
基于半监督学习卷积神经网络的三维人体姿态估计
2021-12-29 03:55林浩翔李万益邬依林谭烨希
现代计算机 2021年31期
林浩翔,李万益,邬依林,谭烨希
(广东第二师范学院计算机学院,广州 510303)
0 引言
三维人体姿态估计目前是一项比较新的研究课题,该课题的技术研究已经成功运用到以计算机视觉为基础的多项高级人工智能技术,比如音乐舞蹈等运动形体化教学[1-2]、制作3D人物的立体电影[3-5]、人体运动形态类型识别[6-7]等等,这些技术的应用都是以视频图像的三维姿态估计为基础,进行深入拓展的高级应用。目前,国内外学者对三维人体姿态估计的研究有一定进展,前期研究具有一定局限性。初始研究阶段,该技术研究用于数据样本的非监督学习,用有限三维数据样本生成新的三维数据样本[8],然而该研究实用性有限。后来,由于实际应用需要从二维图像重构出三维姿态来获取更多人体姿态参数,就从多个视角图像进行预处理,利用一些启发式智能算法来估计相应的三维姿态[9],其对于一些简单运动形态可以较好的估计,但是对于稍微复杂的运动形态效果较差,并且运行时间比较长,算法收敛性差。近两年,该项技术的研究发展到了单视角估计[10],用深度学习的方法对图像进行处理。然而,近期的技术处理的效果也有一定的局限性,比如估计对象的自遮挡处理、二维到三维映射歧义,以及空间位置无法处理等问题。因此,本文针对以上的一些问题,提出一种半监督学习卷积神经网络模型来实现单视角含有空间位置信息的三维姿态估计。
本文所提出的半监督学习卷积神经网络模型可以较好地处理自遮挡问题、图像映射歧义问题,可以估计出三维模型所在的空间位置信息,该方法的模型核心框架如图1所示,底部为骨架模型的二维映射图像,顶部是相应三维图像,通过若干神经网络的神经元构建相互映射关系。经过实验测试,其结果可以验证本文提出方法的有效,并且效果也可以从视觉效果得到很好的验证。
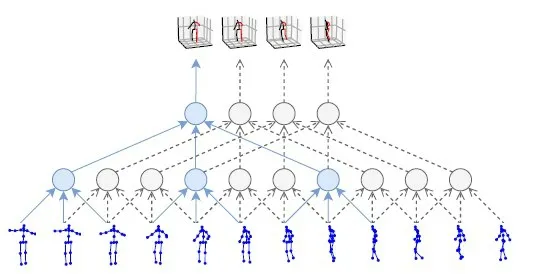
图1 半监督学习卷积神经网络模型的数据映射关系
1 半监督学习卷积神经网络模型
1.1 二维图像关键点检测
本文提出的半监督神经网络模型是依赖最初神经网络模型进行建立的,其最基本的运算方法也是对运行进行卷积计算,提取二维图像特征,建立三维骨架模型与相应视角投影模型,这个过程也可以称为二维关键点检测,如图2所示。该检测关键点需作为所提出模型的输入,该点需在二维图像的人体肢体上进行准确标注出。该数据是个张量,并且也可以被看做是图像的标签数据。

图2 二维图像的姿态关键点检测
1.2 半监督网络模型建立
半监督方法用于完善神经网络模型的映射关系,因此需要用部分真实二维关键点检测数据和相应三维骨架模型先进行训练,其方法框架图如图3所示,WMPJPE和MPJPE函数可以参考文献[10]。
