地实现了对铸件数字化射线成像(Digital Radiography, DR)图像缺陷的分级分类。
综上所述,当前对于缺陷检测的研究已经取得了很大的进步和良好的应用成果,但现有铸件缺陷检测技术还有很大一部分依赖人工设计缺陷特征,并使用传统方式按分类任务完成缺陷检测。这不仅会使特征具有单一性和局限性,还不利于检测方式的领域内扩展。虽然部分学者已经开始尝试以深度学习来完成缺陷检测,也取得了不错的预期结果,但也面临由工业图像获取成本高、难度大而导致的图像样本较少、数据量不足的困境。因此针对以上问题,本文提出了基于深度学习的铸件缺陷检测方法。通过数据增广增加图像数据量,基于仅浏览一次(You Only Look Once,YOLO)的理念实现多尺度特征的自动学习提取,并采用边界框抑制的测试图像检测方法进行测试图像中的缺陷检测,实现了多种铸件缺陷的自动检测。
1 方法论述
基于YOLO的铸件缺陷检测方法主要包含数据增广、检测模型构建和基于边界框抑制的测试图像缺陷检测3部分,其技术流程如图1所示。

图1 铸件缺陷检测流程
1.1 图像数据增广
铸件X射线图像的采集常使用射线计算机层析照相技术。该过程往往会耗费极大的人力和物力,想要采集到足够多的高质量铸件X射线图是相当困难的,而且使用该技术可以获得较大尺寸的检测图像,使得图像中的部分缺陷只占有极小的像素,形成微小缺陷。较少的图像数据难以保证检测模型充分学习缺陷特征,而微小缺陷在神经网络多级下采样过程中会被周围的信息所稀释,这给缺陷的准确检测增加了难度。为此本文提出了以Overlap切图数据增广和Mosaic数据增广来增加数据量和数据复杂性的方法。
1.1.1 Overlap切图数据增广
应用目标检测模型时通常将每张图像缩小到能被网络接受的尺寸后再进行训练或预测。这一过程会使图像中的信息遭受损失,尤其是对于微小缺陷,这种损失将直接影响最后的检测精度。本文受滑窗算法[18]启示,采用Overlap切图法对原始数据进行增广处理。
滑窗算法是指使用某一小尺寸窗口,按照一定的步长从图像左上角开始,从左向右从上到下依次滑动,对每一滑动过程截取的图像进行一次处理。在Overlap切图数据增广中,采用类似的原理,每次按照固定重叠率滑动窗口,并将每次窗口内的图像设定为预选图像,最终根据图像的实际缺陷标注情况,有针对性地将含有缺陷的预选图像选定为新的缺陷图像。图2为Overlap切图操作示意图。采取重叠方式沿图像横向或纵向进行最后一次切图时,窗口或许存在超出原始图像的现象,此时将滑窗后移,使滑窗与原图边缘相切,以获得一个完整的预选图像。
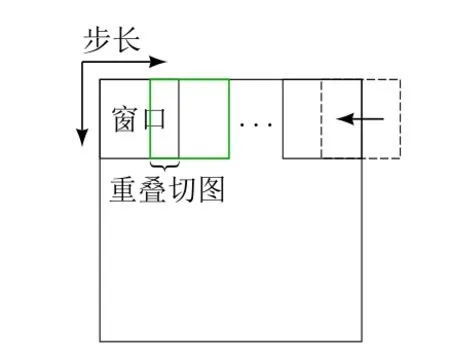
图2 Overlap切图示意图
对铸件图像切图时,会存在已有缺陷被分割的情况。采用Overlap切图方式能在一定程度上减少微小缺陷被分割的可能,但往往难以保证大型缺陷不被分割,因此有可能将同一个缺陷划分到多个子图中。由于缺陷的纹理特征不会因裁剪而受到影响,因此缺陷在子图中的裁剪部分亦可充当新的缺陷样本,起到增加缺陷样本数量的作用。对于某些缺陷,切图后被保留在子图中的缺陷大小并不固定,部分只含有极少缺陷的子图并不利于检测模型学习,所以还得通过判断缺陷留存率r来选取适合作为新缺陷数据的子图:

式中:g代表原始缺陷;s代表切分出的子图;R为面积,R(g ∩s)代表g与s相交的面积,R(g)代表原始缺陷面积。
当原始缺陷图被切图时,计算每个子图与每个原始缺陷标注边界框的r值。当r >0.1时,认定该子图存在利于模型学习的缺陷,并作为新缺陷数据。此外,为保留更多的缺陷原始信息,当原始图像的边长超过子图边长时,另将原始图像的边长缩放到子图尺寸并作为新的缺陷数据。
1.1.2 Mosaic数据增广
铸件图像数据具有稀疏分布现象,每张铸件图像仅含有一个或少量缺陷,这种数据特点不利于模型泛化能力的提升。图3展示了本文简化的Mosaic数据增广方法,用以增加图像的复杂度。简化的Mosaic数据增广方法实现了4张缺陷图像的拼接,主要包含以下4个步骤:1)将选取的4张图像按照4个象限位置排列。2)确定一个宽为w、高为h的图像模板作为最终的输出图像尺寸,同时分别在宽、高方向随机生成2条分割线,从而可将模板切分成4个分割域。以2条相交的分割线为轴,亦可分别将4个分割域对应到4个象限,同时规定分割线生成区间为[0.4w,0.6w]和[0.4h,0.6h]。设定分割线生成区间,可以保证每一个分割域不会被分割得过小。3)以远离分割线交点的顶点为重合点,对步骤1每个象限中的图像进行分割,并将步骤2分割域对应的图像区域称为被分割图像,采用式(1)来确定被分割图像中是否包含缺陷。4)按照分割线边缘对4个象限中的被分割图像进行拼接,形成一个新的宽为w、高为h的图像。

图3 简化Mosaic数据增广方法
1.2 基于YOLO的缺陷检测网络
铸件缺陷检测网络采用YOLOv3[19]结构,能够实现缺陷区域的自动检测。它主要包含由连接网络串联在一起的特征提取网络和检测头。特征提取网络主要完成图像特征的自主学习,提取图像中有用的关键信息。在YOLOv3中使用了Darknet-53作为特征提取网络,并将特征提取网络中不同尺度的特征图输入到检测头,完成不同尺度的缺陷检测。Darknet-53的结构见表1。

表1 Darknet-53网络结构
YOLOv3检测头涵盖了整个网络的检测核心思想。YOLOv3将检测图像划分成S×S个网格,并规定若目标的中心落入某一网格中,则该网格就负责这个目标的检测任务。检测头最终预测出目标边界框所在图像中的中心点坐标、宽、高和置信度。在模型预测之前,会给予模型一系列锚框(Anchor),使检测头预测出目标边界框与锚框之间的偏差值,再进一步计算出目标的预测边界框信息。
基于锚框的目标边界框计算示例如图4所示。图中虚线代表给定的锚框,按规定,其中心坐标在网格的左上角点(cx,cy),则实线代表的预测边界框可以使用含有偏差值tx,ty,tw和th的公式表示:

图4 目标边界框计算示例

式中:bx和by表示预测边界框的中心坐标;bw和bh分别代表预测边界框的宽和高;pw和ph分别为预测前边界框的宽度和高度。σ(·)为Sigmoid函数,该函数将宽、高方向上的偏差控制在(0,1)之间。
检测头能够预测与网格划分数量成比例的数据量,并通过输出相同体量的张量形式矩阵来进行表达。为此,对于YOLOv3,可通过多任务损失函数进行学习:
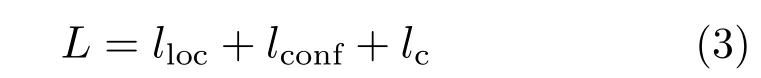
式中:lloc代表位置损失,用于目标预测边界框位置学习;lconf为置信度损失,用于目标边界框置信分数学习;lc代表类别损失,用于目标所属类别的学习。通过最小化损失函数,YOLOv3可以实现端到端的学习,完成缺陷目标的分类和定位。
1.3 基于边界框抑制的缺陷图像检测方法
对测试图像进行缺陷检测时,依旧采用重叠方式进行切图,以保证测试和训练时拥有相同的输入图像尺寸。检测模型将对切图产生的每一个子图进行检测,并得到子图的检测结果。测试图像的最终结果由所有子图的检测结果拼接而成,由于同一个缺陷可能同时存在于多张子图中,因此在最终拼接后的图像中,同一个缺陷可能具有多个标注边界框,如图5所示。图5(a)展示了子图检测结果拼接后的缺陷标注边界框,可以看到同一裂纹缺陷被分配到多张子图中,从而导致最终检测结果拼接图像中具有多个标注边界框。

