
用于短文本情感分类的多头注意力记忆网络
2021-12-07 10:08李晓瑜崔建刘齐
计算机应用 2021年11期
邓 钰,李晓瑜*,崔建,刘齐
(1.电子科技大学信息与软件工程学院,成都 610054;2.解放军93246部队,长春 130000;3.解放军95486部队,成都 610041)
0 引言
随着互联网技术的飞速发展,社交网络和电子商务平台已变成最重要的公共信息集散地,利用其中庞大的数据对人们的情感和观点进行分析,有着重要的社会价值和科研价值。情感分析是人们对产品、服务、组织、个人、问题、事件、话题及其属性的观点、情绪、评价和态度的计算研究[1],属于文本分类的子任务。不同于普通文本分类,情感分析要求更高层的语义抽取,技术上更具挑战性。如何利用自然语言处理(Natural Language Processing,NLP)技术对主观意见文本进行情感分析正被越来越多的研究人员所关注[2]。
早期情感分析任务大多采用传统机器学习方法处理,依赖特征工程,需要花费大量时间对背景知识进行收集、整理和抽象。深度学习方法出现后,迅速取代了机器学习成为NLP领域的主流。作为近年来人工智能领域发展最快的研究方向,深度学习模型在各种NLP 任务中被广泛应用。相较于传统的机器学习算法,深度学习不依赖人工构建特征,具有特征的自学习能力,非常适合非结构化文本数据的抽象、高维、复杂等特点。目前,很多研究人员将长短期记忆(Long Short-Term Memory,LSTM)网络与卷积神经网络(Convolutional Neural Network,CNN)等深度学习模型用于解决文本情感分类问题[3-5],并取得了不错的效果。在结合注意力机制后,深度学习模型在NLP 任务中可以抽象更高层次的特征信息、获得更有效的语义表示。基于注意力的深度学习模型不仅有效而且还具有很好的可解释性[6]。
注意力(attention)机制最早由图像识别领域提出,可以让模型有效关注局部特定信息,挖掘更深的特征信息[7]。随后,在自然语言处理领域,注意力机制被验证使得特征提取更加高效。文献[8]中首次将注意力机制与循环神经网络(Recurrent Neural Network,RNN)结合,在编码-解码模型上计算输入序列与输出序列的对齐概率矩阵,有效解决机器翻译问题。文献[9]中提出了在卷积神经网络中使用注意力机制的有效方法,以完成机器阅读理解任务。目前,很多研究人员将注意力机制应用于情感分类领域,取得了很好的效果。文献[10]中在LSTM 网络将目标内容与序列相应中间状态进行拼接,并计算注意力加权输出,有效解决了上下文对不同目标的情感极性问题。文献[11]中基于LSTM 网络提出了两种注意力实现方法:一种方法是将目标词向量拼接到用于注意力权重计算的句子隐藏表示中,另一种方法是将目标词向量与输入词向量拼接。文献[12]中提出了一种基于注意力机制的交互式注意力网络模型,利用与目标相关的注意力从上下文中获取重要信息,同时利用上下文交互信息来监督目标的建模,以提高情感极性预测精度。
为进一步提高情感分类任务的分类精度,研究人员将注意力机制与记忆网络(Memory Network)结构结合,并取得了很好的效果。文献[13]中借鉴深度记忆网络,提出了多跳注意力模型,计算基于内容和位置的注意力值,利用外部存储单元保存上下文对于目标的权值信息,并通过叠加计算获取更深层次的情感语义信息。文献[14]中利用双向LSTM 网络构建记忆力单元,以对多跳注意力网络进行改进,同时对外部记忆内容进行位置加权,在捕获情感特征的同时消除噪声干扰。文献[15]中提出了一种结合多跳注意力机制和卷积神经网络的深度模型,利用记忆网络中多个相同的计算模块,获取更深层次的情感特征信息。
为了使注意力机制对NLP 任务的性能改进更加有效,并且让模型的可解释性更强,创新的结构被不断提出。文献[16]中提出了一种Transformer 模型框架,用来代替卷积神经网络和循环神经网络体系结构,并在机器翻译任务中取得了最好的结果。Transformer 结构中首次提出了自注意力机制和多头注意力,它完全使用attention 机制来建模输入和输出的全局依赖关系,以生成与语义更相关的文本表示,允许模型在不同的表示子空间中学习相关信息。文献[17]中分析了自注意力网络的模型特点,提出了多头注意力与自注意力结合的两种方式,并探讨了其用于情感分析的有效性。文献[18]中基于自注意力网络,提出了一种灵活、可解释的文本分类模型,可以有效提高情感分类精度。文献[19]中将多头自注意力运用于面向目标的情感分析,提出了一种注意力编码网络,可以用来获取每个目标词与上下文之间的交互关系和语义信息。
在情感分类领域,已经有许多研究工作取得了很好的效果,但也存在一些问题。尽管多头注意力机制可以有效挖掘上下文关联信息,但很难进一步获取更深层次的内联关系;另一方面,多跳结构中的记忆力单元只包含原始输入,利用这种不加处理的浅层特征数据,很难通过模块的线性叠加对短文本中的情感语义结构进行有效的编码。为解决上述问题,本文提出了一种短文本情感分类模型,利用n元语法(n-gram)特征信息和有序神经元长短时记忆(Ordered Neurons LSTM,ON-LSTM)网络对原始输入进行加工,以获得更丰富的语义表示。同时,利用改进的多头注意力机制和多跳记忆力网络对短文本上下文内部关联进行有效建模,充分挖掘高层情感语义特征。最后,在电影评论集(Movie Review dataset,MR)、斯坦福情感树(Stanford Sentiment Treebank,SST)-1 和SST-2 三个公开用户评论数据集上对模型进行评估,实验结果验证了所提MAMN 在情感分类任务中的有效性,其分类性能优于实验任务中其他对比的相关模型。
1 相关工作
文本对于情感的表达通常并不直接,观点和态度往往隐含在句法结构和上下文语境中,所以短文本情感分类的关键在于对深层次情感语义特征的充分挖掘和对上下文内在关系的抽象。多头注意力机制和ON-LSTM 网络可以挖掘深层语义特征,对上下文内在结构信息进行有效抽取,而本文也将利用其特性优化模型结构,以提升情感分类精度。
1.1 多头注意力
多头注意力机制可以简单有效地对上下文依赖关系进行抽象,并捕获句法和语义特征。具体来说,输入矩阵Q、K、V对应注意力(attention)计算的三个重要组件,分别为query、key 和value,其中,,其中m、n、dk、dv分别表示矩阵的不同维度。一般框架下的标准attention计算过程如下:

其中fatt表示概率对齐函数,本文采用Scaled Dot Product:

在多头注意力机制中,输入特征通过不同的权值矩阵被线性映射到不同的信息子空间,并在每个子空间完成相同的注意力计算,以对文本潜在的结构和语义进行充分学习,其中第i头注意力计算过程如下:

自注意力是在序列内部进行attention 计算,寻找序列内部的联系。假设输入序列是X,其多头自注意力计算过程如下:

1.2 ON-LSTM网络
有序神经元长短时记忆(ON-LSTM)网络,由传统的LSTM网络演化而来。传统的LSTM 网络可以有效解决文本处理中因上下文长距离依赖而产生的梯度消失和梯度爆炸问题。在此基础上,ON-LSTM 网络通过有序神经元的设计,将树状的层级结构整合到LSTM 中,使其能自动学习到文本的层级结构信息,提高模型的语义抽象能力。ON-LSTM 中通过主遗忘门(master forget gate)和主输入门(master input gate)对神经元进行排序,利用不同的位置顺序来判断信息层级的高低。在这种层级结构中信息被分组进行更新,其中高层信息能够保留相当长的距离,而低层信息可能随着每一步输入而被更改。
ON-LSTM网络的模型结构如图1所示,它改进了LSTM中ct的更新机制,其主要更新过程如式(6)~(14)所示:

