
基于磁共振影像层间插值的超分辨率及多视角融合
2021-12-07 10:10秦品乐曾建潮李俊伯
计算机应用 2021年11期
李 萌,秦品乐,曾建潮*,李俊伯
(1.山西省医学影像与数据分析工程研究中心(中北大学),太原 030051;2.中北大学大数据学院,太原 030051;3.山西省医学影像人工智能工程技术研究中心(中北大学),太原 030051)
0 引言
在现代医学领域中,计算机断层扫描(Computed Tomography,CT)[1]、磁共振成像(Magnetic Resonance Imaging,MRI)[2]和其他医学成像技术得到了广泛应用。通过可视化显示人体组织或器官的重建技术,可以将医学成像系统获得的一系列完整的二维数据聚合为三维体数据。为了提供必要的人体视觉信息,需要获取高分辨率、高对比度的医学图像。对于MRI,获取高分辨率图像需要很长时间。因此,为了减少因患者身体位移所造成的误差,降低内存成本,通常只存储必要数量的切片,所以大多数医学成像是各向异性的,切片内的分辨率高,切片间的分辨率低。在这些设备获得的三维体积数据中,切片之间的间距比其相邻像素之间的间距要大得多,包含阶梯状边缘、不连续表面、间断细节和其他现象。所以这些不完整的数据具有较低的诊断意义。
医学数据插值的早期工作可以追溯到1992 年,Goshtasby等[3]提出利用连续切片之间的小且渐进的解剖学差异,并通过搜索小邻域来找到像素之间的对应关系。传统的切片插值方法有两类:基于强度的方法和基于变形的方法。线性和三次样条插值方法是基于强度的方法的经典示例,它们直接根据相邻切片的强度执行插值。在后面的研究,研究者们提出了以寻找更精确的变形场为重点的许多方法,包括基于形状的方法[4]、基于形态学的方法[5]和基于配准的方法[6]等。在上述方法中作出的重要假设是,相邻切片包含相似的解剖结构,即结构的变化必须足够小,以便可以在两个切片之间找到密集的对应关系。这种假设在很大程度上限制了切片插值方法的适用性,尤其是在稀疏采样切片时。此外,这些方法没有利用两个相邻切片之外的信息。当切片之间的解剖差异很大时,需要更复杂的建模方法。文献[7-9]的方法直接基于像素灰度。这些方法的优点是操作原理简单、计算复杂度低,且易于实现、应用范围广。但是,它们忽略了一个重要因素:像素变化是由对象的结构引起的。对于线性插值和最邻近插值而言尤其如此,由于线性插值和最近邻插值仅考虑了很少的相邻像素进行插值处理,因此无法考虑许多相关像素,导致插值精度很低,图像模糊,某些结构上的细节残缺,视觉真实性差,并且可能出现伪像。随后,文献[10-12]提出了其他基于像素的方法,并尝试将更多的相邻像素应用于插值算法。Penney等[13]提出了一种基于非刚性配准的方法,以更好地找到具有相似结构特征的切片之间的映射关系。此外,Frakes 等[14]还提出了一种改进的网格控制插值方法。尽管现有研究已经取得了一些进展,但是仍然存在伪影和模糊的问题。
由于深度卷积神经网络(Deep Convolution Neural Network,DCNN)在医学图像分析方面的表现优于传统方法,文献[15-17]提出了通过对数据中的复杂变化建模,可以用于学习从各向异性磁共振(Magnetic Resonance,MR)到各向同性的映射。Dong 等[18]首先提出了使用深度卷积神经网络的图像超分辨率(image Super-Resolution using deep Convolutional Neural Network,SRCNN),学习一种通过三层CNN 将低分辨率(Low Resolution,LR)图像转换为高分辨率(High Resolution,HR)图像的映射。