
基于微振动增强的伪装人体检测算法
2021-12-17 00:56黄飞龙杨学志吴克伟沈晶陈鲸
智能计算机与应用 2021年6期
黄飞龙,杨学志,吴克伟,沈晶,陈鲸
(1 合肥工业大学 计算机与信息学院,合肥 230009;2 工业安全与应急技术安徽省重点实验室,合肥 230009;3 合肥工业大学 软件学院,合肥 230009;4 合肥师范学院 电子信息与电气工程学院,合肥 230061;5 安徽微波与通信工程技术研究中心,合肥 230061)
0 引言
人体的检测在现实生活中有着许多重要的应用,例如交通监控、自动驾驶、智能监控、行人监控等,这些场景都需要实现准确的人体检测。人体的检测一直是计算机视觉领域的研究热点,许多基于人脸和人体姿态估计的人体检测算法已经被提出来并得到了很好的完善。过去几年,人们的重点关注在于行人的检测,在公开可用的研究数据集中,最受欢迎的是INRIA 数据集。除此以外,显著性目标的检测也得到了很充分的研究,为行人的识别研究提供了很好的参考。然而,在一些场景下,当人体的外观特征并不明显的时候,仅仅依靠图像的表层特征是无法检测出来的。例如,在复杂环境中经过了一定程度伪装的人体目标。伪装人体就是经过迷彩服装、颜料等手段,使自己的外观颜色、纹理特征和背景高度融合,以至于人很难通过眼睛发现的人体目标。伪装人体的检测算法可以很好检测出图像特征不明显的人体目标,对于边防监控、入侵检测、灾害救援活人检测、军事目标发现等方面具有重要的作用。
伪装人体检测是目前计算机视觉的一个具有挑战性的任务。使用计算机视觉的检测方法处理的数据通常是单张图像或者是具有时间信息的视频。近年来,已有一些伪装人体检测相关的研究,这些研究根据提取的视觉特征不同,可以分成4 类:亮度或颜色特征、纹理特征、梯度特征、深度特征。亮度和颜色特征是最基本的特征,利用亮度或者颜色特征来检测伪装人体目标,设计了一种加权区域合并的迭代方法,来检测图像序列中颜色非常接近的伪装目标的方法[1]。这种方法的效果主要依赖于图像之间的差异,如果检测的目标不移动或缓慢移动,这种方法就不能检测出伪装人体目标;利用纹理特征进行伪装检测,提出了一种方法来检测目标的伪装部分,并将伪装部分从给定图像的环境中提取出来[2]。采用基于灰度共生矩阵的纹理特征和树状图来检测伪装目标,但是这种方法非常耗时,因为其需要将给定的图像分割成多个块或更小的区域,在包含阴影效果和背景与目标包含相似纹理的图像中,这种方法无法有效检测出伪装的目标。使用梯度特征进行伪装人体检测,提出了一种Darg算子来增强对应于三维目标凸面的阴影区域,从而将该区域从具有颜色和纹理等相似特征的平坦背景中分离出来[3]。Darg算子直接应用图像的灰度函数,对目标上光滑的三维凸面做出响应,不会受到任何特定光源及其反射函数的限制,但是使用Darg算子检测的结果高度依赖于阈值,选择一个合适的阈值本身也是一个重要的问题。此外,这种方法不适用于包含凹面特性的背景和深色的目标。深度特征检测伪装人体目标,提出了强语义扩张网络来检测伪装的人[4]。充分利用了卷积神经网络的语义信息,并利用了空洞卷积来扩大接受野,以发现伪装的人体目标。在一个标准的图像数据集上给出了令人印象深刻的结果,但是如果在一些数据集中未知场景的伪装人体不一定能检测出来。
针对以上问题,本文提出了一种基于微振动增强的伪装人体检测算法。首先,提出了自己的伪装人体视频数据集和基于微振动特征的伪装人体检测模型,利用训练集估计伪装人体目标的最优的呼吸率区间;其次,利用估计的最优呼吸率区间增强了视频中伪装人体的微振动;最后,根据增强了微振动的视频和提出的检测模型实现伪装人体目标的定位检测,并通过图像形态学去噪后处理降低检测结果的噪声。本文的振动特征用于伪装人体检测取得了比其它特征更好的效果,如图1 所示。
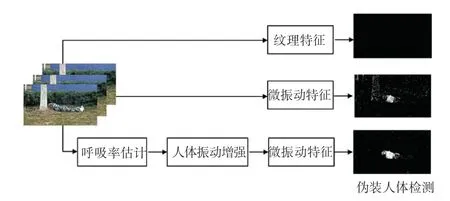
图1 不同特征的检测效果Fig.1 Detection effect of different features
1 本文算法
1.1 提出的数据集
由于现有的伪装数据集收集的伪装图像无法用于基于视频的伪装人体检测。因此,使用带有三脚架的佳能数码相机收集了10 个被伪装人员的300个稳定的视频。视频微小振动检测面临的挑战是长距离的目标,因此这项工作进一步在不同的拍摄距离上收集了不同比例的伪装人类。拍摄距离为10 m、20 m、30 m 的视频数分别为100 个,每个视频的持续时间为15 s,分辨率为720× 360,帧速率为50 fps。在一天中的不同时间,在足够的光照条件下采集视频。视频数据集分为训练集和测试集,其中每种拍摄距离的50 个视频用于训练,其余视频用于测试。测试集中不存在训练集中的伪装人员,可以验证呼吸率区间估计的鲁棒性。
这些视频数据使用标注工具labelme 对第一帧图像的伪装人体目标进行像素级别的标注和外接包围框,并带有拍摄条件,包括:环境、振动类型、遮挡类型、高光和阴影类型、颜色深浅类型和拍摄距离。数据集部分视频及其标注,如图2 所示。
环境:视频包括各种自然环境,例如:草(图2(a)),灌木丛(图2(b)),树木(图2(c)),树叶(图2(d))。
振动类型:视频具有2 种人体振动类型,包括腹部向上(图2(e)和图2(g))和腹部向下(图2(f)和图2(h))。
遮挡类型:伪装的人体没有背景遮挡(图2(e)和图2(f))或有背景遮挡(图2(g)和图2(h))。
高光和阴影类型:在视频中存在高光和阴影(图2(b))或没有高光和没有阴影(图2(a))。
颜色深浅类型:背景和伪装的人体具有深色外观(图2(b))或浅色的外观(图2(i))。
拍摄距离:伪装的人体距离为10 m(图2(i)),20 m(图2(j)),30 m(图2(k))。

