
基于胶囊网络的交互式网络电视视频点播推荐模型
2021-12-07 10:09高铭蔚桑楠杨茂林
计算机应用 2021年11期
高铭蔚,桑楠,杨茂林
(电子科技大学信息与软件工程学院,成都 610054)
0 引言
随着信息技术的高速发展以及互联网的大规模普及,信息爆炸使人们进入了信息过载时代。搜索引擎和推荐系统是解决信息过载的两种主要技术,前者需要使用者提供关键词来获取信息,而后者则通过分析使用者的历史行为信息获取其兴趣偏好并主动给用户推荐其感兴趣的信息[1]。近年来,推荐系统已经广泛应用于各种互联网平台,例如淘宝的商品推荐、今日头条的新闻推荐、抖音的短视频推荐等。
当前深度学习广泛应用于推荐系统领域,通过学习样本数据的多种内在规律和多维表示层次,实现自适应的差异化信息推送和用户的个性化服务。在交互式网络电视(Internet Protocol Television,IPTV)应用中,一个电视终端往往由多名家庭成员共享,不同成员的兴趣偏好往往不同。因此,正确分析隐藏在同一终端ID 后的多成员兴趣偏好是进行IPTV 视频点播个性化推荐的关键。
经典推荐算法通常对家庭组的视频点播数据进行统一建模,这种建模方法会使得推荐系统侧重于家庭组整体的兴趣偏好而难以满足不同家庭成员的独特兴趣偏好。为此,本文提出了一种基于胶囊网络的IPTV 视频点播的推荐算法CapIPTV,以解决多用户共享同一IPTV 终端的差异化推荐问题。首先,利用胶囊网络对每个终端的历史行为进行聚类,将具有较高相似性的点播视频聚集在一起,聚类后的多个结果表示终端背后不同匿名成员的多种类型兴趣偏好。其次,根据多种兴趣偏好为IPTV 终端召回多种类型的点播视频以满足不同家庭成员的需求。实验结果显示,该策略可以更好地提取出每台IPTV 终端背后多名家庭成员的兴趣偏好,有效提升对IPTV视频点播的推荐效果。
本文的主要工作如下:
1)提出了一种基于胶囊网络的IPTV 视频点播推荐模型,通过胶囊网络提取不同家庭成员的兴趣偏好,从而充分满足多名成员的差异化需求;
2)利用注意力机制动态赋予不同兴趣偏好以不同的注意力权重,使得感兴趣程度更高的兴趣偏好能够获得更多的曝光度。
1 相关工作
1.1 IPTV推荐算法
推荐算法在电视领域的应用最早由Das 等[2]开始。早期研究主要对经典推荐算法加以改进,使其适应电视视频推荐的基本数据要求。Yu等[3]提出了一种针对多用户共享的电视节目推荐算法,利用群组内所有观众的偏好组合成一个群组的偏好,并采用平均策略为群组成员进行推荐,从而提高群组整体的满意度。Kim 等[4]提出了一种基于协同过滤的IPTV 个性化推荐算法,将观看时长转化为隐式评分。Shin 等[5]提出了一种混合多模式的推荐算法,结合基于分类的方法和基于关键字的方法,提出了一种基于关系的相似性度量,以提高分类内容的评分精准度。Teng等[6]提出了一种基于协同过滤的推荐相似度计算方法,利用评分、观看和收藏三种用户行为进行历史行为数据挖掘,以评估不同类型的行为与用户兴趣的关系。
1.2 基于深度学习的推荐算法
