
基于FPGA的加速器设计方法研究
2021-12-29 03:55卢敏
现代计算机 2021年31期
卢敏
(西华大学计算机与软件工程学院,成都 610039)
0 引言
近年来,卷积神经网络(CNN)在计算机视觉及其他领域的各种任务中实现了最先进的准确性,在针对复杂场景中的目标检测、图像分类和自然语言处理等取得了巨大的成功[1]。随着智能物联网和边缘设备的飞速普及,嵌入式移动设备引起了广泛的关注。神经网络技术不断扩展到一些低计算和低功耗的移动设备上,比如自动驾驶、无人机和智能机器人等。人们对在边缘设备上实现机器学习算法的需求越来越迫切。然而,CNN的计算复杂性和内存带宽要求成为阻碍CNN在低功耗边缘设备上普遍使用的主要障碍之一。所以,运行在移动设备的算法不仅需要更高的精度,还需要具备低时延、低功耗的特点。常用的CNN结构,随着网络深度的增加,网络性能提高的同时也增大了计算量,不适用于资源受限的移动端。因此,在低功耗、计算资源和内存带宽的限制下保持高精度和吞吐量是在嵌入式平台上部署CNN模型需要解决的关键问题。
为了降低模型复杂度,使其能在资源受限的边缘设备上运行,以达到实时检测的目的,轻量化神经网络模型得到了广泛的关注[2]。实现模型轻量化一般有两种方法。第一种是对已有的模型压缩。CNN算法模型通常过度参数化并表现出明显的冗余,因此适用于减小模型大小。权重量化、剪枝、蒸馏和低秩分解是为优化CNN模型而提出的一些方法。另一种实现模型轻量化的方法是人工设计更小、更高效的CNN架构。目前研究人员总是使用更复杂的网络来提高检测的准确性。然而,复杂的网络花费了大量的资源,不适合用于移动设备和嵌入式设备。为了解决这些问题,参数较少的模型得到了越来越多的关注。近年来提出了MobileNet、GhostNet、SqueezeNet等轻量级卷积神经网络[3]。
神经网络由于其高精度而被广泛用于分类识别任务。然而,推理是一个计算密集型过程,通常需要硬件加速才能实时运行。常用的部署神经网络的平台有CPU、GPU和FPGA。CPU采用传统串行指令架构,推理过程计算复杂,执行起来效率低下。GPU提供了大规模可以并行执行的计算资源和较高的内存处理速度。然而,它们的高性能是以高功耗为代价的,不适用于在边缘设备运行。FPGA具有功耗低和可编程性的特点,目前它已经成为了不错的选择。FPGA硬件电路的并行性和流水线性,将提供实现复杂算法的能力,为算法的实时和高效实现提供了可能性。
1 轻量化网络模型
Google的MobileNet是专为小型模型移植到计算和存储资源有限但追求高精度低延时的嵌入式平台上而设计的[4]。在MobileNet架构中,普通卷积被深度可分离卷积替代。通过深度可分离卷积成功地最小化了参数大小和计算延迟。
1.1 深度可分离卷积
深度可分离卷积是MobileNet模型中提出的分解标准卷积的一种形式。在普通卷积中,每个输入通道与其特定的卷积核进行卷积,所有输入通道的卷积结果相加产生一个输出通道[5]。在深度可分离卷积中,卷积分为深度卷积(DW)和逐点卷积(PW)。深度卷积的卷积核分别和每个输入通道卷积以产生相同数量的输出通道。逐点卷积其实就是卷积核为1×1的普通卷积。深度可分离卷积的因式分解极大地降低了操作复杂度和参数的数量。