图2 视频数据集部分数据Fig.2 Part of the video data set
1.2 提出的方法
本文提出了基于微振动特征的伪装人体检测模型,根据视频训练集估计了更准确的伪装人体呼吸率区间,根据估计的呼吸率区间增强视频中伪装人体振动信号,利用检测模型和形态学去噪方法得到检测结果。检测框架如图3 所示。
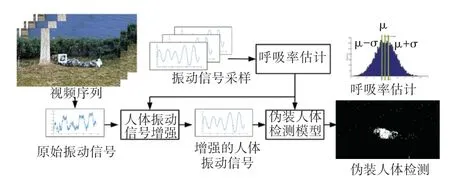
图3 伪装人体检测框架Fig.3 Camouflage human detection framework
1.2.1 伪装人体微振动检测模型
人体的呼吸频率是人体胸部和背部微振动的频率。根据医学统计,人体的呼吸率数值区间为0.20~0.33 Hz。因此,人体胸部和背部的振动频率和人体的呼吸率是一样的。给定包含伪装人体的视频,并将该视频转换到YIQ 色彩空间,其中通道Y是亮度通道。像素x在各个时间t的亮度可以记为序列f(x,t),则f(x,t)是振动信号;使用一维快速傅立叶变换(FFT)将时域信号f(x,t)转换为频域信号:fω(x,ω)=fft(f(x,t)),频域信号fω(x,ω)的模的最大值是其幅值,如公式(1)所示。

频域信号的振动频率与其幅值相对应,如公式(2)所示。
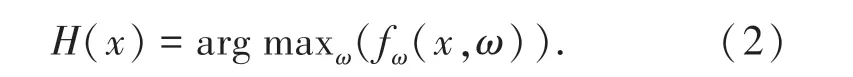
假设人体的呼吸频率区间为H(a,b),则基于微振动特征的伪装人体检测模型如公式(3)所示。