鉴于深度学习在计算机视觉和自然语言处理方面取得了显著的应用效果[7],研究者将深度学习技术广泛应用于推荐系 统[8]。Covington 等[9]在2016年构建了基于深度学习的YouTube 个性化推荐系统并且提供了设计、迭代和维护大型复杂推荐系统的实践经验。Zhou 等[10]提出了DIN(Deep Interest Network)推荐模型,利用注意力机制学习用户兴趣偏好的表达形式,并在阿里巴巴的个性化广告推荐系统中成功部署,取得了较好的效果。Xiao 等[11]提出了DMIN(Deep Multi-Interest Network)推荐模型,利用多头自注意力机制提取用户的多兴趣偏好,从而提升点击率预估效果。Tang 等[12]使用卷积神经网络对用户行为进行建模并提供了一个统一而且灵活的网络结构。各种类型的深度模型已经在推荐系统领域引起了广泛的关注,如何利用全连接深度神经网络建模表示用户物品交互数据受到了重点关注。其中,He 等[13]提出了NCF(Neural Collaborative Filtering),Guo 等[14]提出了DeepFM以及Xue等[15]提出了DMF(Deep Matrix Factorization)。
1.3 胶囊网络
胶囊网络是由Hinton 等[16]在2011 年首次提出的一种全新的深度学习神经网络,其最初被用来改变卷积神经网络(Convolutional Neural Network,CNN)和循环神经网 络(Recurrent Neural Network,RNN)的局限性。带有转化矩阵的胶囊网络可以自动学习到整体与部分之间的关系,从而作为一种层次结构来对特征之间潜在的复杂关系进行建模。胶囊网络用一个向量来表示一个神经元,一个胶囊就是一个向量。Sabour 等[17]提出用胶囊网络的向量输出代替CNN 的标量输出特征检测器,用动态路由协议代替最大池化,确保低层次特征可以选择性地聚合成高层次特征。与CNN 的最大池化不同,胶囊网络可以避免丢失待检测部分在整个区域内的精确位置信息。
Li 等[18]将胶囊网络引入推荐系统领域,提出了一种基于动态路由机制的推荐算法模型MIND(Multi-Interest Network with Dynamic routing),利用胶囊网络聚类用户的历史行为,从而获取用户对于不同类型商品的兴趣。Li等[19]提出了一种基于双向路由机制的情感胶囊网络的用户评分预测模型,该模型从用户的评论数据中提取信息逻辑单元并判断用户对物品的情感,从而解释用户偏好。
已有胶囊网络研究还未充分考虑IPTV 视频点播推荐背景下中如何通过多个兴趣向量共同表示一个终端兴趣偏好的问题。本文针对该问题,在多家庭成员共享同一终端的前提下,提出了基于胶囊网络的IPTV视频点播推荐算法。
2 模型结构
2.1 问题阐述及相关定义
本文重点关注IPTV 视频点播场景下的推荐问题,相关问题和定义阐述如下:
IPTV 视频点播推荐系统的目标是为每一个电视终端t∈T从数万级的点播视频池I中最终筛选出数十个可能感兴趣的点播视频i∈I。为了实现这个目标,推荐系统利用终端历史行为数据It构建推荐算法模型。
为了能更好地阐述本文算法的模型,表1 给出了本文所用到的相关符号及其含义。
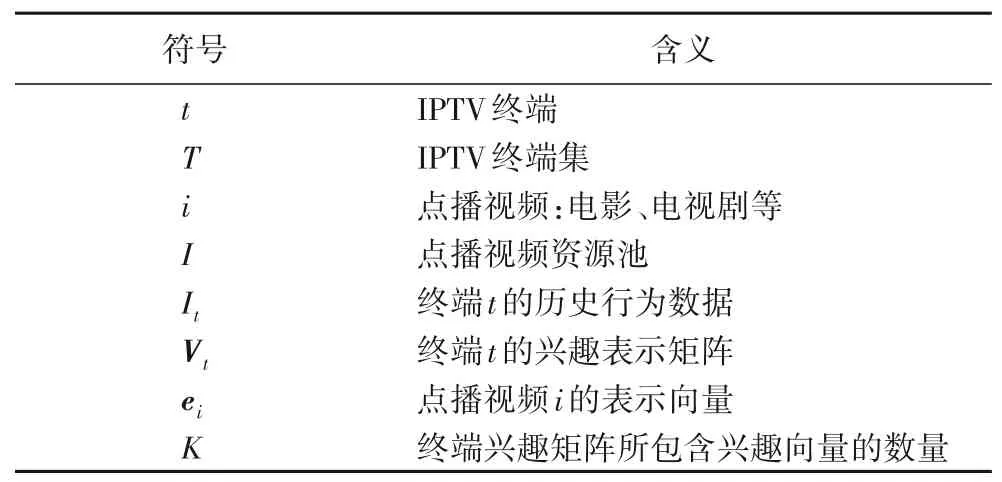
表1 IPTV推荐模型符号定义Tab.1 Symbol definition for IPTV recommendation model
定义1终端历史行为数据It是终端与点播视频的交互数据,包括曝光、浏览、点击、观看、购买、收藏等多种不同类型的行为数据信息。
定义2表示终端t所对应的向量化表示,其中d表示单个兴趣向量的维度大小,K表示一个终端兴趣矩阵所对应的兴趣向量的个数。当K=1 时,表示仅使用一个兴趣向量来表示一个终端。
