
基于pinball损失的结构模糊多分类支持向量机算法
2021-12-07 10:08李洁
计算机应用 2021年11期
李 凯,李洁
(河北大学网络空间安全与计算机学院,河北保定 071002)
0 引言
支持向量机(Support Vector Machine,SVM)是由Vapnik等[1]提出的一种机器学习方法,其目标是根据输入样本集求解一个二次规划问题,从而获得所需的最优分类超平面。为了解决SVM 计算复杂度高的问题,Jayadeva 等[2]提出了孪生支持向量机(Twin Support Vector Machine,TWSVM),该方法通过求解两个较小的二次规划问题,确定两个非平行的超平面,使得每个超平面更接近其中的一个类而远离另一个类,该模型较好地提高了计算速度。此后,在TWSVM 的基础上,研究者们提出了多种孪生支持向量机算法[3-4],如基于pinball 损失的孪生支持向量机[5-7]、模糊孪生支持向量机[8]和结构型孪生支持向量机[9-10]等,并将其应用于实际问题[11]。
可以看到,上述算法均适用于二分类问题,然而,在实际应用中多分类问题更加常见,因此对多分类问题的研究是十分必要的。目前,人们基于孪生支持向量机对多分类问题[12]进行了研究,主要分为三种类型:
1)第一类是基于二分类的多分类策略。该策略主要包括一对一和一对多两种:一对一策略是在任意两类之间构造一个二分类器,对待分类样本使用投票法进行分类。例如Shao等[13]提出了一对一孪生支持向量机(One-Versus-One TWSVM,OVO-TWSVM)。该方法的缺点是当数据类别较多时,需构造的分类器数量过多,且存在数据不可分区域;而一对多策略[14]是在k个类中任意挑选一类作为正类,其余k-1类作为负类,并构造k个二分类器进行分类,缺点是每个分类器的训练集高度不平衡;有向无环图支持向量机(Directed Acyclic Graph TWSVM,DAG-TWSVM)[15]可视为OVOTWSVM方法的一种变形,其训练过程与OVO-TWSVM 相似,在测试时使用有向无环图对分类样本进行分类,有效减少了投票轮数,然而当数据类别较多时仍需构造大量的分类器,且在判决过程中存在误差累积的现象。Don 等[16]提出了一种分而治之支持向量机(Divide and Conquer SVM,DCSVM),它将OVO-TWSVM 方法的简洁性与DAG-TWSVM 的分类速度相结合,克服了分类器过多的缺点,但分类过程仍存在误差累积问题。除此之外,研究人员在这些算法的基础上提出了多种改进算法,Liu 等[17]提出了一种基于OVO 策略和SVM 算法的改进多分类算法,使用K近邻法为分类器设置权重,提高分类准确率;Yang 等[18]将多重递归投影孪生支持向量机、最小二乘法应用到OVA-TWSVM(One-Versus-All TWSVM)算法中,提出最小二乘递归投影孪生支持向量机等。
2)第二类是基于二分类方法演变的其他解决方法,包括一对一对多孪生支持向量机Twin-KSVC(TwinK-class Support Vector Classification)[19]和多生支持向量机(Multiple Birth SVM,MBSVM)[20]。一对一对多孪生支持向量机较好地解决了OVO-TWSVM 中存在的随机投票现象,但其子分类器复杂,时间复杂度过高;而多生支持向量机极大减少了约束条件,使得时间复杂度低,计算速度显著提高,但该算法容易陷入局部最优;之后,研究人员针对这些方法提出了许多改进算法[21-24]。