R(x)表示伪装人体检测结果。
1.2.2 伪装人体呼吸率估计
由于医学统计的人体的呼吸频率区间是在人体正常情况下测量的,而在本文的数据集中,伪装人体的呼吸频率高于正常人体的呼吸率区间,这可能是因为人体的伪装姿势会影响到呼吸。因此,需要在视频数据集人体伪装姿势情况下估计呼吸频率区间。本文使用视频训练集估计伪装人体的呼吸频率的区间,训练集包含每个拍摄距离的50 个视频。呼吸率区间估计过程如图4 所示。在每个训练的视频真值分割图中采样200 个像素,并形成振动信号集Fp(x,t)={fp(xi,t)},其中p表示伪装人体的真值位置,i是训练视频的编号。呼吸率区间估计变成了发现信号集振动频率和频谱幅值的数学分布,振动信号集的振动频率和频谱幅值都服从正态分布,如公式(4)、(5)所示。

图4 呼吸率区间估计示意图Fig.4 An overview of respiration rate interval estimation
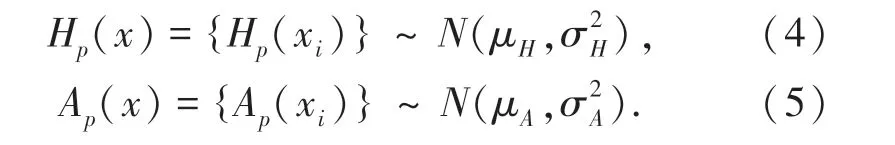
在本文的训练集中,振动频率的均值μH为0.447、标准差σH为0.133,频谱幅值的均值μA为22.830,标准差σA为15.590。数据集中伪装人体目标的呼吸率区间和频谱幅值的阈值分别取为等式(6)、(7)。

