
基于BP神经网络的重油催化裂解模型
2021-12-14 05:53王志宏龚剑洪魏晓丽
石油炼制与化工 2021年12期
王志宏,龚剑洪,魏晓丽,首 时
(中国石化石油化工科学研究院,北京 100083)
目前,我国炼油产能严重过剩,油品结构不尽合理,而化工产能(尤其是高端产品产能)不足,炼油企业的结构转型升级是实现我国炼化行业绿色、低碳、可持续发展的必然选择。催化裂解技术作为油品与化工品的桥梁必将成为炼化一体化的核心部分。
为了指导催化裂解装置操作和工艺优化,研究人员进行了大量的试验研究,并建立了催化裂解集总动力学模型,描述重油催化裂解的内在化学反应规律,以期预测各种工艺参数和原油组成变化对应的产物产率变化[1]。但是,催化裂解过程的原料组成与反应体系非常复杂,依靠集总理论建立的机理模型基于一些理想化的假设,不能完全模拟出工业过程中的不确定性和干扰因素,而这些不确定性和干扰因素会降低机理模型的预测精度。
神经网络作为智能建模方法的代表,区别于以往的机理模型,具有强大的非线性拟合能力、并行信息处理能力和自学习能力,在催化裂解过程的动力学模拟中得到越来越多的应用。神经网络可以用于生产过程中工艺参数控制、数据收集与筛查、结果预测等方面[2],并表现出了巨大的潜力。Serrano等[3]利用神经网络预测生物质在流化床反应器中气化生成焦油的过程,发现预测结果准确性良好;崔阳等[4]发现BP神经网络对煤催化气化过程的预测效果优于回归公式方法;Keyvanloo等[5]以神经网络结合遗传算法预测石脑油热裂解的主要产品收率,提高了预测精度。目前,虽然神经网络方法在炼化过程的预测方面应用广泛,但鲜有将其应用在重油催化裂解领域的研究报道。
本研究基于实验室中重油催化裂解过程数据,构建基于BP神经网络的重油催化裂解产物产率预测模型,通过对不同重质原料、不同工艺参数、不同活性催化剂条件下重油催化裂解产物产率的数据进行训练,优化了预测模型的网络结构及算法,验证了其预测的准确性,以期为重油催化裂解新工艺研发、工程方案优化设计和工业装置优化操作等提供指导。
1 BP神经网络
BP神经网络以适当的数据样本集为基础,在输入变量和输出变量之间建立关联[6]。网络以实际输出值和期望输出值之间的均方误差为判据,调整神经网络的权值、阈值,最终使均方误差达到预期。一般BP神经网络由输入层、隐含层和输出层组成,其学习过程包括输入信息的正向传递和误差信息的反向传递两个过程,如图1所示。由图1可知,输入信息从输入层进入后,经过隐含层变换传递到输出层,计算均方误差。如果均方误差值超过要求,则误差开始反向传递,经过隐含层传向输入层。然后,调整输入变量参数进行再次训练,经多次训练后使均方误差达到要求。