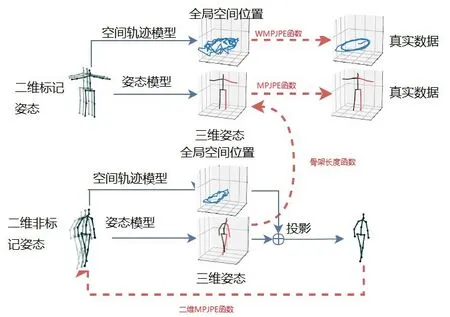
图3 半监督学习方法框架
在半监督模型建立之后,我们需要建立神经网络模型,神经网络模型的参数、层数以及相关具体框架如图4所示。该模型是训练全局空间位置样本以及姿态样本的核心模型,参数的选取以及层数的设置比较重要,因此,图4中给出了模型主要参数。在图4中,BatchNorm为每次训练规模参数,ReLU为偏移计算层,Dropout为丢弃数据的比例参数,Slice为所选数据切片。这里的神经网络训练需要多次,因为在半监督学习过程就是调整和收集额外有效训练样本的过程,需要不断更新我们初始说建立的神经网络,使得神经网络的映射关系不断完善。半监督学习一定的真实配套数据后,用测试数据进行预测,把预测值和测试数据再代入神经网络训练,实现映射关系的更新。

图4 神经网络模型框架
2 实验与评价
当模型建立并完成训练后,我们开始用数据对所提出的模型进行测试。我们选取Human 3.6M数据库[3]、Humaneva数据库[11]以及其他日常生活视频的数据进行测试。测试内容有二维关键点检测,以及相应三维姿态估计的三维骨架模型。我们选取每种运动形态的任意帧估计结果进行展示,实验过程中input为输入二维关键点检测图像,Reconstruction为估计出的三维姿态骨架模型,Ground truth为真实的三维姿态骨架模型。
首先测试Human 3.6M数据库的数据。该数据库带有真实数据集,含有实测真实的三维姿态骨架模型,是一套比较完善的数据库。我们选择放手走路姿态进行估计,测试结果选取任意3帧(图5)。在图5的视角效果比较中我们发现,把选取部分相关二维关键点进行肢体相连后,估计出的三维姿态骨架模型(Reconstruction)与真实的骨架模型(Ground truth)基本一致,并且投影到输入的二维关键点检测图像(input)后,视觉上也相当的匹配。这里所估计的三维骨架模型和真实的骨架模型具有空间位置信息,从所投影的二维图像可知,模型所处的位置就与二维图像的关键点位置相对应。由于绘图篇幅有些,这里就测试结果就显示其所在的空间局部。
市委管文教的林副市长,他老婆下午去世。我和他哥们。这人,还瞒着。我去陪陪他,对了,今晚可能回不来了。他急匆匆地出门了。
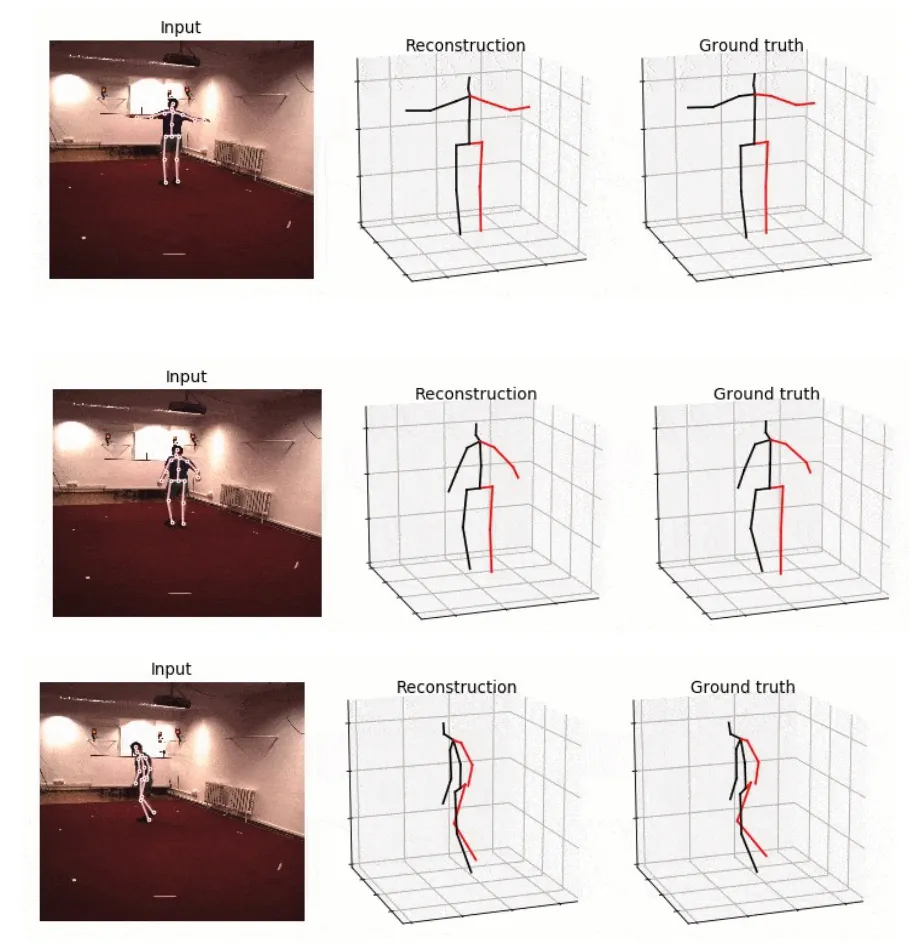
图5 Human3.6数据库测试结果
然后对Humaneva数据库一些常用运动类型的数据进行测试。数据库中的测试数据也有真实数据配套,我们仍然从估计的视角效果来观察,但这次保留原始检测的二维关键点进行测试,测试结果选取任意3帧(图6)。