其中,k是区间估计因子,当k=1时,估计的区间包含95%的真值图像的像素。

1.2.3 伪装人体微振动增强
伪装人体目标在视频中表现出来的振动是微小的,很难直接分析到这种信号。伪装人体的振动还会受到环境的干扰,例如背景中的草、树叶等植物在风的作用下的晃动,需要抑制这些环境中植物的振动。微振动增强就好比一个显微镜,可以将特定频率范围的振动信号进行增强,抑制其它不感兴趣频率的振动,可以更好的捕捉到需要的信号。在这里不能使用标准的傅立叶变换方法,因为其仅适用于图像中的整体相位的变化。
使用了基于相位变化的微振动增强方法来处理局部相位的变化[5]。本文基于其源码修改,以实现伪装人体的振动信号增强。为了测量图像中的局部相位振动,使用了复数数域的可控金字塔,类似于将图像划分为不同空间结构的局部傅里叶变换。复数数域的可控金字塔将图像分解为对应于不同图像尺度和方向的不同子带,每个子带的每个像素位置都用局部幅度和局部相位来表示。用时间带通滤波器进一步处理随时间变化的相位信号,以提取感兴趣振动的像素位置,这些经过时域带通滤波的相位差乘以一个放大因子α。在图像的局部相位放大处理之后,将所有的子带求和以重建视频,得到伪装人体微振动增强的视频。伪装人体微振动增强的整个过程如图5 所示。
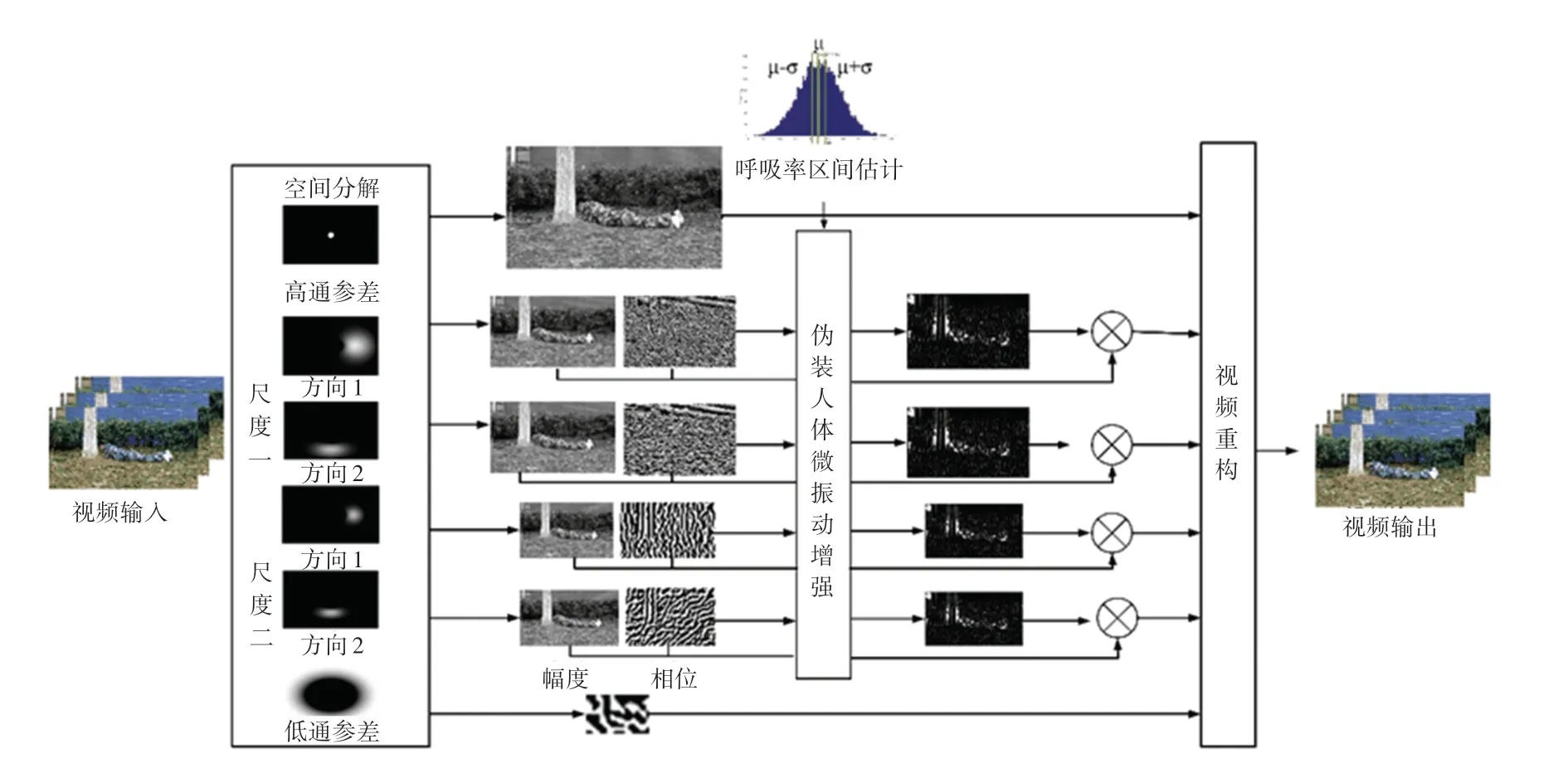
图5 伪装人体微振动增强示意图Fig.5 An overview of micro-vibration enhancement of camouflaged human
假设图像尺度j的视频信号为fj(x+δ(t)),其中f表示尺度j的图像的亮度平面,δ(t)表示伪装人体的微振动位移。根据傅里叶级数展开式,fj(x+δ(t))可以写成一系列复数正弦信号Sjω(x,t)=Ajωeiω(x+δ(t))的和,而且这些复数正弦信号分别对应一个频率ω,如公式(8)所示。
