
基于优化YOLOv4 的主要电气设备智能检测及调参策略
2021-12-13 07:32律方成牛雷雷王胜辉王子豪
电工技术学报 2021年22期
律方成 牛雷雷 王胜辉 谢 庆 王子豪
(1. 新能源电力系统国家重点实验室(华北电力大学) 北京 102206 2. 河北省输变电设备安全防御重点实验室(华北电力大学) 保定 071003)
0 引言
绝缘子、金具等是电网输变电设备的重要组成部分,及时掌握其绝缘水平和运行状态对电力系统的安全稳定运行至关重要[1]。目前电网主要采用的人工巡检方式耗时费力,且无法及时全面地掌握主要电气设备的外绝缘状态[2]。基于无人机和巡检机器人搭载的可见光、紫外和红外图像信息是高压设备热、电参量非接触检测的重要手段和发展趋势,而绝缘子等主要电气设备的识别是对其进行综合诊断以实现其绝缘状态判别的基础[3]。
实现绝缘子等高压设备图像识别思路主要有机器学习方式和深度学习方式。前者主要针对电气设备的形状和纹理特征进行设计,优点为针对性强、特征具有可解释性,缺点为检测鲁棒性差,对目标的拍摄角度等要求较高[3];后者通过卷积算法自动提取目标抽象化特征,实现端到端图像识别,其识别精度高,泛化能力好,识别速度快,但对样本需求量大,可解释性差[4]。随着无人机和机器人巡检方式的推广,现场将产生大量高压设备检测视频和图片,基于此,本文采用了深度学习方式。
深度学习的概念是在由G. E. Hinton 等2006 年提出的非监督贪心逐层训练算法的基础上[5],融合了卷积计算、神经网络框架、下采样和自动提取及匹配网络特征的端到端有监督学习框架。常用的深度学习框架包括以LeNet,Faster R-CNN(Region-Convolution Neural Network),SSD(Single Shot MultiBox Detector)和YOLO(You Only Look Once)为代表的深度卷积神经网络及以长短期记忆网络(Long Short-Term Memory, LSTM),GRU(Gated Recurrent Unit)为代表的循环卷积神经网络[6]等,其在电气领域的应用研究主要包括:①利用电力系统运行数据实现其调度预测[7]、调度控制[8]、稳定性评估[9]。例如:文献[7]以100%消纳光伏发电为前提,提出采用周期衰减学习率的改进型深度确定性策略梯度算法(CDLR-DDPG)的光伏-抽水蓄能互补发电系统的实时智能调度方法。②利用计算机视觉、结构化和非结构化文本,实现电力系统和电气设备状态预测[10]、缺陷识别与故障诊断[11]、自然语言处理[12];例如:文献[11]基于Faster R-CNN 算法对变压器、套管等变电设备进行目标检测,基于温度阈值判别法对设备区域进行缺陷识别。检测平均精度均值达到90.61%。文献[13]提出了一种基于改进LSTM 的短期高压负荷电流预测方法。该模型在时间序列方面引入自循环权重,使细胞彼此循环连接,从而动态改变时间尺度,进而增强长短期记忆功能。
对图像识别主要采用深度卷积神经网络[4]。相比于Faster R-CNN,YOLO 在2015 年由美国华盛顿大学提出。同属图像识别state-of-art 检测框架,YOLO 采用无候选区域的类别和坐标one-stage 检测思路,具有较高的识别准确度和更高的识别速度[14],可实现对无人机和机器人巡检产生的图像的实时、整体识别。其在电力系统的应用方面,文献[15]采用YOLOv3 算法,通过调整学习率等超参数,实现了模型的快速收敛,平均识别准确率为88.7%,可结合紫外光路实现绝缘子的智能诊断。文献[16]探究了随机旋转角度、饱和度、曝光度、色调等预处理红外成像数据,研究了基于YOLOv3 算法的绝缘子红外图像故障检测方法。以上研究主要基于YOLOv3 或更早版本,关于网络参数对训练误差和识别准确度的影响的研究较少。
