
基于ALBERT与BILSTM的糖尿病命名实体识别
2021-12-02 06:44:40马诗语黄润才
中国医学物理学杂志 2021年11期
马诗语,黄润才
上海工程技术大学电子电气工程学院,上海 201620
前言
糖尿病是当前威胁全球人类健康的最重要的非传染性疾病之一,根据国际糖尿病联盟统计,2011年全球糖尿病患者已达3.7 亿,其中80%在发展中国家,预计到2030年全球将有5亿多糖尿病患者[1]。中国糖尿病患者在全球占比最高,成人糖尿病患者约1.298亿,平均每10个成年人中有1个糖尿病患者,因此,防治糖尿病成为重点难题之一。然而,我国糖尿病血糖控制状况不佳,有研究显示,糖尿病知晓率、治疗率、控制率均偏低[1]。为此,需要加强居民对糖尿病知识的关注,通过分析糖尿病相关知识来引导广大市民及医疗卫生机构提早预防或延缓这一疾病的发生[2]。人们对如何迅速从众多文献中获取专业知识给予了极大的关注。医学文本挖掘技术在文本知识的自动获取中起着重要作用,作为这项技术的任务之一,糖尿病命名实体识别(Named Entity Recognition, NER)旨在从糖尿病文献中识别特定类型的名称,如1型糖尿病、2型糖尿病、血糖、胰岛素促分泌素等[3]。NER 为下一步关系抽取,构建知识图谱提供了前提;为引导广大市民了解糖尿病相关知识,指导糖尿病患者加强健康管理提供了技术帮助。
1 相关工作
百度研究院在2015年提出了深度学习应用NER的经典模型,即BILSTM-CRF[4],凭借双向长短期记忆网络(Bidirectional Long Short-Term Memory Network,BILSTM)对上下文信息进行深度建模,条件随机场(Conditional Random Fields,CRF)利用特征矩阵解码整个句子的标签。Strubell等[5]提出迭代膨胀卷积神经网络(Iterated Dilated Convolutional Neural Network,IDCNN),与传统的CNN相比,此模型在大文本和结构化预测中具有更好的表现能力。对于文本的表示,传统的词表示方法有one-hot、词袋模型、n-gram[6],但这些离散的表示无法考虑词向量之间的关系。为提高模型精度,利用深度神经网络提取特征得到越来越多的关注。Mikoliv等[7]提出的word2vec词嵌入模型是目前最常用的词嵌入模型之一,然而词嵌入模型只提供一层表征,无法解决一词多义的问题。随着深度学习的发展,自然语言处理(Natural Language Processing,NLP)不再是一个任务一个模型,而是预先在大量语料上训练好一个模型,再对模型在特定的下游任务上进行微调,微调后的模型在众多NLP任务上均取得了不错的效果,如ELMO[8]、GTP[9]、BERT[10]等。李妮等[11]利用BERT与IDCNN-CRF的融合提高了NER的准确率。然而,目前这些预训练模型关注的焦点在于将模型变得更复杂,依赖越来越多的参数,很少考虑训练耗时长、成本高等问题。对此,Lan等[12]在2019年提出BERT的轻量级模型,即基于轻量型动态词向量模型(A Lite BERT,ALBERT),两个模型架构几乎一样,但ALBERT参数量相比BERT大幅度减少。即便如此,模型性能不但没有下降,反而有所提升。