许多研究探索了改善单幅图像超分辨率(Single Image Super Resolution,SISR)的策略,例如使用更深的架构和权重共享[19]。但是,这些方法需要将插值作为预处理步骤,从而极大增加了数据的计算复杂性和前导率。为了解决上述问题,Dong 等[20]提出将反卷积层应用于低分辨率图像以直接上采样至更高分辨率。具体来说,Zhang 等[21]结合了残差学习块和密集块,并引入了残差密集块(Residual Dense Block,RDB),以使所有层的功能都可以被其他层直接看到,从而进一步提高了性能,表明了残差学习在图像超分辨率上拥有更好的效果。除此之外,晋银峰等[22]在对抗生成网络的基础上提出基于对抗生成网络框架和正则化的超分辨率重建算法,保证了低分辨率MR 图像到高分辨率图像的映射一致性。
为了使上采样因子更具灵活性,以实现更快的部署和更高的鲁棒性,Lim 等[23]提出了用于单一图像超分辨率的增强型深度残差网络(Enhanced Deep residual networks for single image Super-Resolution,EDSR),通过在模型中创建单个子结构,以适应不同的上采样因子。Hu等[24]提出的用于超分辨率的任意放大网络(Magnification-arbitrary network for Super-Resolution,Meta-SR)可为每个LR-SR 像素对动态生成滤波器,从而允许任意上采样因子。
为了获得更高分辨率的冠状面和矢状面视觉效果,提高其在医学诊断中的意义,本文提出了一种多视角超分辨率重建融合网络,分别对冠状面和矢状面进行特征提取后,通过空间矩阵滤波器生成动态权重用于任意尺度上采样,在聚合成三维体数据后沿轴状方向分割成二维图像再进行两两融合。相较于直接对三维图像进行超分辨率重建及融合,二维图像需要消耗的内存及图形处理器(Graphics Processing Unit,GPU)资源更少,网络更加轻量级且收敛速度更快。
1 相关工作
1.1 上采样层
在超分辨率网络中,较为主流的上采样层方法有反卷积层和像素筛选(Pixel Shuffle),由于反卷积层是先填充零再进行卷积操作达到放大图像的目的,因此会产生难以避免的伪影,导致重建效果较差。Pixel Shuffle 则是通过卷积得到r2(r为上采样因子,即图像的扩大倍率)个通道的特征图,然后通过周期筛选的方法得到高分辨率图像,但是由于感受野分布不均匀,因此可能会使图像边界发生畸变。
除上述方法外,一种用于超分辨率的任意放大网络(Meta-SR)在超分辨率重建的效果上取得了巨大的提升,该算法提出的Meta-Upscale 包含三个重要的函数:Location Projection、Weight Prediction、Future Mapping。Location Projection 函数把像素投射到LR 图像上,Weight Prediction 函数为SR 图像上每个像素预测对应滤波器的权重,最后Feature Mapping 函数利用预测得到的权重将LR 图像的特征映射回SR图像空间来计算其像素值。
本文受Meta-SR 的Meta-Upscale 启发,结合Pixel Shuffle设计了上采样模块,Meta-SR 通过输入-输出映射,缺少对三维空间下分辨率变化的考虑。本文设计的各向异性插值模块采用了一种新的图像范围投影,针对医学图像三维数据的空间分辨率的变化,通过计算图像中体素的空间位置信息,动态获取上采样层所需要上采样卷积核的权重,这样网络可以不用保存每个尺度对应模型的权重,从而实现对输入低分辨率图像的任意尺度超分辨率放大。