3)第三类是直接构造解决多分类问题的方法。该方法针对所有样本直接构造一个单一优化问题,并确定所有类的决策函数,该方法有效解决了其他方法中存在不可分区域等问题。例如:Guo 等[25]为解决SVM 不适用于未标记的数据的问题,提出了一种基于主动学习和SVM 多分类模型用于处理未标记的数据。Weston 等[26]提出了多分类支持向量机(Multi-Class SVM,MSVM),但其存在二次规划问题过大与计算时间长等缺陷。Crammer 等[27]通过引入克罗内克函数,使得约束更加紧凑,但其计算量依然较大。Wang等[28]通过引入新的宽松边界条件,提出了简化的多分类支持向量机(Simplified Multi-Class SVM,SimMSVM)算法,较好地提高了计算速度,如图1(a)所示。然而,由于该方法使用铰链损失,很容易导致算法具有噪声敏感性和重采样不稳定性;此外,在一些应用中,例如在推荐系统中,较新产品的重要性程度应高于旧产品,同样地,不同样本对支持向量机的作用可能不同;最后,样本间存在潜在的结构信息,这些信息可能包含一些重要的先验知识来训练分类器,该方法未考虑到这几点,使得该方法对噪声或异常点仍具有较大的敏感性和较低的泛化性能,分类结果较差。
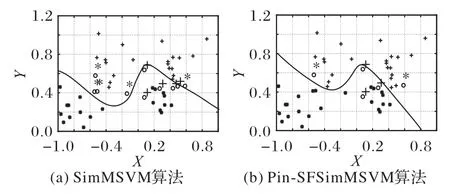
图1 两种算法的分类示意图Fig.1 Classification schematic diagram of two algorithms
为了进一步解决上述问题,将pinball损失函数、样本模糊隶属度和样本结构信息等引入到SimMSVM 算法中,本文提出了一种基于pinball 损失的结构模糊多分类支持向量机算法Pin-SFSimMSVM。如图1(b)所示,该方法使用pinball 损失函数对分类错误的样本进行惩罚,同时对分类正确的样本给出一个额外惩罚,该函数使用分位数距离,使其对噪声不敏感,数据重采样更稳定;为样本添加模糊隶属度,使得属于一个类的样本在分类时扮演更重要的角色;最后,将数据的先验结构信息应用到算法中,进一步提高了支持向量机的分类性能。
1 相关工作
对SimMSVM 算法的数学模型、算法中用到的铰链损失函数以及本文所提出的Pin-SFSimMSVM 算法所用到的pinball损失函数进行介绍。
1.1 SimMSVM
为了解决多分类问题,Wang等[28]提出了一种新的支持向量机算法,通过最大化每类到其余类的余量来区分出所有类,并且可一次性确定所有类的决策函数,解决了存在不可分区域的问题,且和同类方法相比在速度上也有较大的提升。给定l个样本的k类数据集T={(x1,y1),(x2,y2),…,(xl,yl)},其中xi∈Rn为训练数据样本,yi∈{1,2,…,k}为类标签,其优化问题如下:
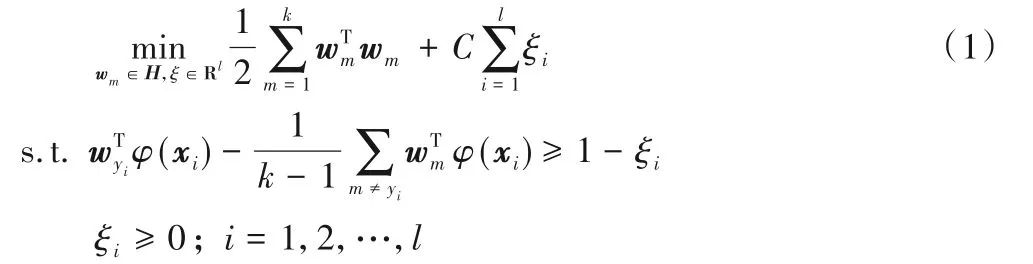
其中:C为惩罚参数;wm为第m类的分类决策向量;H为适当维度的特征空间。通过求解式(1)可以得到所有k个类的分类决策向量。对于待分类样本x,利用式(2)确定其类别:
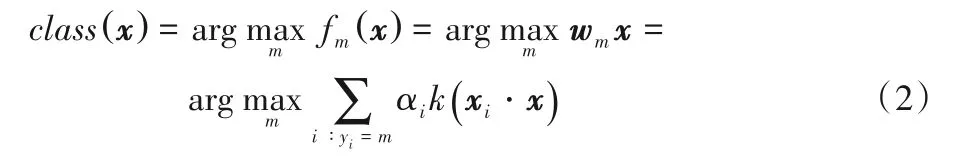
1.2 损失函数
对于支持向量机与孪生支持向量机以及相关算法,在建立相应模型时,主要使用了铰链损失函数,即:
Lhinge(u)=max{0,u}
在算法中,常见的使用形式为:
Lhinge(x,y,f(x))=max(0,1-yf(x))
其中:y和f(x)分别为理想值和预测值。由于铰链损失函数使用了最短距离,因此,它易导致噪声敏感性和重采样的不稳定性。为此,人们对不同损失函数的SVM 及TWSVM 进行研究,其中pinball 损失函数研究较为广泛。pinball 损失函数定义如下:
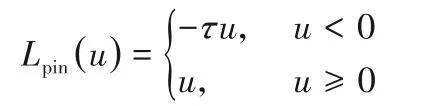
在本文中,使用的pinball损失函数为:
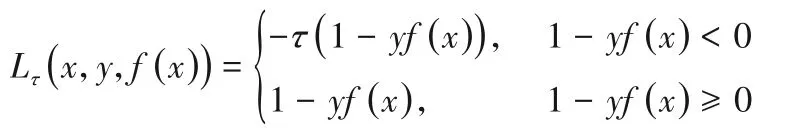
其中τ∈[0,1]。可以看到,pinball损失函数不仅对分类错误的样本进行惩罚,而且对分类正确的样本给出一个额外惩罚;另外,由于该函数使用了分位数距离,因此,它对噪声不敏感,数据重采样更稳定,且不会增加计算成本。当pinball 损失的参数趋于零时,损失函数成为铰链损失。
2 结构模糊多分类支持向量机
在本章中,将pinball损失函数、样本权重和样本的结构信息引入到SimMSVM 中,提出了一种新的多分类支持向量机算法Pin-SFSimMSVM。使用pinball 损失函数能较好地解决铰链损失函数所带来的噪声敏感和重采样不稳定性等问题,通过引入模糊隶属度对样本赋予不同权重,并充分挖掘样本中潜在的结构信息,数据中可能包含用于训练分类器的重要先验知识,进一步提高了算法的噪声不敏感性和算法的性能。该方法不仅保留了SimMSVM 中一次性解决所有样本的分类问题、避免产生数据不可分区域和计算速度快等优点,且提高了算法的抗噪性和分类准确率。下面将从线性和非线性两种情况对算法进行介绍。
2.1 线性情况
给定一个含有l个样本的k类训练数据集T={(xi,yi,Si)|i=1,2,…,l},其中xi∈Rn为训练样本,yi∈{1,2,…,k}为样本类标签。将pinball 损失函数、样本模糊隶属度和样本结构信息引入到SimMSVM 中,从而得到线性Pin-SFSimMSVM的优化问题:
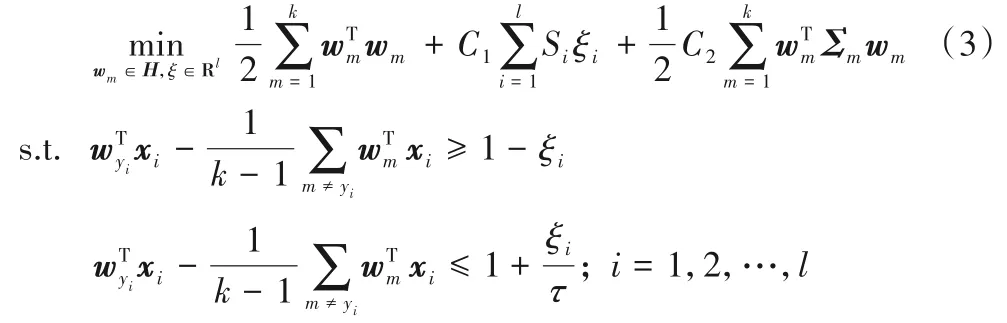
其中:wm为第m类样本的分类决策向量;C1和C2分别是平衡因子且C1>0,C2>0;Si为样本模糊隶属度;ξi为松弛变量;Σm为第m类样本的结构信息;τ∈[0,1]为pinball损失参数。为了解决式(3),构造拉格朗日函数如下:
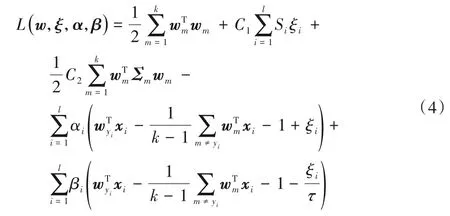
其中α和β是由拉格朗日乘子构成的向量,且α≥0,β≥0。
将拉格朗日函数对变量求偏导并令其等于0,得:
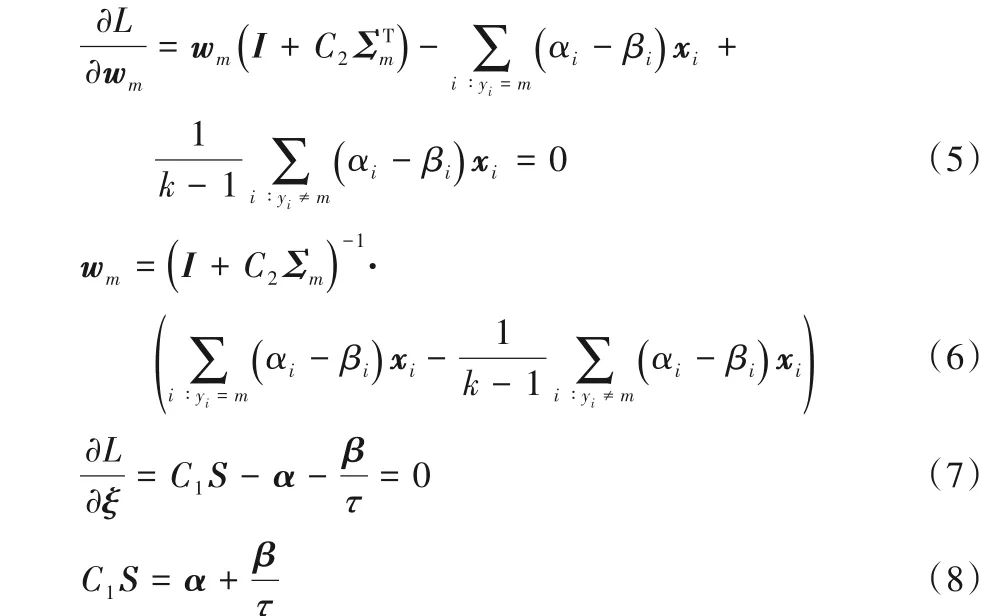

由式(7)和式(9)可得约束条件为:

将式(6)和式(8)代入到式(4)中,从而得到式(3)的对偶问题如下:

其中:γ=(α-β);S为由样本模糊隶属度构成的向量;G为一个l×l维的矩阵。G的矩阵元素为:
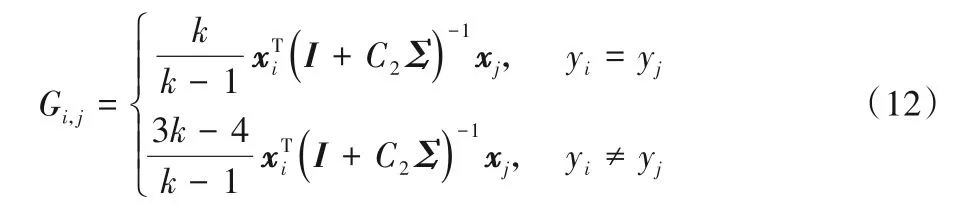
其中I为适当维度的单位矩阵。
通过求解对偶问题式(11),从而得到γ,进一步可以求得wm,即每类样本的分类决策向量。因此,获得的决策函数为:
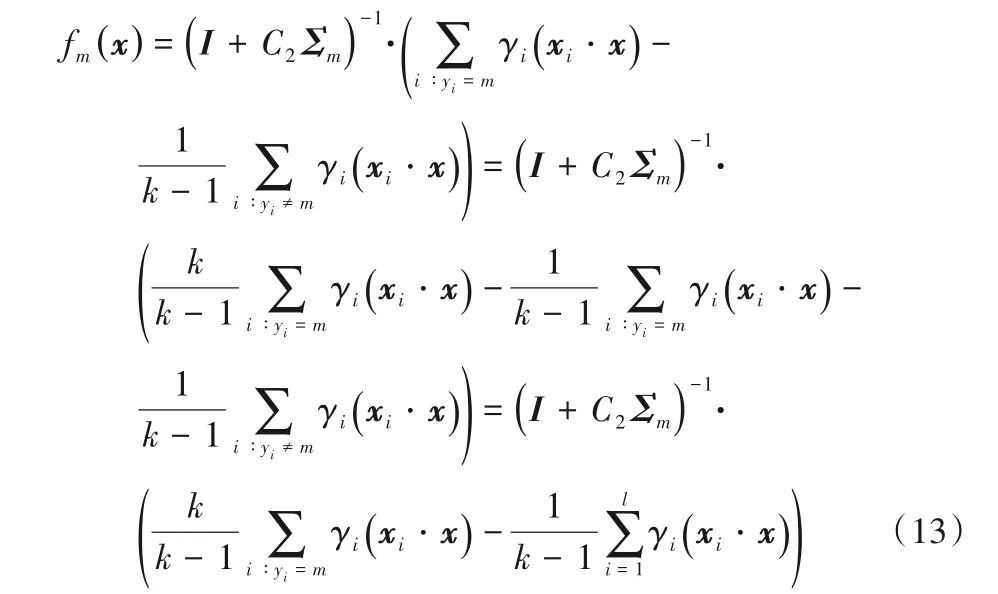
当对待分类样本x进行分类时,其最终所属类别的求解方法如下:
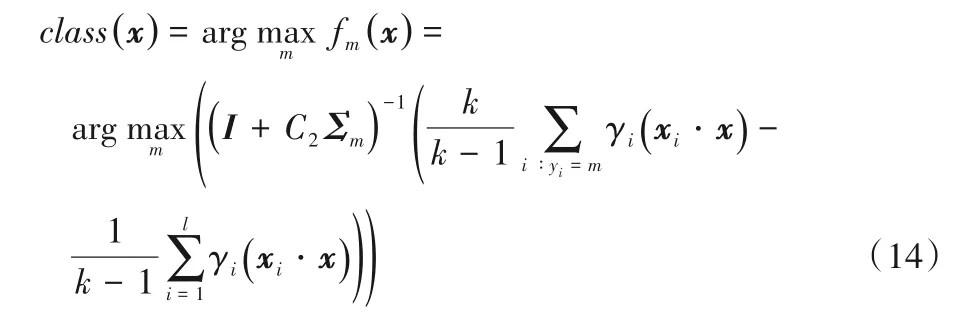
2.2 非线性情况
在这一节中,将线性情况推广到非线性情况中。通过核矩阵将输入样本映射到高维特征空间,使其在高维空间中也能实现线性可分。设φ是一个从输入空间Rn到特征空间Z的映射,则非线性Pin-SFSimMSVM算法的优化问题为:
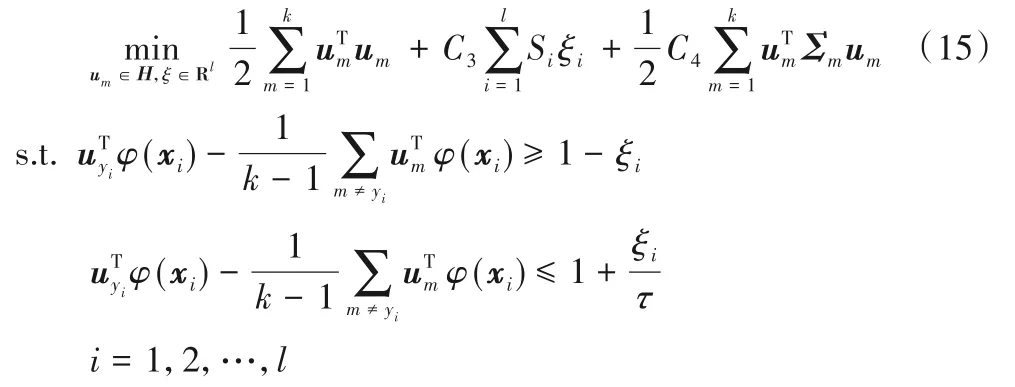