定义3ei∈Rd×1表示点播视频i所对应的向量化表示,其中d表示点播视频向量的维度大小,点播视频向量的维度大小与兴趣向量的维度大小相同。
本文的核心任务是训练一个函数,可以通过输入行为数据It,得到终端的兴趣表示矩阵Vt。由于一个终端兴趣具有多种不同类型的兴趣偏好,因此一个终端的兴趣表示矩阵Vt由多个不同的兴趣向量组合而成。

当通过模型学习到终端t的兴趣表示矩阵Vt和点播视频i的表示向量ei之后,可以通过计算得到每一个终端兴趣矩阵Vt的每一个兴趣向量对于每一个点播视频ei的评分。选取多个兴趣向量的评分最大值作为终端兴趣矩阵Vt对于点播视频i的评分,这个评分可以反映出终端对于点播视频的喜爱程度。通过对评分进行排序,取前N个评分最高的点播视频作为最终推荐结果。

2.2 CapIPTV推荐模型框架
如图1 所示,CapIPTV 推荐模型结构分别由嵌入层、用户兴趣生成层、全连接层、注意力层构成,其核心是用户兴趣生成层,输入是终端的历史行为记录,而输出则是终端的兴趣矩阵Vt和点播视频的表示向量ei。

图1 CapIPTV推荐模型结构Fig.1 Structure of CapIPTV recommendation model
模型训练是为了得到终端的兴趣向量和点播视频的表示向量。模型部署时需要将训练得到的向量部署在服务器端,以便于及时响应来自电视终端的推荐请求。
2.3 嵌入层
本文所提出的CapIPTV 模型的输入是终端行为数据,包括终端ID 和其点击观看过点播视频ID。由于IPTV 推荐系统中包含数以万计的点播视频和终端,并且这些ID 特征具有高维度和稀疏性的特点,因此可以利用推荐系统中常用的嵌入方法,将ID 特征转化为低维度稠密特征向量,从而减少模型中参数量,加快模型的训练速度。对于点播视频而言,其表示向量共享同一个嵌入空间,嵌入空间可以表示为E∈Rd×|N|,|N|表示点播视频池的大小,d表示该嵌入空间的维度大小。
2.4 用户兴趣生成层
2.4.1 兴趣矩阵
为了学习到同一个IPTV 终端ID 背后多个家庭成员的兴趣偏好,本文采用聚类算法将同一个终端的历史交互点播视频数据聚合成多个不同的类。同一个类中的点播视频具有较高的相似度,不同类之间的点播视频相似度较低,从而可以通过一个类来表示一种特定类型的兴趣偏好。为此,本文设计了用户兴趣生成层,从终端的历史交互点播视频数据中提取多名家庭成员的不同兴趣偏好。该层利用胶囊网络强大的向量化特征表示能力以及基于动态路由机制的特征整合能力,从终端的历史行为数据中提取多名家庭成员的不同兴趣偏好,以提升推荐准确度。
通过用户兴趣生成层所得到的兴趣矩阵,其中每一个兴趣向量都可以表示一种特定类型的兴趣偏好。每一个终端对这种类型的兴趣偏好的喜爱程度可以用兴趣向量的模长大小表示。兴趣向量的模越长,该向量所对应的偏好出现的概率越高。为了实现这种特性,定义了一个胶囊网络版的非线性激活函数squash。该函数将输入向量的模长取值范围压缩到[0,1],确保短向量长度压缩到接近0,而长向量长度压缩到接近1,同时保持胶囊j总输入向量sj与输出向量uj方向相同。
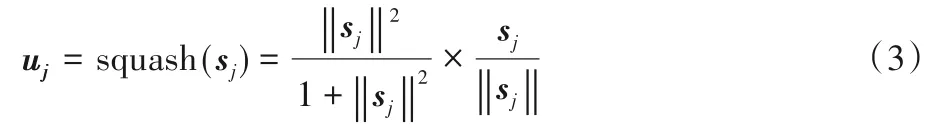
用户兴趣生成层的输入最终会经过一个非线性激活函数squash得到兴趣矩阵。
2.4.2 动态路由机制
