
基于Web爬虫技术的电子病历信息聚合工具的开发及验证
2021-12-02 06:44:40刘宏嘉王静黄宇亮李晨光吴昊马文君曹文田张艺宝
中国医学物理学杂志 2021年11期
刘宏嘉,王静,黄宇亮,李晨光,吴昊,马文君,曹文田,张艺宝
1.北京大学医学部医学技术研究院,北京 100191;2.北京大学肿瘤医院暨北京市肿瘤防治研究所放疗科/恶性肿瘤发病机制及转化研究教育部重点实验室,北京 100142;3.浙江大学医学院附属邵逸夫医院,浙江杭州 310202;4.北京大学物理学院,北京 100871
前言
人工智能技术在医学科研和临床工作中得到越来越多的应用[1-4],不仅提高工作效率[5],而且减少了由于主观因素和经验水平导致的质量波动和地域差异[6-7]。对于放射治疗专业而言,除了标准DICOM 格式的医学图像[8-9]、放疗计划[10-11]、剂量分布[12]等常用信息外,病历中记录的其他多模态信息也具有不可替代的数据价值[13-14]。
病历是病人在医院诊断治疗全过程的原始记录,包含首页、病程记录、检查化验结果、医嘱、手术记录、护理记录等。随着医学信息化的逐步推进,病历也从曾经的纸质、光盘等粗放存储演变成医院信息系统(Hospital Information System,HIS)集中管理。但是,相比DICOM 格式的电子数据,HIS系统中存放的病历信息缺乏统一标准,对大数据应用背景下的自动挖掘和分析整理带来挑战[15]。系统提供的有限功能已不能满足科研对于批量查询和聚合分析等“定制化”需求,而市面上又缺乏针对HIS系统开发的数据自动挖掘服务工具,进行数据整合时往往使用传统人工方法进行整理。传统人工整理方法不仅效率低下,而且容易发生遗漏或错误,影响样本量的扩充和数据质量的保障[16]。作为访问权限较低的终端用户,如何在没有医院信息管理部门的配合下,安全、便捷地实现对批量病历信息的自动汇总和分析,在大数据时代背景下对于临床和科研工作具有重要意义。
本研究开发了一种基于Web 爬虫技术的病历信息聚合工具,并以大量病历中的诊断报告信息筛选和血常规检查结果的特定指标信息聚合为例进行验证,同时与手工提取相关信息的过程作为参照进行对比验证分析,结果表明相对于手工提取的过程,自动方法在提取效率和准确性相对于人工方法均有较大提升。
1 材料与方法
1.1 需求背景和操作环境
本工作基于北京大学肿瘤医院的HIS病历系统,在内部网络环境下可通过患者身份编号、姓名等信息调取病历文书、诊断报告等信息。该病历查询系统是一个ASP.NET 的Web 应用程序,普通用户无法获取病历系统数据库的直接访问权限,也无法“定制”批量查询和整理等系统尚未提供的特殊功能。而直接获取信息的爬虫方法难以绕过Web 应用程序的安全设计,同时也存在一定程度的安全风险。同时,为了节约计算资源,也为了探索日后本工作在利用小型计算设备的可能性,本工作在搭载了Raspbian(一种基于Debian 的Linux 操作系统)的树莓派4ModelB上执行(硬件上使用树莓派4B原生套件)。