1.2 多视角融合
Peng 等[25]提出了基于边缘超分辨率、融合和细化的深层切片插值(Deep Slice Interpolation via Marginal Super-Resolution,fusion and refinement,DSIM-SR),首先对冠状面和矢状面通过边缘超分辨率(Marginal Super-Resolution,MSR)网络分别得到目标分辨率的体数据,然后通过两视图融合修正(Two-view Fusion and Refinement,TFR)学习沿轴向的结构变化来进一步提高切片插值的质量,在重建效果上取得了一定的提升。TFR 网络将冠状面和矢状面通过MSR 之后得到的体数据分别重新截取获得轴状面的数据,将对应的轴状面两两作为输入进入融合网络。融合网络采用残差密集网络(Residual Dense Network,RDN),训练融合网络的目标函数为:
本文提出了一种多视角融合网络结构,通过对冠状面和矢状面层间插值之后得到的体数据沿轴状方向提取轴状面数据,对得到的两部分轴状面数据一一对应,进行融合,根据轴状方向数据进行约束,增强两种数据的共同特征,然后将融合后的数据和通过RDN 特征提取后的数据进行逐像素加,从而达到提高重建效果的目的。
2 多视角超分辨率重建融合网络
本文所提出的多视角超分辨融合网络整体结构如图1 所示。所提网络主要分为两个阶段:第一个阶段为层间插值阶段,首先采用RDN 对低分辨率图像进行特征提取,其次通过生成不同大小的卷积滤波器和各向异性亚像素卷积来得到任意的上采样因子,通过执行亚像素卷积和周期性转换操作以产生放大后的图像。第二个阶段为多视角融合阶段,对完成第一阶段的冠状图和矢状图所得到的体数据沿轴状方向切割成二维数据,两两进行融合,结合轴状面进一步提高切片插值的质量。
令I(x,y,z)∈Rx×y×z表示MR 的切片。通常来说,将x轴称为矢状轴,将y轴称为冠状轴,将z轴称为轴状轴,因此各面的切片表示为:1)矢状面,Ix(y,z)=I(x,y,z),∀x;2)冠状面,Iy(x,z)=I(x,y,z),∀y;3)轴状面,Iz(x,y)=I(x,y,z),∀z。
同时,以轴状面为例,其稀疏采样定义为:

2.1 层间插值
在准备阶段,将MR 体数据分别沿矢状方向和冠状方向获取到Ix(y,z)、Iy(x,z),分别对Ix(y,z)和Iy(x,z)进行下采样后,再进行特征提取,获取到特征提取图FLR,然后再通过空间矩阵滤波器,计算得到动态权重,通过周期性Pixel Shuffle 获取到超分辨率后的结果ISR。
2.1.1 特征提取
在特征提取阶段,将单张矢状切面或冠状切面输入RDN中进行特征提取,如图2 所示。对于给定的低分辨率图像,特征提取阶段仅提取特征图FLR:
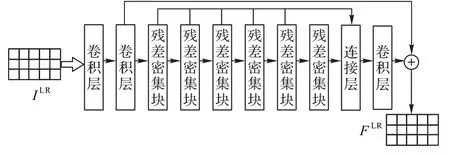
图2 特征提取网络Fig.2 Feature extraction network

其中θFL是过滤器学习网络的参数。
2.1.2 空间滤波器