为了对外绝缘设备的绝缘状态进行智能诊断,本文对YOLOv4 网络框架进行了研究,建立了绝缘子、均压环、防振锤、套管和导线训练和测试数据库,研究了数据扩充算法、锚框及其聚类中心对其训练和识别性能的影响。主要工作包括:采用表征训练误差、识别准确度和训练速度的系统性能评价体系,分析了YOLOv4 检测框架及网络框架,研究并改进了 Mosaic 数据扩充算法,研究了交并比(Intersection over Union, IoU)算法对不同尺度检测目标的边界框预测有效性,以及自建数据库的宽高数据标注值聚类对检测结果及其评价参数的影响,优化了YOLOv4 的网络,提出基于IoU 和识别准确度的网络调参方法,最终较好地实现了主要电气设备的识别。
1 YOLOv4 模型
1.1 网络框架
YOLOv4 的其运行检测流程及网络框架构成如图1 和图2 所示。
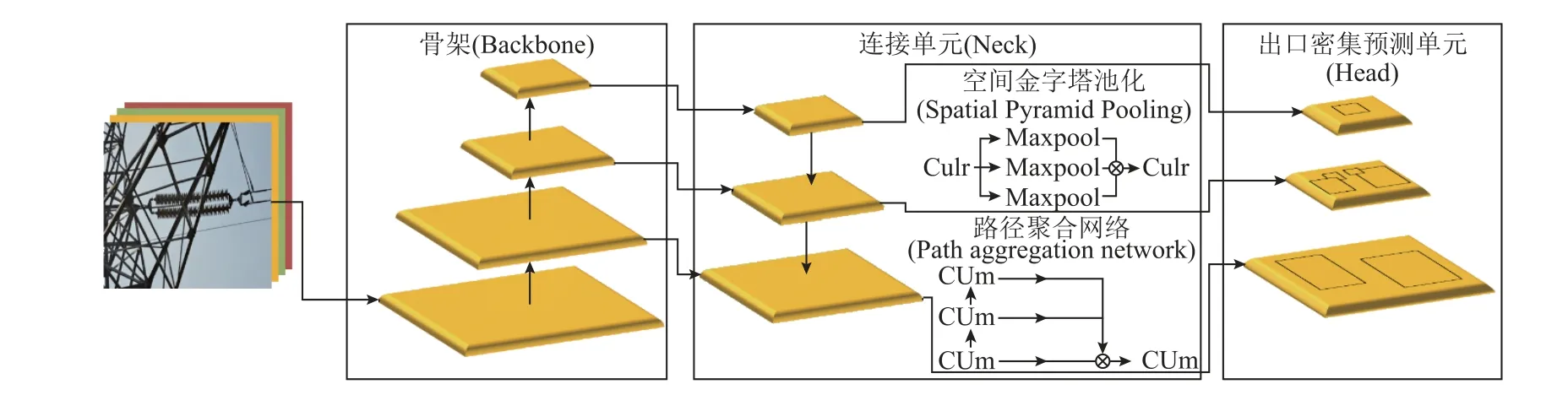
图1 One stage 检测流程Fig.1 Inspection of one stage method
图2 YOLOv4 网络框架Fig.2 Network architecture of YOLOv4
首先,图片被打包输入骨架(Backbone)部分进行卷积计算,Backbone 的卷积网络以Darknet53为检测框架,将图片分辨率由416×416×3 卷积、下采样至13×13×1 024。Backbone 网络包含29 个卷积层堆叠而成的5 组NDC(dropout connect)单元,其网络权重参数经过了Imagenet 的预训练,是图片特征提取的主体和性能良好的分类器,如图1 和图2 的Backbone 部分所示。
其次,进入以空间金字塔池化(Spatial Pyramid Pooling, SPP)和路径聚合网络(Path Aggregation Network, PAN)为特征的Neck 框架,两者可增加图像训练和检测过程中特征提取单元的感受视野,将不同通道数据进行拼接(Concatenation),提取最重要的、不同路径特征[14],经过两个上采样单元形成26×26 和52×52 两个分辨率,同Backbone 的13×13输出,形成的三个不同尺度的中间检测单元,如图1 和图2 的Neck 部分所示。
最后,将Neck 输出的三种分辨率送入Head 部分,如图1 和图2 所示。作为类别和边界框同时预测的one-stage 预测框架,Head 部分采用YOLOv3结构,进行基于每个锚框产生多组输出变量的高密度目标检测[14]:生成锚框并分别预测其类别和边界框偏移量得到预测边界框。训练过程中,利用预测值与真实值的IoU 进行非极大值抑制,筛除无效预测边界框,并给出优化结果。
图2 中,可将网络的卷积单元由卷积计算C、批均一化U 和激活函数(mish、leaky RELU 和Linear)三部分组成,根据采用的激活函数不同可分为CUm、CUlr 和CUl 三类。
Backbone 采用CUm[17],mish 激活函数表达式为
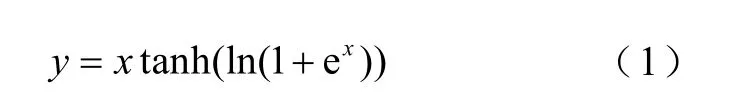
两个CUm 卷积单元通过Shortcut 层相加连接可构成一个残差单元RU,N个残差单元经过route层构成组dropout connect 单元NDC。
中间框架采用leaky-RELU 作为激活函数,其计算式为