本文设计了一个拥有两层胶囊网络的用户兴趣生成层,利用动态路由机制从一个终端的历史交互点播视频数据中提取多名家庭成员的多兴趣表达。第一层胶囊层的每一个输出向量传递到合适的第二层胶囊层作为第二层胶囊的输入,从而构建出第一层胶囊与第二层胶囊之间的潜在关系。
如图2 所示,第一层胶囊网络称为终端胶囊层,第二层胶囊网络称为用户胶囊层。当输入数据进入终端胶囊层后,可以通过如算法1 所示的动态路由算法计算出用户胶囊层。在每次迭代中,给出一个终端胶囊i∈{1,2,…,m},其表示向量为,Nt表示终端胶囊ti的维度,可以得到用户胶囊j∈{1,2,…,n},其表示向量为,Nu表示用户胶囊uj的维度。
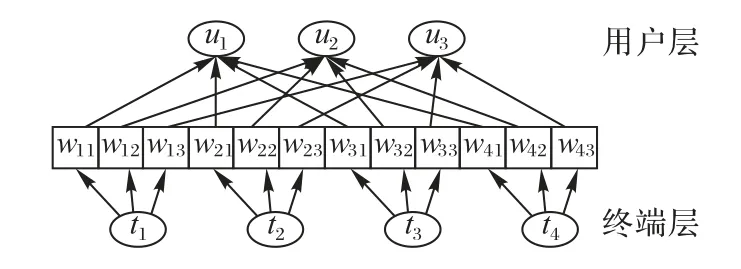
图2 用户兴趣生成层模型结构Fig.2 Structure of user interest generation layer model
对于用户胶囊j而言,其输出uj是其输入sj通过压缩激活函数squash 得到的,而输入到用户胶囊层的sj则是通过所有终端胶囊层作出的预测输出向量加权和计算得到。

cij是由动态路由迭代过程所确定的耦合系数,终端胶囊ti与用户胶囊层中所有胶囊之间的耦合系数总和为1,表示终端胶囊ti与用户胶囊uj之间的权重链接,耦合系数cij通过bij计算而得。

2.5 全连接层
为了提高模型的泛化能力,在用户兴趣生成层的后面加入了全连接层网络,并使用relu作为非线性激活函数。

2.6 注意力层
通过用户兴趣生成层,利用终端的历史行为生成了多个用户兴趣胶囊,不同的兴趣胶囊代表了终端不同类型的兴趣偏好。利用用户兴趣胶囊表示终端对某种偏好的喜爱程度,在模型训练过程中,基于注意力机制设计了一个注意力层[10],利用目标点播视频从而动态调节用户胶囊层多个胶囊之间的权重。注意力层模型结构如图3所示。

图3 注意力层模型结构Fig.3 Structure of attention layer model
对于一个目标点播视频而言,可以得到多个兴趣向量和这个目标点播视频的向量,通过计算出目标点播视频与每一个兴趣向量的匹配程度,将终端的多个兴趣偏好向量的加权和作为这个终端对于目标点播视频的终端表示向量。
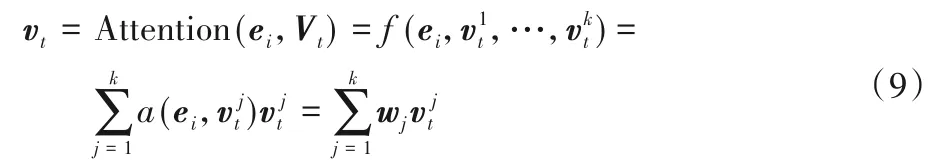
2.7 模型的训练和部署
对于工业级推荐系统来说,模型的训练和部署是独立的。随着行为数据的不断增长,推荐模型需要定时训练以更新模型内部的参数。经过训练后的模型会在线部署,以便于推荐请求访问模型获取最新推荐结果。
2.7.1 模型训练
当得到每个终端的最终兴趣向量vt和每个点播视频的兴趣向量ei后,通过计算得到某个终端t对于某个点播视频i∈It的感兴趣程度。
模型的目标函数是最大化感兴趣程度P(i|t),即最小化损失函数loss。

模型训练迭代过程中,将终端t的第n次交互点播视频作为目标点播视频,利用终端的前n-1 次交互行为预测第n次交互行为。当计算式(10)时,使用点播视频池中所有的点播视频来计算会导致计算量过大,因此采用sample softmax 来训练模型[20]。
2.7.2 模型部署
通过训练优化模型,提取点播视频的隐向量以及每个终端的多种兴趣偏好。每一种兴趣偏好向量可以独立使用最近邻相似算法从点播视频候选池中召回终端可能感兴趣的点播视频。那些与终端兴趣向量相似度较高的点播视频将会作为召回阶段的结果,在输入排序阶段进行排序。当终端产生了新的行为记录时,可以通过定时训练模型更新终端的兴趣向量。在检索与兴趣向量最匹配的点播视频时,使用Faiss[21]作为检索工具。
