
机器视觉技术在图书馆书籍书号识别问题中的研究
2021-12-06 10:13冯丽娟郑中旭袁玉霞
魅力中国 2021年49期
冯丽娟 郑中旭 袁玉霞
(郑州科技学院电子与电气工程学院,河南 郑州 450064)
一、引言
光学字符识别(OCR)是图像处理和模式识别中最热门的问题之一,它需要对图像中的符号进行识别。这个问题已经存在了很长时间,然而,即使是众所周知的OCR系统,在OCR的特殊情况下也不能很好地工作,以美国国会图书馆(LC)书号识别为例。本文的目标是定义这一特定的问题,并评估现有的OCR 系统,分析哪种方法可以有效解决识别难的问题[1-3]。
已经有人尝试使用新技术,如RFID 或条形码[4,5]来识别书籍。然而,这将需要重新标签每一本书,购买RFID 或条形码阅读器,天线和软件许可证,这将导致非常高的初始和维护成本。此外,在读取设备或系统出现故障的情况下,RFID 标签和条形码无法被人类或用户读取。因此,有低成本自动化系统的需求,可以检测书籍的移动,如在[6]中提出的。在这类系统中,关键问题之一是识别每个图书馆书籍上的标签中的书号。
OCR 已经研究了很长一段时间并取得了显著的成功,但在本文中,通过大量的实验,结果表明,目前的OCR 系统在这个特定的情况下并没有产生令人满意的结果。因为存在下划线的问题,导致了识别较差的结果,如许多图书馆标签褪色或磨损,特别是当标签的背景是白色的,在上面的符号非常薄。另一个面临的问题是图书馆周围的书架不均匀的照明,这经常造成不均匀的亮度,在某些情况下,它不够明亮,不足以阅读什么是旧标签。这些问题表明,在研究新的更有效的算法来解决这个特殊的图书书号识别问题之前,需要更彻底地研究这个问题,更仔细地分析可用的OCR系统的性能。在本文中,进行了一些实验,在不同的情况下,OCR 算法的性能将被测试和分析[7]。
二、图书馆书籍书号识别问题分析
(一)问题描述
给定图书馆书架上书籍的图像,每本书的书面上应该有一个图书馆标签或贴纸,如图1 所示,它通常在白色的背景上包含书的编号。需要一个OCR 软件来提取给定图像中所有图书的每个标签中的图书书号或图书ID。问题是需要清晰的识别图像中的文本和符号。首先,它看起来很简单,而且也有很多令人满意的OCR 识别应用程序。但是,正如后面的实验结果所显示,这仍然是一个具有挑战性的问题。
(二)参数
在光学字符识别问题中,输入图像质量对识别结果的成功起着很大的作用。对于这个特殊的OCR 问题,我们需要检查各种情况和环境,在什么时候和什么地方获得书本的图像。换句话说,需要确定在解决给定的图书书号问题时,哪些参数可能会影响识别成功率。
书面背景:书面的颜色在识别通常为白色背景,对图书标签上的文字和书号符号识别时会产生很大的影响。
1.标签质量:书号印在书面上的标签上。标签的背景色通常是白色,而编号(由字母和数字混合而成,中间有点)印得很薄,看起来是灰色而不是黑色。这些标签是在书籍被添加到图书馆目录时第一次制作的。经过多年,许多标签可能会磨损掉,因为它们是部分剥落,墨水褪色。不幸的是,这些标签不会立即被新的替换,因为检测、打印和替换标签需要很长时间。因此,在图书馆看到的图书标签可能会从非常清晰的黑色墨水标签到模糊的标签,其中图书编号的符号是模糊的,不再清晰。
2.相机高度(灯光):众所周知,灯光对OCR 的性能有很大的影响。光强的差异可能很难被人的眼睛检测到,但对于OCR 软件来说,这可能会导致识别成功率的巨大差异。在图书馆里,光线的主要来源通常来自天花板。因此,相机的位置越高,图像就越亮,越清晰,反之,相机的位置越低,图像就越暗。获得不同光线强度的图像最简单的方法是将相机从高到低放置在图书馆书架的不同书架上。可以在书架的顶层得到光线更多的图像,或者是书架底层光线较少的图片,如图1 所示。

