
基于改进PCA+SVM的人脸识别系统
2021-12-03 03:27:36彭荣杰彭亚雄陆安江
电子科技 2021年12期
彭荣杰,彭亚雄,陆安江
(贵州大学 大数据与信息工程学院,贵州 贵阳 550025)
人脸识别技术起源于21世纪,该技术与传统的指纹识别、虹膜识别、掌纹扫描、身份识别相比,有较好的隐蔽性,安全性高,操作便捷[1],是计算机领域和机器学习领域研究的热点之一,有着广阔的前景。近年来人脸识别技术已渗入到日常生活中,例如支付宝付款、人脸识别解手机密码锁及刷脸乘车等方面,使人们的生活更加便利。文献[2]最早将主成分分析(Principal Component Analysis,PCA)算法应用于人脸识别,用于特征脸的提取。该方法效果良好,很快在人脸识别技术中得到应用。但在人脸图像中,除了线性部分,还有非线性部分,且提取的人脸特征向量是高维的,因此只能提取人脸线性部分的PCA算法的应用范围及效果较为有限。为了更好地提取人脸图像信息,解决人脸图像的非线性问题,研究人员提出了核主成分分析(Kernel Principal Component Analysis,KPCA)算法。该算法将高维空间中的特征向量变化到低维空间中,使原始空间的数据信息降到最小值,以便更好、更快地提取人脸图像的有用信息。在人脸识别方面,分类器的选取很重要。分类器种类包括最近邻算法分类器[3]、K近邻算法分类器、支持向量机(Support Vector Machines,SVM)分类器以及基于贝叶斯识别模型的分类器[4]等。SVM分类器在处理小样本数据集和非线性问题及高维模式方面具有优势,所以本研究结合SVM分类器对人脸图像进行分类识别[5-6]。
1 人脸识别算法
1.1 图像预处理
在人脸特征提取前,需要对人脸图像进行预处理,去除光照过强或过弱对人脸识别带来的不利影响。本文使用Gamma校正法对人脸图像进行对比度增强处理,基本原理如下。
本文将原人脸图像设为I1,将定义的标准图像设为I2,通过调节参数λ将需要校正的原人脸图像校正到定义的标准图像。首先,对输入图像像素值归一化,归一化后像素值在[0,1]之间。然后,调节参数λ对像素值做非线性映射,非线性映射计算式为[7]
(1)
式中,f(I1)为输出非线性映射的值;λ是调节参数。当λ<1时,人脸图像灰度值变大,整体亮度增大。当λ>1时,人脸图像灰度值变小,整体亮度变暗。最后用反归一化对所得像素值进行处理,再将处理后的像素值扩展到[0,255]。使用Gamma校正法得到的效果如图1所示。

(a)
1.2 PCA算法
PCA是一种分析统计的有效方法,该方法用特征向量对样本数据进行分析,将高维特征向量通过特征向量矩阵转换后得到低维向量[8],并略去次要信息,保存主要信息。通过K-L变换(Karhunen-Loeve Transform)提取图像的主要成分,构成低维特征空间。识别时,将测试图像投影到低维特征空间,得到一组投影系数,通过与各个图像比较进行识别[9]。
假设有n个训练样本,每个训练样本由其灰度像素构成,并用x表示向量。向量x的维数用样本图像像素m表示。样本图像像素m等于行像素数与列像素数的乘积,得样本训练集{x1,x2,x3,…,xn},计算样本的平均向量为式(2)。
(2)
平均向量又称训练图片的平均脸,每个训练样本与平均脸的差值用d表示。
di=xi-φ,i=1,2,3,…,n
(3)
样本集的协方差矩阵用C表示
(4)
即
(5)
使用式(4)中协方差矩阵C的特征向量ei和特征值γi来构造特征空间,需要对特征值进行分解。但因其维数较大,故采用奇异值分解(Singular Value Decomposition,SVD)定理,通过求解ATA的特征值和特征向量来求AAT的特征值和特征向量。最后,得到ATA的特征值λi和正交归一化特征向量vi[10]。
选取前p个最大的特征向量和其对应的特征值作为主要信息提取,特征值的贡献率为δ,选取特征值与所有特征值的和的比值表示,为ω。
(6)
为更好地对图像进行表达,贡献率δ=0.99。协方差矩阵C的特征向量为
(7)
得到特征空间ϑ为式(8)。
ϑ=(e1,e2,e3,…,ep)
(8)
1.3 SVM算法原理
假设平面上有两类数据,分别用空心圆圈和实心圆圈表示。如图2所示,寻找一个超平面能正确划分平面上的所有数据,此分割线可能有多条。如果找到一个平面,该平面内全部样本数据点距离分割线最近,且距离最大,那么找到的这个平面就是超平面[11],该超平面也是最佳超平面。超平面之间的H分类分别为H1和H2,它们之间的距离称为分类间隔。