深度卷积使用单独的卷积核计算单个通道,负责从空间上提取信息。因此,卷积核具有与输入相同数量的通道,生成的输出图像保留其深度。深度卷积的过程是将卷积核与输入特征图对应的通道进行卷积,卷积核从输入图像的左上角向右和向下滑动,区域的数据和权重相乘相加[6]。
逐点卷积一般用于增加或减少图像的深度。由于深度卷积只负责单通道的卷积,缺少通道间的联系。逐点卷积使用[1×1×N]的卷积核使不同通道间的特征产生联系。
如图1所示,输入特征图的尺寸为D F∙D F∙M卷积核尺寸为D K∙D K,输出特征尺寸为D F∙D F∙N,M是输入通道数,N是输出通道数。在步长为1的情况下,普通卷积的卷积计算为D K∙D K∙M∙N∙D F∙D F深度卷积为D K∙D K∙M∙D F∙D F,逐点卷积为M∙N∙D F∙D F,所以深度可分离卷积和普通卷积之间的算力消耗比如下所示:
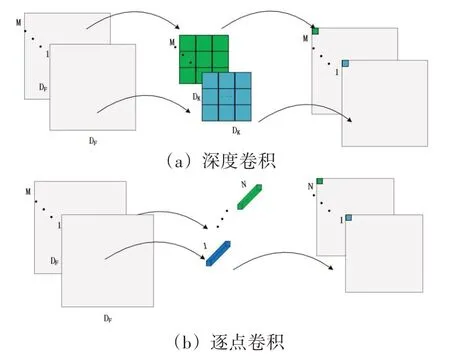
图1 深度可分离卷积
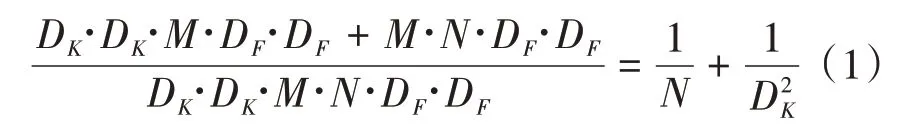
由此可以推断,使用深度可分离卷积在计算时可以大幅度地降低运算量。
1.2 倒残差和线性瓶颈结构
深度卷积无法捕获按通道方面的信息。同样,逐点卷积弱化了运算复杂度,同时也完全降低了通道深度。然而,随着特征沿着网络深度移动并嵌入到低维空间中,仍然存在信息丢失。2018年文献[7]中提出的MobileNet V2采用更先进的方式,在MobileNet的基础上,增加了一个具线性瓶颈和反向残差结构的模块。在不牺牲检测精度的情况下,进一步降低了计算量和模型大小。
MobileNet V2将卷积、归一化和激活阶段组合成倒残差瓶颈模块,如图2所示。通常,残差块开始和结束是宽层,即宽-窄-宽。但是反向残差以相反的方式实现它,即窄-宽-窄。该结构首先用逐点卷积扩展了输入特征图中的信道数,然后用深度卷积提取了特征。最后,它用逐点卷积投影简化到原始维,并在特定块中添加跳转连接,以便网络仍然可以在更深的层次上进行训练。线性瓶颈层还为了保留低维输入的信息,将最后一层的低维特征图中的ReLU激活函数换成了更适合的线性激活函数。
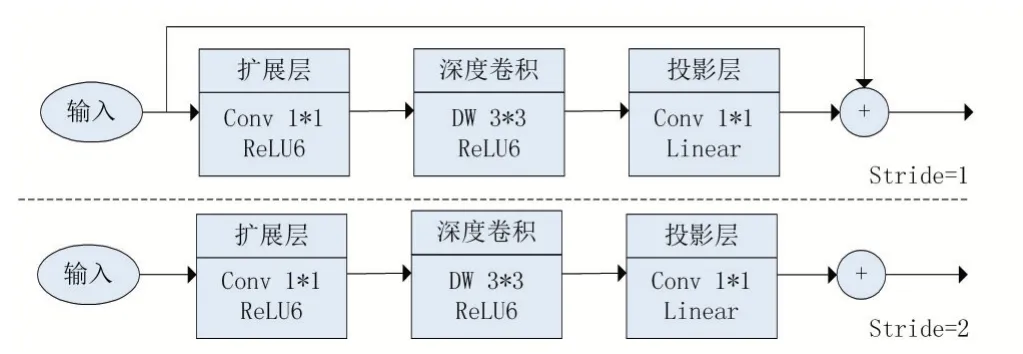
图2 倒残差瓶颈结构
1.3 网络模型
MobileNetV2的模型如表1所示,其中参数t为瓶颈层升维的倍数,参数c为特征的维数,参数n为该瓶颈层重复的次数,参数s为瓶颈层第一个卷积的步幅。它在第一层使用标准卷积组合RGB通道,使用18个瓶颈块提取特征,并使用平均池化和全连接层对特征进行分类。神经网络有340万个参数。
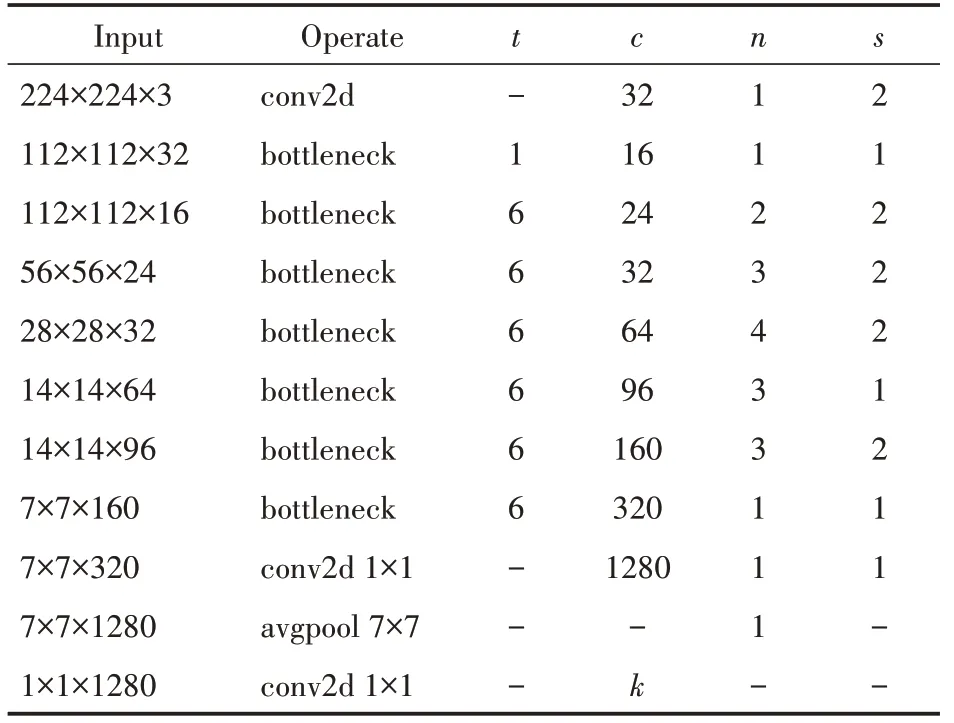
表1 MobileNet V2网络结构表
2 神经网络硬件加速
本节首先介绍了加速器的整体系统体系结构,然后确定每个网络层的最佳并行度,随后给出了设计,并进行了优化。
2.1 总体架构