图1 左:更多光下的顶部搁板;右:较少光下的底部搁板
由于相机位置的高度可以很容易地通过书柜的外表来量化。最低的光强度值是当相机是在水平的低端时拍的。同样的,最高光强值也会出现在相机在顶部的水平上。
三、本文的识别测试系统
为了测试OCR 软件的性能,可以用于图书馆书号识别问题,设计了一个测试系统,它集成了几种OCR 的技术。用相同的一组输入数据运行,如图2 所示。
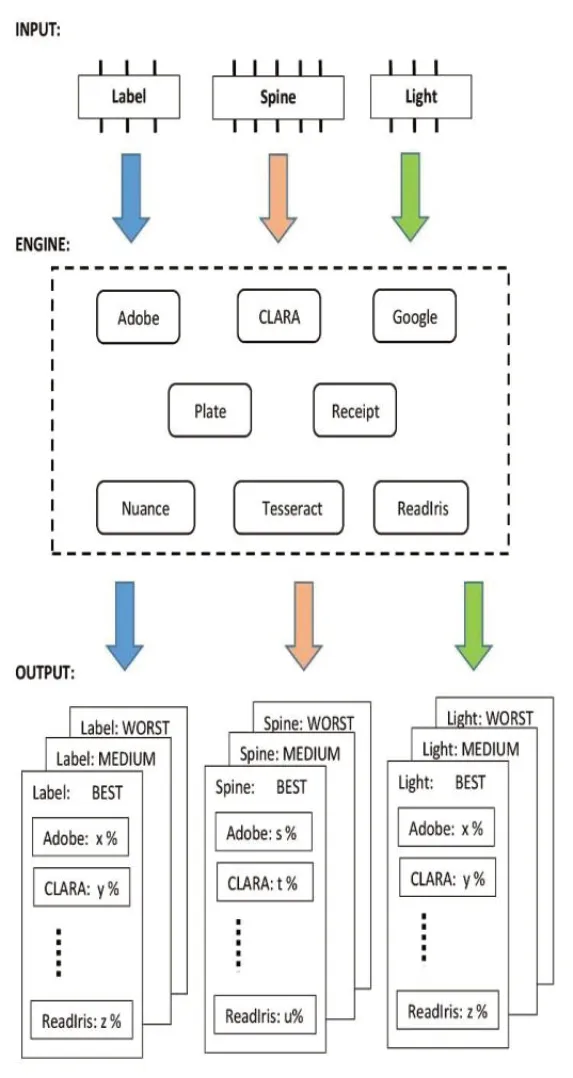
图2 识别书号测试系统
在测试系统的引擎中包含以下内容:Adobe Acrobat、CLARA、Google Cloud Vision、License Plate ALPR、Nuance OmniPage、Readlris、Tagun Receipt、Tesseract 等。引擎中的所有OCR 使用相同的输入。在不同环境中,可能会遇到识别复杂图书书号的问题。输入数据可以分为三组:书面背景、标签质量、照明(或相机高度)。
用图书馆标签处理每一幅书面的图片,图像的输出是文本文件中的图书书号列表。然后,通过比较文本文件中的结果和相应图片中的图书编号,对每个OCR 系统的每个参数的性能进行评分。
四、实验及结果分析
使用两种不同分辨率的相机:(i) 1.3 万像素的基本的网络摄像头和(ii) 12 万像素的高端智能手机摄像头。由于给定的问题需要解决在大型图书馆中的设备可能太昂贵,因此可能无法得到。因此,了解相机质量对每个OCR 软件性能的影响是很有用的。利用上述测试系统,进行了实验。
使用在第2 节中描述的参数范围内的不同输入图像集来测量所有OCR 系统的成功率。成功率由从1 到10 的分数来定义,其中10 是最好的,或者识别100%的标签是正确的,而1 是最差的性能,即OCR 不能识别超过10%的书号。结果如表1、2、3所示。本实验中使用的图像均为手机相机拍摄。
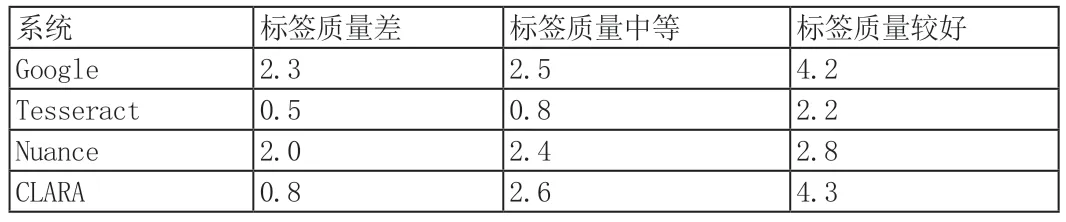
表1 标签质量对测试结果的影响
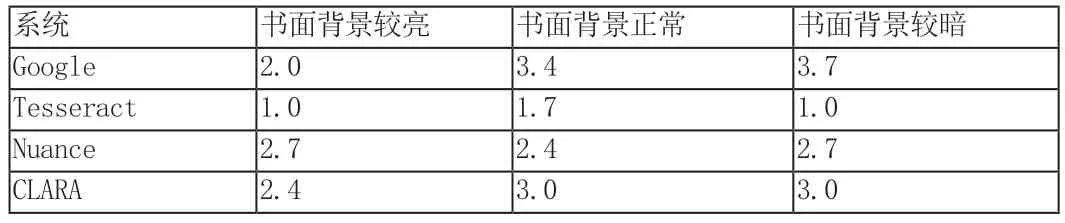
表2 书面背景对测试结果的影响

表3 相机高度对测试结果的影响
五、结论
在图书馆图书图像中识别图书书号是一个非常具有挑战性的OCR 问题。即使使用目前先进的OCR 系统和顶尖IT 公司的技术,识别书面上标签图片上的书号成功率也只有40%或更低。考虑到一个很好的解决方案对于这个OCR 的问题会形成一个非常低成本自动化的大图书馆的书位置跟踪系统,无需添加任何新标签的书或需要任何额外的人类劳动,这将对图书馆建设是非常重要的。在未来,根据机器学习机制,如神经网络和模糊逻辑可以加入到目前的解决方案中,以取得更好的结果。更多地研究其他可能影响这个特定OCR 问题结果的因素,也有助于为这个非常具有挑战性的问题制定更有效的解决方案。
猜你喜欢
疯狂英语·新读写(2022年6期)2022-06-08
疯狂英语·读写版(2022年6期)2022-06-08
南风(2020年22期)2020-09-15
小学生优秀作文(低年级)(2019年5期)2019-04-25
当代作家(2018年11期)2018-11-27
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
小学阅读指南·低年级版(2017年12期)2017-12-26
初中生世界·七年级(2017年9期)2017-10-13
Coco薇(2015年11期)2015-11-09