网络的出口处的卷积层采用Linear 函数y=x作为激活函数,其作用是将网络的输出统一为T×T×255,其中T表示网络的三个检测尺度。
1.2 锚框和边界框
训练集中,将每一个锚框(anchor box)看作一个训练样本,需要为其标注锚框类别和锚框偏移量两个标签,而在测试阶段顺序为:生成锚框;预测每个锚框类别和偏移量;基于非极大值抑制筛选预测边界框(bounding box)[18]。

图 3 展示了锚框和真实边界框的匹配标注过程。在图3 中,矩阵H中最大元素h23所在的行和列为i1=2,j1=3 ,则为将锚框2A标注为3B,同时,将H中第2 行、第3 列元素置零。继续找出H中最大的元素h61所在的行和列i2=6,j2=1,将锚框6A标注为1B,将H中第6 行、第1 列元素置零,依次找出h33和h84,并为对应锚框标注边界框,接下来只需遍历h14、h34、h54和h74并根据其IoU 值决定是否为剩余的锚框分配边界框。

图3 锚框与真实边界框Fig.3 Anchor boxes and the bounding boxes
在训练过程中,锚框A被标注为边界框B,则将B的类别赋予A,假设A和B的中心坐标、宽和高分别为(xa,ya,wa,ha)和(xb,yb,wb,hb),则A的偏移量计算公式为[18]

式中,Bgt表示真实标注框,但IoU-loss 只在两个边界框有交叉时才有效,基于此,文献[19]提出增加了惩罚项的GIoU-loss,即
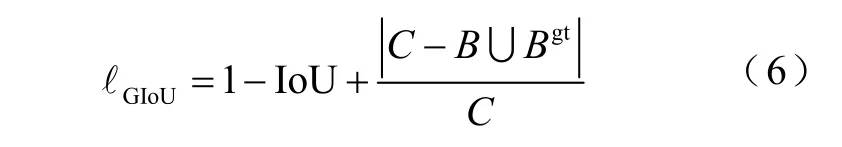
式中,C为包含了B和Bgt的最小框。
当B和Bgt位于水平或垂直位置时,GIoU-loss依然具有很大的误差,文献[20]将重合面积、边界框中心坐标之间的距离和边界框的宽高比加入惩罚项,提出了DIoU-loss 和CIoU-loss,分别为

1.3 数据增强
1.3.1 Cutmix
Cutmix[21]在Cutout[22]的基础上进行了改进,融合两张图片的特征,其计算式分别为
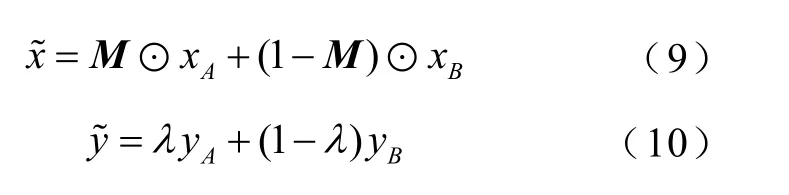
式中,M为二进制0、1 矩阵;⊙表示从两个图像中删除并填充的位置;λ为Beta(τ,τ)贝塔分布,τ为超参数。经过Cutmix 扩充处理前后的效果如图4所示。

图4 Cutmix 数据扩充Fig. 4 Cutmix data augment
1.3.2 改进Mosaic
Mosaic[14]在Cutmix 的基础上,将融合的图片特征数量增加为4 张,等效增加了训练批次的图片数量,提高检测性能。本文对Mosaic 进行了改进,在图像融合过程中加入基于Mixup[23]的背景虚化,改进后的计算式为

式中,Mi分别为第i个二进制0-1 矩阵,其并集为整张图片(Σ∪Mi=Ω);μ、iλ为透明度调整系数,服从贝塔分布。经过改进Mosaic 扩充处理的数据效果如图5 所示。

图5 改进Mosaic 数据扩充Fig.5 Refined mosaic data augment
1.4 训练集宽高数据的K-means 和分层聚类
YOLOv4 采用K-means 聚类算法,基于VOC 数据库进行聚类中心数量为9 的label 宽高比聚类。K-means 是迭代求解的聚类分析算法,其步骤为:首先将数据分为k组并随机选取初始聚类中心;其次,计算每个数据点与各聚类中心之间的距离,并将其分配给距离最近的聚类中心所在的组[24]。优化迭代因子为

式中,xn为数据点;n为数据点个数;rnk在数据点xn被归类到组k时为1,否则为0;μk为归类到组别k中的数据点的平均值。
为对比分析K-means 聚类和可指定聚类中心的其他聚类方法的聚类效果,研究锚框聚类结果对网络性能的影响,并从整体上评价两者的检测表现,本文引入了分层聚类算法。分层聚类以树形结构在不同层次上对数据集进行自下而上的划分,其步骤为:首先将每个样本看作初始聚类簇;其次通过计算集合间的豪斯多夫距离,将距离较近的聚类簇合并;最终得到预设的聚类个数[24]。
图6 展示了标注样本的宽高原始数据及其聚类数据。图6a 为样本的原始宽高数据,不同颜色代表了不同高压设备类别。基于自建数据库,K-means 的K值和分层聚类簇群数均设为5。图6b 为K-means聚类效果,算法以点到聚类中心的距离为分类标准,5 个聚类中心近似沿直线y=x轴对称分布;图6c 为5 类聚类树状图,可看出簇类层次,如当簇群数为3时,原簇类沿树状图合并为A、B 和C 三个新簇群;图6d 为分层聚类效果,算法以簇类之间的距离为分类标准,除簇类1 和簇类5,其余簇类的分布与Kmeans 基本相同,聚类中心分布没有明显的规律。

