
基于数据挖掘模型的区域经济数据分析系统设计及应用
2021-12-13 13:04程童
湖北农业科学 2021年22期
程 童
(陕西警官职业学院基础部,西安710021)
区域经济作为国民经济的重要组成部分,是地区社会活动活力的主要体现[1]。由于区域经济在国民经济中扮演着重要的角色,因此区域经济是社会各领域重点关注和普遍研究的领域。中国作为一个地域、人口大国,经济发展内向程度高,经济系统极其复杂,不同部门、不同领域在日常经济活动中均产生大量经济数据,分散化的数据以不同格式、不同类型存在于各经济部门数据库中[2-4]。如何从多源异构数据寻找到有用的信息,为区域经济的发展提供数据支撑,成为亟待解决的关键问题[5-7]。数据挖掘是从海量的、不完全、模糊的异构数据中提取隐藏在其中的有潜在价值的信息和知识的过程[8]。目前,比较成熟的数据挖掘技术主要有遗传算法[9]、人工神经网络[10,11]、邻近搜索方法[12]等,通过在大量数据中提取隐含规则和信息,为区域经济的发展推进策略提供分类指导、分区推进的技术支持[13]。基于此,本研究根据区域经济系统的特点,提出一种基于Multi-Agents数据挖掘技术的区域经济系统,将数据挖掘算法应用于区域经济分析中,把握地区发展方向和进程,提高区域规划的及时性和有效性。
1 Multi-Agents的区域经济分析
1.1 Multi-Agents技术
Agent是能够感知环境、接收环境消息并作出反应,进而反作用环境中的一种实体[14]。在移动互联网数据挖掘中,将Agent看作是一种能在异构网络中有一台主机前移到另一台主机实现资源交互的程序。而Multi-Agents是通过多个Agent组成的集合,系统中各Agent根据具有的知识对外界刺激作出反应,并获取新的消息更新自身状态,通过消息获取和数据交互完成任务。
由于Multi-Agents系统的Agent都是相互独立的,各Agent间、Agent与环境间通过通讯、协商和协作共同完成系统数据的采集、传输、分析和评价[15]。Multi-Agents系统在异构、分布控制、解决多个关联性任务场合具有较高的可靠性,可动态对系统任务进行分解。根据区域经济系统的特点,结合数据挖掘系统结构,将Multi-Agents技术应用于区域经济系统,建立基于Multi-Agents的区域经济应用框架如图1所示。
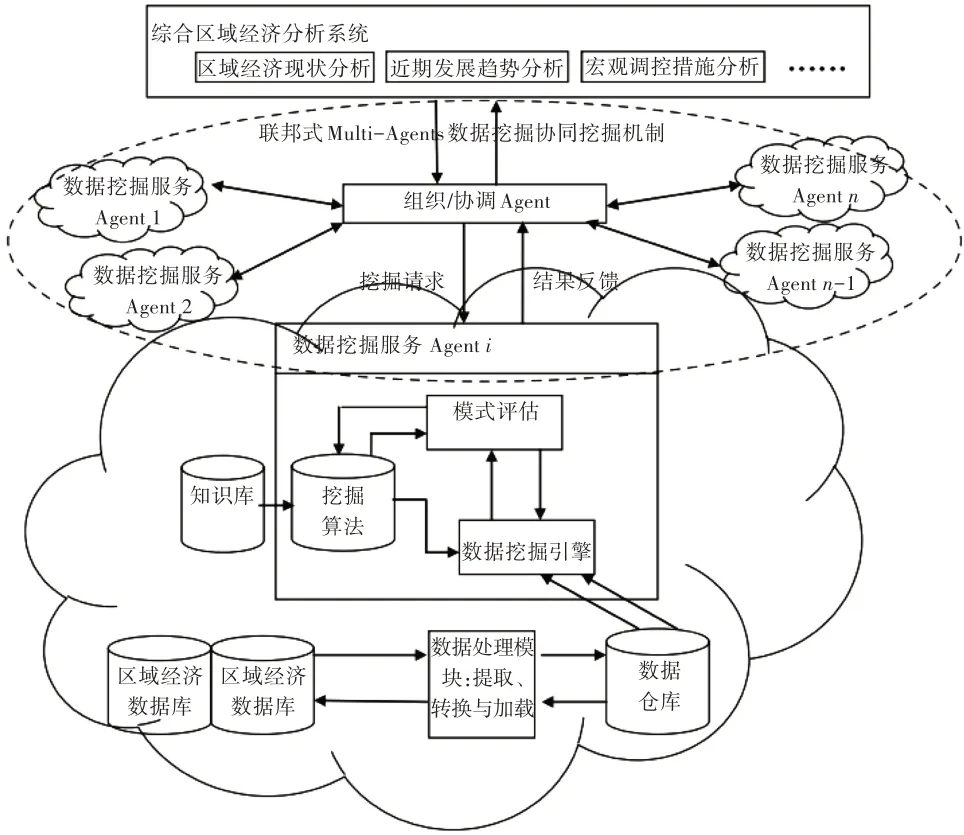
图1 基于Multi-Agents的区域经济应用框架
从Multi-Agents应用框架可以看出,整个系统被划分为数据处理模块、数据挖掘引擎、模式评估、知识库系统4个部分。数据处理模块将区域经济数据库基础数据提取、过滤、转化为数据库要求数据文件。数据挖掘引擎包括关联规则、聚类算法等数据挖掘工具。模式评估根据知识库的相关知识,对获得的结果评估。知识库中存取经济领域知识,将获得的数据评估结果与知识库相关领域比较,用以指导数据挖掘执行。
