
基于BERT 的突发事件文本自动标注方法
2021-12-17 00:56杨芷婷马汉杰
智能计算机与应用 2021年6期
杨芷婷,马汉杰
(浙江理工大学 信息学院,杭州 310018)
0 引言
自然语言处理技术(Natural Language Processing,NLP)是计算机科学、人工智能和语言学交叉的领域,主要研究用计算机来处理、理解和应用人类语言,达到人与计算机之间的有效通信。信息抽取为自然语言处理领域的一个重要研究方向。其中,命名实体识别(Named Entity Recognition,NER)是信息抽取的基础任务,其任务是从文本中识别出诸如人名、组织名、日期、时间、地点、特定的数字形式等内容,并为之添加相应的标注信息,为信息抽取后续工作提供便利[1]。在实际自然语言处理任务中,如社交媒体文本处理等,NER 作为上游任务在整个系统中起着举足轻重的作用。
随着网络信息的爆发式增长,传统的文本分析手段已不适合处理海量突发事件信息,机器学习和数据挖掘技术才是目前信息抽取任务处理过程中备受青睐的处理技术。随着评测会议,如:MUC(Message Understanding Conference)[2]、自动内容抽取(Automatic Content Extraction,ACE)[3]的举办,事件抽取技术取得了长足进展。2016 年Peng等人将Chen等人发表的SOTA 中文分词系统[4]与中文媒体ER 模型结合[5],在实体识别训练过程中利用分词训练提供的输出参数训练,使识别效果提高了5%[6];Lample 在堆叠LSTM 模型(S-LSTM)基础上,结合基于字符的表示模型[7]和词嵌入模型,在多种语言上得到了较好的训练结果[8];伟峰等人在2019 年首先提出利用基于注意力机制[9]的序列标注模型,联合抽取句子级事件的触发词和实体,与独立进行实体抽取和事件识别相比,联合标注的方法在F值上提升了1 个百分点;武惠[10]提出基于迁移学习和深度学习的TrBiLSTM-CRF 模型,采用实例迁移学习算法将源域知识迁移到目标域,在小规模数据集上取得了较好的效果。