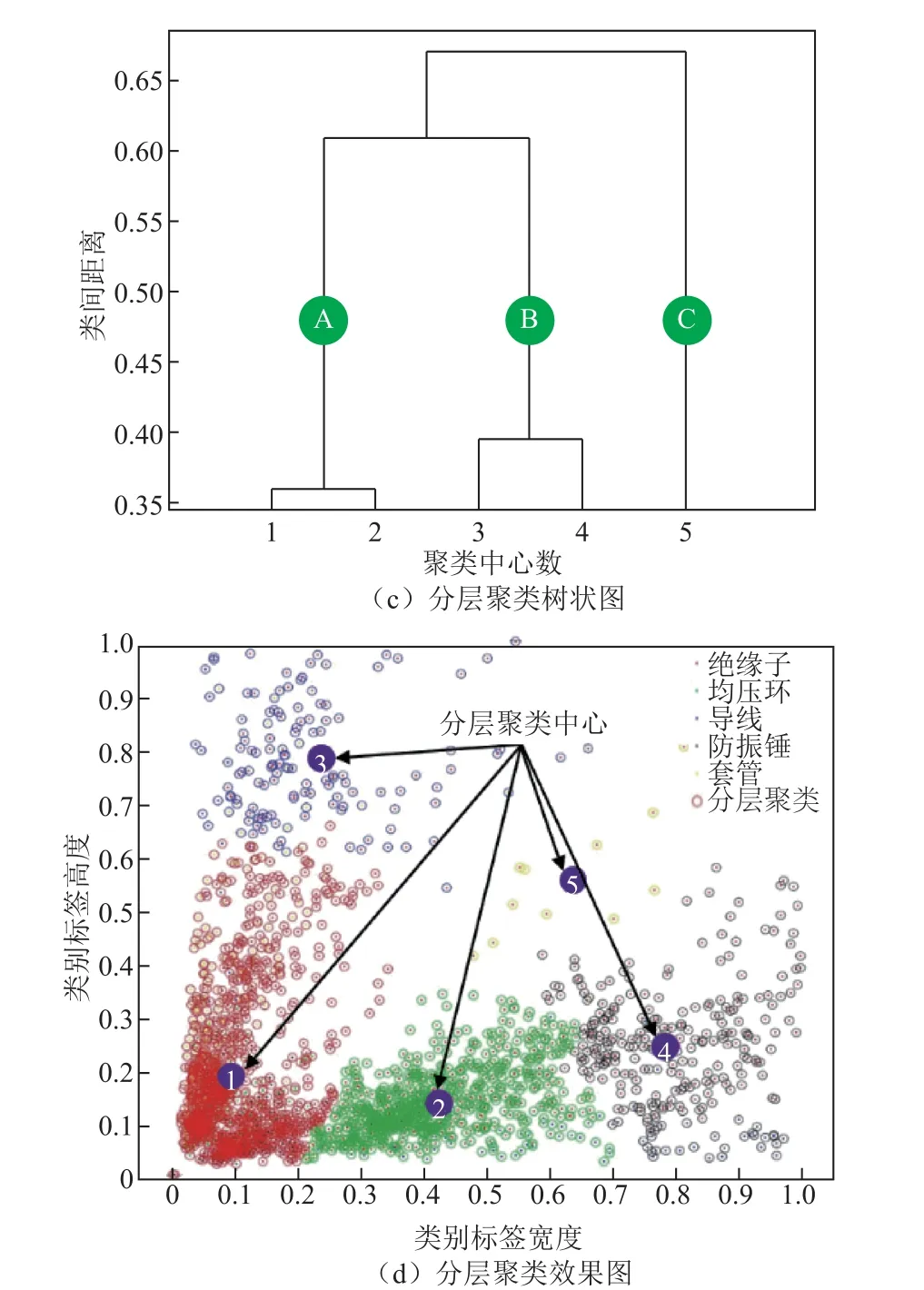
图6 数据标签及其聚类Fig.6 Label and cluster
2 试验及性能评价体系
以 Linux 系统下的 darknet 平台搭建了基于YOLOv4 的深度学习网络框架。训练服务器GPU 为Nvidia Quadro P600,CPU 为Intel silver 4210,训练集为在实验室和现场拍摄得到的绝缘子、均压环、防振锤、导线和套管五类图片2 800 张,测试集200张,每个类别的图片各占20%,部分训练集数据库如图7 所示。