由于MR 的拍摄时间较长,且病人移动会对成像造成影响,通常会采用适量减少切片的方式来减少拍摄时长;且由于设备及实际情况的差异,不同数据在插值阶段所需要的缩放因子也存在较大的差异。传统的上采样模块会预定义卷积核的数量以及由训练集学习得到的权重,Meta-SR 采用Meta-Upscale Module 代替传统的放大模块。针对任意缩放因子,Meta-Upscale Module 可以通过缩放因子动态地预测放大滤波器的权重,进而使用这些权重生成任意大小的高分辨率图像,实现单一模型解决任意缩放因子的超分辨率问题。
如图3 所示,本文受Meta-SR 的启发,为了解决MR 图像普遍存在的切片内分辨率高、切片间分辨率低导致的各向异性,在上采样模块中首先设计了一个空间位置矩阵滤波器(Space Position Filter,SPF),通过像素之间的空间位置计算得到权重,从而允许任意大小的上采样因子。将ISR的空间分辨率表示为(Rh,Rw)。为了找到体素之间的对应关系,首先计算ILR生成的特征块中每一个点与ISR之间的坐标距离,根据它们在最终图像ISR中的坐标位置,用坐标距离乘以空间分辨率(Rh,Rw),从而得出其对应的物理距离关系。以目标通道c、滤波尺寸k、空间分辨率(Rh,Rw)以及通道c在坐标位置的映射Mc作为输入可得空间位置矩阵Pc:
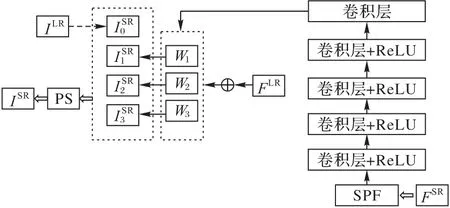
图3 层间插值上采样Fig.3 Inter-layer interpolation upsampling

由计算Pc的输入参数可以看出,Pc包含了给定切片的空间分辨率信息并且与目标通道建立了关联关系,同时会对后续参与的计算同样建立起这种关系。
最后,将空间位置矩阵作为输入,进入到过滤器生成阶段,该阶段由5 个卷积层和4 个ReLU 组成:第一层卷积的输出通道为32,即RDN 中的默认超参数;第二、三、四层卷积的输出通道数为64;第五层卷积的输出通道数为FLR的通道数,最后得到可根据空间分辨率变化的过滤器权重Wc。将FLR与Wc相乘,得到对应坐标的值,通过周期性筛选得到ISR。
2.2 多视角融合网络
本文提出了多视角融合网络通过学习单个切片的结构变化来进一步提高切片插值的质量。如图4 所示,该网络分为两个部分,本文用矢状和冠状超分辨率后体数据的Isag(x,y,z)和Icor(x,y,z)分别获得单张轴向切片(x,y)和(x,y)用作输入。
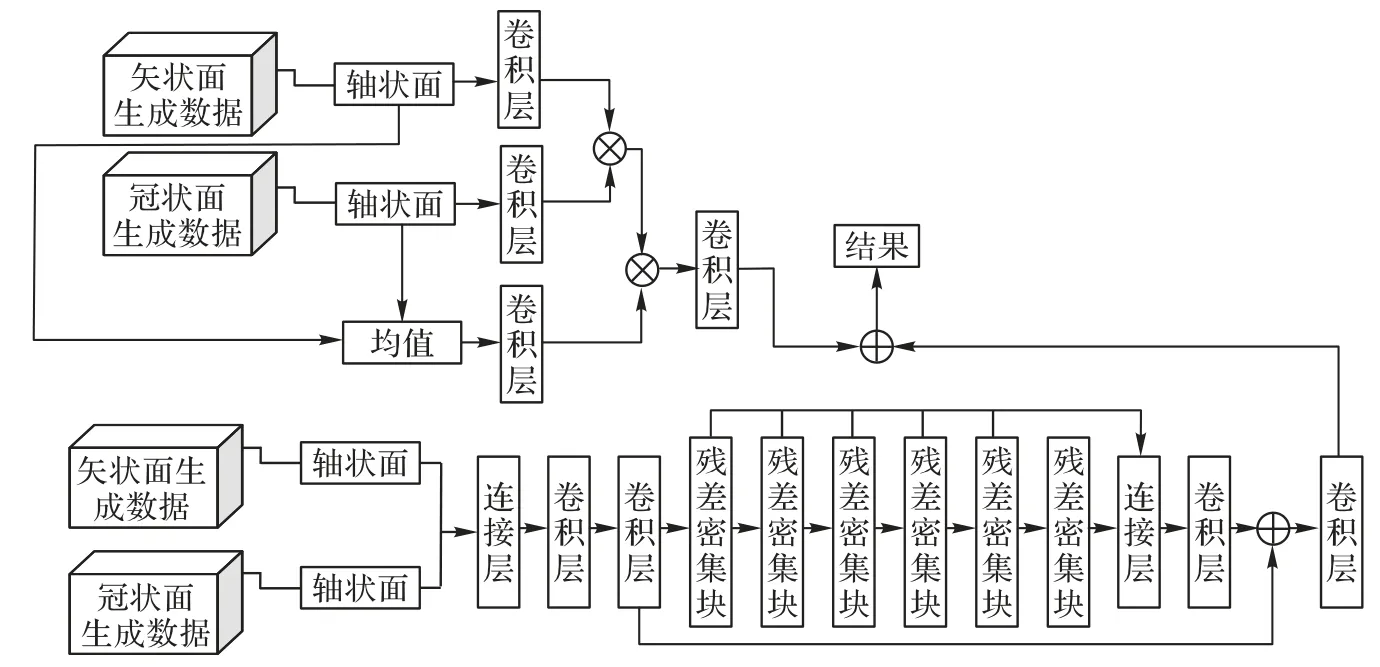
图4 多视角融合网络Fig.4 Multi-view fusion network
在第一部分中,首先对(x,y)和(x,y)取均值,得到=(x,y),由于(x,y)和(x,y)的每个像素代表从矢状和冠状方向的最佳估计,因此切片(x,y)的平均值可以减少某些方向上的伪影。令(x,y) 的网络输入为X=(batch,h,w,256)(x,y)的网络输入为Y=(batch,h,w,256)。首先,经过Embedded Gaussian 中的两个嵌入权重变换,分别得到(batch,h,w,128)和(batch,h,w,128),通过降低通道数,达到减少计算量的目的。其次,对这两个输出进行reshape 操作,使之变成(batch,h×w,256)对这两个矩阵进行矩阵乘,计算相似性,得到(batch,h×w,h×w),在第2 个维度上进行SoftMax 操作,得到(batch,h×w,h×w)找到当前图片中每个像素与其他所有位置像素的归一化相关性;然后,对均值也采用一样的操作,先通道降维后resha pe;接下来,和(batch,h×w,h×w)进行矩阵乘,得到(batch,h×w,128),本质就是输出的每个位置值都是其他所有位置的加权平均值,通过SoftMax 操作可以进一步突出共性。经过一个1× 1卷积恢复输出通道,保证输入输出尺度完全相同。最后,和进行逐像素加,目标函数为:
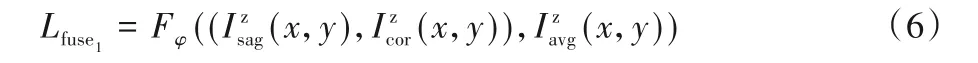
在第二部分中,本文采用具有5 个RDB 的RDN,每个RDB有4个卷积层,增长率为16的目标函数为:
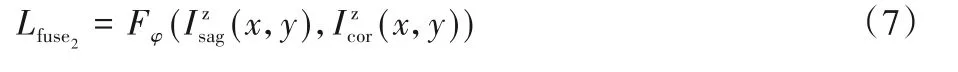
RDN 通过密集卷积层来提取充分的局部特征,对于每一个RDB,不仅允许将前一个RDB 的状态直接连接至当前RDB的所有层形成连续记忆,还可以通过局部密集连接充分利用其中的所有层,再通过局部特征融合(Local Feature Fusion,LFF)自适应地保留累积的特征。通过使用RDB 中的局部特征融合来自适应学习来自先前和当前局部特征的更有效特征,并稳定更大网络的训练。在完全获得密集的局部特征后,使用全局特征融合将所有RDB 提取到的特征融合在一起,自适应地学习全部分层特征,得到全局特征。
最后,对第一部分和第二部分得到的结果进行逐像素加得到最终的结果。

在融合部分中的两部分图像是由冠状面和矢状面分别进行超分辨率重建后重新聚合成三维数据后,再次切片得到的轴状面数据,融合旨在获取图像不同面的关联性,对轴向进行约束。通过第一部分中的两层(4 个)卷积能够弱化图像中的伪影,再与第二部分中得到的结果进行逐像素加后,可以达到增强图像中的关键组织区域的纹理信息的目的。
3 实验与结果分析
3.1 实验参数
本文使用了15 个来自阿兹海默症神经成像计划(Alzheimer’s Disease Neuroimaging Initiative,ADNI)数据集中的MR T1 权重的脑部数据,MR 以1mm × 1mm × 1mm 的各向同性采样。原数据在轴状面的分辨率均为256 × 256,部分数据轴状方向的切片数量略少于256,本文选择将其零填充到256 × 256 × 256后重新获取切片,最终在轴状面、矢状面和冠状面各得到3840个切片。进一步通过系数k=2、k=3、k=4对各向同性数据进行抽样,得到I↓k(x,y,z),大小分别为256 ×256 × 128、256 × 256 × 85 和256 × 256 × 64。本文将数据分成训练集、验证集和测试集三部分,样本数量分别为12、1、2。在测试集中,本文仅采用具有脑部组织区域的图组成测试集。
实验阶段本文使用PyTorch1.0,对所有模型采用Adam 作为梯度下降优化器,动量为0.5,学习率为1× 10-4,学习率衰减为1× 10-5,每当训练损失的最优值在20 个epoch 内没有改善时,学习率进行衰减,训练使用一台NVIDIA P100 GPU 服务器。
3.2 对比实验
为了测试本文算法的性能,将本文算法与传统的最近邻差值(Bilinear),双三次插值法(Bicubic),基于神经网络的RDN,Meta-SR 以及同样进行了多视角融合的DSIM-SR 算法进行了性能对比。
表1 给出了尺度分别为×2、×3、×4 时各算法的峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)值和结构相似 性(Structural SIMilarity,SSIM)指标。与同样进行了多视角融合的DSIM-SR 相比,本文算法在各个尺度上均有1 dB 左右PSNR 值的提升,且与其他算法相比,本文算法和DSIM-SR 的性能表现都更优,这是由于本文算法和DSIM-SR 均设计了多视角融合模块,通过约束轴状方向,对单一视角重建的结果进行了修正。且本文算法在融合模块进一步进行了结构优化,更为突出了图像高频信息较为丰富的区域,进一步提高了边界区分度。