3 实验与结果分析
3.1 数据集
为了验证不同类型的数据集对算法模型性能的影响,本文分别选取MovieLens 公开数据集和某广电系统的真实电视终端数据集IPTV来进行实验。
MovieLens 数据集是一个在推荐系统中广泛使用的公开数据集,本文选取了MovieLens-20M 数据集,此数据集包含了13 多万名用户和2 万余部电影,以及2000 多万条观影行为。选取至少观看过20部电影的用户以及至少被观看过5次的电影,最终得到了13万多用户、1.8万多电影,以及2000万多观影记录。
实际广电网络的IPTV 点播数据集包含用户的曝光、浏览、点击、观看、购买等多种历史交互行为。经过常规清洗等操作,得到约64万个终端、2万点播视频,以及2300万用户隐式行为的数据。两个数据集的具体统计信息如表2所示。

表2 实验数据集统计信息Tab.2 Statistics of experimental datasets
在数据处理方面,将每个数据集的用户按照8∶1∶1 的比例切分为训练用户数据集、验证用户数据集、测试用户数据集,确保切分之后的各个数据集的用户没有交叉存在[22-23]。对于训练用户数据集,采用留一法切分训练点播视频和目标点播视频;对于验证用户数据集和测试用户数据集而言,按照8∶2的比例切分训练点播视频和目标点播视频。
3.2 评价指标
本文采用召回率(Recall)、命中率(HR)、归一化折损累计增益(Normalized Discounted Cumulative Gain,NDCG)这三种评价指标来衡量推荐算法模型的性能。
Recall 反映推荐列表中用户可能感兴趣的点播视频占测试集中有过交互行为的目标点播视频的比例大小。令Rt表示终端t的最终推荐列表,表示测试集中与终端t有过交互行为的目标点播视频列表,N表示推荐列表的大小(即:推荐列表中包含的点播视频的数量)。对于推荐列表大小为N的测试用例,召回率定义为:
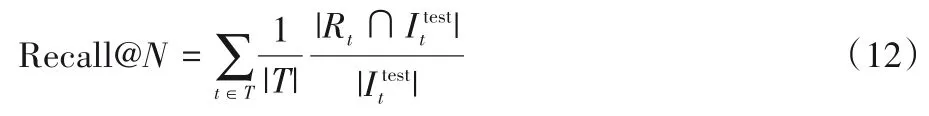
HR 反映生成的推荐列表中是否含有测试集中的目标点播视频,命中率越高,表明推荐的效果越好。对于推荐列表大小为N的测试用例,命中率定义为:

NDCG 是反映推荐列表中点播视频位置的指标,用户喜欢的点播视频排在推荐列表中靠前的位置,则获得的增益越大。其中,I(x)是一个指示函数,当x>0 时,I(x)=1,反之为0。表示终端t的推荐列表中的第n个位置的推荐点播视频。Z是一个常数,其值为理想状态下的DGC@N,对于推荐列表大小为N的测试用例,归一化折损累计增益(NDCG)定义为:
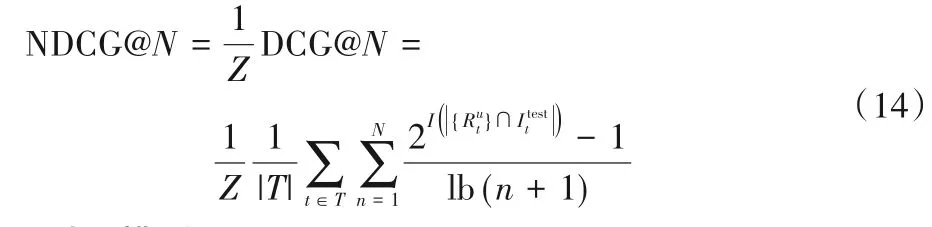
3.3 对比模型
选取以下模型与本文CapIPTV模型进行对比:
1)ItemPop[24],非个性化推荐策略的基准模型。该模型通过点播视频的观看次数来判断其受欢迎的程度,并将热门的点播视频推荐给每一个终端。
2)YouTube DNN[9],由谷歌在2016 年提出的应用于视频领域的推荐模型。该模型已经在YouTube 上线部署并且取得了较好的效果,是成功将深度学习应用于工业推荐系统的推荐模型之一。
3)DIN[10],首次提出使用注意力机制对用户历史行为进行建模,从而提取出用户的兴趣偏好。DIN 与CapIPTV 均使用注意力机制,不同的是DIN 直接对行为数据利用注意力机制进行建模,而CapIPTV 首先从行为数据中提取出多种类型的兴趣偏好,然后利用注意力机制对兴趣偏好进行建模。