MobileNet V2加速器的总体架构如图3所示。异构架构包括处理系统(PS)、集成了一个可编程处理器(ARM)用作控制器和一个存储CNN的图像和权重数据的片外存储器、可编程逻辑(PL)。ARM使用AXI协议将控制数据和权重数据的片外存储器(DDR)地址写入PL,然后通过直接内存访问(DMA)将输入特征图和卷积权重数据流导入内存(BRAM)作为数据流发送到每个处理单元。每个CNN层在硬件中由一个功能单元(PE)表示。每个PE都是专门进行特定计算的,可以简单地合成不同的CNN模型。PL使用可重构逻辑实现了计算MobileNet V2各种层的功能单元(PE)。并且这些PE可以并行执行。PE计算完成后DMA将每个输出映射作为数据流写入外部存储器。加速器迭代数据,直到完成推理。
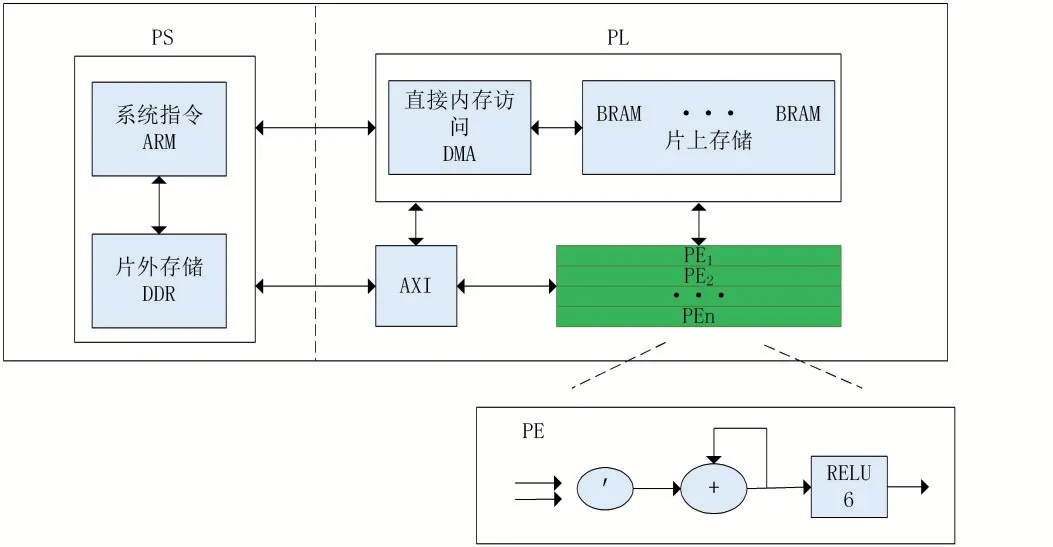
图3 加速器总体架构
2.2 并行分析
加速器试图最大限度地提升资源利用率,以最快的计算速度完成CNN的推理。性能和资源利用在不同的并行策略下有所差异。为了确定卷积层适合的并行化策略,应该考虑它们之间的数据关系以及并行性和资源约束之间的关联。卷积过程中的并行化计算大致有三种,包括多卷积层之间的并行计算、输入和输出特征图的多通道并行计算,以及卷积核中的并行计算。
2.2.1 层间并行
在多层卷积神经网络中,有些卷积操作不需要等到上一步全部完成才能开始下一层的卷积,所以能够通过建立流水线的形式去并行运算。但是,由于相邻层之间存在的数据相关性阻碍了卷积神经网络各层间计算的并行执行,卷积层级别的并行性一般比较低[8]。
2.2.2 通道并行
由于MobileNetV2是由瓶颈层构建的,因此每个深度卷积层都被一个1×1的扩展层和一个1×1的投影层包围。逐点卷积和深度卷积几乎占运算负载的100%。卷积的过程中输入特征图的不同通道之间的输入图像数据和权重数据与最终输出结果没有冲突。不同通道不存在数据依赖,可以实现并行计算。如果输入特征图中有M个通道,则实例化对应M个乘加单元。
2.2.3 卷积核并行
与逐点卷积层相比,深度卷积层的操作数其实很小。逐点卷积具有较少的算法和较少的数据移动复杂性,最适合大量并行。由于逐点卷积的密集运算,这个算子的设计可以类似于一般矩阵乘法的设计,非常适合收缩阵列。不一样的卷积核提取一样的输入图像数据,可以复用输入的特征数据,提高计算效率。通过最大程度的数据重用,逐点卷积可以利用最大的并行性。
3 实验结果分析
3.1 实验环境
该项目使用的FPGA平台是基于Xilinx Zynq-7000 SoC的ZedBoard,如图4所示。Zynq-7000包含两个子系统:处理系统(PS)和可编程逻辑(PL),具有660万个逻辑单元。PL包含CNN加速核心,运行核心驱动程序,PS主要用于初始化和配置CNN,向其提供数据并接收结果。这两个子系统在CNN中协同工作。系统相互通信是AXI接口进行实施的。两个系统还可以使用由PS控制的AXI-DMA内核访问DDR3内存。与PS的通信使用SD读卡器和UART串口完成。

图4 实验平台