图7 训练集数据库Fig.7 Train database
采用lableimg 标注训练集,生成包含电气设备类别、尺寸、位置信息的.xml 文件,再将其转换为包含中心坐标(x,y)和(w,h)偏置的.txt 标注文本[14]。
实验过程中,网络的迭代次数为8 000 次,采用YOLOv4 默认参数作为基准组,每次训练只改变一个超参数变量,研究变量包括数据增强算法(Cutmix、Mosaic 和改进Mosaic)、IoU(CIoU,GIoU和DIoU)、anchor 聚类中心个数(5、9 和YOLOv4)和聚类函数类型。
系统性能评价体系可表征训练误差、识别准确度和训练速度。采用avgLoss 和IoU 来表示系统训练的评价指标,采用真正例(True Positive, TP)、假正例(False Positive, FP)、假负例(False Negative,FN)作为网络的识别指标,其中TP 值越高,FP 和FN 值越小,网络的优化效果越好[24]。采用准确率(Precision), 平均准确率均值(mean average precision, mAP)和召回率(Recall)指标来表征系统检测准确性和鲁棒性,使用F1来度量网络的识别准确度与召回率均衡时的网络得分,即

式中,P和R分别为准确率和召回率。
将训练过程中每次迭代所需时间定义为 Avgspeed,单位为s,表征网络迭代速度。
3 网络优化方法研究
3.1 数据增强算法
图8 对比分析了Cutmix、Mosaic 和改进Mosaic数据增强方法对网络参数的影响。图9 展示了不同算法的平均网络损失与检测准确度和迭代次数的关系。
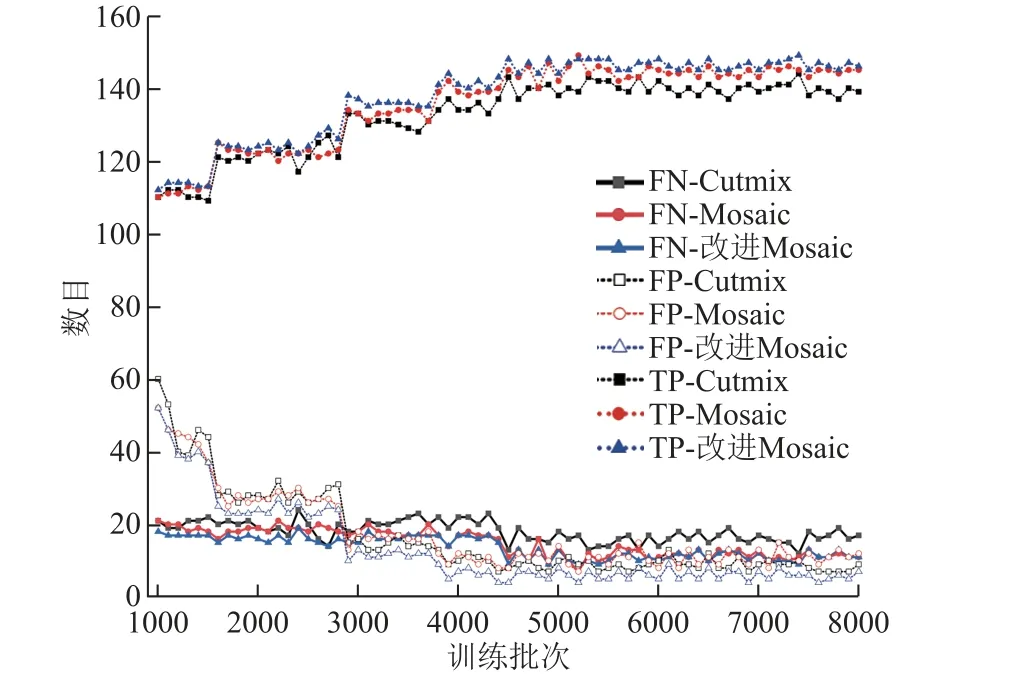
图8 数据增强方法与识别结果Fig.8 Data augment and detection results