4)DMIN[11],阿里研究发现用户在同一个时间点的兴趣是多样的,因此利用多头自注意力机制提取用户的多样化兴趣。DMIN 与CapIPTV 都是提取多种兴趣偏好,不同的是DMIN 使用多头自注意力机制,而CapIPTV使用胶囊网络。
5)MIND[18],面向天猫用户的多兴趣推荐模型。该模型提出了一种兴趣转化(Behavior-to-Interest,B2I)动态路由,可以将用户行为自适应转化为兴趣表示向量。MIND 与CapIPTV均使用胶囊网络提取多兴趣,不同的是MIND 使用B2I动态路由,而CapIPTV 使用CapsNet[17]所使用的原始动态路由,并且CapIPTV 使用的注意力机制与MIND 所使用的自注意力机制也有所不同。
3.4 实验参数分析
CapIPTV 模型与其他五种对比模型所有的实验都是基于TensorFlow实现,是在GEFORCE RTX 2080 Ti和内存64 GB的服务器上进行的。模型的超参数设置如表3所示。

表3 模型超参数设置Tab.3 Hyperparameter setting of model
3.4.1 训练时间开销
为了衡量本文所提出的模型与其他模型的复杂度,在相同参数设定的条件下,通过单次迭代训练所消耗的时间间接体现出模型的复杂度。
如表4 所示,YouTube DNN 模型的时间开销最小,从而反映出其模型结构较为简单;DIN 模型相较于YouTube DNN 模型增大了时间开销,是因为其增加了注意力机制,使得模型结构变复杂;DMIN 模型相较于DIN 模型而言,单次迭代所花费的时间更多,是由于采用了更加复杂的多头自注意力机制,其模型结构更为复杂;MIND 模型的时间开销最大,其引入了胶囊网络并使用B2I 动态路由,增加了模型的参数量;本文所提出的CapIPTV 模型使用原始的动态路由协议,在保证模型精度的条件下,降低了模型的复杂度,减少了模型的训练时间。
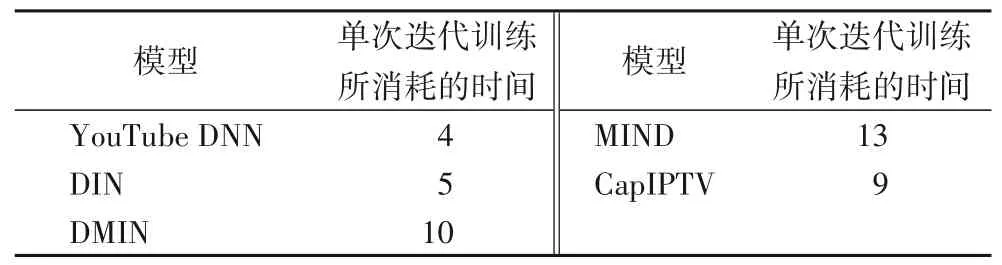
表4 不同模型单次迭代训练时间对比 单位:sTab.4 Training time comparison of different models in single iteration unit:s
3.4.2 超参数选择
本文最重要的超参数是动态路由机制的超参数。针对两个数据集分别对比不同的参数设置并进行分析,结果如表5所示。

表5 不同参数K下的CapIPTV模型在MovieLens和IPTV数据集上的性能比较 单位:%Tab.5 Performance comparison of CapIPTV model with different parameter K on MovieLens and IPTV datasets unit:%
根据表5 中的实验结果可以看出:对于MovieLens 数据集而言,当CapIPTV模型的参数K为1时,其召回率、命中率和归一化折损累计增益明显优于参数K为其他值时的推荐效果。实验结果表明,MovieLens 数据集中大部分用户的兴趣偏好较为集中,未能表现出明显的单用户兴趣多样性,并且随着参数K的增加,推荐效果明显减弱。对于IPTV 数据集而言,当CapIPTV 模型的参数K为4 时,推荐效果明显优于参数K为其他值时的推荐效果。实验结果表明,本文所使用的IPTV 数据集中用户呈现出明显的兴趣多样性,并且K为4 时,CapIPTV模型可以充分提取多种不同的兴趣偏好,推荐效果最优。