图1 ON-LSTM网络的模型结构Fig.1 Model structure of ON-LSTM network
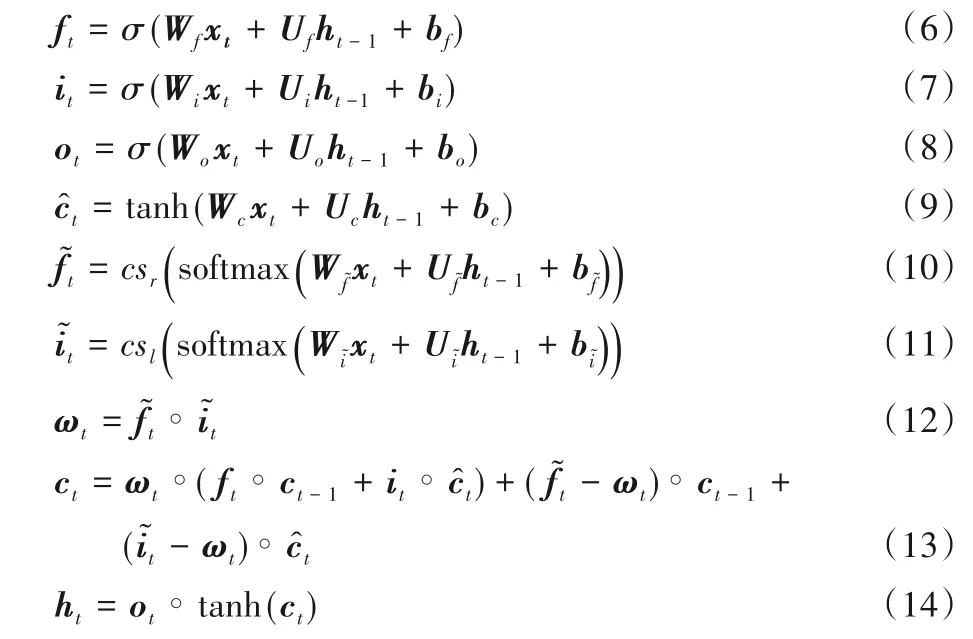
其中:xt和ht-1分别表示当前输入信息和历史隐层信息;σ表示sigmoid 函数;tanh 表示双曲正切函数;“∘”表示向量对应逐位相乘运算。而cs函数定义如下:

2 多头注意力记忆网络模型
为解决短文本情感分类问题,本文在以上研究的基础上提出了一种多头注意力记忆网络(Multi-head Attention Memory Network,MAMN)模型,用于短文本情感分类。该模型主要按照以下两个方面进行构建:
1)利用n-gram 特征和ON-LSTM 网络对多头自注意力机制进行改进,以对文本上下文内联关系进行更深层次的提取,使模型可以获得更丰富的文本特征信息;
2)利用多头注意力机制对多跳记忆网络结构进行优化,以对短文本上下文内部语义结构进行有效建模,充分挖掘高层情感语义特征。
本文模型总体结构如图2 所示,包括词嵌入层、特征抽取层、注意力编码层、多跳记忆结构,接下来将对该模型的实现思路及细节进行描述。
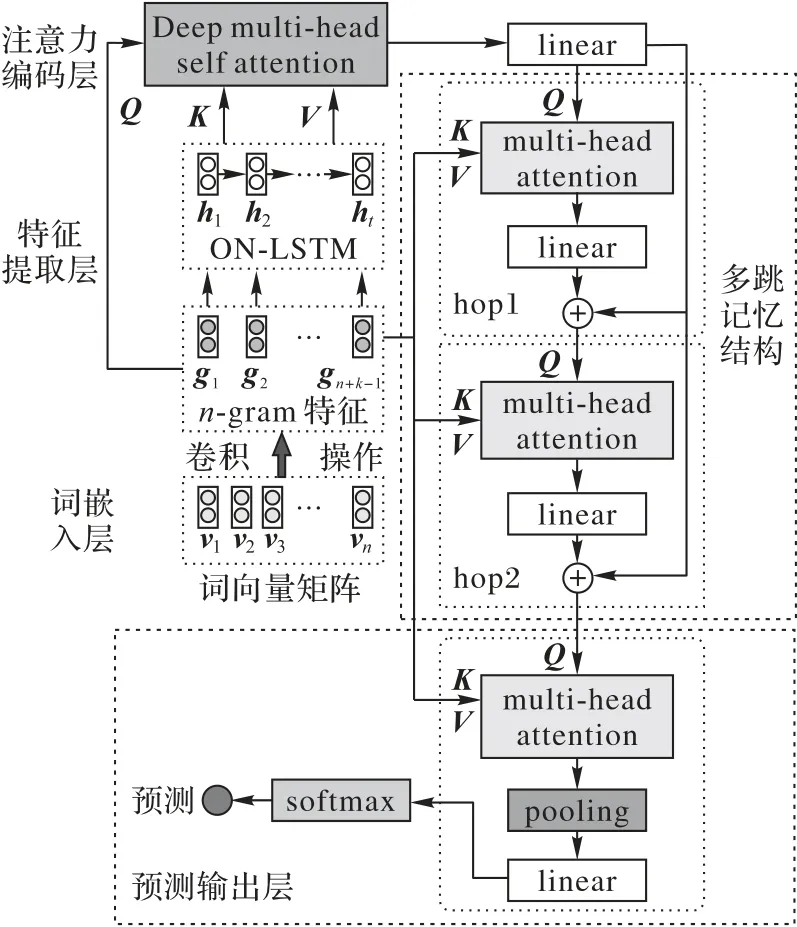
图2 MAMN模型总体结构Fig.2 Overall structure of MAMN model
2.1 词嵌入层
为便于处理,非结构化的文本首先被转换成结构化的低维数值向量。在典型的NLP 任务预处理阶段,文本中的词汇首先使用word2vec、Glove 等算法进行预训练,转换为词向量(word embedding)。在本层中,一个包含n个词的上下文序列可以转换为S={v1,v2,…,vn},其中vi∈Rd,是第i个词的d维向量表示,S∈Rn×d代表句子的输入词向量序列。
2.2 特征提取层
本层主要用于对输入特征作进一步抽象和加工。在自然语言处理任务中,通常使用由语料产生的词库作为模型输入,然而这种浅层的直观特征对于隐含关系的表达并不充分,而简单依靠增加输入特征的数目,并不能有效突破模型的极限预测性能。引入n-gram 词组特征,将输入从浅层特征转换为深层特征,使模型拥有更多的语义信息,以挖掘上下文更多的深层交互特性。通过卷积神经网络生成n-gram 特征,可以在有效处理文本词汇局部相关性的同时,避免n-gram 中对于特征权重的大量概率统计计算,相较于循环神经网络具有更小的训练开销,因此卷积神经网络也被大量用于文本处理问题。
该层将多个卷积运算应用于句子的输入词向量矩阵(context embedding),以提取相应的n-gram 特征,产生新的特征向量序列G={g1,g2,…,gn-k+1},其中,k为一维卷积窗口大小,dp为卷积核个数。
随后,将ON-LSTM 网络应用于得到的n-gram 特征序列,以对短文本中各词组的依赖关系进行建模,并挖掘其隐含语义,同时获取短文本上下文内部层级结构信息。最后采用ON-LSTM网络得到的隐藏状态H={h1,h2,…,hn-k+1}作为原始文本的高层特征表示,其中,dq为网络隐藏层维度。
2.3 注意力编码层
标准的多头注意力模型中,以上下文序列中的单个词作为基本处理单元,这使得句子隐含的语义和结构信息被忽视。实际应用中,单纯依靠增加头部数量,也很难提高多头注意力模型的性能,表明其在多维信息空间中的提取和学习能力并没有得到充分发挥。
受Hao 等[20]研究的启发,本文将n-gram 特征与多头自注意力模型结合,提出了深度自注意力机制,引入相邻词汇组合形成的语义特征,使多头注意力机制能在多维特征空间中学习更多隐藏信息,以更好地预测目标情感极性。
在深度自注意力中,首先对输入特征序列进行抽象转换,将得到的高层表示加入模型以对标准自注意力机制进行扩展。本文采用ON⁃LSTM 网络对输入的n-gram 特征序列G作进一步抽象,深度自注意力具体计算过程如下:

2.4 多跳记忆结构
记忆力网络最早由Facebook AI在2015年提出[21],其研究人员将LSTM 网络中类似的内部标量记忆单元扩展成为外部向量记忆模块,以解决NLP任务中涉及的复杂语义计算问题。MAMN模型将多头注意力机制和外部记忆单元结合构造独立计算模块(hop),并将计算模块叠加,形成多跳(hops)深度记忆网络。这种多跳注意力递归深度记忆结构,相较于普通链式深度网络可以在更短路径上获得长距离依赖,并且相较于浅层模型可以学习到更高级别的抽象数据表示[22-23]。由于每个计算层的运算都有外部原始记忆单元内容参与,可以使模型一直关注历史信息,通过足够跳数的计算层堆叠转换,可以使模型学习到文本内部蕴含更加复杂、抽象的非线性特征。因为所有的输入n-gram特征借由注意力的递归计算过程充分交互,也使得文本特征间的远程依赖关系得到更充分的建模。
模型在运行多跳结构之前,先将注意力编码层的输出进行线性变化(Linear),生成历史信息记忆

由于每一个计算层作为独立模块,拥有相同的处理流程,用第i个计算层来说明计算过程:

2.5 预测输出层
本层作为模型的最后一层,负责将多跳记忆结构的输出进行再加工,最后通过softmax函数来计算各类的输出概率。

最后,为了可以充分对短文本上下文序列蕴含的句子结构以及语义信息进行建模,MAMN 模型采用了多种粒度的词汇组合(2-gram,3-gram 和4-gram),以扩展多头注意力信息子空间规模,丰富语义表达。整个模型的数据处理架构如图3所示。
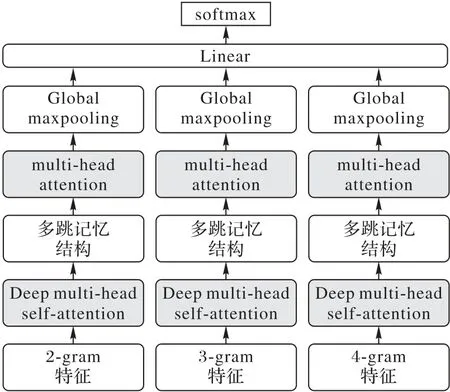
图3 MAMN模型的数据处理架构Fig.3 Data processing architecture of MAMN model
2.6 预测输出层
由于在情感分类任务中,情感极性通常被定为“正面”“负面”和“中性”等,属于典型的文本多分类任务,于是MAMN 的损失函数选择交叉熵,并通过对其最小化来优化模型。交叉熵损失函数如式(27)所示:

其中:D为训练数据集大小;C为类别数;P(i,j)是模型预测样本i为类别j的概率;Q(i,j)为1或0,表示模型分类结果是否正确;λ‖θ‖2为正则项。
3 实验与结果分析
3.1 实验数据
本文在两类基准数据集上开展实验,即电影评论集(MR)[22]和斯坦福情感树(SST)[23]数据集。MR 和SST 都被广泛应用于短文本情感分类任务模型的性能评估,本文在这两个数据集上将MAMN 与同类任务模型进行性能对比,数据集具体细节统计如表1所示。

表1 实验数据统计Tab.1 Experimental data statistics
1)MR:该数据集数据抓取自专业英文电影评论网站,包含“积极”和“消极”两类情感倾向的电影评论短文本,各5331条。测试一般采用随机分割,十折交叉检验。
2)SST-1:该数据集是对MR 的进一步扩展,是一个具有完全标记的解析树的语料库。它拥有11855 条电影评论,但是数据按照“非常消极”“消极”“中性”“积极”和“非常积极”分为了五类。
3)SST-2:该数据集为SST 的二进制标记版本。其中,“中性”评论被删除,“非常积极”和“积极”的评论被标记为“积极”,“非常消极”和“消极”的评论被标记为“消极”。它总共包含9613条评论,其中1821条用于模型测试。
3.2 实验设置
词嵌入层使用Glove预训练模型,词向量在训练过程中固定不变,维度设置为300,学习率设置为1E-3,模型最后运行于NVIDIA RTX 2080Ti GPU,采用分类精度(accuracy)值来对其性能进行评价,其他通用超参数设置如表2所示。