图2 SVM算法分类图Figure 2.SVM algorithm classification map
该超平面H的方程表达为:wTx+b=0;样本点p(x1,x2,x3,…,xn)到此超平面的距离用d表示,计算式如下所示。

(9)
训练集D={(xi,yi)|xi∈RN,yi∈{-1,1}}。训练集中xi为样本集,yi是xi对应的标签,yi=1为正样本集标签,yi=-1为负样本集标签。此超平面H将不同的样本集分离,其对应的判别式为[11]
w×xi+b≥1,yi=1
(10)
w×xi+b≤1,yi=-1
(11)
联合式(10)、式(11)得式(12)。
yi(w×xi+b)-1≥0
(12)
上述优化问题的目标函数转换成
(13)
为解目标函数,使用拉格朗日优化理论,即
(14)
最终优化形式为式(15)。
(15)
由于数据集不统一,存在噪点,所以引入松弛变量ξ,并允许少量不能正确划分的数据存在[11]。重新调整目标函数,新目标函数为
(16)
新约束条件为式(17)。
yj(w×xi+b)≥1-ξi,i=1,2,3,…,n
(17)
1.4 改进的人脸识别算法
PCA算法是线性算法,不能很好地描述人脸图像的内在结构及内在纹理特征,所以本文对PCA算法进行核改进,提出KPCA算法[12-13]。KPCA算法运用其自身产生的核函数来提取人脸图像的非线性结构特征。KPCA算法的主要思想是通过一个非线性核映射φ(x),将训练集的数据从低维的特征空间X投射到高维的特征空间F中[14],在高维的特征空间F中重新构造一个最优分类面[15-16],实现数据的分类。该方法可解决数据线性不可分的分析及提取等问题,又因其维数不会超过训练样本的总数,故能避免在高维空间中进行大量运算。将输入的人脸数据经过非线性核映射后得到样本组,对样本组做中心化处理,即
(18)
式中,N表示训练样本的个数;φ(xk)是对训练样本的映射函数。C是映射后的协方差矩阵[17],C表示为
(19)
用下式来求解特征方程,可得主分量
λV=CV
(20)
式中,V为特征向量,可用φ(x1),φ(x2),…,φ(xn)的线性组合来表示。
核函数的表示有很多种,本文采用高斯核函数,高斯核函数表达式为
K(xi,x)=exp(-q‖x-xi‖2)
(21)
假设用K来表示N×N的核矩阵
Kij=φ(xi)Tφ(xj)
(22)
把表达式(19)、式(21)和式(22)带入表达式(20)可得
Kα=Nλα
(23)
由式(22)可以得到核矩阵K。K具有正定性和对称性,并且各特征值为非负值。
求解式(23)能得到
λi(αi,αj)=1
(24)
假设测试样本X,该样本在Vj方向的投影可用下式表示。

(25)
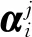

(a)
2 改进的人脸算法实现
本文先对训练集和测试集中的图像进行预处理,再对PCA算法进行核改进,得到KPCA算法,最后结合SVM分类器,采用“一对一”分类策略将SVM推广到多类问题的分类过程,完成多分类的变换。具体算法步骤如下:
步骤1在人脸图像库中选择样本集P,将P分成训练样本集和测试样本集。训练样本集由前M个人脸图像组成,测试样本集由剩下的(P-M)个人脸图像组成;
步骤2对训练集和测试集中的图像用Gamma校正法进行预处理;
步骤3对预处理后的图像以矢量的形式排列,形成特征集;

步骤5结合SVM多分类器进行分类识别。
3 实验结果
本文在MATLAB 2014b上进行实验,同时在MATLAB 2014b上搭建人脸识别系统并对系统进行仿真。本文使用剑桥大学AT&T实验室创建的ORL人脸数据库以及Yale人脸数据库。ORL人脸数据库里有40个人,每人有10张图片,其分辨率为112×92,灰度级是256。Yale人脸数据库里有15个人,每人有11张拍摄角度不同、表情不一致的人脸图像[18-19]。本实验选取前10张图片,其人脸图像分辨率为100×100,灰度级是256。分别对PCA、PCA+SVM、KPCA+SVM算法进行比较,KPCA+SVM算法在ORL人脸库上识别率是95.16%,在Yale人脸库上识别率是95.10%,表明KPCA+SVM算法优于PCA算法和PCA+SVM算法。将KPCA+SVM算法用于人脸识别系统,并用GUI界面仿真,系统的流程框图如图4所示。