本文利用深度学习网络搭建学习模型,以标注的中文事件语料数据为输入,训练得到自动提取事件信息的网络模型,该模型主要由BERT-BiLSTMCRF 组成。其中,BERT 预训练语言模型由谷歌人工智能团队提出,能够较完整地保存文本语义信息;BiLSTM-CRF 是较为常见的序列标注模型,在语音识别、词性标注、实体识别等领域应用广泛。在中文文本事件知识提取领域,研究语义、推理和挖掘是提取信息的主要手段之一,在程序开发过程中还需语言领域相关储备知识,对研究人员来说是个不小的挑战,而深度学习网络训练模型和大数据,使得中文信息处理发展向前推进了一大步。
1 相关工作
由于事件文本的特殊性,学者们对不同的事件语料库采用了不同的标注体系[11],目前影响较大的事件标注语料库有ACE 测评语料[12]和TimeBank语料[13],中文事件标注语料比较常用的是中文突发事件语料库(CEC)。CEC 语料库是由上海大学(语义智能实验室)所构建。CEC 语料库根据国务院颁布的《国家突发公共事件总体应急预案》分类体系,收集了5 类(地震、火灾、交通事故、恐怖袭击和食物中毒)突发事件的新闻报道作为生语料,经过对生语料进行文本预处理、文本分析、事件标注以及一致性检查等处理,最后将标注结果保存到语料库中,CEC 合计332 篇[14]。与ACE 和TimeBank 语料库相比,CEC 语料库的规模虽然偏小,但是对事件和事件要素的标注却最为全面。
CEC 标注语料采用XML 格式,文本格式以Title、ReportTime、Content、eRelation 标签依序组成,如图1 所示。Content 标签内容为已标注事件元素的新闻文本。Event 标签主要包含的标签有:事件触发词(Denoter)、事件发生地点(Location)、时间(Time)、对象者(Participant)等。eRelation 标签定义事件之间的关系属性,有5 种类型值:因果(causal)、伴随(accompany)、跟随(follow)、组成(composite)以及意念包含(thoughtContent)。