其中:um为第m类样本的分类决策向量:C3、C4是平衡因子且C3>0,C4>0;ξi、Si和Σm分别为松弛变量、样本模糊隶属度和第m类样本的结构信息,τ∈[0,1]为pinball损失参数。其拉格朗日函数为:
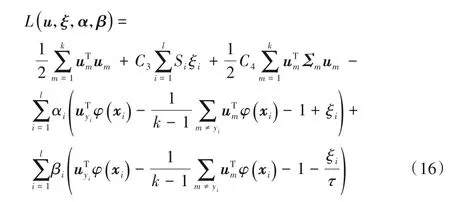
其中α≥0,β≥0为拉格朗日乘子。
将式(16)对变量求偏导并令其等于0得:
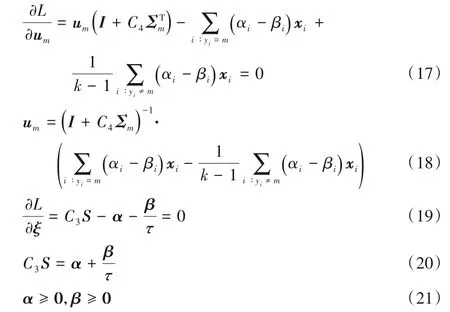
由式(19)和式(21)可得约束条件为:

将式(18)、(20)代入式(16),从而得到式(15)的对偶问题为:

其中:γ=(α-β);S为由样本模糊隶属度构成的向量;G为一个l×l维的矩阵。G的元素为:
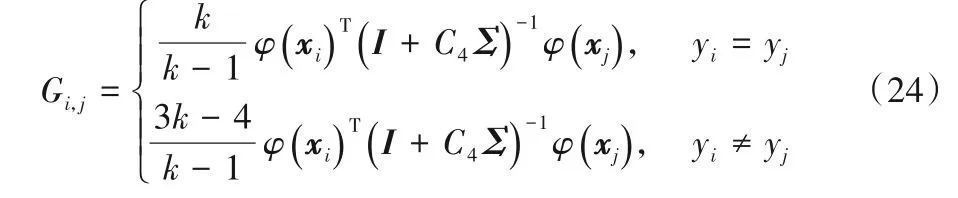
其中I为适当维度的单位矩阵。
通过对其对偶问题进行求解,求得um的值,进而得到如下决策函数:
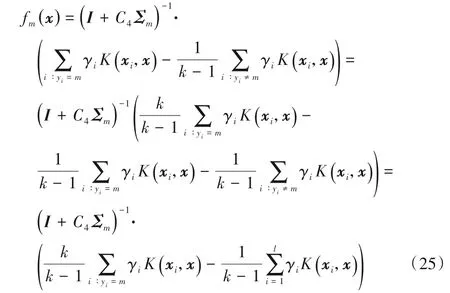
其中K(xi,x)=φ(xi)Tφ(x)。
对于待分类样本x,利用决策函数可确定样本x所属类别,即:
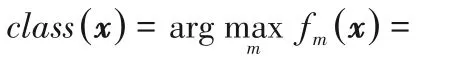
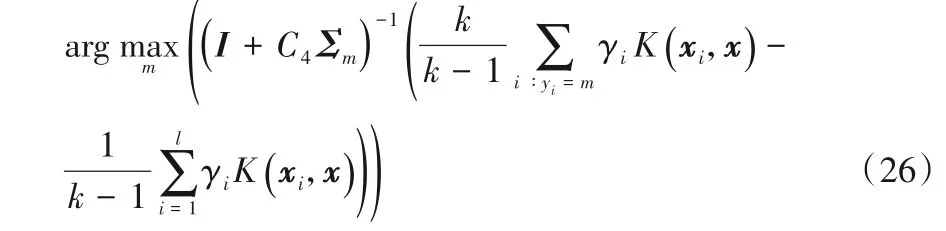
2.3 时间复杂度分析
对Pin-SFSimMSVM 算法的时间复杂度进行分析,该方法针对所有样本直接构造一个单一优化问题,一次性确定所有类的决策函数,并采用了较为简单的损失函数,因此时间复杂度为O(l3),其中l为问题的规模。
3 实验与结果分析
首先,对样本模糊隶属度以及样本结构信息的获取方法进行介绍,实验中采用类中心距离法、模糊C 均值法和S 型方法获取样本模糊隶属度,并分别使用基于距离和基于聚类的方法获取样本结构信息。接着,对提出的Pin-SFSimMSVM 算法的性能进行评估,从线性和非线性两种情况对算法进行实验比较。将SimMSVM[28]、OVO-TWSVM[13]、OVA-TWSVM[14]、Twin-KSVC[19]以及MBSVM[20]等多种多分类算法与所提出的Pin-SFSimMSVM 算法在UCI 数据库[29]中的8 个标准数据集和4 个人工生成的数据集上分别进行实验。此外,在标准数据集中分别加入5%和10%的特征噪声并比较其准确率,以检验算法对噪声的敏感性。结果表明,Pin-SFSimMSVM 算法在标准数据集和人工生成的数据集中都有很好的抗噪性。
3.1 模糊隶属度
为了研究不同样本赋予不同权重时对分类结果的影响,本文将对使用类中心距离法、模糊C 均值法和S 型三种不同方法赋予权重值时的测试结果进行比较。
1)类中心距离法。该方法根据每类中的样本距离该类中心的距离远近来定义其权重,距离类中心点越近的样本权重越大,距离越远权重越小。计算k类中的任意一类中的样本权重Si的方法如下:
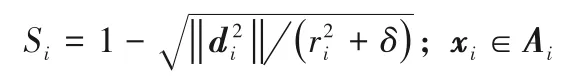
其中:di表示该样本到该类类中心的距离;ri表示该类的半径,即距离类中心最远的样本到中心的距离。
2)模糊C 均值法。该方法将每类样本分为C个簇并使每个样本到C个聚类中心的距离最小,即为每一个样本赋予一个权重,该权重的值表示样本隶属于某一簇的重要程度。任意一类的优化问题如下:
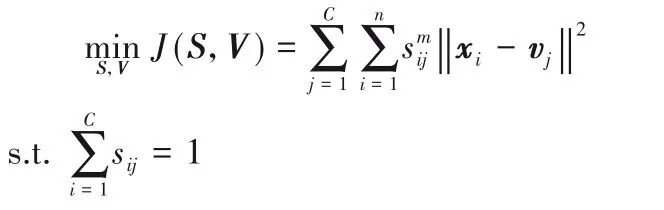
其中:vj为聚类中心;sij为第i个样本在第j个簇中的权重;V和S分别由vj和sij组成;m为模糊加权指数。通过拉格朗日求解该优化问题得到vj和sij的计算式,再通过求解公式迭代更新矩阵S和集合V:
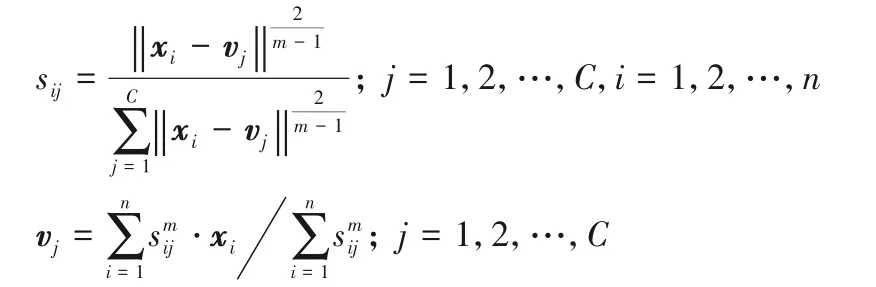
3)S 型方法。与类中心距离法相似,根据样本点距离该类中心的距离远近来确定权重,不同的是,该方法将类中心距离法中的线性函数用如下非线性函数替换:
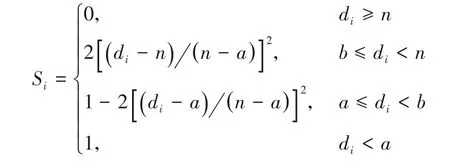
其中:a、b、n均为定义好的参数并满足b=(a+n)/2,且当di=b时,Si=0.5。
3.2 结构信息
同样在算法中加入样本的结构信息可以更好地利用数据样本中潜在的分布信息,本文主要使用以下两种方法来获取结构细信息。
1)类内离散度法求结构信息:用于描述每个类内部的结构信息。设μm为第m类样本的均值向量,nm表示第m类样本的个数,则结构信息可表示为:
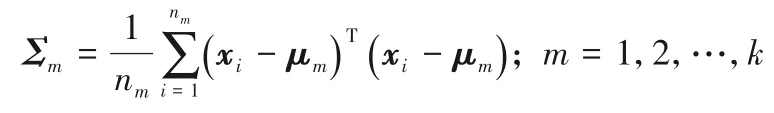
2)基于聚类方法求结构信息:该方法通过对每类样本进行聚类,将其划分成不同的簇,计算出每个簇的聚类信息再求和得到该类的聚类信息。本文中主要使用到的聚类技术有模糊C 均值聚类、层次聚类和C 均值聚类。假设将其中第m类样本聚类成c个簇,则第i个聚类簇和第m类的结构信息可分别表示为:
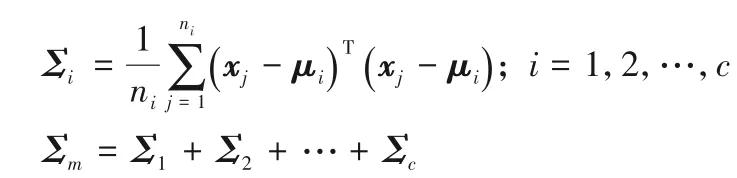
3.3 实验数据集和分类性能评价指标
实验选取Ripley 综合数据集[30]、人工生成的3 个数据集和UCI 标准数据库中的8 个数据集对Pin-SFSimMSVM 算法进行验证。其中Ripley 为二类数据集,共包含250 个训练样本和1000个测试样本,人工数据集中的数据为正态分布下随机生成得到,将其分别命名为Data1、Data2 和Data3。其中,Data1每个类数据按照均值[-5,5]、[5,5]、[-5,-5]和[5,-5],方差[0.40;03]生成。Data2 中共三个类:第一类包含3 个簇,每个聚类簇按照均值[2,-2]、[0,2]和[-4,5],方差[0.70;00.7]生成;第二类包含2 个簇,每个聚类簇按照均值[-5,1]和[-1,0],方差[0.40;03]生成;第三类包含3 个簇,每个聚类簇按照均值[-5,-4]、[-2,-4]和[1,-4],方差[1.50;00.7]生成。Data3每个类数据则按照均值[-4,4,2]、[4,4,2]、[-4,-4,2]、[4,-4,2]和[0,0,2],方差[200;020;003]生成。数据集中的样本数、特征个数、分类数目和每类样本所包含的簇数如表1所示。
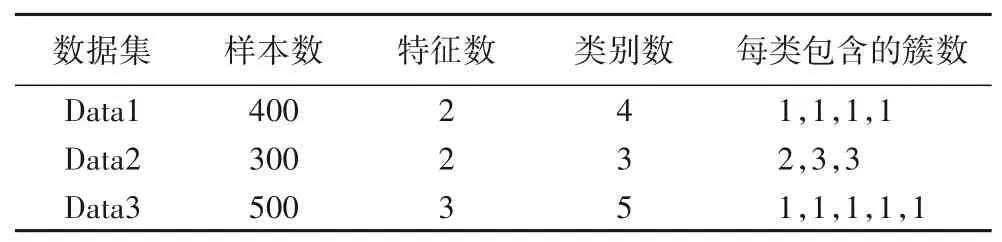
表1 人工数据集特征Tab.1 Synthetic dataset characteristics
选用UCI 数据库中的8 个标准数据集对算法进行验证,它们分别为Iris、Zoo、Glass、Seeds、Ecoli、Balance、Soybean 和CMC,表2中描述了数据集的详细特征。
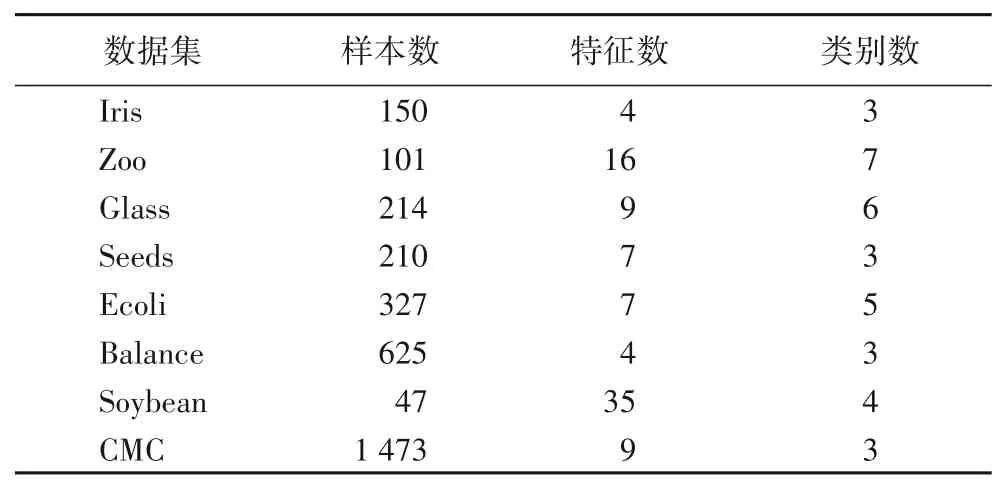
表2 UCI数据集特征Tab.2 UCI dataset characteristics
另外,在分类问题中,分类器的性能评价指标也是选择最优分类器的重要依据。本文中选取的评价指标为分类准确率和标准差,准确率为分类正确的样本与总样本的比,标准差则是算法在数据集上进行10 次分类结果平均值方差的平方根。
3.4 Pin-SFSimMSVM算法实验