图9 数据增强方法与损失准确度Fig.9 Data augment and network loss detection results
图8 中,在具有较低的FN 值的同时,改进Mosaic 的TP 表现明显高于Mosaic 和Cutmix,说明在相同训练条件下,采用改进Mosaic 数据扩充方式能够得到更高的Recall 和网络识别准确度;对比而言,改进Mosaic 和Cutmix 具有更小的FP 值。
因增加了融合图片数量,对比Cutmix,Mosaic和改进Mosaic 具有更好的网络性能,而改进Mosaic加入了模糊处理的原始尺寸图像,解决了的Mosaic FP 值较高的问题。
图9 中,平均损失(avgLoss)随着训练批次的增加而降低。相比而言,采用了Cutmix 的模型损失(loss)最小(0.185),7 000 次迭代之后的改进Mosaic模型的loss 减小到与前者相当(0.302),而Mosaic模型的loss 最大(1.011)。mAP 在训练过程中上下波动,但总体随训练批次增加而增加,其中,Cutmix的模型识别准确度最低(82.3%),相比于Mosaic 模型,改进Mosaic 模型的平均识别准确度提高了2%。其原因在于,Cutmix 算法主要对图片进行切割和嵌入,在不改变训练集图片分辨率的情况下降低了网络训练误差,但也因图片的嵌入降低了网络的识别准确度。Mosaic 算法将4 张训练集图片融合,等效增加每次训练图片数量,但减小了训练集图片的分辨率。改进Mosaic 在Mosaic 的基础上增加了Mixup的思想,在扩充数据集的基础上保持训练集的分辨率,相比于Mosaic,在相同迭代次数下的网络误差降低了约70%,识别准确度提高了2%。
3.2 IoU 算法的影响
IoU 是基于锚框和边界框回归算法的目标定位算法。图10 展示了网络采用不同IoU 算法时,训练批次(epoch)、平均网络损失(avg Loss)和学习率(learning rate)的变化曲线。
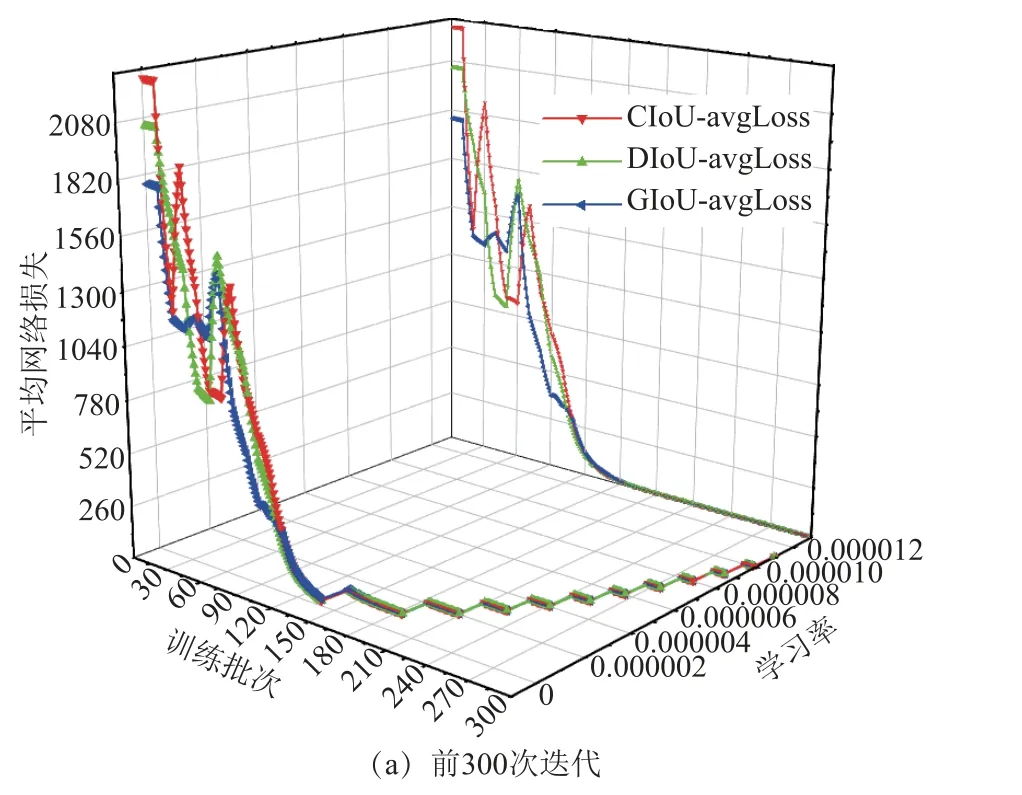
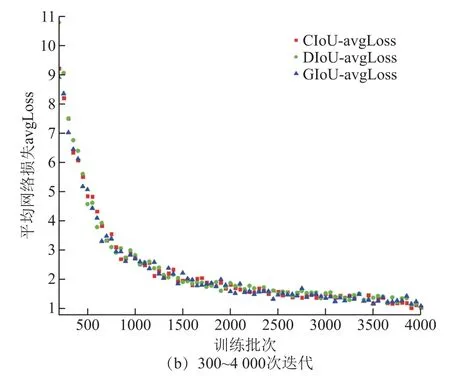
图10 不同IoU 的误差变化曲线Fig.10 Average loss of different IoU
在图10a 中,网络前300 次迭代训练采用的学习率逐渐增大,采用CIoU、DIoU 和GIoU 算法的网络,其训练误差首次小于10 所需的训练次数分别为188、212 和174。迭代训练前期,GIoU 算法的网络误差起始值小(1 775),收敛速度较快。
在图10b 中,网络的300~4 000 次迭代学习率为0.001 3。每迭代50 次,对CIoU、DIoU 和GIoU的网络误差值进行采样。在75 次采样中,其网络误差值为三者中最小的次数分别为28、14 和33,表明在迭代过程中,GIoU 整体表现较优。而在3 500迭代之后,CIoU 网络的训练误差均为最小,整体来看,CIoU 的效果较好。
图11 展示了网络采用CIoU、DIoU 和GIoU 时,在相同测试集上的识别准确度曲线。
图11a 中,网络mAP 随着迭代次数的增加而变化,整体呈提高趋势。采用CIoU、DIoU 和GIoU 算法网络的平均识别准确度标准差分别为 3.407、4.334 和4.722,CIoU 波动幅度较小,GIoU 网络具有mAP 最大值94.51%。