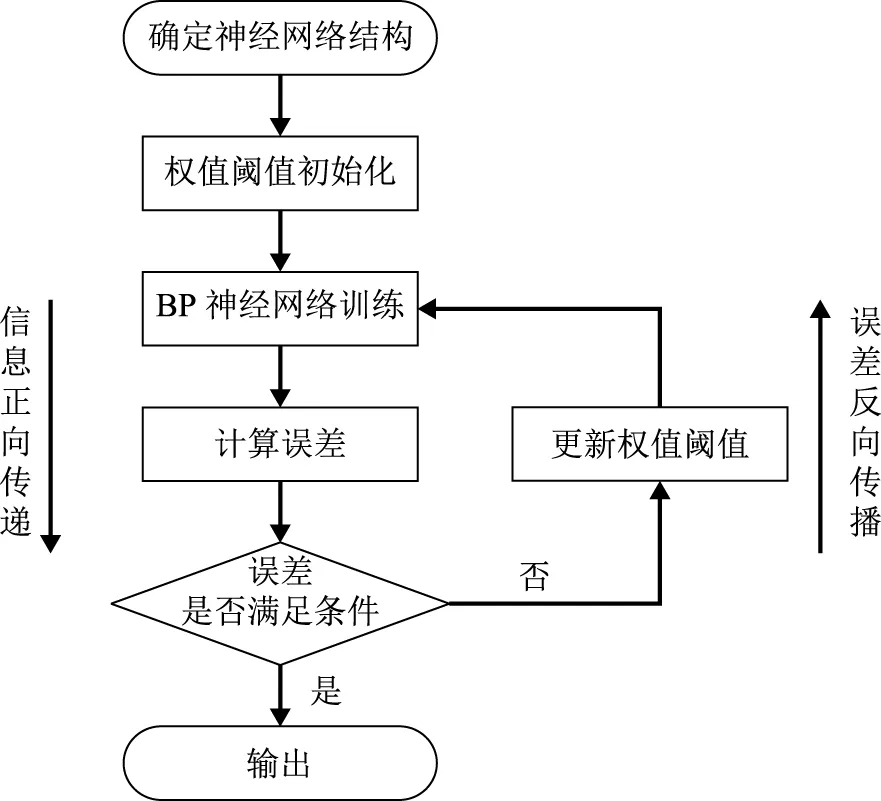
图1 BP神经网络训练过程示意
2 模型的建立
2.1 数据收集
构建模型的数据为小型固定流化床装置上重油催化裂解的试验数据,该装置由中国石化石油化工科学研究院自行设计制造,其原料为典型的重油催化裂解原料,催化剂为工业用催化剂DMMC-2。部分原料油的主要性质如表1所示。

表1 部分原料油的主要性质
在保证模拟效果的前提下,神经网络模型输入变量的维数应尽可能小。由采用Pearson相关系数法对催化裂解原料油性质特征间的相关性分析[7]可知,原料油性质特征数间相关性较高时会造成不同性质特征间相互影响。因此,神经网络模型的输入变量应选择原料油性质中相关性较小的特征。通过对催化裂解原料油性质特征的相关性分析,选择密度(ρ)、残炭(CR)、氢质量分数(wH)、饱和烃质量分数(wSH)、(胶质+沥青质)质量分数(wRH)、镍质量分数(wNi)、钒质量分数(wV)等原料油性质特征作为输入变量;并选择催化裂解工艺中常用的关键操作参数反应温度(T)、剂油质量比(mC/mO)、水蒸气与原料质量比(mW/mO)、催化剂微反活性(MR)作为输入变量;乙烯、丙烯、BTX(苯、甲苯、二甲苯)的产率作为输出变量。综上所述,本研究中神经网络的输入变量共11个,包括7个原料油性质和4个操作参数,输出变量为3个主要产物的产率。通过试验共采集91组数据样本,将数据样本进行随机分类,其中70组数据样本归入训练集,12组数据样本归入验证集,另外9组数据样本用于检验模型的预测性能。
2.2 数据归一化
数据归一化是指通过运算将不同范围的有量纲的数据经过变换转变为无量纲的数据,并映射到固定范围(例如0~1或-1~1等)中,从而避免大数值数据将小数值数据的影响掩盖,同时解决因数据变化范围特别大而导致神经网络收敛慢、训练时间长的问题,使数据落在激活函数的敏感区域内[8]。数据归一化计算式如式(1)所示。
(1)
式中:xi为原始数据,x′i为xi归一化的数据,xmin为原始数据中的最小值,xmax为原始数据中的最大值。
2.3 神经网络结构的优化