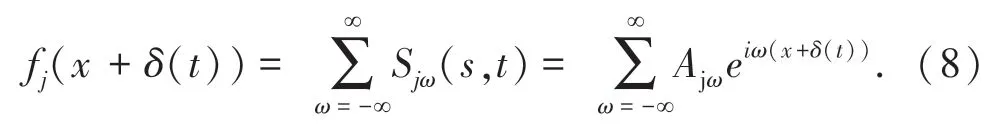
其中,Sjω(x,t)是子带信号fj(x+δ(t))的频率为ω的基信号。因为Sjω(x,t)是正弦信号,其相位信息ω(x+δ(t))包含了伪装人体的微小振动的相位信息和直流分量ωx。在使用时域带通滤波器去除直流分量ωx后,伪装人体的微振动相位信息是Bω(x,t)=ωδ(t),这在每一个视频尺度和每一个子带下都是一样的,然后使用放大因子α对表示伪装人体微振动相位信息进行放大处理,得到放大了相位信息的基信号,如公式(9)所示。
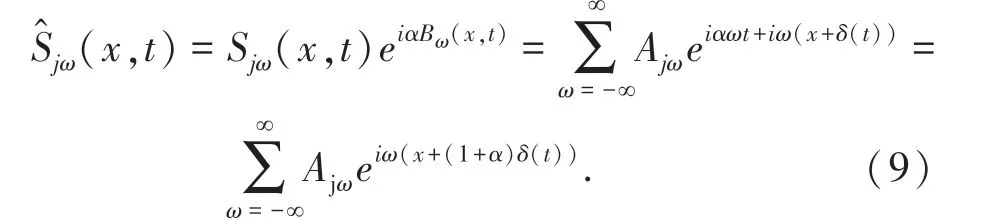
其中,(x,t)表示放大了相位信息的基信号。把所有放大了相位信息的基信号加起来,得到一个增强的子带信号,如公式(10)所示。
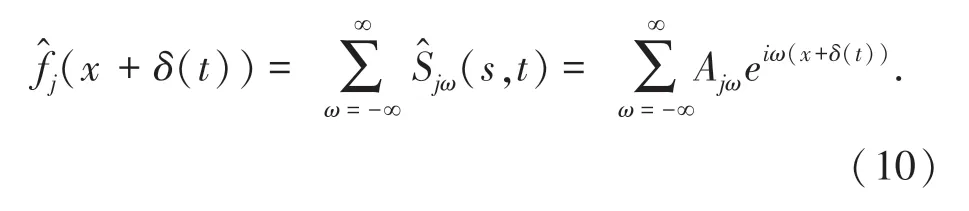
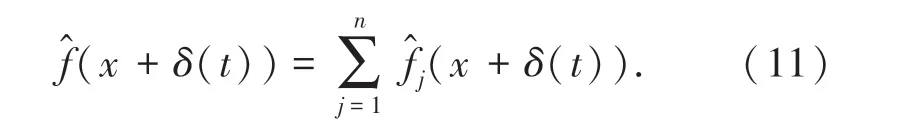
1.2.4 伪装人体检测后处理
经过振动增强模块,原视频中伪装人体的微小振动信号得到增强,对进一步进行伪装人体检测很有帮助。对增强信号后的视频进行处理,计算出增强视频的整个空间的频率平面(x)和幅值平面(x),利用公式(3)表示的检测模型,根据频率平面(x)、幅值平面(x)、公式(6)、公式(7),得到了伪装人体目标检测的结果R(x)。
为了降低检测结果的噪声、填补目标的空洞,最后加入了一个图像形态学去噪模块对检测结果进行后处理操作。使用大小为3×3 的结构元素,对检测结果R(x)进行一次图像开运算,以降低检测结果的噪声。一次图像开运算是先对图像进行一次膨胀操作,再对图像进行了一次腐蚀操作,前者可以填补目标的空洞,后者可以去除检测结果的噪声。这个过程如图6 所示。