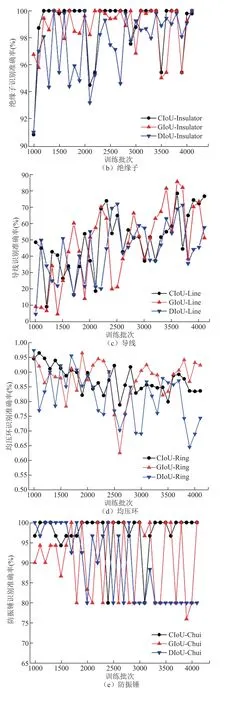
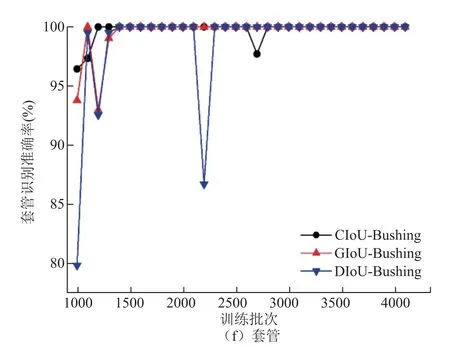
图11 不同IoU 的识别准确度曲线Fig.11 Average precision of different IoU
图11b~图11f 分别为绝缘子、导线、均压环、防振锤和套管五种电气设备的 IoU-50%识别准确度,CIoU 网络在绝缘子、防振锤和套管识别方面识别效果较好,而在如均压环的小目标识别上,GIoU网络的识别效果较好。表1 展示了采用不同IoU 算法识别的网络参数。

表1 检测准确性表Tab.1 Detection parameters of different IoU
从表1 中可以看出,采用CIoU 网络在识别准确度、召回率、F1得分和平均IoU 上具有较大优势,这得益于 CIoU 在锚框归类的训练过程中将传统IoU、中心坐标和宽高比作为最优化目标,使网络预测锚框更接近真实标注框。与此同时,DIoU 的网络训练速度最快,Avg-speed 为7.98s,这是因为CIoU和GIoU 网络增大了计算开销,降低了迭代的速度。
3.3 重新聚类label 宽高数据的影响
基于自建的五种主要电力设备图像数据库和K-means 与分层聚类算法,本文计算得到了label 宽高数据聚类中心坐标,图12 展示了不同聚类中心属性对网络训练和识别相关参数的影响。
图12a~图12d 中K=9 时的K-means 聚类中心的网络参数较YOLOv4 变差,原因是相比于VOC,自建数据库的类别和样本量较少。聚类中心K=5 时,网络Precision 和平均IoU 值与YOLOv4 的默认参数基本持平,但两者的标准差分别降低减至0.029 和5.44,优于 YOLOv4 情况。当网络迭代次数大于3 500 时,最优mAP 和召回率参数分别为94.37%和98%,虽波动较大,但最优结果比YOLOv4 的默认参数分别提高了0.3%和1%。
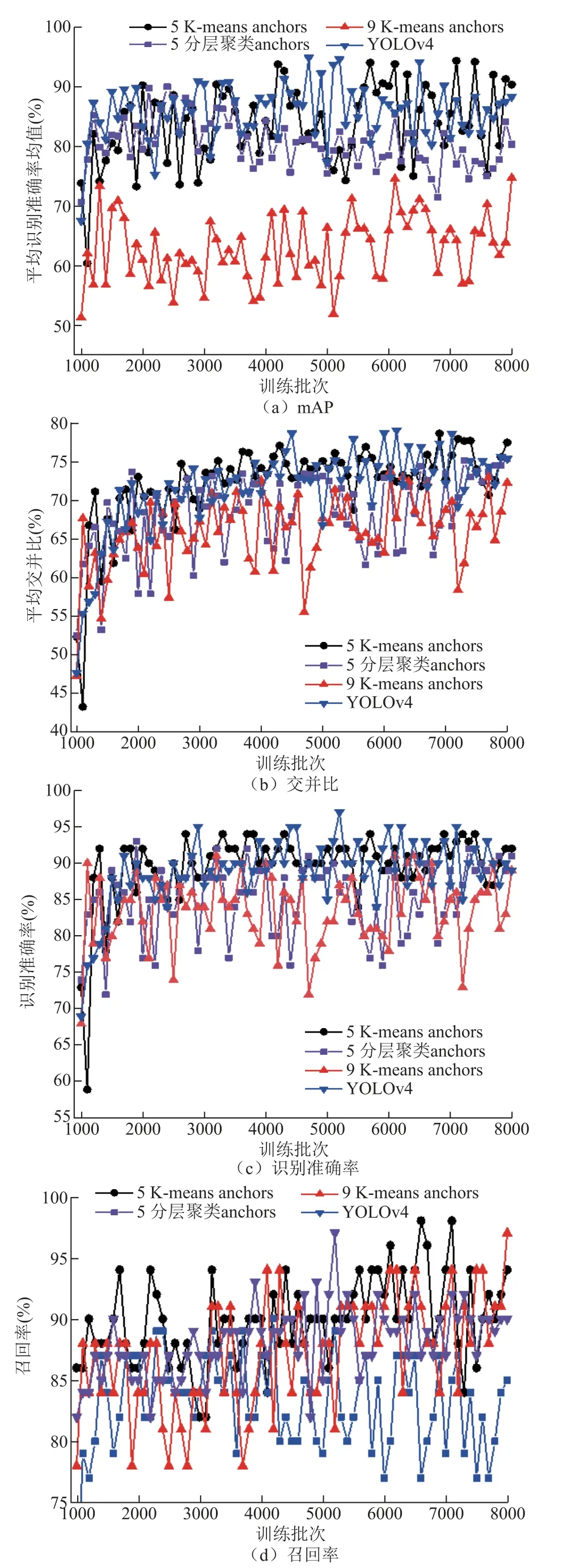
图12 不同label 宽高数据聚类的网络特性Fig.12 Network performance of label w-h data clusters
采用分层聚类的总体系统性能评价参数除mAP 外,IoU、召回率和识别准确率与K=9 时的Kmeans 聚类方法表现相当。其原因是K-means 分类是基于欧氏距离,各个聚类中心相互独立;而分层聚类基于簇类集合之间的距离逐级合并,簇类越少,聚类中心与簇内各点之间距离的波动越大,而导致网络提取五种设备特征的能力变差。
图13 展示了不同label 宽高数据聚类中心对网络训练误差和识别准确度的影响。