确定BP神经网络结构的关键是选择合适的隐含层节点数。隐含层节点数选取过大,会导致网络结构过于复杂,可能出现过拟合,网络的容错性和泛化能力变差、对信息的处理能力降低;隐含层节点数选取过小,会导致网络结构过于简单,输入信息不能被网络充分学习,进而影响训练效果[9]。隐含层节点数计算式见式(2)。
(2)
式中:H为隐含层节点数;m为输入变量数;n为输出变量数;L为1~10的常数。
为选择合适的神经网络结构,采用试错法探究隐含层节点数为4~14时BP神经网络模型的拟合效果,如表2所示。良好神经网络的拟合相关度应尽可能大,均方误差应尽可能小。由表2可知,当隐含层节点数为12时,验证集数据的相关系数(R)最大,为0.919 87,均方误差最小,在20 000次迭代后达到0.006 849。因此,构建BP神经网络模型的输入层、隐含层和输出层节点数分别为11,12,3,其结构为11-12-3。
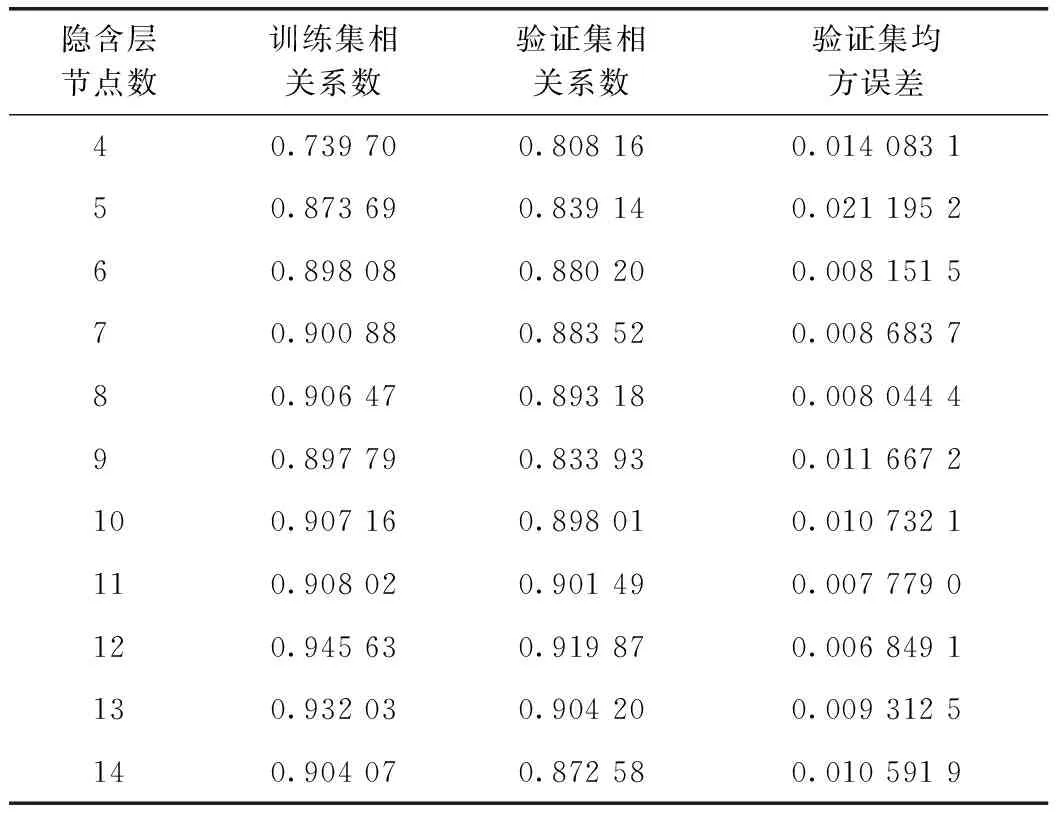
表2 不同隐含层节点数BP神经网络的拟合效果
2.4 算法的优化
BP神经网络的梯度下降法收敛速率低、易陷入局部极小点,因此需用其他学习算法改善其运算性能。可以选用的算法有L-M算法(Trainlm)、共轭梯度法(Trainscg)、拟牛顿法(Trainbfg)、贝叶斯法(Trainbr)、自适应学习率的梯度下降法(Traingda)、带动量的梯度下降法(Traingdm)、带动量的自适应梯度下降法(Traingdx)等共7种。表3为采用不同学习算法的BP神经网络拟合效果。由表3可知,选用贝叶斯算法的BP神经网络性能最好,验证集数据的相关系数最大,为0.967 08,均方误差最小,在17次迭代后为0.002 497 8。因此,构建BP神经网络模型优选贝叶斯算法。

表3 采用不同学习算法的BP神经网络拟合效果
因此,本研究基于BP神经网络构建的重油催化裂解预测模型的结构为11-12-3,模型采用数据归一化方法提高网络收敛速率、缩短训练时间,并用贝叶斯算法优化了其运算性能。表4为优化前后BP神经网络模型的性能。由表4可知,与优化前相比,优化后的BP神经网络迭代次数由20 000次降为17次,训练集数据和验证集数据的拟合相关系数分别提升了0.241 55和0.158 92,验证集的均方误差减小了0.011 585 3。这表明,通过对模型网络结构和学习算法优化后,BP神经网络的相关性增强,均方误差大幅下降,网络模型的收敛速率提高,训练效果良好,预测结果更加接近真实值。