鉴于先验知识对实体识别任务有良好的帮助,本研究将ALBERT 与经典BILSTM-CRF 相结合,提出融合ALBERT的糖尿病NER方法。
2 ALBERT-BILSTM-CRF
本研究提出的ALBERT-BILSTM-CRF 模型的主要结构如图1所示。
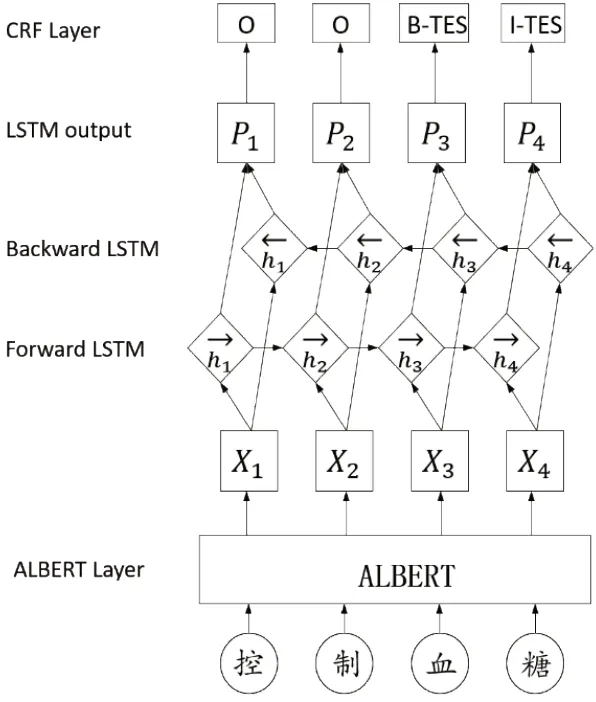
图1 ALBERT-BILSTM-CRF 的模型框架Fig.1 ALBERT-BILSTM-CRF model framework
该模型主要分为3 个部分,输入表示层、序列建模层和预测解码层。输入表示部分未使用传统的人工特征,而是选择了拥有先验知识的预训练模型提取字符级表征。本研究使用的是ALBERT 模型,该模型通过Embedding层把每个字映射为字向量;然后采用Transformer 双向综合的考虑上下文特征进行编码,将学到的知识加到token的表示上,获得字符级别的语义信息。获取的字向量输入到序列编码层的BILSTM 模块中,BILSTM 考虑上下文信息并进行高维特征抽取。最后在CRF 语义解码模块中预测出真实标签序列。
本研究在经典模型BILSTM-CRF 的基础上进行改进,引入ALBERT 模型。ALBERT 模型通过对字符的掩码学习可以捕捉到字符上下文之间的语法和语义层面信息,增强字符级向量的语义表征能力。
2.1 ALBERT预训练模型
ALBERT 是一种轻量级的BERT[13]。该模型架构与BERT 几乎没有区别,但其所占内存仅为BERT的十分之一。为了不大幅度降低模型性能,ALBERT提出跨层参数共享机制,使用句子顺序预测(Sentence Order Prediction,SOP)训练方法代替下一句子预测(Next Sentence Prediction,NSP)训练方法。ALBERT预训练模型的结构如图2所示。
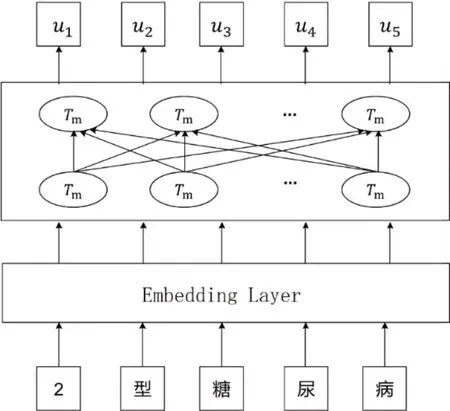
图2 ALBERT预训练模型结构Fig.2 ALBERT pre-training model structure
ALBERT 的 结 构 是 由 Embedding 层 和Transformer encoder 层组成。Embedding 层通过字典将每个字符映射成字向量,输入串联的Transformer encoder 层,通过预训练去捕捉语法和语义层面的信息,把文本中包含的语言知识编码到Transformer 中以参数的形式体现出来。