表1 不同算法在测试集上的PSNR和SSIM对比Tab.1 PSNR and SSIM comparison of different algorithms on test set
为了客观显示本文算法与各个算法的重建效果,本文从测试集中选取了两幅高分辨率图像,分别进行4 倍下采样后输入以上6 个算法,重建效果如图5 所示。由图5 可以看出,相较于其他5 个算法,从视觉效果上来看,本文算法提升明显;且与同样进行了多视角融合的DSIM-SR相比,本文算法在图像的细节上也取得了更优的还原度。
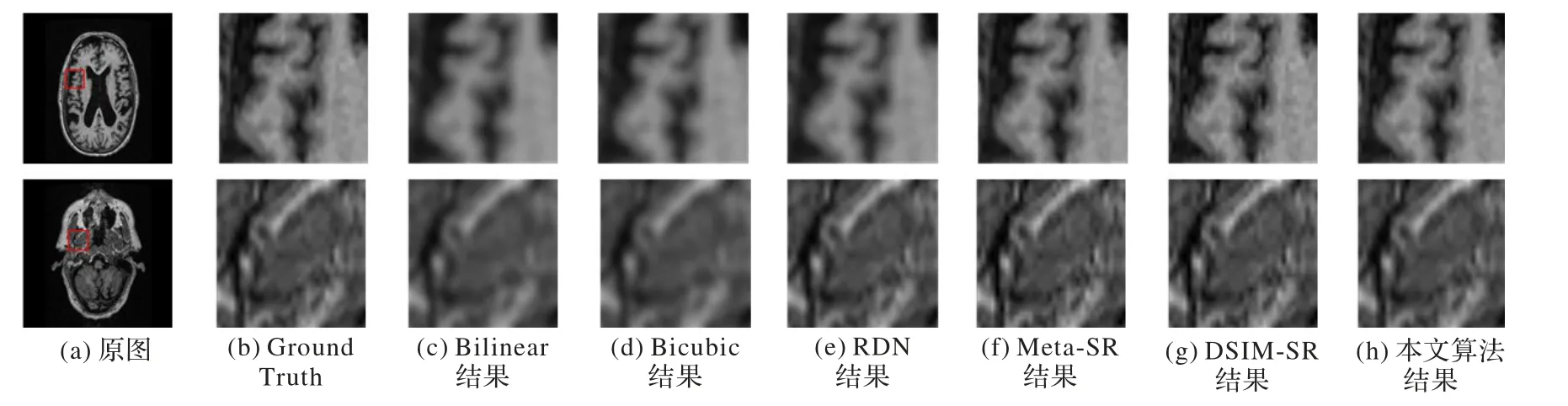
图5 不同算法重建效果对比Fig.5 Reconstruction effect comparison of different algorithms
3.3 消融实验
为了进一步验证多视角融合网络的作用,在实验中去掉本文算法的多视角融合网络部分,分别使用仅对冠状面进行超分辨率重建的结果和仅对矢状面进行超分辨率重建的结果,与多视角融合之后的结果进行比较,如图6所示。
由图6 可以看出,仅对冠状面进行重建和仅对矢状面进行重建时,由于缺乏轴向方向上的约束,均表现出一定的方向伪影。在本文算法的融合部分中,通过对两个面进行轴向约束,降低伪影对图像的影响,融合的图像更贴近真实图像。

图6 消融实验中多视角融合前后重建效果对比Fig.6 Comparison of reconstruction effect before and after multi-view fusion in ablation experiment
表2 中给出了尺度分别为×2、×3、×4 时仅对冠状面进行重建、仅对矢状面进行重建和多视角融合后的PSNR 和SSIM指标。
从表2中可以看出,多视角融合后的PSNR 相较于仅对冠状面进行重建和仅对矢状面进行重建的结果在各个尺度中均有一定的提升。

表2 融合前后的PSNR和SSIM对比Tab.2 PSNR and SSIM comparison before and after fusion
4 结语
针对MR 图像切片内分辨率高而切片间分辨率低导致的冠状面和矢状面缺乏医学诊断意义这一问题,本文提出了一种新的多视角超分辨率融合算法。该算法可以实现任意上采样因子放大低分辨率的图像,同时通过以轴状面作为约束进行多视角融合,进一步提升了图像的视觉感知效果。实验结果表明,该算法可以对存在各向异性的MR 图像进行重建,将冠状面和矢状面的图像恢复至与轴状面相同分辨率,便于医学诊断。但是该算法中均采用将三维数据转换成二维数据后进行处理,因此在处理过程中,仅考虑了横向与纵向之间的关联关系,缺少对于斜向角度中关系的利用,因此接下来将进一步研究直接针对三维体数据进行三维上的处理。
猜你喜欢
导航定位学报(2022年3期)2022-06-10
中国心血管杂志(2022年1期)2022-03-08
昆明医科大学学报(2022年1期)2022-02-28
文史杂志(2020年2期)2020-07-18
科学与财富(2020年15期)2020-07-04
婚育与健康(2020年2期)2020-06-01
移动通信(2020年4期)2020-05-07
移动通信(2019年4期)2019-06-25
新生代(2018年16期)2018-10-21
现代信息科技(2018年4期)2018-07-12