将所提出的算法Pin-SFSimMSVM在人工数据集和UCI标准数据集上进行实验,并与SimMSVM、OVO-TWSVM、OVATWSVM、Twin-KSVC 以及MBSVM 这几种常用的多分类算法进行对比。下面介绍实验中用到的参数及参数的选择。惩罚参数C1和C2为平衡因子且大于0,C1值较大时对误分类的惩罚增大,C2值较大时则结构信息所起作用增大;反之亦然。在非线性情况下,使用高斯核函数k(x,y)=作为核函数。当pinball 损失参数τ为0 时,损失函数为铰链损失,因此参数τ在(0,1]取值。为使实验结果达到最优,C1,C2和p在2-4~210进行取值,首先取80%的样本为训练数据集,使用网格搜索和十重交叉验证的方法对4 个参数进行筛选,得到实验结果最优时的各项参数值;并使用得到的最优参数对训练数据进行训练得到决策函数,对测试样本进行分类得到最终的分类准确率。实验中对每种算法均采用10 次测试的平均值和标准差作为最终的评价指标。
为验证所提出算法的分类性能,在表3和表4中分别给出了线性及非线性情况下,已有的5 种用于多分类的算法和本文所提出的Pin-SFSimMSVM 算法在几个人工数据集上的分类准确率和标准差。其中Pin-SFSimMSVM算法使用模糊C均值法获取样本模糊隶属度,并分别使用层次聚类和C 均值聚类方法获取样本的结构信息。
根据表3和表4可以看出,Pin-SFSimMSVM算法在线性和非线性情况中均表现出比SimMSVM 算法更好的性能,且在Ripley、Data1和Data2这3个数据集中均优于其余几种多分类算法。SimMSVM 和Pin-SFSimMSVM 这两种算法对Ripley 数据集和Data1数据集的一次分类结果如图2~3所示,在图中对分类错误的样本点进行了标记。
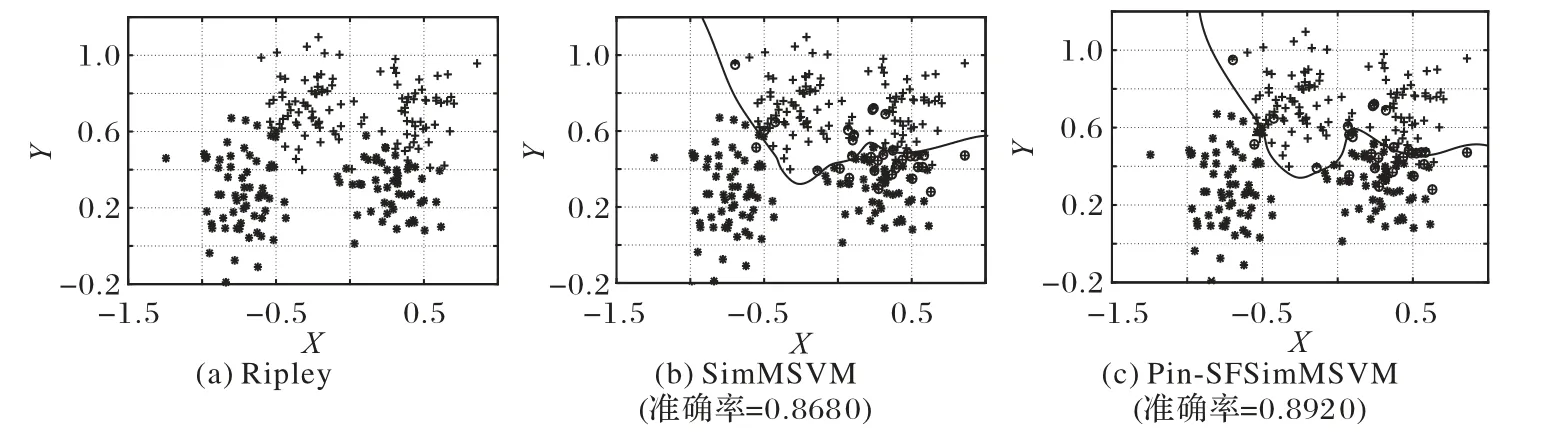
图2 Ripley数据集及使用不同算法在其上的分类结果Fig.2 Ripley dataset and classification results of different algorithms on it

表3 线性情况下不同算法准确率和标准差对比 单位:%Tab.3 Comparison of accuracy and standard deviation of different algorithms in linear condition unit:%

表4 非线性情况下不同算法准确率和标准差比较 单位:%Tab.4 Comparison of accuracy and standard deviation of algorithms in nonlinear condition unit:%
在UCI 数据集上的部分实验结果如表5~6 所示,对每个数据集中实验结果最好的算法进行了标记,其中Pin-SimMSVM 算法为仅使用pinball 损失替换原算法中的铰链损失而不作其他改变得到的算法,和原算法进行对比可以更好地观察不同损失函数对算法分类结果的影响。可以看出,大多数数据集在使用pinball 损失和模糊隶属度后,准确率已有了一定的提升,为了研究pinball 损失参数τ 的变化对分类结果的影响,使用非线性情况下的Pin-SimMSVM 算法对其进行测试,在图4 中给出了在UCI 数据集上Pin-SimMSVM 算法的精度随pinball 损失参数τ 变化的规律,可以看出,随着τ 值的变化,数据集的准确率十分稳定,表明了Pin-SimMSVM 算法的性能是稳定的。
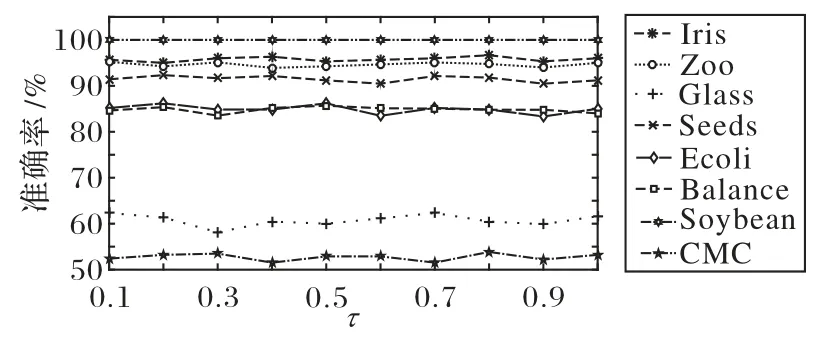