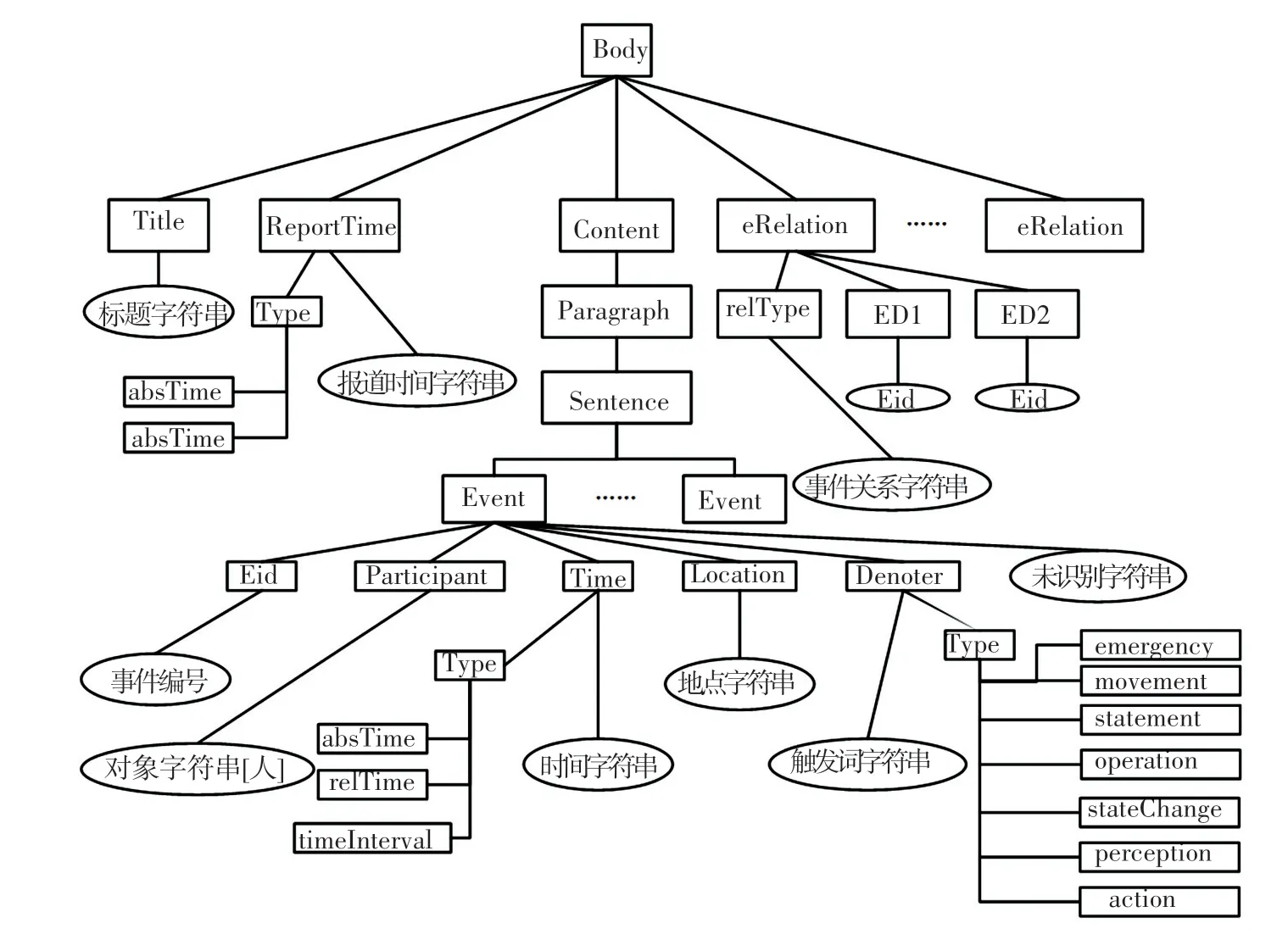
图1 CEC 语料标签树Fig.1 CEC corpus label tree
中文实体识别与英文不同,是以分词为基础(word-based)的训练模型,识别效果与分词准确性相关。如:“南京市长江大桥”若错误地被分割为“南京/市长/江大桥”,则会影响该实体的识别效果。不少专家研究得出,在中文实体识别中使用基于字(character-based)深度识别模型优于基于词的模型。但由于中文的多义性和多态性,单纯依靠字特征将会丢失词语隐藏的信息。因此,如何将基于字的模型和基于词的模型混合得到更好的结果,是当前中文实体识别的一大研究热点[15]。在数据不足或特殊文本的情况下,引入语法结构特征和词性特征,通过编写规则,识别事件信息是常用的事件抽取方法[16]。
本文主要针对的是中文文本的事件识别和事件元素提取研究。利用BERT-BiLSTM-CRF 模型对CEC 语料进行训练,提取出相关事件元素。在进行处理之前,需要对事件语料进行预处理,将标注的xml 文件转换成可训练格式。事件触发词抽取任务要求正确识别触发词并判断触发词赋予正确的类型。对于实体识别,要求对文本中事件触发词Denoter、事件中的对象Participant、时间Time、地点Location、目标Object等5 类实体进行正确识别和分类。
2 网络模型
2.1 LSTM 模型
2013 年Mikolov 提出Word2Vec 模型,包含两个模型CBOW 和Skip-gram,前者通过窗口语境预测目标词出现的概率,后者使用目标词预测窗口中的每个语境词出现的概率。语义上相似或相关的词,得到的表示向量也相近,这样的特性使得Word2Vec获得巨大成功。2014 年Hochreiter 与Schmidhuber提出LSTM 模型,解决了梯度消失和爆炸问题,能够提取更长文本之间的信息,属于循环神经网络RNN的一种变体。其结构如图2 所示。
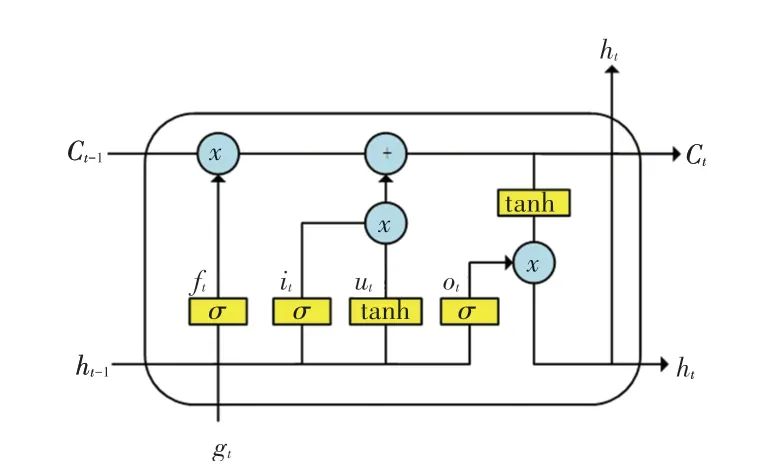
