
基于FCN+ResNet的地表建筑物识别
2021-12-29 03:55肖建峰
现代计算机 2021年31期
肖建峰
(南华大学计算机学院软件工程系,衡阳 421001)
0 引言
深度学习(deep learning,DL)是机器学习(machine learning,ML)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(artificial intelligence,AI)[1]。近年来随着深度学习的发展,深度学习在计算机视觉上用于语义分割有不错的成就。图像分割是计算机视觉领域的一个重要方向,是图像处理的核心环节。伴随深度学习技术的发展,结合深度学习的图像分割技术在精确度上远超传统图像分割方法。卷积神经网络(CNN)与全卷积神经网络(FCN)的提出,极大促进了图像语义分割技术发展,研究人员提出了很多新型网络模型,分割精准度大幅度提升[2]。
遥感技术在空间地理信息的应用上解决了许多的问题。遥感技术广泛用于军事检测、监视海洋环境、观察天气等。在民用方面,遥感技术被用来进行地理资源检测、农作物分类、用地规划、环境污染监测、建筑识别、预测地震等方面。
本文将讲述语义分割的相关内容,阐明使用FCN和ResNet结合的网络模型来对地表的建筑物进行识别,将图像分割出来的原理。并利用航拍的地表图片进行训练,得出实验结果,进行总结。
1 语义分割
1.1 语义分割的定义
语义分割是计算机视觉中十分重要的领域,它是从像素的级别上识别图像,识别出图像中每个像素对应的物体的种类。语义分割的目的是将图像中的每个像素映射至一个目标类。语义在图像的领域来说就是指对图像内容进行理解。分割,就是将图像中物体从像素的颜色上分离。如图1中对像素进行分类识别出一只猫。
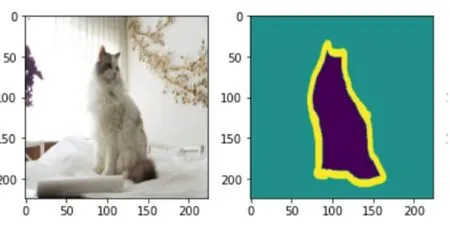
图1 语义分割简单示例
1.2 语义分割的应用
1.2.1 地理位置信息
通过构建神经网络训练数据,将航拍的图像作为输入能有效地自动识别地表的建筑、山川、河流等位置信息,来帮助地理局进行相关的工作。
1.2.2 用于无人驾驶
对于自动驾驶的汽车来说,判断道路的情况是十分重要的,对无人驾驶来说语义分割是很核心的算法,通过对道路图像的输入利用神经网络将道路上的物体分类,从而对分析的道路情况进项相应的驾驶操作,提升驾驶的安全。如图2所示。

图2 道路情况语义分割
1.2.3 医疗影像分析
图像分割是一个重要的处理步骤,它可以帮助进行以图像为指引的医学干预、放射疗法或是更有效的放射科诊断等[3]。如图3所示。

图3 医学影像龋齿诊断语义分割
1.3 计算机视觉领域对比
1.3.1 图像分类
给出打好标签的分类的图像,进行训练然后这就是图像分类问题。图像分类是判别图中物体是什么,比如是猫还是羊。
1.3.2 目标检测
区分图像中的物体并进行定位,一般对所检测的物体进行矩形框的标记,同时标注出是什么物体。如图4所示的检测则要使用边界框检测所给定图像中的所有羊。