1.2 程序架构
为了解决访问安全、自动化和实现特殊定制功能等问题,本工作采用Selenium 技术来聚合信息。程序基于Web 架构设计,采用名为Selenium 的Web应用程序测试的框架和Python 编程语言,通过浏览器来实现所需要的信息搜集。Selenium 作为Web 应用程序测试工具,能够在近乎真实的浏览器中执行测试,模拟人类用户操作。而Python 作为一种优秀的胶水语言,在利用Python 执行Selenium 工具时,可以对浏览器所能展示的数据进行方便的分析聚合。整体的程序架构图如图1所示,工作流程如图2所示。
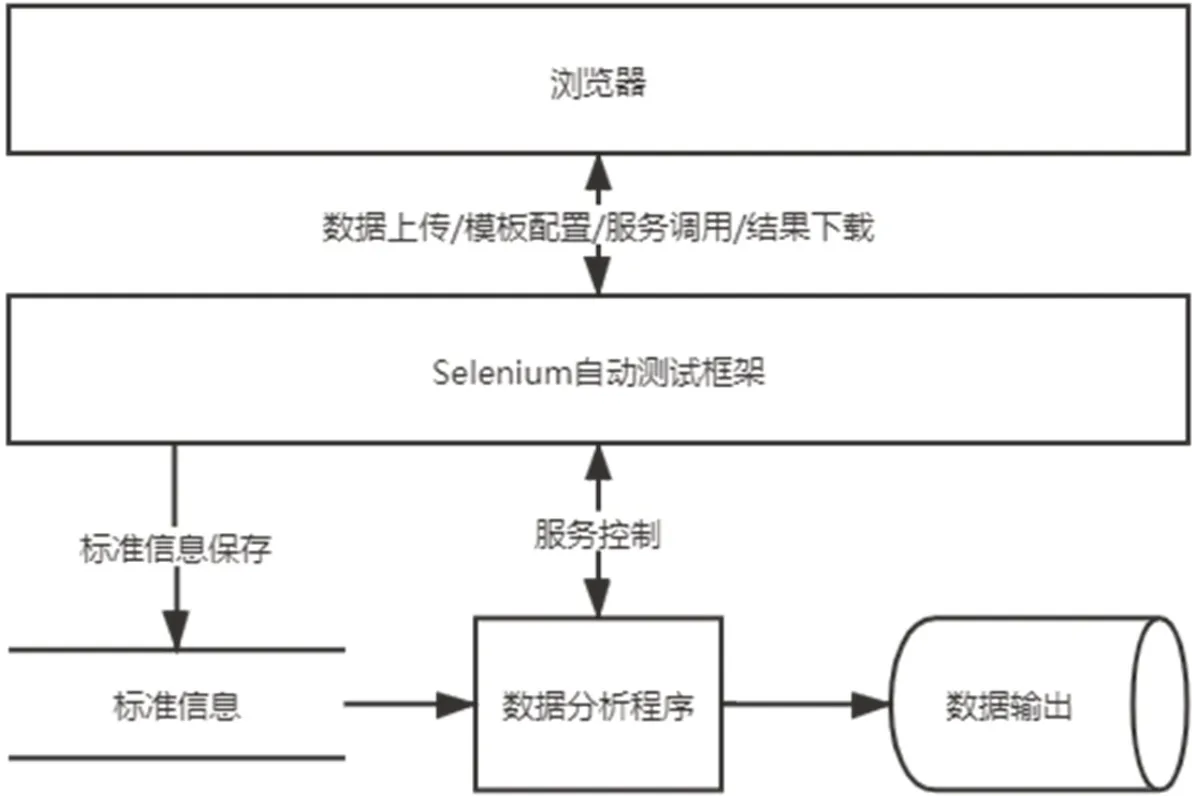
图1 基于Web爬虫的工具程序架构图Fig.1 Program framework of Web-crawler-based tool
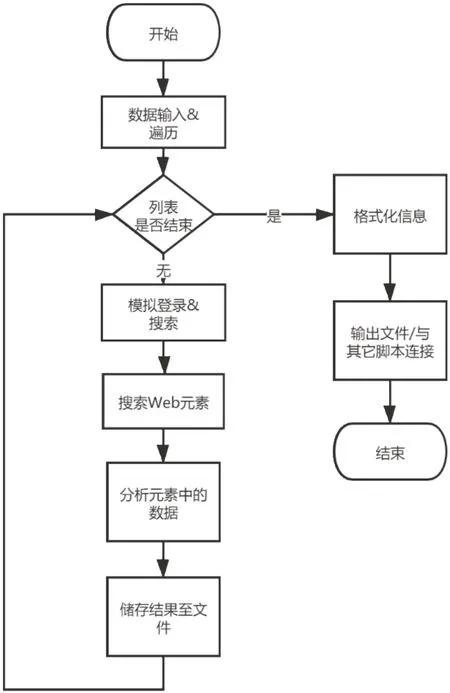
图2 聚合工具的工作流程图Fig.2 Workflow chart of aggregation tool
该聚合工具接收研究人员可定位的患者基本信息(病历号、姓名等信息)以及所需信息项目名称列表,模拟实际登录过程,依次定位到患者信息所在页面。其中根据页面的DOM 树结构,分析整个页面是否包含所需信息以及哪些信息可以被访问,返回所需的DOM 树节点以及Xpath路径。之后根据返回的节点和路径来提取数据并根据预先定义的数据字典来判断数据准确性,并以结构化方式(Python 数据字典)来进行储存。最后按照研究人员的需求,或者将结果存储为结构化文件,或者将结果接口与其它数据分析的脚本相连接,直接供研究使用。
1.3 测试目标和工作流程
本程序通过模拟浏览器操作来实现癌症患者相关数据的批量查询以及定位获取,利用服务器后台程序对获取到的数据进行信息聚合,并按照指定的格式输出所需数据的文件。验证测试目标包括:(1)从既往肺癌、食管癌、乳腺癌等胸部放疗患者病历数据库自动查询并汇总发生放射性肺炎的病例,以及距离放射性肺炎发生的最近一次放疗的时间;(2)对新入院患者的临床血常规检查报告的结果进行聚合。具体工作流程包括:(1)记录并模拟人工查询1例患者从授权进入到访问包含所需数据页面等全过程需要在Web 界面上执行的操作;(2)将上述操作映射为Selenium 操作语句(在本例下,执行的操作会进入到包含放射报告以及病历文书的界面),同时封装起来,暴露数据输入为唯一变量患者号;(3)分析数据所在页面网页源代码,找到目标数据所在的元素,映射为Selenium 操作语句以获取所需数据(在本例下,需要获取放射诊断报告栏目下的所有子报告以及病历文书下的所有文档);(4)利用Python 分析得到的数据。对于放射性肺炎测试目标,程序在得到的所有放射诊断报告中模糊搜索有关放射性肺炎的描述,判断具体患者是否被诊断为放射性肺炎。