图4 系统的流程框图Figure 4.System flow diagram
3.1 实验结果及分析
本文实验取每个人10张人脸图片,训练集用前5张人脸图片,测试集用后5张人脸图片。对训练集和测试集中的图像用Gamma校正法进行预处理,取调节参数λ=0.6。如表1和表2所示,PCA算法将高维的人脸图像投影到低维的特征空间,得到特征脸后进行人脸识别。由于人脸图像易受光照、表情等因素的影响及存在非线性特征,故PCA算法识别率较低。SVM在处理小样本数据分类方面具有一定的优势。结合SVM的PCA+SVM方法在ORL人脸库和Yale人脸库中的识别率相对于PCA算法分别提高了7%和9.1%。本文对人脸图像进行预处理,减少光照的影响,再对PCA算法进行核改进,提出KPCA算法。KPCA利用其内部非线性核函数作用,能较好地提取人脸的轮廓,有效处理非线性特征数据,降低数据维数,减少特征数据存储所需要的空间,提高运算能力。将KPCA结合SVM分类器进行分类识别。如表1所示,本文所提的KPCA+SVM算法在ORL人脸库上识别率是95.16%,比传统PCA算法提高了18.16%,比PCA+SVM提高了11.16%。将KPCA+SVM算法在人脸识别系统中运行5次,其平均运行时间为3.95 s,少于PCA算法及PCA+SVM算法的平均运行时间。如表2所示,本文所提KPCA+SVM算法在Yale人脸库上识别率是95.10%,比传统PCA算法提高21.1%,比PCA+SVM提高12%。KPCA+SVM算法运行5次,平均运行时间为5.12 s,比传统PCA算法、PCA+SVM算法的平均运行时间要少。实验结果表明,本文改进后的KPCA+SVM算法具有较好的识别效果,提高了平均运算速度。

表1 在ORL人脸库上的实验结果Table 1. Experimental results on ORL face database

表2 在Yale人脸库上的实验结果Table 2. Experimental results on Yale face database
3.2 系统仿真
基于改进后的KPCA+SVM算法,在MATLAB平台上搭建人脸识别系统并进行仿真,以GUI呈现。点击开始训练按钮,调用函数对前5张图片进行训练并保存数据。点击开始测试按钮,调用函数对后5张图片进行测试,对测试集200个人脸样本,识别率为95.16%。点击打开图片按钮,选择ORL人脸库中第9个人第6张图片作为待识别人脸图像,点击识别人脸,系统读入训练参数进行特征匹配并输出识别结果。该系统能正确识别出人脸图像,GUI界面输出结果如图5所示。

图5 基于KPCA+SVM的人脸识别系统Figure 5.Face recognition system based on KPCA+SVM
调节参数框中的C是惩罚因子,C值越高,系统容易出现过拟合现象;C值越低,系统容易出现欠拟合现象。C值过大或过小都会使系统的泛化能力变差。gamma是单个训练样本的影响因子,可以看作支持向量样本的影响半径的倒数。基于改进后的KPCA+SVM算法在惩罚因子C=2,gamma=0.01时,在ORL人脸库和Yale人脸库上的识别率均在95%以上,运行时间均在6 s以下,达到系统识别率的要求。该结果表明基于KPCA+SVM的人脸识别系统的研究是可行的,对实际研究有一定的参考应用价值。
4 结束语
本文所提的KPCA+SVM算法首先使用Gamma校正方法对人脸图像进行预处理,减少光照过强或者过弱对图像带来的不利影响;再用KPCA算法对提取的图像进行人脸特征提取,减少了光照干扰和小样本问题,较好地提取了人脸图像的非线性特征;最后用SVM分类识别器对人脸图像进行分类识别。KPCA+SVM算法的识别率相比于PCA、PCA+SVM算法均有所提高。近年来,由于深度学习被广泛应用于模式识别中来提取人脸的深层特征,因此下一步工作将结合深度学习进行人脸识别。
猜你喜欢
数学年刊A辑(中文版)(2021年3期)2021-11-05 08:36:32
数学年刊A辑(中文版)(2021年2期)2021-07-17 08:37:58
计算机工程(2020年3期)2020-03-19 12:24:50
科技创新与应用(2020年6期)2020-02-29 10:39:27
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
数学物理学报(2019年1期)2019-03-21 05:26:12
中国交通信息化(2018年3期)2018-06-13 03:27:58
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