图4 目标检测示例
1.3.3 语义分割
对图像进行像素级分类,预测每个像素属于的类别,不区分个体。如图5所示。

图5 语义分割示例
1.3.4 实例分割
定位图中每个物体,并进行像素级标注,区分不同个体。如图6所示,3只羊都被分割出不同的颜色。
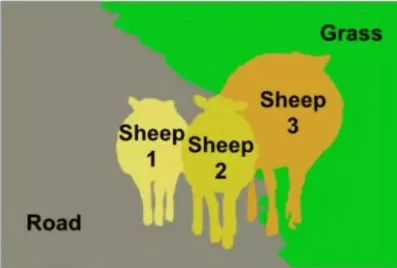
图6 实例分割示例
2 模型介绍
2.1 用于语义分割的全卷积神经网络
CNN在卷积、非线性激活和最大池化运算后,将特征图展开成若干个独立神经元,并通过全连接方式映射为固定长度的特征向量,常应用于对整幅图像分类。与CNN不同,Long等人2015年提出的FCN模型(fully convolutional networks for semantic segmentation),利用特征图同尺寸卷积运算得到若干个卷积层用来代替CNN网络中的全连接层,并采用空间插值和反卷积等上采样技术对特征图进行尺度复原,最后基于多分类模型进行逐像素预测,实现端到端语义分割[4]。FCN有三大特点:
(1)接收任意尺寸输入的全卷积网络。全卷积神经网络把卷积神经网络中的全连接层使用卷积层来代替。在传统的卷积神经网络结构中,前面是卷积层,后3层是全连接层,而FCN打破了常规,把后面的全连接改成卷积,最后输出和原图大小相同的图片。因为所有的层都是卷积层,故称为全卷积网络。为了实现图像的像素分类,最后将图片进行分割,输出应为图片,而全连接层的是将二维的输入转换为一维,不能变为二维图像。但是FCN将全连接层替换为卷积层就能达到输出为低分辨率图像的目的,同时卷积也能学习到更深的特征。网络结构如图7所示。

图7 FCN网络结构
(2)图片上采样。图片上采样利用反卷积把图像变大,最后放大成和原图大小相同的图片(图8)。上采样还能提高分辨率,能够输出良好的结果。并确保特征所在区域的权重,最后在提高图像分辨率和原始图像一致性后,高权重区域就是目标所在区域。如图9中,自行车的图片,没有经过上采样的图像热图形状模糊,识别不出是什么物体,经过不断地反卷积之后图像特征逐渐明显,自行车的部分权重高热图颜色深,很好的提升了图像分辨率保留了特征。
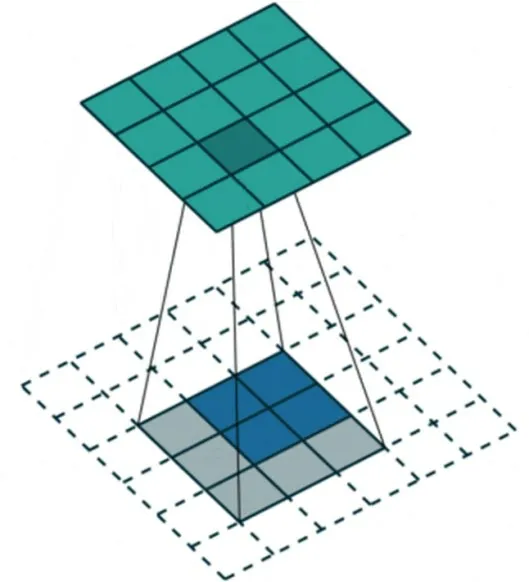
图8 反卷积填充

图9 上采样示例
(3)融合深层粗糙特征和浅层精细特征的跳跃结构。经过卷积池化后的图像特征丢失会很明显,为了加强特征的学习使得输出的图像更加精细,保留细节。FCN具有跳跃结构,如图10所示。
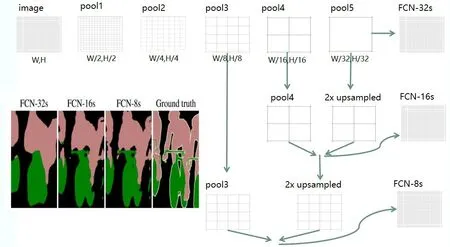
图10 FCN跳跃结构
图像经过1次卷积池化过程,长变为1/2,宽变为1/2;图像通过第2次卷积池化过程后,长变为1/4,宽变为1/4;图像通过第3次卷积池化过程后,长变为1/8,宽变为1/8,留下第3次的池化后的featuremap;通过第4次卷积池化过程后图像长变为1/16,宽变为1/16,这时留下第4次的池化后的特征图featuremap;在第5次卷积池化过程后图像长变为1/32,宽变为1/32,FCN-32s是直接经过5次卷积池化后通过后几层卷积得到的分割图像。FCN-16s是第4次保留的featuremap和第5次的卷积池化后的上采样叠加的图像,能恢复一些细节。FCN-8s是第3次保留的featuremap和第4、5次上采样的图像再次叠加的放大图像。此时一些细节的特征将保留下来。使用跳级连接结构,从卷积的前几层中提取的特征图像,分别与后一层的上采样层连接,然后再进行上采样,经过多次采样后,可以得到与原始图像大小相同的特征图像,因此在复原图像时,可以获得更多的和原图一样的图像信息。
2.2 残差网络
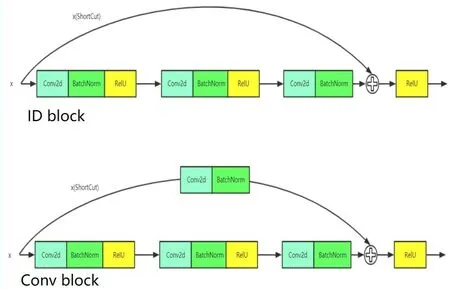
图11 残差网络残差块
残差网络是由来自Microsoft Research的4位学者提出的卷积神经网络,在2015年的ImageNet大规模视觉识别竞赛(imageNet large scale visual recognition challenge,ILSVRC)中获得了图像分类和物体识别的优胜[5]。残差网络的特点是它有特殊的跳跃结构能帮助学习更多的特征,精细化表述,同时能解决相应的网络退化梯度消失的问题。一般网络,随着层数的加深,网络会发生退化,即特征图像包含的图像信息会随层数的增加而减少,而ResNet的跳跃结构能将之前的层的特征直接映射到后层或者经过降维之后叠加到后面的层,从而可以使得模型训练时学习更多的特征,刻画细节,最后和原图一致。
2.3 FCN+Res Net 50模型
为了更好的实现对建筑物的语义分割,本文利用FCN和ResNet50网络模型进行训练,网络结构如图12所示。