图4 UCI数据集上Pin-SimMSVM算法的精度随τ值变化曲线Fig.4 Accuracy curve of Pin-SimMSVM algorithm varying with τ on UCI datasets
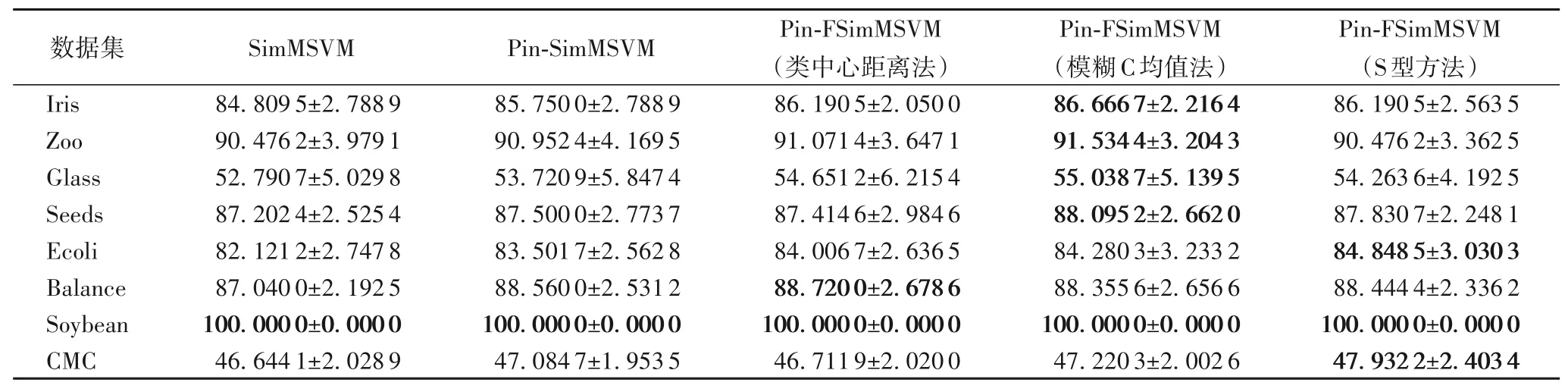
表5 不同算法求取模糊隶属度在UCI数据集上的准确率和标准差对比(线性) 单位:%Tab.5 Comparison of accuracy and standard deviation of different algorithms in solving fuzzy membership degree on UCI datasets(linear)unit:%
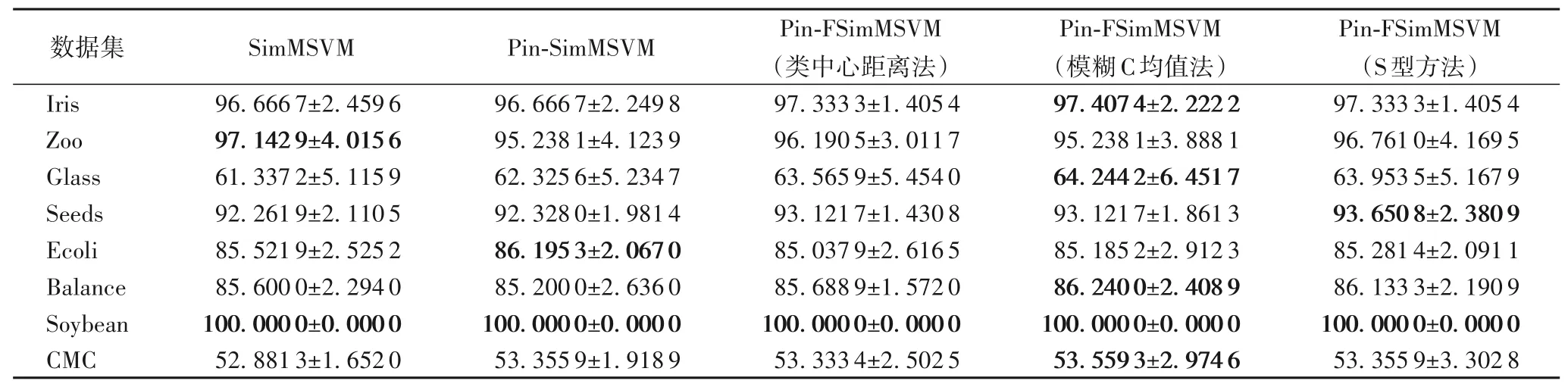
表6 不同算法求取模糊隶属度在UCI数据集上的准确率和标准差对比(非线性) 单位:%Tab.6 Comparison of accuracy and standard deviation of different algorithms in solving fuzzy membership degree on UCI datasets(nonlinear)unit:%
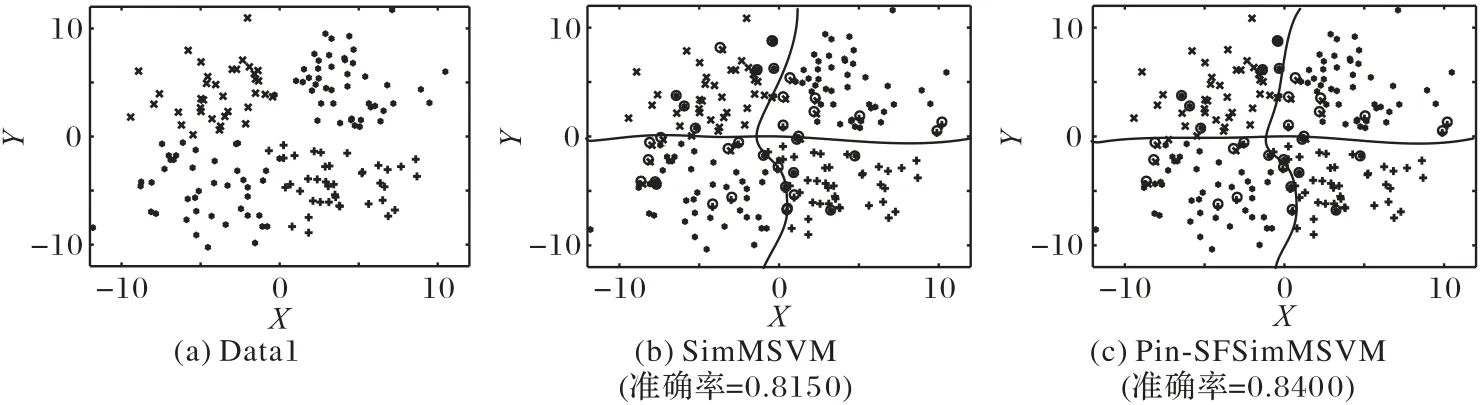
图3 Data1数据集及使用不同算法在其上的分类结果Fig.3 Data1 dataset and classification results of different algorithms on it
为验证不同获取样本模糊隶属度的方法对实验结果的影响,使用在Pin-SimMSVM 算法的基础上引入样本模糊隶属度得到的Pin-FSimMSVM 算法进行实验,分别使用类中心距离、模糊C 均值和S型三种方法获取样本模糊隶属度,根据表5~6的实验结果可以看出,使用模糊C 均值方法获取模糊隶属度的算法在大部分数据集中具有较好的性能:线性情况下在Ecoli、Balance和CMC三个数据集中略低于其他获取模糊隶属度的方法,但相较于SimMSVM算法依然具有优势;非线性情况下,模糊C均值方法和S型方法均具有较好的性能。因此,在后续实验中均选取模糊C均值方法获取样本模糊隶属度。
除此之外,针对选取的UCI 数据集,表7~8 中给出了线性及非线性情况下,使用四种不同获取样本结构信息的算法准确率,根据结果可知,与基于距离的方法比较,基于聚类的方法具有一定的优势,特别是层次聚类其优势较为明显。
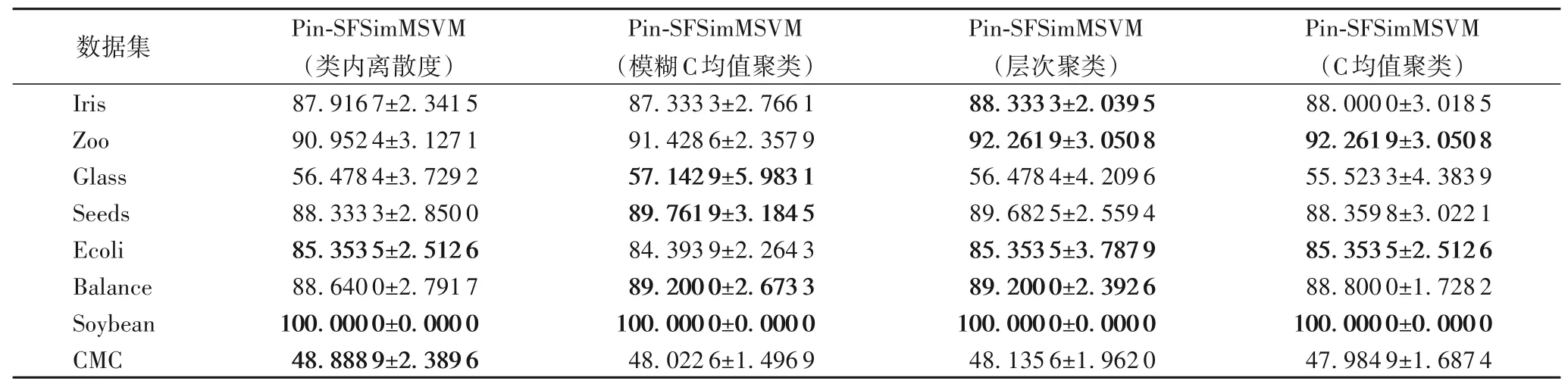
表7 不同算法求取结构信息在UCI数据集上的准确率和标准差对比(线性) 单位:%Tab.7 Comparison of accuracy and standard deviation of different algorithms in solving structural information on UCI datasets(linear)unit:%
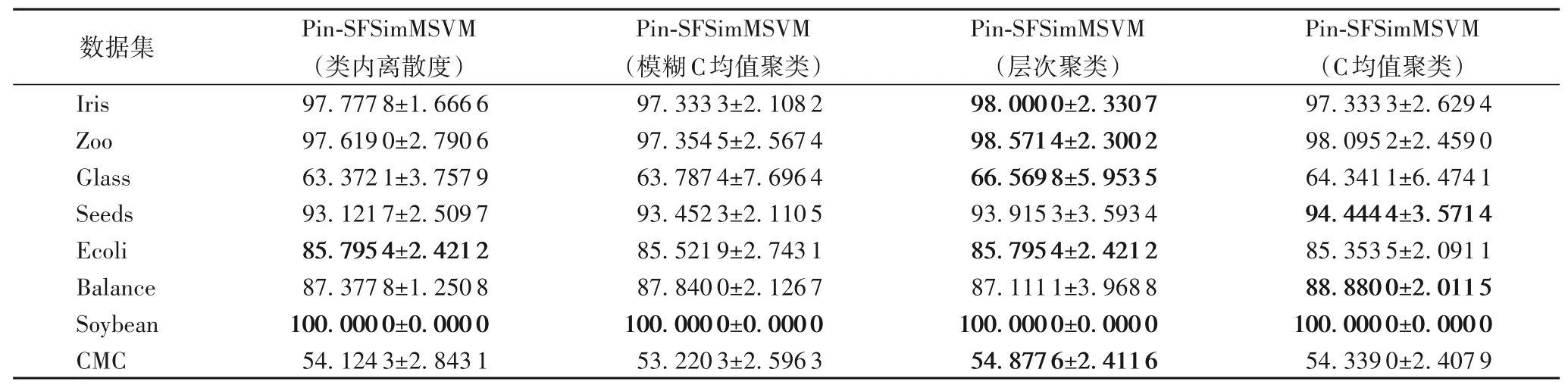
表8 不同算法求取结构信息在UCI数据集上的准确率和标准差对比(非线性) 单位:%Tab.8 Comparison of accuracy and standard deviation of different algorithms in solving structural information on UCI datasets(nonlinear)unit:%