Multi-Agents的区域经济数据挖掘通过分布在网络中的多个Agent完成各区域经济事务的数据服务,将各Agent挖掘信息汇总,与综合分析系统形成交互机制,分析区域经济现状成因、宏观调控有效性等,各Agent智能代理间采用联邦式协同挖掘机制[16]。
1.2 Multi-Agents的数据处理
在区域经济数据库中,选择某些经济事务的相关数据,对数据进行预处理,通过数据分析和挖掘获得准确的结果来指导区域经济发展成为关键点。由于区域经济分析基本是在过往数据基础上进行[17],因此,首先选择Microsoft时序算法对经济数据分析挖掘并预测经济指标,再通过聚类算法对选定的预测指标相关的数据进行挖掘分析。
1.2.1 Microsoft时序算法自回归是在特定的时间点t内,根据过往的时点计算,获得当前时刻的预测值。因此,考虑n个以前时点,获得当前时刻点t的函数关系为:
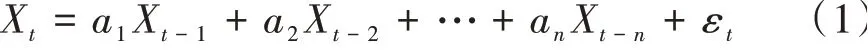
式中,Xt为t时刻的预测值,ai为i时刻点的自回归系数,εt为阈值,通常取0~1。
采用自回归时序算法的关键是将系统内部不同时间序列转化为多个事件,创建一个行列允许算法根据过往值获得当前某一时刻的计算值。确定自回归系数采用最小化建模时间序列与观察时间序列的均值。
1.2.2 Microsoft聚类算法当数据分组不明显时,采用Micorsoft聚类算法从数据中寻找自然分组。聚类算法创建一组聚类,假设该聚类为正确的,并将事例分布到每个聚类,建立了正确的模型[18]。将需要训练数据的事例随机分配到模型中进行合适的聚类,并通过不断调整使之与现实世界相适应,直至某个事例不再满足提前设置的终止条件或不在聚类间,此时该模型与实际相符,处于一个准确状态。
在聚类算法中,采用期望最大化算法(Expectation maximization,EM)将事例分配到聚类中。即便对于一个包含m个元素和d个连续属性的数据库D,假设每个事例x∈D,计算x属于每个聚类h=1,2,…,k的概率:
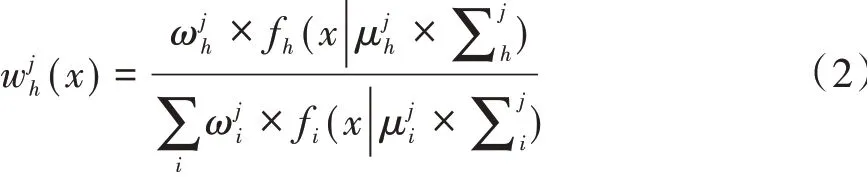
将获得的元素概率结果放入到模型中,更新混合模型参数值:

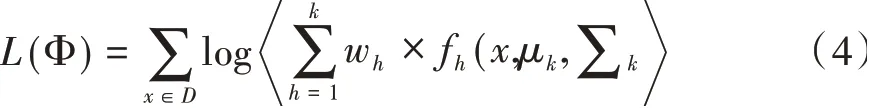
EM算法通过度量某对象的概率来决定该对象属于哪个类别[19]。算法将每一维作为钟型曲线计算标准差和均差,当某点落入钟型曲线内,则表示该点以计算的概率分为某一个聚类。由于各聚类曲线可重叠,因此该点也可以属于其他聚类,但聚类概率不同,存在模糊边界,表征实际参数间存在的相互关联关系,因此可通过统计每个对象的聚类概率进行结果预测。