图12 FCN+ResNet50模型
Conv2_x层是3个1×1,64、3×3,64、1×1,256的卷积构成,Conv3_x层是3个1×1,128、3×3,128、1×1,512的卷积构成,Conv4_x层是3个1×1,256、3×3,256、1×1,1024的卷积构成,Conv5_x层 是3个1×1,512、3×3,512、1×1,2048的卷积构成。
3 数据实验与结果分析
为了验证模型的有效性,本文使用航拍的地表建筑数据进行训练,图像分为有建筑与无建筑,训练测试后将图像分类,有建筑则进行分割图像。
3.1 数据说明
train_mask.csv:存储图片的标注的rle编码,run-length encoding,游程编码或行程是一种不会破坏图像的无损压缩的方法。
train文件夹和test文件夹:存储训练集和测试集图片,训练集图片30000张,测试集图片2500张。
3.2 处理流程
首先对图片进行预处理,读取图片,进行rle解码,然后对图片进行数据增广。数据增广是一种有效的正则化手段,可以防止模型过拟合,在深度学习模型的训练过程中被广泛地运用。数据增广的目的是增加数据集中样本的数据量,同时也可以有效增加样本的语义空间。本文利用albu⁃mentations对数据进行增广,包括对图片进行裁剪、翻转、随机裁剪等操作。划分好训练集和测试集,接着进行模型训练,设置EPOCHES=20,BATCH_SIZE=32,IMAGE_SIZE=512,使 用DiceLoss作为损失函数,每次训练时进行正向传播,计算损失,反向传播。
3.3 实验结果
在训练过程中,对训练集和验证集进行了划分,并利用绘图工具绘制了精度曲线和损失函数曲线。最终准确率为82%。损失率为0.101。如图13所示。
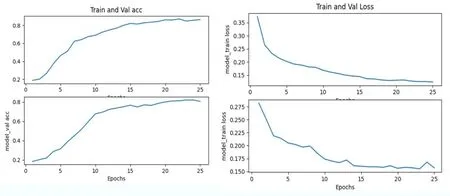
图13 准确率损失率
从图14预测结果看出,验证FCN+ResNet50网络模型用于地表的建筑物的识别是行之有效的。

图14 预测结果
4 结语
本文讲述了FCN+ResNet的网络模型进行语义分割的方法,主要是应用于航拍的地表建筑识别。介绍了FCN的三大特点,接收任意尺寸输入的全卷积网络;图片上采样;融合深层粗略特征和浅层细节特征的跳跃结构,ResNet的跳跃结构,以及FCN是如何做到语义分割的原理。同时提出将FCN+ResNet网络模型结合能更好的学习深层特征和浅层的精细特征,最后通实验进行验证,利用航拍的地表建筑图像数据集,使用FCN+REsNet50模型进行训练最终得出不错的效果。因此得出FCN_ResNet网络用于航拍的地表建筑识别是行之有效的,其也是语义分割表现不错的模型。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
红领巾·萌芽(2019年8期)2019-08-27
中国新通信(2017年9期)2017-05-27
CHIP新电脑(2016年3期)2016-03-10
长江学术(2015年1期)2015-02-27
意林(2013年16期)2013-05-14
数码影像时代(2006年5期)2006-05-29