根据表5的实验结果可以看出:CapIPTV模型对于用户兴趣多样性明显的数据集可以充分提取出多种不同类型的兴趣偏好,即对于IPTV 推荐场景而言,本文所提出的模型可以更好地获取那些共享同一个IPTV 终端的家庭组中的不同家庭成员的不同兴趣偏好,从而更好地满足每一位家庭成员的个性化推荐需求,提升IPTV推荐场景下的推荐效果。
3.5 对比分析
为了验证CapIPTV 模型的性能,本文设计了3 组对比实验,并对实验结果进行了分析。
3.5.1 公开数据集实验结果对比
第一组对比实验将CapIPTV 模型与其他五种对比模型在MovieLens 数据集上进行比较来衡量推荐效果,表6 是对比实验的结果,可以验证CapIPTV 模型在通用推荐场景下的推荐效果。
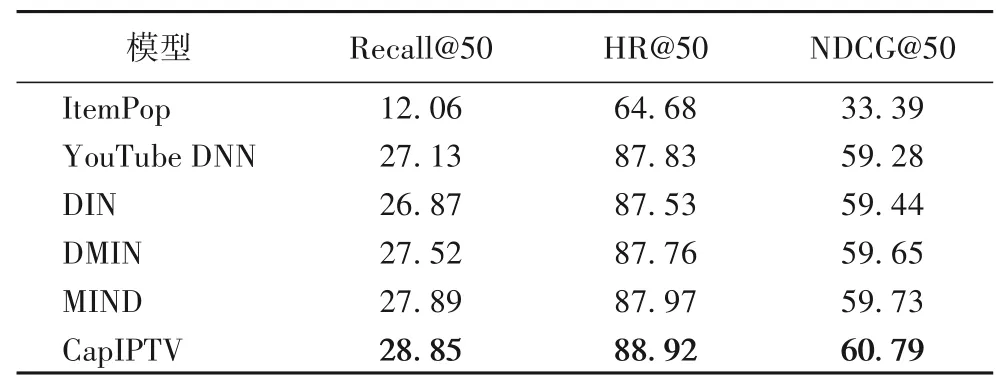
表6 六种推荐模型在MovieLens数据集上的性能比较 单位:%Tab.6 Performance comparison of 6 recommendation models on MovieLens dataset unit:%
表6 显示六种不同的推荐模型在公开数据集MovieLens上的推荐效果,可以从表6中看出:
1)非个性化的推荐模型ItemPop 在各项指标上均没有其他5 种推荐模型效果好,这是因为非个性化推荐并没有考虑到不同终端之间的兴趣差异性,对所有的终端使用相同的推荐列表,不能够提供个性化推荐。
2)YouTube DNN 模型仅优于ItemPop模型,该模型利用深度学习挖掘用户兴趣,从而提升了推荐效果,说明深度学习确实可以有效提升推荐效果。
3)DIN 模型在YouTube DNN 模型的基础上增加了注意力机制,因而推荐效果获得了提升,表明引入注意力机制有利于充分获取用户偏好。相较于DIN 模型直接对行为数据进行建模,CapIPTV 模型首先从行为数据中提取出多种兴趣偏好然后再进行建模,从而可以获得更好的推荐效果。
4)DMIN模型引入多头自注意力机制,充分提取用户的兴趣偏好,因而优于YouTube DNN模型和DIN模型,说明多头注意力机制可以有效提取用户偏好。同样是提取用户偏好,与DMIN 模型不同,MIND 模型通过引入胶囊网络提取用户偏好,并取得了不错的效果,体现了胶囊网络捕获多兴趣偏好的强大能力。
5)对比本文所提出的CapIPTV 模型与其他模型可以看出,CapIPTV 模型在MovieLens 数据集的每一项指标上均具有至少1 个百分点的提升,表明融合胶囊网络和注意力机制是非常有必要的。
3.5.2 真实广电数据集实验结果对比
第二组实验将CapIPTV 模型与其他五种对比模型在IPTV数据集上进行比较来衡量推荐效果,结果如表7所示,可以验证CapIPTV模型在特定场景下的推荐效果。
表7 为6 种不同的推荐模型在IPTV 数据集上的实验结果,其整体趋势与表6 所示结果相似,CapIPTV 模型均优于其他模型,与同样采用注意力机制的DIN 模型和同样采用胶囊网络的MIND 模型相比,融合了胶囊网络与注意力机制的CapIPTV 推荐模型的Recall@50 分别提升了1.93 个百分点和1.07 个百分点,HR@50 分别提升了3.01 个百分点和1.31 个百分点,NDCG@50 分别提升了1.82 个百分点和0.8 个百分点,这表明CapIPTV 模型可以较好提升IPTV 视频点播推荐场景下的推荐效果。