图5 基于边界框抑制的测试图像缺陷检测
铸件X射线图像缺陷分布具有稀疏性,这意味着同一区域的多个同类标注边界框通常来自同一缺陷。针对上述特点,文中提出了基于边界框抑制的测试图像缺陷检测方法,剔除冗余的边界框,并将同一个缺陷的多个边界框整合为一体。基于边界框抑制的测试图像缺陷检测方法通过以下步骤实现:
1)按照预测类别将检测结果拼接图中的所有标注边界框归类,每一个类别的标注边界框构成一个列表,第i类的边界框列表记作Li。
2)从Li中第一个标注边界框开始循环遍历每一个边界框,通过计算该边界框与其他边界框的区域重叠比来确定边界框是否被抑制。边界框A和边界框B的区域重叠比分别记作rA和rB,其表达式为:

3)通过某一阈值T来判定边界框A和边界框B的留存情况。若rA和rB中有一个大于等于阈值T(本文取0.7),则保留rA和rB中较小值所对应的标注边界框;若rA和rB都小于阈值T,则两个标注边界框都保留。
4)通过步骤2得到抑制后的标注边界框列表L′i,从L′i中的第1个边界框box1开始遍历,搜寻与该边界框具有区域重叠关系的一组边界框。要求该组边界框中每一个边界框与其他至少一个边界框具有重叠区域,然后计算该组边界框的最小外接矩形边界,作为新的标注边界框代替box1,并删除该组边界框中其他所有边界框,之后开始遍历L′i中下一个边界框,重复上述操作直到将L′i中所有边界遍历完成。
5)重复步骤2和3,直到完成所有类别标注边界框的抑制或合并。
采用基于边界框抑制的测试图像缺陷检测方法,能够解决由切图方式导致的缺陷存在多个标注边界框的问题。图5展示了使用该方法对一类边界框的融合结果。
2 实验与结果分析
2.1 实验数据
通过同一个实际工业案例,对本文的方法进行验证。采用射线计算机(以X射线作为射线源)层析照相技术,获得314张轻合金铸件缺陷图像。每张图像具有3个通道,尺寸为2 176×1 792,共有气孔、夹渣、裂纹、疏松和偏析5种缺陷类型,缺陷图像如图6所示。

图6 不同铸件缺陷的X射线图像
使用LabelImage标注工具标注缺陷图像中的缺陷位置,以XML文件形式保存图像文件名、图像分辨率、存储位置、缺陷类型及区域等信息。按照8:2将所有缺陷图像划分为训练集和测试集,共得到训练图像252张,测试图像62张。
本文使用300×300的滑动窗口,以重叠率为15%的步长对训练图像进行Overlap切图数据增广,并将具有缺陷的子图边长扩大到448×448作为新的训练图像。同时为了能够保留更多的缺陷图像中的原始信息,当原图像中存在超过子图边长的缺陷时,需另行将原始图像边长缩放到448×448作为新的训练图像。在此基础上,采用几何变换(如旋转、镜像等)进一步扩充缺陷数据,最终得到2 779张尺寸为448×448的新图像。对获得的新训练图像进行Mosaic数据增广。此处使用的模板(608×608)比图像更大,可以使每个分割域含有更多的原始信息。在对全训练数据进行Mosaic数据增广时,首先将所有样本划分成每批含有n张图像的批量;然后从每一批中随机抽取4张图像进行Mosaic数据增广,直到获得同等数量的增广数据;最后使用YOLOv3对训练数据进行训练,得到铸件缺陷检测模型。
2.2 缺陷检测结果
本文使用62张测试图像对文中的方法进行了组合测试。不同检测模型组合见表2,其中,“”代表采用,“—”代表未采用。
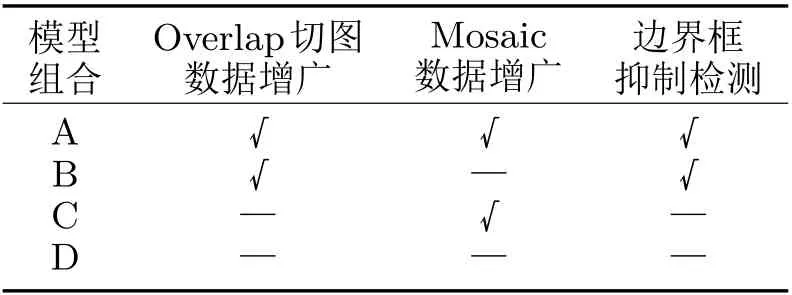
表2 不同检测模型组合
本文提出的4种组合模型都采用基于YOLOv3的检测模型结构,不同之处在于每种模型使用了不同的数据处理方法和测试图像检测方式。对以上4种组合模型进行训练后,使用测试数据集进行验证,检测结果见表3,表中σ代表平均检测准确率,σm代表平均检测准确率的平均值。
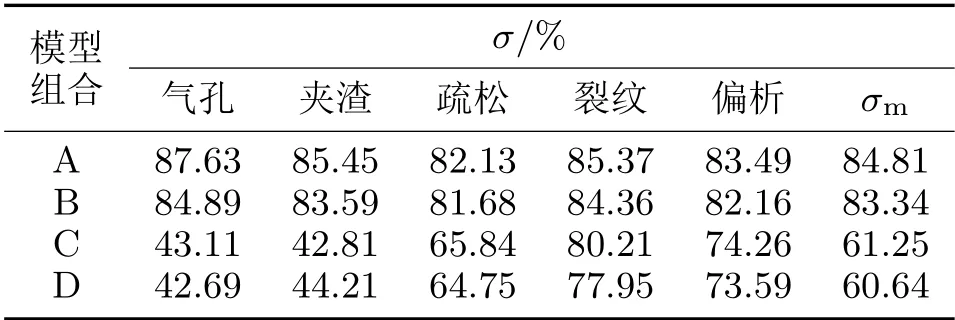
表3 不同模型组合检测结果表
经过实验,与模型C和模型D相比,模型A和模型B有更高的σm值(平均检测准确率的平均值),即使用Overlap切图数据增广和基于边界框抑制的测试图像的检测模型可以达到更好的检测性能。同时,气孔和夹渣缺陷在模型A和模型B中具有更高的检出率,而在没有使用Overlap切图数据增广的模型C和模型D中检出较少,说明此类小型缺陷在切图后更容易被检测出来。图7展示了模型A和模型C的检测结果对比。模型A准确检测出了偏析和气孔2种不同尺度的缺陷,而模型C却漏检了气孔缺陷。