表2 模型超参数设置Tab.2 Hyperparameter setting of model
3.3 模型性能对比
为了评价MAMN 模型在三个数据集上的性能,引入多种典型模型进行实验对比,其中包括一些性能基线方法和最新研究成果。以下详细介绍了所有比较模型:
1)RAE(Recursive AutoEncoder)[24]:该模型基于递归自动编码器构造,可对复杂构词短语的空间向量表示进行学习,以对句子情感极性标签的所属概率进行预测。
2)矩阵-向量RNN(Matrix-Vector RNN,MV-RNN)[25]:该模型是一种递归神经网络,可以学习任意句法类型和长度的短语,获得句子的组合向量表示。模型为解析树中的每一个节点分配一个向量和一个矩阵,以抽象相邻词语的组合情感语义。
3)递归神经张量网络(Recursive Neural Tensor Network,RNTN)[23]:该模型是一个基于情感语义解析树结构的递归深层神经网络,利用张量特征对解析树上不同维度的子节点之间的相关性进行建模,抽象组合情感语义。
4)CNN-non-static[26]:该模型将一个预训练的word2vec 词向量模型与卷积神经网络相结合,并在每个任务的训练过程中对词向量进行微调。
5)CNN-multichannel[26]:该模型同时采用两个词向量集,每一组向量都被视为一个“通道”,并将每个滤波器同时对两个通道进行卷积操作。模型能动态微调一组向量,同时保持另一组向量为静态。
6)RNN-Capsule[27]:该模型将RNN 与胶囊网络相结合,并在胶囊网络中采用注意力机制,利用概率模块对输出胶囊进行重构以抽象更高层次的情感语义表达。
7)Capsule-CNN[28]:该模型将卷积神经网络和胶囊网络相结合,实现了一种多级胶囊的通用文本分类处理架构,并针对特定的文本分类任务对胶囊网络中的动态路由算法进行了优化。
8)BiLSTM-CRF(Bi-directional LSTM with Conditional Random Field)[29]:该模型将序列结构和卷积神经网络结合,提出了一种用于文本情感分类的流水处理框架。首先将文本按照所包含的情感目标数分为不同类型,然后采用一维卷积操作分别对每类文本进行情感特征检测。
本文用分类精度作为评测指标,各模型分类实验结果如表3 所示。可以看出,MAMN 模型在三个基准数据集上都有良好表现,特别是在MR数据集上显著提高了分类性能。
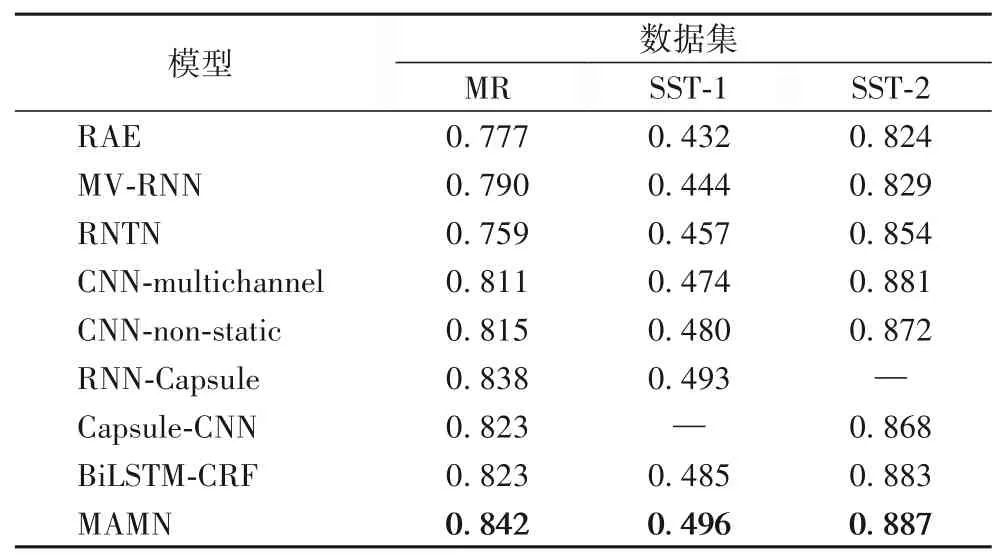
表3 不同模型在三个数据集上的分类精度Tab.3 Classification accuracies of different models on three datasets
在基线模型中,RAE、MV-RNN 和RNTN 都采用了简单的深度学习算法,整体分类性能偏低。其中:RAE模型只简单使用了空间向量特征和自编码器,分类精度最低;MV-RNN 在空间向量的基础上,利用相邻词汇的组合特征对情感分类进行改善;而RNTN 通过融入情感语义解析特征,进一步改善性能,尤其在SST两个数据集上性能提高明显。
从实验结果上看,采用循环神经网络和卷积神经网络结构的复杂深度学习模型在所有数据集上的表现都显著且持续地优于简单的深度学习算法。除了模型结构复杂度增加,预训练词向量的使用也是性能改进的关键原因。其中,CNNnon-static 和CNN-multichannel 都采用了CNN 结构,但在不同数据集上互有优劣,可见单纯靠增加不同词向量集并不能有效改善模型性能,而对词向量进行微调可以充分挖掘潜在语义特征;RNN-Capsule 和Capsule-CNN 都采用了胶囊网络与普通深度模型相结合的架构,以对高层情感语义特征进行抽象,其中RNN-Capsule 在MR 和SST-1 上都有优异表现,说明注意力机制的引入,可以让模型有更好的内部关联挖掘的能力,能在二分类和多分类任务中更有优势;BiLSTM-CRF 模型利用LSTM 和CNN 相结合,设计了多级流水结构将模型的深度继续加深,以提高特征的表征能力,并在SST-2 数据集上取得参考模型的最好分值。
MAMN 模型在MR、SST-1 和SST-2 这三个数据集上相较对比模型的最好分值分别提高了0.4个百分点、0.3个百分点和0.4 个百分点。可见多头注意力机制的采用、记忆模块的参与以及多跳结构对模型深度的加深,都对分类性能提升起到了重要作用。所提模型在二分类和多分类任务中都表现出分类的有效性和性能的稳定性。
3.4 模型结构性能分析
为进一步验证MAMN 模型的多跳记忆结构对性能改善的有效性,同时考察模块跳数设置对分类精度的影响程度,在三个数据集上对跳数取不同值进行对比实验,以评价各个数据集上的最优跳数设置。在实验中,将跳数预设范围定为1~7,对应着记忆结构模块不断增加。另外,整个实验过程模型的超参数集合均保持不变,实验结果如图4所示。