2 Multi-Agents的区域经济系统
2.1 系统软件结构
创建区域经济分析系统的重点是解决异构数据格式和数据服务方式的统一[20]。本研究选择采用XML Web Service技术实现数据服务Agent,以XML格式文件作为系统数据的表达方式。XML Web Service是一个与具体开发工具和平台无关的标准,XML Web Service采用SOAP协议,并通过Http来调用。利用XML Web Service建立网络中的服务节点,响应数据请求,进而形成具有标准传输接口的数据库“黑盒”服务节点[21]。XML作为用户数据服务标准格式,实现数据在网络上的无损传输,形成网络共享的数据库服务数据流[22]。通过XML Web Service技术和XML系统数据表达方式建立区域经济分析系统结构框架如图2所示。系统被分为4层结构,分别为数据库层、数据库服务扩展层、异构数据库服务层、用户应用层。
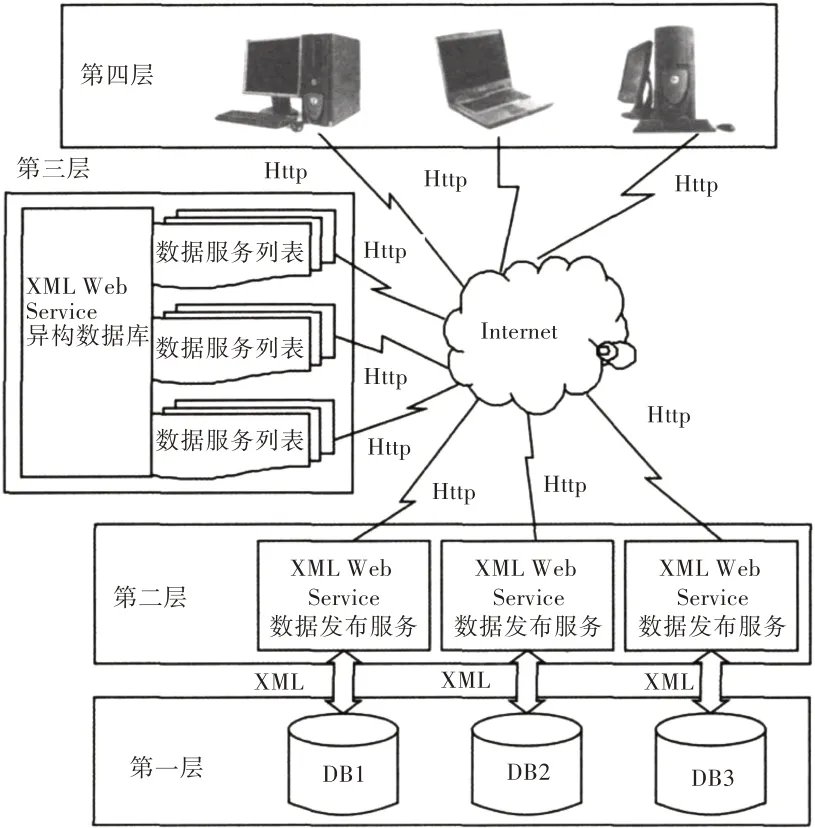
图2 区域经济分析系统结构框架
数据库层作为系统最底层,既可作为异构数据库系统的底层数据源,也可作为网络中数据服务节点。数据库层作为系统共享资源,应该能为系统提供可视化数据图表信息,同时根据用户访问权限的不同将数据分为共有或私有数据,强化数据库的访问安全性。
数据库服务扩展层主要为系统提供数据服务资源结构,为数据信息共享提供数据服务,并根据功能需求进行数据提取,以XML形式屏蔽不同数据库间的差异,提供统一的数据格式响应,并将数据交付给上一层。
异构数据库服务层通过系统服务里列表记录不同数据库的数据服务,并实时更新数据库数据,提供全局数据服务视图响应用户服务请求,建立全面的数据服务平台将数据服务分解,向下层传递请求信息,并根据下层数据库返回的信息进行再加工,生成满足用户要求的服务数据。
用户应用层通过互联网进行数据服务请求。用户应用层可以对数据库服务扩展层、异构数据库层进行管理,通过数据库服务扩展层的全局数据服务为用户提供面向系统的数据服务,这种服务屏蔽掉平台系统的差异,在异构数据库层提供全局的共享平台。
通过系统的4层网络结构,为用户提供基于互联网的XML Web Service数据服务体系,用户能够在异构数据库进行数据采集、加工和数据整合,建立透明的数据综合服务平台。
2.2 区域经济分析系统实现
针对系统结构框架,采用C#语言开发区域经济数据分析。系统开发工具为:NET集成开发平台,服务器采用Windows Server 2016服务器,采用MySQL数据库。系统硬件标准为:PIII/1G以上CPU,内存16 G以上,操作系统Windows 10。数据库软件:MySQL数据库。数据挖掘采集过程中采用Micorsoft聚类的期望最大化算法抓取Agent系统文本内容,采用XML web Service技术实现数据服务,由XML作为用户数据存储和传输。