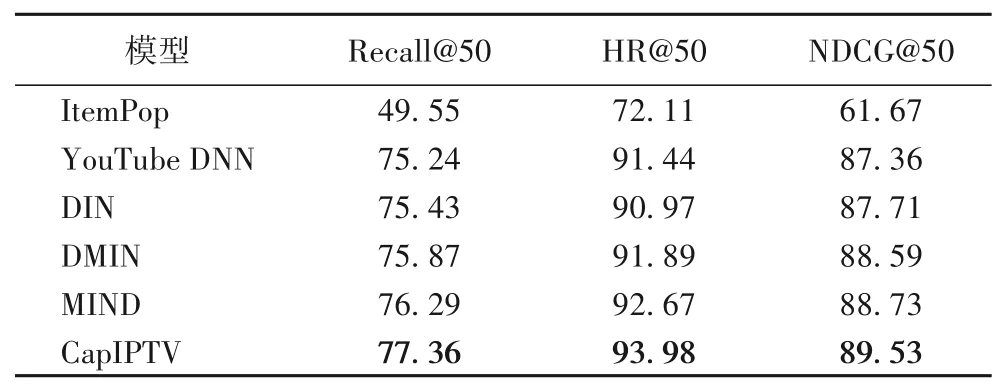
表7 六种推荐模型在IPTV数据集上的性能比较 单位:%Tab.7 Performance comparison of 6 recommendation models on IPTV dataset unit:%
通过表6~7 可以进一步得出,CapIPTV 模型无论在用户兴趣偏好比较集中的MovieLens数据集,还是在兴趣偏好呈现出明显多样性的IPTV 数据集,都可以呈现出比较好的推荐效果。
3.5.3 模型消融实验结果对比
第三组对比实验针对CapIPTV 模型各个部分进行消融实验[25],验证模型中主要组成部分的有效性。CapIPTV_1 表示去掉用户兴趣生成层,即不提取多兴趣偏好,直接对行为数据进行建模;CapIPTV_2 表示去掉模型中的注意力机制,使用men-pooling 操作融合多个兴趣偏好;CapIPTV_3 表示去掉模型中的注意力机制,使用max-pooling 融合多个兴趣偏好。各模型实验结果如表8所示。
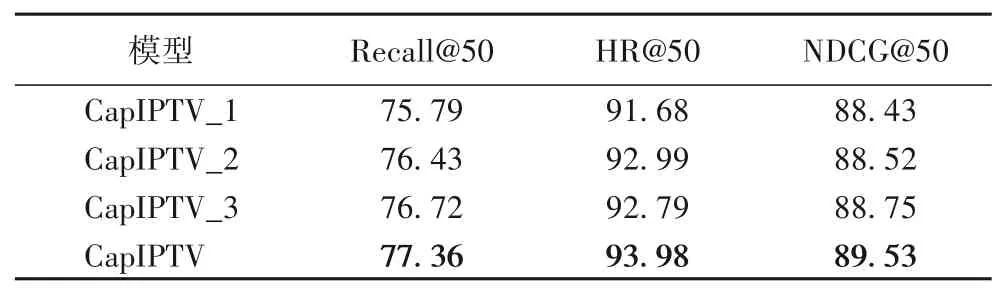
表8 CapIPTV模型的消融实验结果 单位:%Tab.8 Ablation experimental results of CapIPTV model unit:%
CapIPTV 模型的消融实验结果如表8 所示,从表8 可以看出:
1)CapIPTV 在各项指标上均优于CapIPTV_1,这表明引入胶囊网络提取多样性偏好信息有助于提升推荐准确度。
2)CapIPTV 在各项指标上均优于CapIPTV_2 和CapIPTV_3,表明引入注意力机制能够有效地获取多样性偏好之间的隐含关系,从而提高IPTV视频点播推荐的准确性。
4 结语
针对IPTV 视频点播推荐系统中一个电视终端由多名家庭成员共享的应用特点,本文提出了一种提取家庭组成员多类型兴趣偏好的推荐算法CapIPTV。该模型融合了胶囊网络与注意力机制,对历史行为数据进行多层次建模,有助于生成更加精确的推荐结果。通过在公开数据集MovieLens 和广电系统真实数据集IPTV 的实验结果表明,本文所提出的推荐算法在召回率、命中率和归一化折损累计增益上均优于五种同类算法。另外,本文还通过消融实验验证了模型中各组成部分的有效性。
本文对于包含多名成员的群组推荐进行了新的尝试,通过获取家庭群组中多名成员的多种类型兴趣偏好丰富群组的兴趣表达。未来研究将关注用户兴趣与观影时刻的潜在关系,利用成员的不同观影习惯调节不同时间点多兴趣的权重以优化推荐效果,从而进一步提升推荐准确性。
猜你喜欢
中老年保健(2022年3期)2022-08-24
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
现代装饰(2021年2期)2021-07-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小学生优秀作文(低年级)(2020年4期)2020-07-24
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小学阅读指南·高年级版(2009年3期)2009-03-27