图4 三个数据集上MAMN模型在不同跳数下的分类性能Fig.4 Classification performance of MAMN model with different hops on three datasets
从实验结果的数据可以看出,其中,MR 数据集最优跳数取值为4,对应分类精度为0.842;SST-1 数据集最优跳数取值为3,对应分类精度为0.491;SST-2数据集最优跳数取值为5,对应分类精度为0.887。从实验中很容易发现,模型在三个数据集上都表现出同样的规律,即随着跳数取值的增加,分类精度不断升高,并在堆叠特定数量的记忆模块时达到最优,随后性能明显下降。这表明,多跳结构的设计可以使模型深度得到扩展,让情感语义信息的提取层次更高、更加有效,从而直接改善模型的分类性能。并且,记忆结构的设计也极大增强了模型的扩展性,因为模块具有相同的代码和接口,使得工程实施变得简单。需要注意的是,记忆模块的过度叠加,也会给模型带来过拟合的风险,导致性能下降。
4 结语
针对短文本情感分类问题,本文提出了一种多头注意力记忆网络模型。该模型一方面利用卷积神经网络从输入序列中提取n-gram 信息,结合改进的多头自注意力机制对上下文内部关联进行有效挖掘;另一方面引入多跳记忆结构,对模型深度进一步拓展,同时通过对记忆模块内容的递归操作,也使得模型可以挖掘更高层次的上下文情感语义关系。最后,在MR、SST-1 和SST-2 这三个数据集上对模型进行评估,实验结果表明MAMN 与流行的基线模型和最新的任务相关模型相比,分类性能都显著优于其他模型,充分验证了其在短文本情感分类任务中的有效性。另外,结构性能分析实验也验证了多跳结构对于模型分类性能提升的重要作用。
在接下来,我们希望将更加灵活多样的注意力计算方法用于文本内部关联语义特征提取,可以为记忆力单元生成更复杂、抽象层次更高的数据内容,让语义信息建模更加高效合理。另外,多跳记忆模块中可以加入其他辅助信息,如考虑将位置信息、词性和先验知识作为补充,针对特定任务优化模型。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
中学英语之友·高一版(2008年10期)2008-12-11