2.2.1 数据采集功能以某个金融行业数据库为基础,进行进入系统的数据分析,由于金融机构所属行业众多,金融数据差异性极大,采用Micorsoft支持的时序算法抓取数据,系统保留数据源,并对数据应用层进行数据更新,图3为数据采集界面。

图3 数据采集界面
2.2.2 数据挖掘功能用户根据采集到的数据,由需求分析,选择Micorsoft聚类算法进行数据挖掘,根据用户执行命令获取异构数据库中信息,并进行数据挖掘,并将挖掘的数据信息在界面显示,每次挖掘出来的数据,系统都会详细罗列出来,用户能查询每项数据的详细信息,图4为数据挖掘界面。
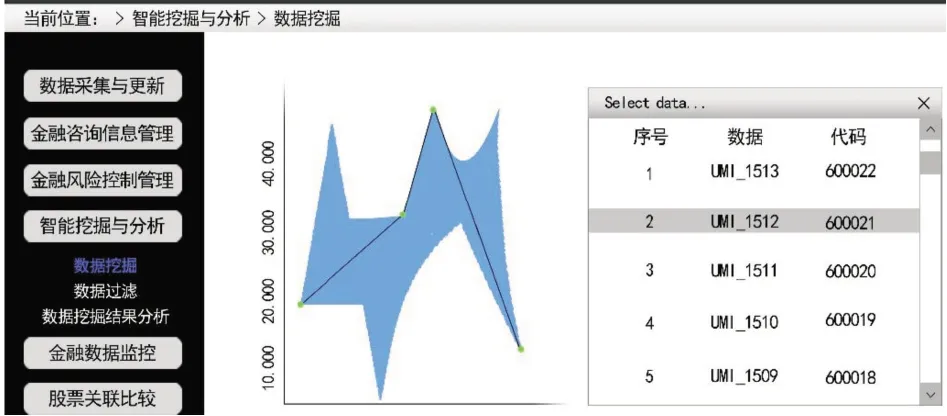
图4 数据挖掘界面
2.2.3 数据监控功能为加强对数据的管理,系统开发了数据监控功能,数据监控功能包括数据的选择、监控信息反馈、进度查看等子功能。用户在进行数据监控时,首先确定监控数据,然后由系统应用层对全局覆盖监控数据,用户能查看到数据的实时状态,并将最终反馈发送至数据服务层,如图5所示。
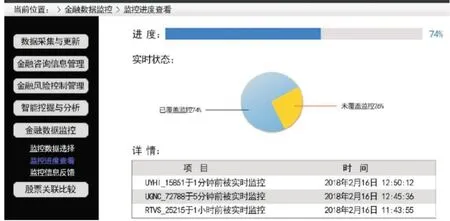
图5 监控进度查看界面
3 结论
区域经济是经济社会活动普遍存关注的问题,对地方寻求经济振兴、中央制定宏观决策具有重要的参考作用。而区域经济涉及海量的多源异构数据,如何从分散化的数据库异构数据中提取有价值的经济数据成为难点。在充分认识区域经济特征基础上,从分布式网络管理体系结构入手,基于Multi-Agents的分布式数据管理模式和协作方式,建立起区域经济分析的数据挖掘应用框架,采用Microsoft时序算法和期望最大化算法进行系统数据的采集和数据挖掘,并以通过XML Web Service技术实现数据服务Agent,以标准XML格式进行数据访问,创建一个多数据库访问Agent来集中管理数据访问,为用户提供跨数据库平台的数据共享环境。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
小学教学研究(2022年5期)2022-04-28
电力与能源(2017年6期)2017-05-14
中国洗涤用品工业(2017年2期)2017-04-16
中国商论(2016年34期)2017-01-15
电信科学(2016年11期)2016-11-23
电子科技大学学报(2016年2期)2016-08-31
通信电源技术(2016年6期)2016-04-20
信息通信技术(2015年6期)2015-12-26
电信科学(2014年2期)2014-02-28