图7 模型A和模型C检测结果对比
对比模型A与模型B之间以及模型C与模型D之间的检测结果,发现使用Mosaic数据增广的模型具有相对较高的σm值,模型A相比模型B提高了1.47%,模型C相比模型D提高了0.61%,也证实了Mosaic数据增广有助于缺陷检测模型性能的提升。同时,在使用本文的方法之后,检测模型(即模型A)的σm值达到了84.81%,可以获得较好的检测效果。
为了进一步证实本文的方法比传统检测方法更有效,以模型A为例,对本文的方法与结合传统滑窗算法(Sliding Window Algorithm, SWA)和卷积神经网络(Convolutional Neural Networks, CNN)分类器[20]的传统检测方法进行比较。表4展示了2种不同模型的缺陷漏检率统计结果。本文的方法在除偏析缺陷外的检测中都优于传统检测方法,能够降低7%~10%的漏检率,证明本文的方法比传统检测方法更有效。

表4 本文方法与传统检测方法漏检率统计表 %
3 结束语
本文针对铸件X射线检测图像,使用Overlap切图数据增广和Mosaic数据增广实现了训练数据集的扩充,并在此基础上实现了基于YOLOv3的铸件缺陷检测模型的训练,最后通过基于边界框抑制的测试图像检测方法完成了多种铸件缺陷的检测。该方法解决了原始缺陷数据较少带来的模型训练困难的问题,提升了对小型缺陷的检测能力。实验结果表明,本文的方法可以实现多种铸件缺陷的检测,并具有比传统检测方法更高的检测准确率和泛化能力。
猜你喜欢
铸造设备与工艺(2022年4期)2022-11-15 17:52:18
机械工业标准化与质量(2022年3期)2022-08-12 02:29:46
儿童时代·幸福宝宝(2021年11期)2021-12-21 06:18:46
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
同济大学学报(自然科学版)(2019年2期)2019-04-02 05:43:48
证券法律评论(2018年0期)2018-08-31 02:33:08
中国铸造装备与技术(2017年6期)2018-01-22 01:50:05
中国铸造装备与技术(2017年3期)2017-06-21 11:33:48
电子科技大学学报(2016年2期)2016-08-31 02:50:00
外语学刊(2014年6期)2014-04-18 09:11:49