图6 伪装人体检测后处理过程示意图Fig.6 An overview of the post-processing process of camouflaged human detection
基于微振动增强的伪装人体检测的框架可以使用算法1 进行描述。
算法1基于微振动增强的伪装人体检测
输入:原始视频信号f(x,t),估计的呼吸率区间ω=(Ha,Hb),估计的幅值阈值τ
输出:伪装人体图像分割结果R(x)


2 实验结果与分析
2.1 评价指标
使用重叠度(IOU)来评价本文检测算法的检测能力。重叠度指标经常用在物体检测任务上,用来评价检测的物体区间和物体真实区间之间的匹配程度。本文实验里,重叠度是检测区间面积与物体真实区间面积的比例。如果检测到的目标的区间面积、目标真实区间的面积分别是Sp、Sg,那么重叠度IOU的计算方式是公式(12)。

也使用了精确度(Precision)来评价本文的检测模型。精确度指标是在分类模型里评价模型检测出正确数据点的能力,定义为公式(13)。

IOU和Precision是机器学习目标检测中广泛使用的评价标准,两个评价标准可以很好评价目标检测的准确性,本文选择了这两个评价标准来进行性能度量。
2.2 算法时间效率
使用Matlab 2019 在处理器为i7Core、3.60 Ghz CPU 和8 G 内存的PC 上实现的。为了减少运行时间,将视频原始图像降采样为360×180 的分辨率。输入的振动信号是360×180×750,其中750 是帧率为50 fps 的15 s 的视频帧数。一个视频的平均处理时间为237 s,其中快速傅立叶变换、形态学去噪处理模块、微振动增强模块的运行时间分别为50 s,14 s和173 s。
2.3 消融实验
2.3.1 呼吸率区间的影响
在本文的检测框架里,主要估计了数据集的伪装人体的呼吸率区间。为了证明使用估计的呼吸率比使用经验值效果好,本文改变呼吸率的值做了3组实验,见表1。当k=1时,使用估计的呼吸率比经验值有更好的检测效果,这是因为估计的呼吸率比经验值更好的符合数据集中伪装人体的呼吸率。相比之下,IOU提高了0.143,Precision提高了0.141。当k等于其它值,例如k=2,检测效果反而下降。通过实验,认定k=1时估计的呼吸率最好。其它的实验也使用了k=1 的呼吸率区间。

表1 不同呼吸率区间的影响Tab.1 The effect of different breathing rate respiration rate interval
2.3.2 视频微振动增强的影响
为了分析微振动增强对不同距离的人体检测的影响,本文分别在微振动不增强视频和微振动增强视频的两种情况下,验证了10 m、20 m、30 m 的检测结果,见表2,部分视觉检测效果如图7 所示。可以发现,在没有增强的视频中,对于20 m 和30 m 的较远的目标,检测的IOU和Precision都比10 m的要低;在增强的视频中,对于20 m、30 m 的目标,检测准确性大大提高,整体上IOU提高了0.24,Precision提高了0.278。可以得出一个结论,微振动增强有助于检测出20 m 远的小尺度目标。