图2 LSTM 模型Fig.2 The model of LSTM
每个LSTM 单元由循环连接的记忆细胞ct组成,细胞包含3 种类型的门:遗忘门ft、输入门it、输出门ot。在时刻t各个门的计算公式如下:
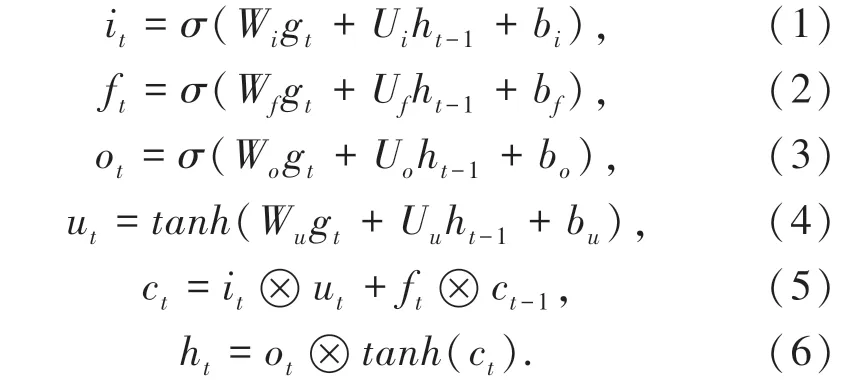
其中,Wi、Ui、Wf、Uf、Wo、Uo分别表示各个门的权重矩阵;bi、bf和bo为各个门的偏置矩阵;Wu、Uu、bu分别是新记忆内容ut的权重矩阵和偏置矩阵;ht为LSTM 的隐藏状态;σ为元素级sigmoid激活函数;tanh为元素级的双曲正切激活函数;⊗表示元素级相乘操作。
公式(2)中,遗忘门通过查看ht-1和gt信息,使用sigmoid函数输出一个0~1 之间的向量,决定细胞状态ct-1中信息的取舍;公式(4)中,输入门通过查看ht-1和gt信息,使用tanh层得到新的候选细胞信息ut,并同样使用sigmoid函数决定信息的更新(公式(1)、公式(5)是新细胞信息的更新公式);最后,由输出门公式(3)判断输出细胞的状态特征,将细胞状态经过tanh层后得到的向量与输出门得到的向量相乘(公式(6))即为细胞单元最终的输出。
在句子中,识别一个实体需要考虑上下文信息,所以本文使用双向LSTM(Bidirectional LSTM)获取句子的语境信息。BiLSTM 的结构如图3 所示,隐藏状态表达公式为:
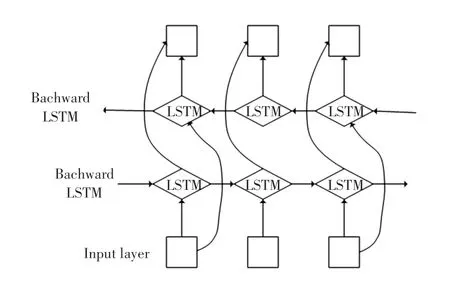
图3 BiLSTM 结构图Fig.3 The structure of BiLSTM
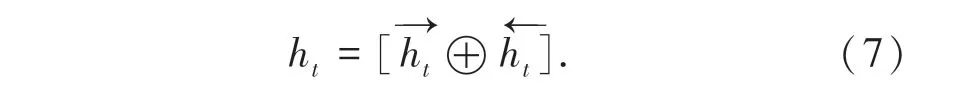
2.2 BERT 模型
BERT 模型由谷歌提出[17],需要面向各类任务,其输入处理与常见的语言训练模型不同,在词向量的基础上添加了位置向量和段落向量,如图4。在处理输入的句子时,序列首位会加上[CLS]标记,若输入句子正确时,则添加[SEP]标记。
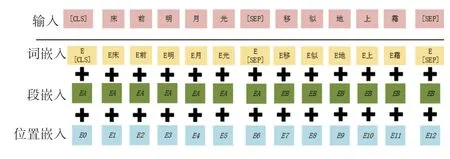