为了训练Transformer 模型中的encoder 层,ALBERT设计了两个任务:掩码学习和SOP。掩码学习的基本想法是随机遮挡一或两个单词,让encoder层根据前后文预测被遮盖的单词。SOP 的基本思想是将两个句子放在一起,encoder 层通过学习去判断两句话是否是原文中相邻且顺序正常的两句话。BERT 的NSP 任务只需要判断是否为相邻的两句话,而ALBERT 在相邻的基础上更侧重于句子之间的连贯性,所以SOP 在一定程度上能够解决NSP 任务。ALBERT 任务较BERT 难度增加,也提高了多语句编码的性能。
2.2 Transformer
ALBERT 是一个流程,采用双向多层的编码器Transformer。 为了使模型轻量化,ALBERT 在Transformer 层采用参数共享的方法来减少模型存储参数量。Transformer 发表于2017年,是seq2seq 模型,包括encoder 与decoder 两部分[14]。ALBERT 只采用encoder 部分。encoder 网络由多头Self-attention和全连接层搭建而成。Self-attention 的计算公式如下:
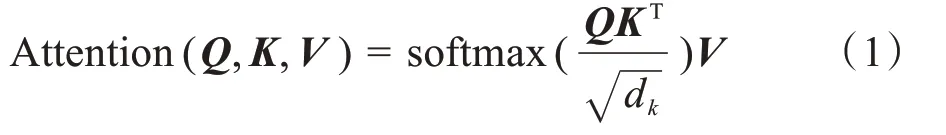
其中,Q,K,V是输入向量通过线性变换得到的3个输入矩阵,dk为输入字向量维度。通过计算每一个输入字向量与序列其它字向量之间的关系比重大小,得到不同的权重,再将权重与所有序列的表示进行加权求和,最终获得新的字符表征。
2.3 BILSTM
由于ALBERT 中的encoder 部分采用自注意力结构,因此输出的特征缺少顺序性。为了得到糖尿病文本中的序列特征,本研究采用BILSTM模型对糖尿病文本的上下文信息进行建模,BILSTM 网络结构与BIRNN 类似,在隐含层单元采用LSTM[15]结构,其单元结构如图3所示。
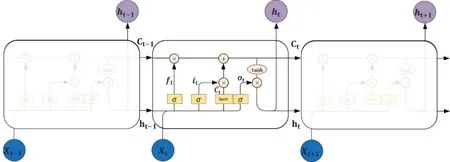
图3 LSTM 单元结构Fig.3 LSTM unit structure
LSTM 是对Simple RNN 模型的改进,可以避免梯度消失的问题,拥有更长的记忆。LSTM 内部结构中,最重要的结构是传输带C,过去的信息直接通过传输带送到下一时刻,传输带可以避免梯度消失。
LSTM 由遗忘门、输入门、计算及输出门这4部分组成,它们可以选择性地让信息通过。遗忘门ft介于0~1 之间,可以有选择地让传输带Ct-1的值通过,假设ft中有元素0,那么Ct-1中对应元素无法通过,即选择性遗忘掉一些元素;并且输入门it向传输带C中添加了新的信息,从而对传输带进行一轮更新。输出门ot依赖于旧的状态向量ht-1和新的输入Xt,计算类似于遗忘门。最后,对传输带Ct的每一个元素求双曲正切,将元素压到-1 与+1 之间,然后将ot与tanh[Ct]的对应元素相乘,运算符记为∘,得到状态向量ht。整体流程为:
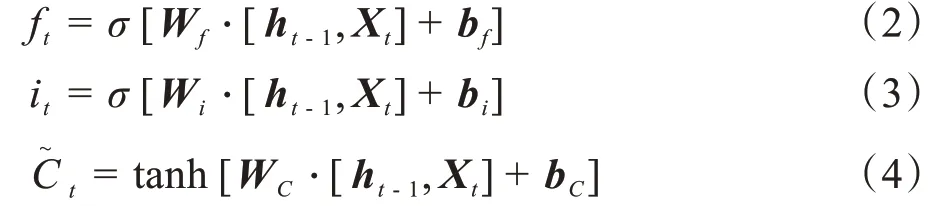