表2 微振动增强对检测结果的影响Tab.2 The effect of micro-vibration enhancement

图7 微振动增强对检测结果的影响Fig.7 The effect of micro-vibration enhancement
2.3.3 不同模块的影响
为了验证本文的检测框架中微振动增强、幅值估计模块、形态学去噪3 个模块对伪装人体检测准确性的效益,本文设计了模块的消融实验,实验的结果见表3。从本文方法1 与基线方法比较可知,视频放大模块对检测结果提升明显,IOU提升了0.102,Precision提升了0.120;本文方法2 与基线方法比较可知,视频放大模块结合幅值估计模块可以大幅度提升检测的效果,IOU提升了0.183、Precision提升了0.194。因为对放大的视频使用快速傅里叶变换求各像素的振动频率时,在非振动区域中得到的频谱去除了一些没有明显波峰的数据,使得估计的像素振动频率更准确;本文方法3 与本文方法2 比较,形态学去噪模块对于提升检测效果也有一定的作用,IOU提升了0.057,Precision提升了0.084。形态学去噪模块之所以有作用,是因为其对初步的检测结果消除了零散的噪声,并填补了结果的空洞。
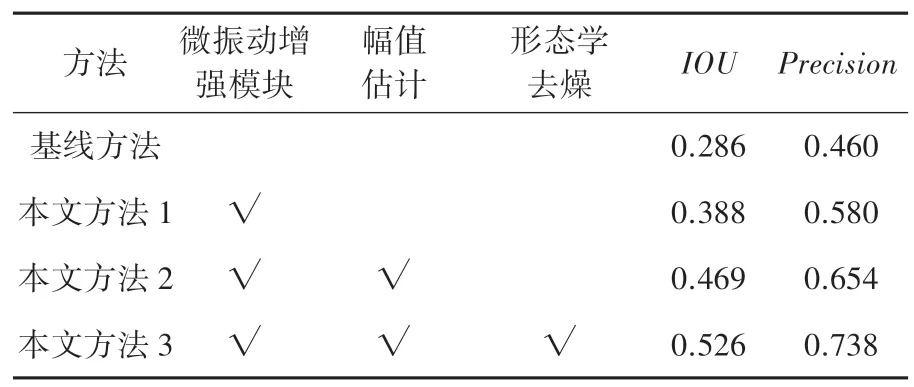
表3 不同模块的影响Tab.3 The effect of different modules
2.4 对比实验
为了证明本文的算法有效,还实现了基于梯度特征的检测方法、基于纹理特征的检测方法、基于深度特征的检测方法,并与其检测效果进行了比较,这几个算法分别是梯度特征、纹理特征、深度特征等不同特征的先进方法。由于这几个研究或是没有公开其数据集,或是其数据集不适用于本文的算法,为了比较更加公平,把这些算法用在本文的数据集上进行测试。这几种检测方法的输入数据是图像,因此把所有验证视频的第一帧作为其输入数据。检测结果见表4,本文算法的检测准确性是最高的,IOU达到0.526,Precision达到了0.738。
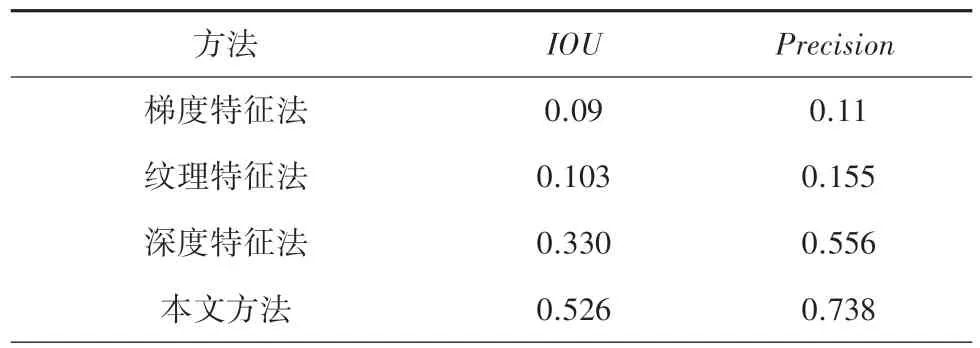
表4 对比实验结果Tab.4 Comparison of the detection results
部分检测效果如图8 所示。可以看出,本文的检测算法效果比较清晰,可以较好的保持伪装人体目标的外形和边缘轮廓,具有较高辨认度。这是因为本文增强并提取的是伪装人体目标的微小振动特征,由人体目标的呼吸而产生,与人的呼吸一样具有内在稳定性,不受背景中纹理、阴影、颜色深浅的影响,较梯度特征法、纹理特征法具有更好的抗噪声能力。本文使用视频训练集估计出伪装人体的振动频率区间,得到的结果可视为先验知识,在未知场景中同样适用,较深度特征法是更普遍通用的伪装人体检测框架。梯度特征法只是定位出一个目标点,检测准确性比较低,会将图像中纹理的边缘错检测成伪装人体。纹理特征法的检测准确率也很低,并且检测出来比较暗淡模糊,无法辨识伪装目标。深度特征法虽然善于检测正常的图像,但是不擅长检测有遮挡的伪装人体,通常将背景的物体错误检测成伪装目标。

图8 对比实验检测效果Fig.8 Comparison of detection results
3 结束语
本文针对颜色或亮度特征、纹理特征、梯度特征、深度特征等视觉表层特征无法有效检测出没有明显移动的伪装人体目标,提出了基于增强的微振动特征实现伪装人体检测的算法。在训练集上估计伪装人体目标的最优的呼吸率区间,并通过放大振动的相位信息来增强视频中伪装人体的微振动,根据增强的微振动视频和提出的检测模型实现伪装人体目标的定位检测,并通过图像形态学去噪后处理以降低检测结果的噪声。通过一系列的消融实验和对比实验,在提出的数据集上证明了本文检测算法的先进性。与其它检测特征的算法相比,本文算法可以在高光、深色、纹理不平坦等复杂背景中检测出没有明显移动的伪装人体目标。
猜你喜欢
建材发展导向(2022年3期)2022-04-19
考试与评价·高一版(2020年6期)2020-11-02
天天爱科学(2020年6期)2020-09-10
中学数学杂志(高中版)(2017年5期)2017-10-09
读者·校园版(2016年14期)2016-07-07
股市动态分析(2015年16期)2015-09-10
环球时报(2010-02-11)2010-02-11
数字家庭(2009年3期)2009-06-23
中学理科·综合版(2008年9期)2008-10-15
中学理科·综合版(2008年4期)2008-07-15