图4 BERT 模型输入向量Fig.4 BERT input vector
虽然通过神经网络训练模型可以得到词的向量表示,但该向量为固定向量,无法体现字的多义性。而BERT 预训练语言模型可以得到一个字上下文相关表示,能够表示字的多义性及句子的语法特点[18]。面对不同的学习任务,BERT 模型内部结构不需要做太多改变,主要对输出层做出调整。BERT模型采用双向Transformer[19]做为编码器(结构如图5 所示),采用多头注意力机制,可以更好的捕捉词与词之间的关系,序列编码更具整体性。Transformer 编码单元如图6 所示,编码单元最主要的模块是自注意力部分计算公式:
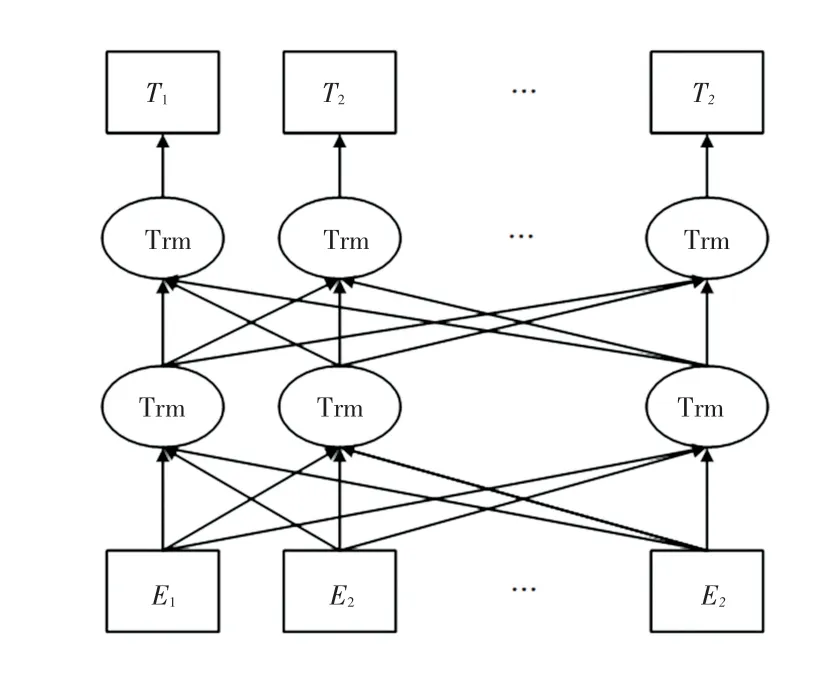
图5 双向Transformer 结构Fig.5 Bidirectional Transformer structure
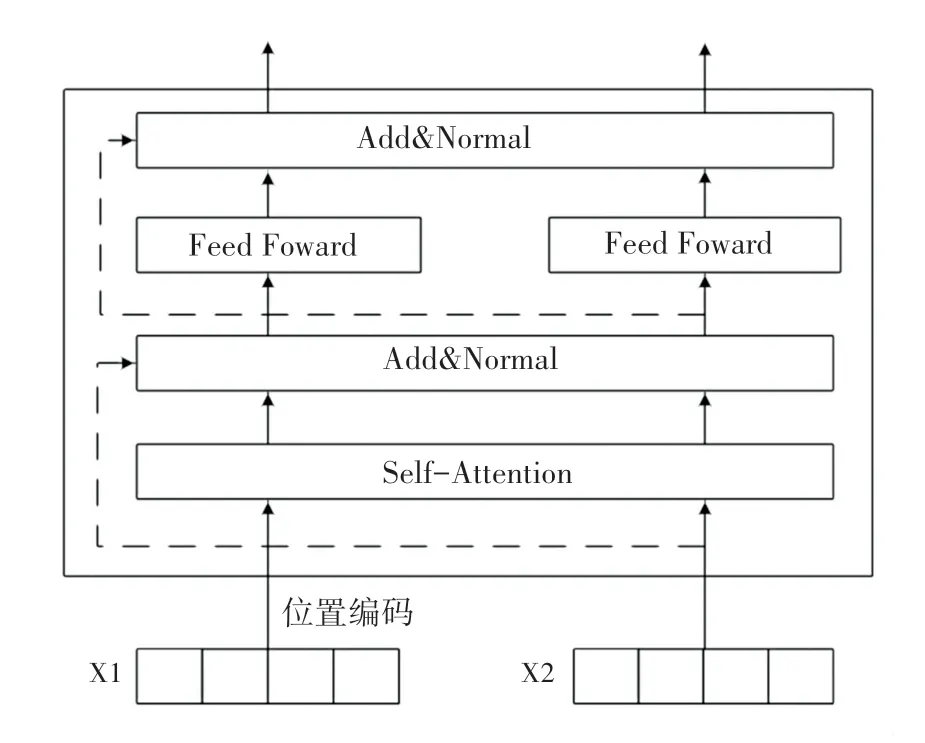
图6 Transformer 编码单元Fig.6 Transformer encoder unit

其中,Q、K、V为输入向量分别乘以WQ、WK、WV矩阵,经过线性变化得到dk为输入向量维度。经过dk进行缩小之后通过softmax归一化得到权重表示,最后得到句子中所有词向量的带权和,这样的词向量相较于传统词向量更加具有全局性。
此外,BERT 模型采用了多头注意力机制(Multi-Head Attention),多头自注意力计算过程分为4 步:
(1)输入经过线性变换后生成Q、K、V3 个向量;
(2)进行分头操作(假设原始向量维度为512,分成8 个head 后,每个head 维度为64);
(3)每个head 进行自注意力计算;
(4)最后将计算结果拼接起来。公式描述为:
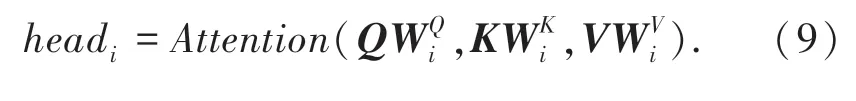
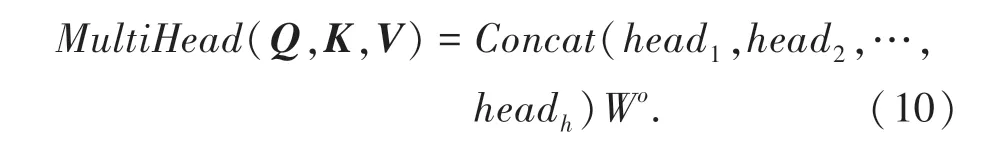
为解决深度学习中的退化问题,编码单元加入了残差网络和层归一化,如式11 所示:

之后将归一化结果使用ReLU 做为激活函数,运算如下:
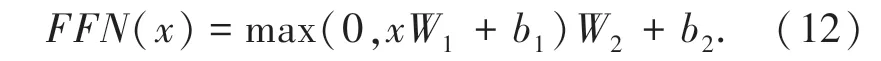
该模型在预训练中主要包括2 个任务:Masked语言模型和Next 句子预测。在训练过程中,首先构造句子对。构造方法是在规模文本中,选择具有上下文关系的句子对,对其中50% 的句子对进行随机替换,使其不具有上下文关系,然后在“Masked 语言模型”和“Next 句子预测”任务上进行训练,捕捉词级别和句子级别的表示。
2.3 CRF 模型
CRF 模型[20]由Collobert 提出,相较于softmax分类器,能考虑标签序列的全局信息,获得更优的标签序列。CRF是在给定随机变量X的条件下,随机变量Y的马尔科夫随机场,在序列预测问题常用的是线性链马尔科夫随机场。对于观察序列x=(x1,x2,…,xn)和状态序列y=(y1,y2,…,yn),利用Softmax归一化后的概率如式(13)所示:
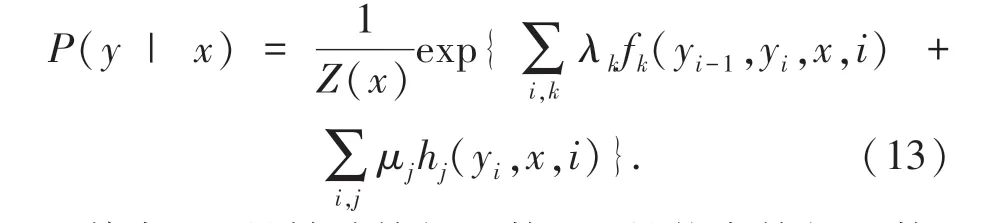
其中,fk是转移特征函数;hj是状态特征函数;λk、μj是对应的权值;Z(x)是归一化因子,计算公式如下:
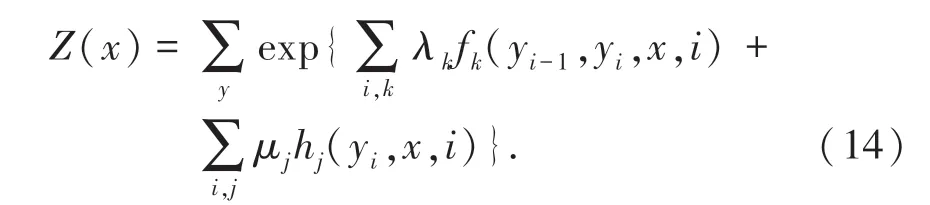
模型在预测过程(解码)时,使用动态规划的Viterbi 算法来求解最优路径,如式(15)所示:

3 实验过程
3.1 实验数据
本文使用的是上海大学公开的中文突发事件语料库,是一个一个小规模的事件语料库,合计332 篇。语料文本包括:地震、火灾、交通事故、恐怖袭击、食物中毒等5 类。其中各类文本数据统计见表1。
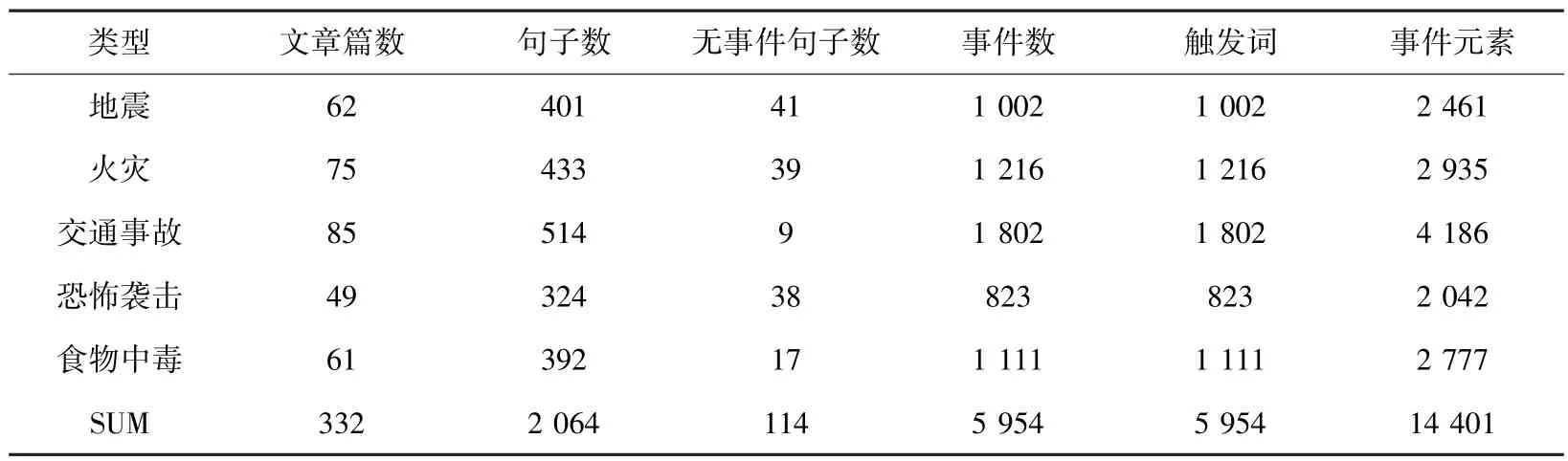
表1 CEC 语料文本数据统计Tab.1 CEC corpus text data statistics
对于CEC 语料的处理方式可以参考实体识别训练时使用的BIO 三段标记法:对于每个需要识别的标签,将第一个字标记为“B-(实体类别)”,后续标记为“I-(实体类别)”,对于无关字,一律标记为O。以下面一段xml 格式文本为例做一说明:

经过转换之后变为如下形式(文字斜杠后表示标注序列):
学/B-PP 校/I-PP等/O 单/O 位/O 也/O 立/O即/O 疏/B-DNT 散/I-DNT 到/O 安/B-LOC 全/ILOC 场/I-LOC 所/I-LOC。/O
BIO 三段记法最大的优点是支持逐字标记,减少了系统因分词而产生的误差。标记好的数据有O、B-PP、I-PP、B-LOC、I-LOC、B-TM、I-TM、BDNT、I-DNT、B-OJ、I-OJ、B-RT、I-RT、X、[CLS]和[SEP]共16 大类;[CLS]为句子开始标志,[SEP]为句子结尾标志。对于每一类实体的识别效果,采用精确率(P)、召回率(R)和F值作为模型性能的评价标准,具体计算公式如下:

3.2 模型参数
本文采用由谷歌人工智能团队开发的Tensorflow框架搭建模型,BERT 预训练语言模型默认采用12头注意力机制,每次读取序列长度为128,预训练词长度为768;训练批次为16,优化器采用Adam,学习率设置为10-5。LSTM 隐藏单元设为128,为解决梯度消失和爆炸问题,设置丢弃率为0.5,采用梯度裁剪技术,clip 设置为5。由双向LSTM 网络输出得到的256 维字向量,经过压缩为16 维向量作为CRF层的输入。
3.3 实验结果及分析
将训练数据从xml 格式转换为适合的训练数据后,得到标签统计见表2。
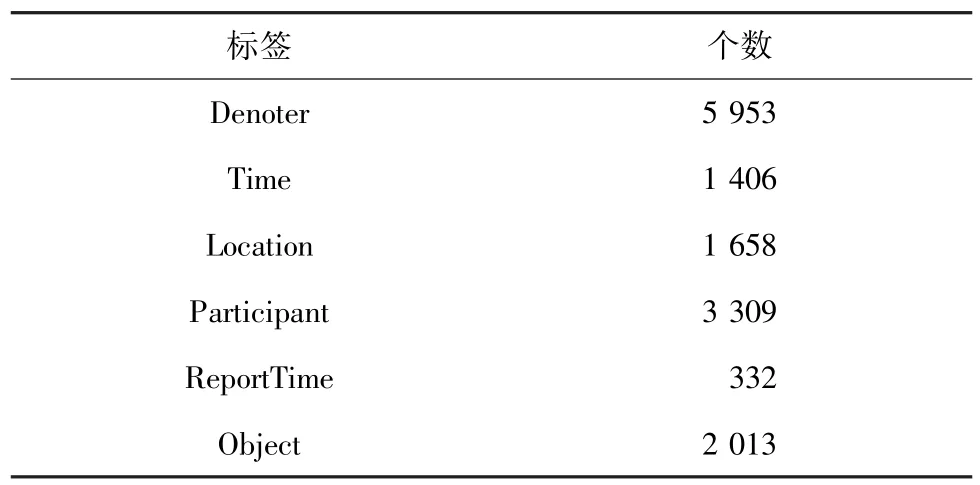
表2 训练数据标签统计Tab.2 Train data labels statistics
由于训练数据量较少,将训练数据按照8 ∶2 分割为训练集和测试集。训练得到的网络模型在测试集上各类实体的识别率与BiLSTM+CRF 神经网络识别率对比结果见表3。

表3 实验识别结果Tab.3 Label element recognition experiment results