为了验证所提出的Pin-SFSimMSVM 算法的有效性,在标准数据集上进行实验并选取SimMSVM、OVO-TWSVM、OVATWSVM、Twin-KSVC 与MBSVM 算法进行比较;同时,为了检验算法的抗噪性能,在8 个标准数据集中分别加入了5%和10%的噪声数据进行对比实验,噪声数据服从均值为0、方差为1 的高斯分布,实验结果见表9,其中r表示所含噪声比例,结构信息的获取分别使用层次聚类和C均值聚类方法。
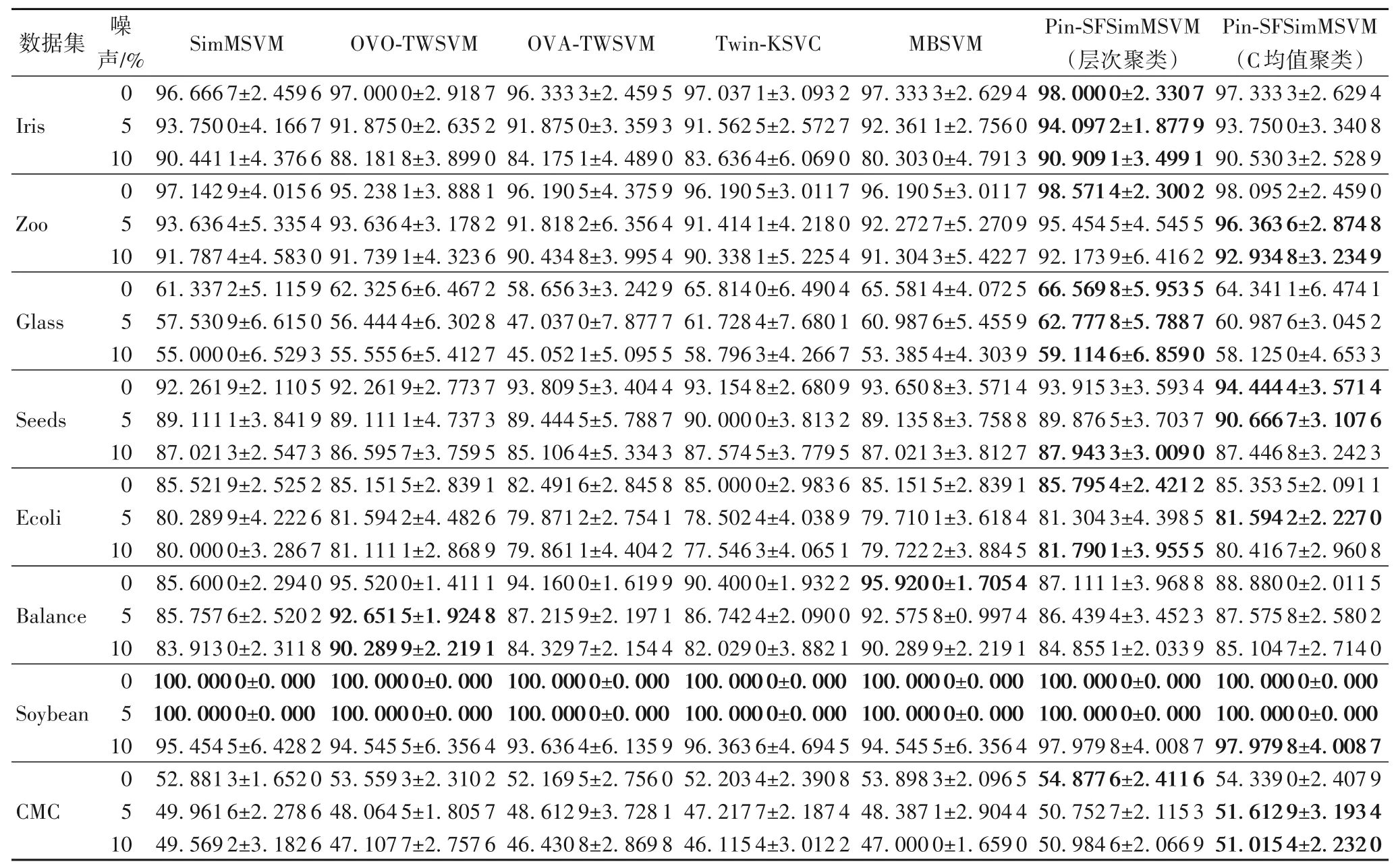
表9 不同算法在UCI数据集上添加噪声的准确率和标准差对比(非线性) 单位:%Tab.9 Comparison of accuracy and standard deviation of different algorithms on UCI datasets with adding noise(nonlinear) unit:%
实验结果表明,在选取的8 个UCI 标准数据集中,Pin-SFSimMSVM 算法在7 个数据集中均表现出优异的性能,尤其是在加入噪声数据后,准确率均高于其他算法,而在Balance数据集中,尽管本文所提出的算法低于OVO-TWSVM 等算法,但仍优于SimMSVM 算法,且在加入噪声后得到的实验结果仍有明显提高,这也表明了所提出的算法对噪声和重采样数据不具有敏感性。
此外,根据表9的实验结果,将Pin-SFSimMSVM 算法的实验结果与其他五种多分类算法的实验结果在8 个标准数据集中进行比较,如表10所示。其含义为将Pin-SFSimMSVM 算法与其他五种不同算法在UCI 标准数据集上的输局/平局/赢局个数,例如Pin-SFSimMSVM 算法与SimMSVM 算法在没有添加噪声情况下相比较的结果为1/1/6,则表明所提出的算法仅1次准确率低于原算法,1次准确率与原算法相等,6次结果优于原算法。

表10 Pin-SFSimMSVM算法与其他算法在UCI标准数据集上的赢局/平局/输局对比Tab.10 Comparison of Pin-SFSimMSVM algorithm with other different algorithms for win/draw/loss on UCI standard datasets
可以发现,本文所提出的算法的性能仅在一个数据集上差于改进前的SimMSVM 算法,但在噪声数据集上优于SimMSVM 算法,与其他算法相比,所提出的算法也具有很高的精度,表明Pin-SFSimMSVM具有更好的噪声不敏感性。
4 结语
本文提出了一种新的用于多分类的支持向量机算法Pin-SFSimMSVM,该算法在SimMSVM 的基础上,基于pinball 损失函数,通过引入样本的模糊隶属度和结构信息,较好地解决了多分类方法存在不可分区域,以及对数据中的噪声和重采样数据敏感等问题,并且在准确率上有很大提升。通过在人工数据集和UCI 标准数据集上对SimMSVM、OVO-TWSVM、OVA-TWSVM、Twin-KSVC 以及MBSVM 等多分类算法的对比实验,验证了所提出算法的有效性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
计算机应用与软件(2021年7期)2021-07-16
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
健康体检与管理(2021年10期)2021-01-03
高中生学习·高三版(2016年9期)2016-05-14