图13 不同label 宽高数据聚类中心的网络特性Fig.13 Loss-precision characteristic of different label w-h cluster algrithom
图13 中,采用K-means 算法且K=5、K=9 时,平均网络损失avg Loss 最小值相比于YOLOv4 分别减小了3%和4%。同时,K=5 时网络的识别Precision平均值为89.61%,相比于YOLOv4 提高了0.8%。原因是基于自建数据库聚类锚框进行训练时,网络的初始化和优化更加贴合原始标注数据,训练误差更小,识别准确度更高。
采用分层聚类算法且层数为5 时,网络avgLoss相比于 YOLOv4 减小了 73%,但网络的识别Precision 表现与K=9(K-means)相近,其原因在于,分层聚类的分类标准基于集合距离,导致较多电气设备图片聚类类别与实际类别不同,因此网络剔除了分类错误的图片而降低了损失函数,以降低网络的召回率的代价保持Precision 基本稳定。
表2 展示了基于不同聚类锚框对网络训练和识别性能的影响。
由表2 可知,采用K-means 算法且聚类中心个数K=5、K=9 时,网络的F1-score 较高,说明自建数据库的K-means 聚类在识别准确度和召回率均衡度上优于分层聚类和YOLOv4 默认参数。K=5 时,网络的最高召回率和准确率更高,各方面表现较为均衡。当分层聚类层数为5 时,以牺牲召回率的代价提高了系统损失和IoU 的总体表现,且检测速度较快。

表2 label 宽高数据聚类对网络性能的影响Tab.2 The influence of label w-h cluster on network performance
分层聚类网络的训练速度高于YOLOv4,其原因是分层聚类网络的召回率最低,等效于减少了每张图片中网络的目标数量,降低了计算复杂度。Kmeans 聚类算法训练速度低于YOLOv4 的原因除较高召回率之外,还包括因VOC 数据库预训练的权重数据与自建数据库数据结构不一致而增加的计算开销。
4 优化YOLOv4 识别结果
基于以上研究,本文采用了改进Mosaic 数据增强算法对训练数据集进行数据扩展;针对均压环和防振锤小目标的检测,采用GIoU-loss 作为IoU 分类函数,而对于绝缘子等较大检测目标,则采用CIoU 作为分类函数;基于自建数据库,采用K=5 的K-means 算法训练获得标注值宽高数据聚类中心,最终实现的主要电气设备识别效果如图14 所示。

图14 优化后网络的识别效果Fig.14 Detection results of the network after optimize
5 结论
本文基于YOLOv4,搭建了五种主要电气设备识别平台,提出了网络的改进方法,并对其调参方法进行了研究。主要结论如下:
1)对数据扩充算法进行了改进,优化后的网络训练误差由1.011 降低到了0.302,识别平均识别准确率提高了2%。
2)研究并分析了CIoU 和GIoU 方法在训练和识别大目标和小目标中的优劣势,对均压环和防振锤等相对较小目标采用了GIoU 的优化方法,使其平均识别准确率提高了3%。
3)提出了基于自建数据库识别类别和label 宽高数据的聚类思路,经过优化后的网络识别准确度提高了0.8%,训练误差减小了3%。
经过优化和参数调优,较好地实现了主要电气设备的识别。可用于基于无人机和巡检机器人搭载的多光谱成像检测。
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
建筑科技(2018年6期)2018-08-30
北京航空航天大学学报(2018年1期)2018-04-20
中国交通信息化(2016年5期)2016-06-06
电测与仪表(2016年18期)2016-04-11