由此可知,相较于使用训练好的维基百科字向量+BiLSTM+CRF 模型,使用BERT 模型得到的训练结果在各个元素上皆优于该模型,尤其在对象元素识别上得到了近20%的提高。再对比文献[24],采用人工语法规则自动标注得到的实验结果见表4。
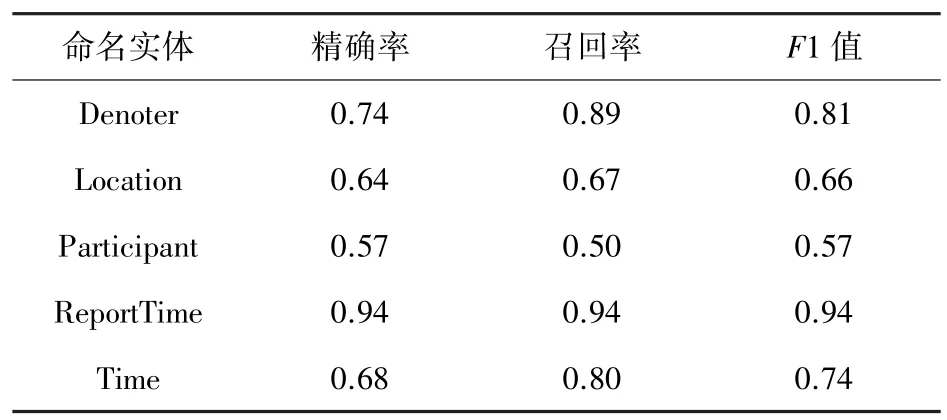
表4 人工语法规则自动标注结果Tab.4 Experiment results of using grammar rule
可以看出,使用机器学习的方法在时间、报道时间、参与对象3 类实体的识别准确率、召回率和F1值上均有所提高,在发生地点、触发词的识别率上稍有降低。由此表明,在利用BERT-BiLLSTM-CRF模型基础上,确实可以提高部分实体识别的精确率,避免了对实验文本的语法规则和人工实现过滤规则等耗费时力的操作,但在触发词等实体类的识别上稍显劣势,这也是今后需要研究改进的地方。
4 结束语
本文利用BERT-BilSTM-CRF 深度学习模型,对CEC 语料库进行自动化标注,提高了标注效率。与传统手工标注方法相比极大的提高标注速度,即使在识别准确率不高的情况下也可人工调整,有利于大规模语料标注工作。对比BiLSTM-CRF 网络模型,在事件各个要素识别上都取得较为明显的优化。本文实验模型还存在改进的地方,如在无明显规则的事件触发词、事件参与对象等实体识别的效果并不理想,这是由于事件对象短语在事件句中没有较为明显的规律特征,需要结合中文语法特征进一步发掘有效识别规则,有待进一步研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
长江丛刊(2019年25期)2019-11-15
知识文库(2019年22期)2019-11-11
电脑知识与技术(2019年23期)2019-11-03
师道·教研(2017年11期)2017-12-10
科学与财富(2016年30期)2017-03-31
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
改革与开放(2010年6期)2010-06-04
教学与管理(理论版)(2009年9期)2009-11-04