如有,则继续查询从无到有的变化日期,并检索该日期最近的若干病例文书,返回其中内容最多的文书(病历文书是一个长期积累,通常新的文书会包含之前旧文书的内容),以备日后科研工作分析以及错误核验。对于聚合新入院患者的临床血常规报告,该工具将遍历检查表,从中按名称判断是否是所需要查询的检查,然后记录该次检查时间、负责医生等信息,搜索表格中是否有所需的血常规子项目并记录对应数据储存到预设的数据结构中。最后将得到的数据按照需要的格式输出,如以患者号命名的文本研究件形式,或者是便于导出导入的Numpy 数组格式等。
2 结果
本工作成功开发了满足图1架构以及图2所示工作流程的基于Web 爬虫技术的病历信息聚合工具。使用上述系统开发架构和工作流程建立的信息聚合工具成功自动登录了HIS 系统,并在HIS 系统上的不同区域和路径成功获得指定患者所需的准确信息。
放射性肺炎病例的获取:基于Web 爬虫技术的病历信息聚合工具从3 541 例患者中识别出110 例放射性肺炎病例。使用手动方法对这3 541 例患者进行识别与自动化方法对比,自动化方法每例患者耗时约为54 s,手动方法每例患者耗时约为90 s。
新入院患者的临床血常规检查报告的结果聚合:分析110例患者的血常规检测报告,使用自动化方法平均约10 s完成单例患者血常规分析的数据收集,而如果使用人工方法则需要75 s或者更多的时间。
此外,由于自动化方法是从HIS系统中直接获取结构化的病人信息,或是直接利用该信息进行判断,从而准确性更高。相比之下,上述两个验证测试目标在人工实现的过程中均发现了错误,比如填写报告数据遗漏和错误等。
3 讨论
测试验证的结果表明,基于Web 爬虫技术的病历信息聚合工具在效率和准确性方面均远胜于人工提取操作。值得注意的是,在不同需求背景下,自动工具的特点和优势也不尽相同。在程序设计时需要充分考虑具体任务的特点,个性化优化流程和代码。比如放射性肺炎病例的排除相比检出相对复杂:前者需要遍历所有的放射诊断报告,而后者只需在任一报告中发现有用信息即可停止检索。本例中放射性肺炎的检出发病率约为3.11%,而如果本程序用于搜索发病率更低、样本量更大的病例,自动工具与人工方法的效率差异会被进一步放大。如果涉及不同页面的切换,也会对结果产生秒级的影响。相比之下,第二个提取和整理血常规信息的例子相对简单。原因之一是血常规的报告相对规范且客观,没有放射诊断报告中涉及的人工描述和主观差异;原因之二是提取的信息主要是同一页面上的检验报告,不涉及到切换页面等耗时操作。如果报告内容涉及更多更复杂的数据,人工整理的效率和准确性会进一步降低,而对于自动化方法的影响仅在毫秒量级。