表4 优化前后BP神经网络模型性能
3 模型的预测性能
3.1 模型的训练效果
图2为优化后BP神经网络模型对输出变量(乙烯、丙烯和BTX的产率)的预测值与其实际试验值的关系。由图2可知,该BP神经网络模型训练集的预测值与实际试验值的相关系数为0.981 25,验证集的预测值与实际试验值的相关系数为0.967 08,均接近1,数据均匀分布在Y=X线(图中虚线)两侧,说明神经网络模型的预测值与试验值偏差很小,网络模型的训练效果良好。
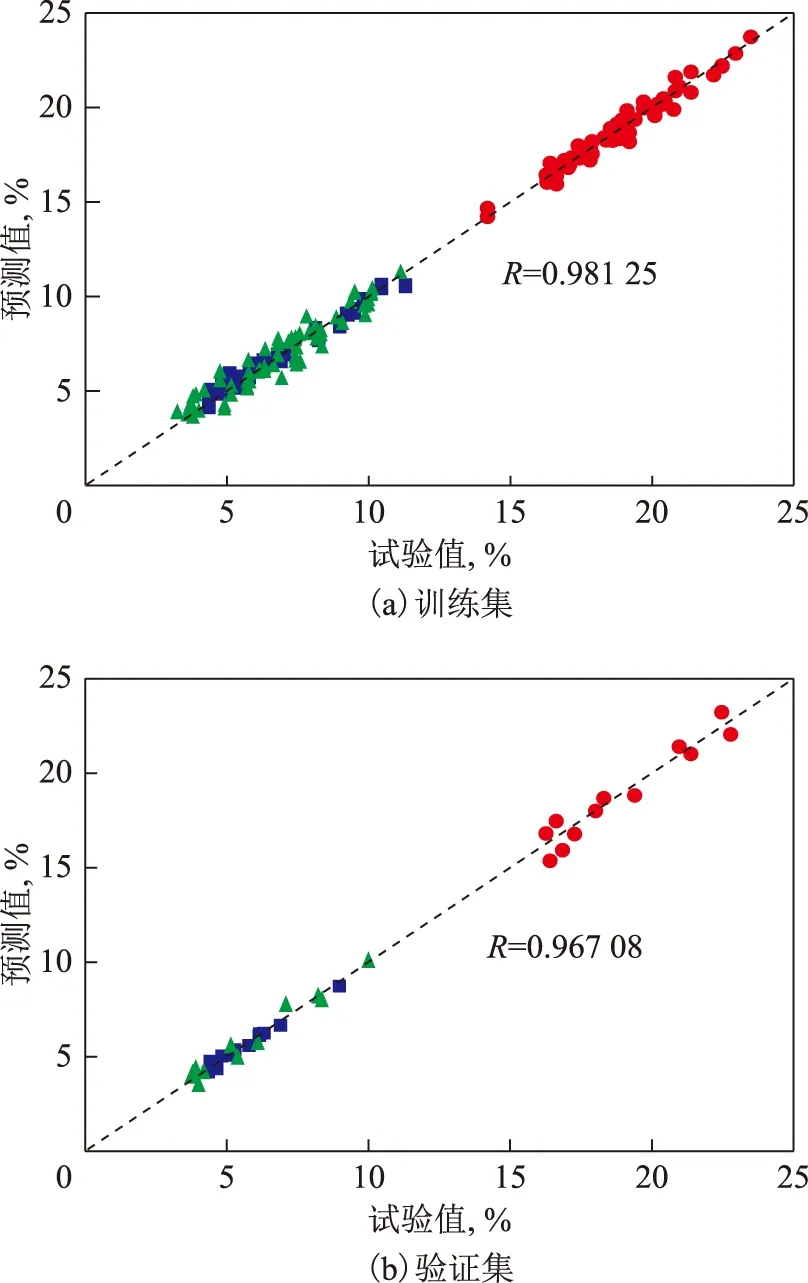
图2 优化后BP神经网络试验值与预测值的关系■—乙烯产率; ●—丙烯产率; ▲—BTX产率
3.2 模型的预测性能
利用构建的BP神经网络重油催化裂解预测模型,对另外9组试验数据进行模拟预测,并与试验值进行比较,结果如表5所示。由表5可知:该模型对乙烯、丙烯、BTX产率预测结果与试验结果的相对误差均在10%以内;经过计算,其平均相对误差分别为4.59%,3.92%,2.28%。表明构建的BP神经网络模型对重油催化裂解产物产率的预测效果良好,具有较好的实用价值。

表5 优化后BP神经网络重油催化裂解模型预测值与试验值的对比
4 结 论
以对重油催化裂解反应影响较大的11个参数作为输入变量,以乙烯、丙烯、BTX的产率作为输出变量,在网络结构和学习算法优化的基础上成功建立了结构为11-12-3、以贝叶斯法作为学习算法的重油催化裂解BP神经网络模型。
利用优化后的BP神经网络模型预测重油催化裂解产物乙烯、丙烯、BTX的产率,其平均相对误差分别为4.59%,3.92%,2.28%。表明建立的重油催化裂解预测模型对反应产物产率的预测效果良好,可以为重油催化裂解过程模拟优化提供技术支持。
猜你喜欢
能源化工(2021年6期)2021-12-30
科技风(2021年19期)2021-09-07
能源工程(2021年1期)2021-04-13
石油炼制与化工(2020年9期)2020-09-10
石油炼制与化工(2020年7期)2020-07-08
今日中国·法文版(2020年7期)2020-07-04
船舶标准化工程师(2020年1期)2020-06-12
中国化工贸易·中旬刊(2018年8期)2018-10-21
火工品(2017年6期)2017-02-01
哈尔滨理工大学学报(2016年3期)2016-11-05