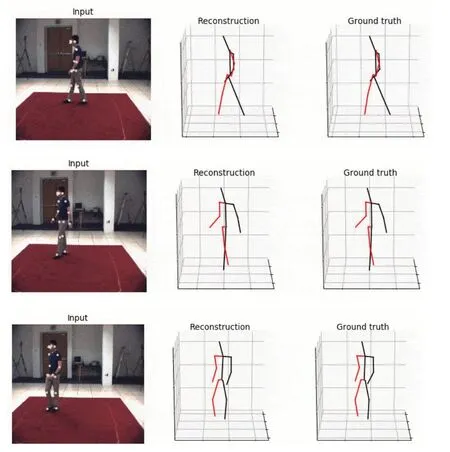
图6 Humaneva数据库测试结果
在图6中我们发现,所估计的三维姿态估计模型(Reconstruction)的效果也比较理想,与真实的骨架模型(Ground truth)非常接近,并且左右肢体没有相反的现象。这些结果证明,一些自遮挡、二维到三维图像的映射歧义问题能克服。二维图像(input)的关键点检测也较准确,符合所估计模型的投影位置。这些现象都表明所提方法的准确性和稳定性较好。同样的,这里所估计的三维骨架模型和真实的骨架模型也具有空间位置信息,可以从所投影的二维图像关键点可知,模型所处的位置就与二维图像的位置也有较理想的对应。这里同样也是为了适应测试显示的绘图篇幅,选取三维骨架模型的局部空间来显示测试结果。
最后,我们选取日常生活的视频数据进行处理,每个日常生活的视频选一帧,测试结果如图7所示。这里测试的数据没有标准数据库那样的真实数据配套,测试估计三维姿态是不合空间位置信息的,所以估计的只有不含空间位置信息三维姿态骨架模型(Reconstruction),以及二维图像(input)的关键点检测结果。从视觉效果上看,所提方法得到的结果再次验证其具有良好的数据通用性和准确性。

图7 日常生活的视频测试
3 结语
本文提出了一种半监督学习卷积神经网络模型来对单视角的二维图像进行三维姿态估计,其三维姿态用三维骨架模型表示,并且给骨架模型可以转换为很多细腻的人体体型模型[4]。本文提出的方法较好地解决了前人研究成果的一些局限性,比如自遮挡、图像映射的歧义以及空间位置处理等问题都能较好解决。经过实验测试的验证,本文提出的方法具有良好的稳定性、准确性,以及数据通用性。本文所提出的方法是深度学习理论在计算机视觉的发展理论成果,同时为实现三维姿态估计提供一种思路,可供相关研究人员参考。本文所提出的方法含有的神经网络模型具有半监督学习功能,同时也是继承了机器学习的部分理论基础,发挥其应有的性能优势。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
电子乐园·上旬刊(2022年5期)2022-04-09
电子乐园·上旬刊(2022年5期)2022-04-09
建材发展导向(2022年2期)2022-03-08
发明与创新·大科技(2020年6期)2020-06-22
当代陕西(2019年18期)2019-10-17
广东教育·高中(2017年10期)2017-11-07
农业工程技术·温室园艺(2017年3期)2017-07-13
诗选刊(2015年4期)2015-10-26
新高考·高一物理(2015年5期)2015-08-18