由于ZynqSoC的资源很少,一般使用PC来训练模型,并将权重下载到Zynq-7000嵌入式平台进行测试。采用高级合成方法将CNN部署到Zynq板的实验过程如下:①在PC上训练网络得到权重参数。②在Vivado高级综合工具HLS中使用C或C++编程语言编写高级综合来描述检测网络,实现底层描述。进行仿真创建RTL代码,封装成CNN加速器IP核。③导入IP,在建立的加速器系统中运行,生成比特流文件。将IP核集成到整个系统体系结构中,并与嵌入式处理器实现进行比较。④下载比特流文件,在Zynq板上进行验证[9]。
3.2 实验结果
本文首先在ImageNet图像数据集上运行基于ZynqSoC框架的MobileNetV2模型,得到模型参数。结果得出MobileNetV2识别单幅图像的时间仅为17.821 s,计算复杂度是1.253 Bn,网络参数个数只有15.23 MB。可以看出MobileNetV2不仅保持了较高的识别精度,与其他网络结构比较,计算复杂度和存储资源占用更低,非常适合用来部署在资源少的边缘设备上。
Xilinx Vivado工具在Zynq SoC架构上提出的加速器硬件架构体系如图5所示。包含时钟、AXI总线控制、CNN IP核、DMA内存访问控制、DDR存储设置、Zynq处理系统模块。其中CNN模块是核心,DMA模块将读写IP核和RAM之间的像素流。Zynq7处理系统是包含嵌入式处理器的块。AXI将处理硬件架构的不同块之间的互连。

图5 系统模块设计
根据生成的IP核的综合结果可以看出,生成的IP核在DSP、BRAM、FF和LUT方面需要较低的FPGA资源,执行时间也非常快,这使得可以将其集成到任何需要卷积的系统全局架构中。实验证明,运行CNN硬件加速器处理图像的运行速度会比在嵌入式上运行快约30倍。这些结果表明,所提出的通过卷积设计进行图像和视频处理的协同设计方法需要较低的FPGA资源,满足在嵌入式设备中运行的需求。
4 结语
为了将神经网络技术应用于嵌入式平台,针对嵌入式平台资源少、计算能力低的特点,构建了具有深度可分离卷积的轻量级模型MobileNetV2的神经网络加速框架并部署在Zynq-7000开发板上。在这项工作中,采用了一种协同设计方法,使用Vivado HLS设计用于实时图像和视频处理的加速器系统。基于所提出的方法,该加速器实现了较高的检测速度和精度,符合在嵌入式系统中使用的设计要求。总而言之,由于CNN模型的改进和硬件加速技术,该系统实现了较高的识别率和精度,较低的系统存储开销,可用于移动终端。
猜你喜欢
现代装饰(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
现代仪器与医疗(2022年3期)2022-08-12
现代仪器与医疗(2022年2期)2022-08-11
汽车实用技术(2022年13期)2022-07-19
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
图书馆界(2013年5期)2013-03-11
现代电子技术(2009年6期)2009-05-31