本工作的创新之处在于:(1)除了大幅缩短数据整理时间外,还实现了全程无人工干预的自动化流程;(2)由于使用了相对简洁的 Python+Chromedriver+Selenium 套装方案,本工具即使是在树莓派这样的微型机器上也能够流畅运行,降低对计算设备的要求,节省算力成本;(3)该工具同时兼容多种图形化工作界面,具有良好的跨平台特性;(4)具有很高的查准率和查全率,降低复核数据的工作压力;(5)兼具良好的安全性和灵活性,可以在没有访问原始数据库权限的情况下,实现低权限场景下获取数据,“定制”实现HIS系统中尚未提供的特殊功能。低权限场景下可以防止对HIS 系统进行篡改以及降低暴露数据漏洞的可能,体现出良好的安全性。
在未来更复杂的应用场景中,本工作可以进一步拓展和改进的方面包括:(1)在分析更大数据量以实现规模效益时,可以利用分布式计算技术来进一步压缩执行时间。比如从该工具的系统架构入手,设计一个C-S(客户端-服务端)结构的工具,在若干个设备或虚拟机上使用实际执行代码的客户端,而服务端则把执行逻辑以及需要查找的患者根据客户端返回的运行状况进行动态的调度。预计采用此方法可以进一步大幅降低规模化查找的时间,另外也可以实现不同设备之间的负载均衡,从而使得算力和网络访问资源被更高效的利用[17-18];(2)利用标准化接口降低该工具的耦合度[19-20]。以本研究中涉及的两个应用为例,虽然系统架构是一致的,但是在检索部分和分析部分分别使用了结构不尽相同的代码。这一方面体现了该工具良好的可拓展性,但另一方面也对非信息科学专业的人员提出更高要求,增加了根据不同背景环境来更改、调试代码所需的精力。因此,我们计划在使用该工具进行更多场景的测试之后,总结出更普适性的数据搜集办法。尝试在一套工具里面标准化提取不同种类HIS 数据的接口,使得工具具有更好的用户友好度,同时进一步降低该工具的耦合度,提升其可拓展性,以及与其他科研代码的可整合性。
4 结论
本工作成功开发并验证了一套基于Web 爬虫技术的病历信息自动聚合工具,该工具具有安全、高效、准确、成本低、跨平台、易拓展等特点,可以在较低访问权限的情况下,“定制”实现临床和科研工作所需的数据检索、分类汇总等特殊功能,使得自动化技术在医学中得到进一步发展和应用。
猜你喜欢
房地产导刊(2022年10期)2022-10-18 08:03:52
健康体检与管理(2022年2期)2022-04-15 01:33:37
趣味(语文)(2021年9期)2022-01-18 05:52:42
中老年保健(2021年8期)2021-08-24 06:22:38
现代信息科技(2021年21期)2021-05-07 02:54:12
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:16
电子测试(2018年1期)2018-04-18 11:53:04
电子制作(2017年9期)2017-04-17 03:00:46
中国卫生(2016年10期)2016-11-13 01:07:44
中国卫生(2015年10期)2015-11-10 03:14:32