其中,σ为Sigmoid激活函数;、ft、it、Ct、ot、ht、Xt分别为t时刻的输入的中间状态、遗忘门、输入门、传输带、输出门、状态向量、输入向量;b为偏置向量;tanh为双曲正切函数;W为模型参数矩阵。
BILSTM 训练两条双向LSTM,一条从左往右,一条从右往左,两条LSTM 是完全独立的,不共享参数及状态向量。BILSTM 层的输出向量是由两条LSTM输出的状态向量拼接后得到的。
2.4 CRF
BILSTM 层能够学习上下文信息,但不能限制前后两个标签之间的关系,输出结果相互之间没有影响。BILSTM 在每一步挑选出最大的概率值作为输出标签,这样可能会出现B-label1 后接入B-label2 的情况;而CRF 中有特征转移矩阵,可以考虑输出标签之间的顺序性,从而提高预测的准确率。
CRF 是由Lafferty 等[16]在2001年首次提出。CRF 用于序列标注问题,是通过输入序列来预测输出序列的判别式模型。给定一组观测序列X={x1,x2,…,xn},得到预测序列标签y={y1,y2,…,yn}。文本X对应的标签y的分数由转移矩阵A和发射矩阵P相加得到。
其中,Ayi,yi+1为从标签yi到标签yi+1的转移分数;Pi,yi为发射矩阵,表示第i个字符预测为yi标签的分数。
CRF 的优化目标是正确序列的概率最大化,给定一个线性链条件随机场P(y|X)
其中,y'为所有可能的状态序列集合,y为真实序列。
让真实序列的分值在所有序列的分值和中最大。最终做预测时,采用Veterbi 算法,在所有状态序列中寻找分值最大的序列,即为CRF 层的最终标注序列。
3 实验
3.1 实验环境与数据
本实验在Ubuntu18.04 LTS 上进行,使用语言为Python 3.7,GPU 版本为华硕1070Ti GPU,显存8 G,CPU 为E3-1281-V3,系统内存为16 G,tensorfolw 版本为1.15GPU版。
实验数据由阿里云天池大数据平台提供,数据内容主要为基于糖尿病的相关研究论文以及糖尿病临床指南。其中共有363 篇文档,约250 万字,训练集与验证集以8:2 的比例划分。测试集由平台独立提供的59篇糖尿病文本构成。由于数据存在一定的噪声,需要对数据进行清洗数据、句子划分等一系列预处理操作。
3.2 概念定义与标注文本
糖尿病NER 旨在从大量医学文献中抽取有价值的医学知识,其知识指医学文本中有用的实体,将实体按事先定义的实体类型进行分类,即NER 过程。实体类型的定义需要满足知识图谱的应用需求,本研究针对糖尿病知识图谱的应用需求,定义了15 类实体类型,如表1所示。
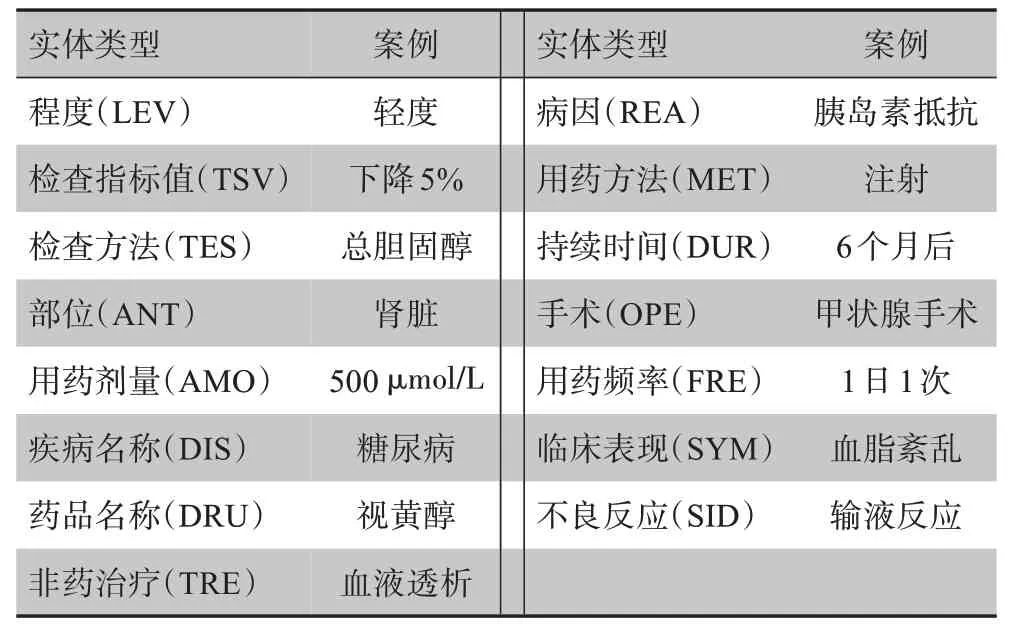
表1 实体类型定义Tab.1 Entity type definition
本研究采取BIO序列标注模式,对句子中的每个字符进行标注。“B-实体类型”表示为该实体类型的实体首字符标签,“I-实体类型”表示为该实体类型除了首字符标签外实体其他符标签,“O”表示非实体标签。本次任务有15 种实体类型,因此每个字符有31种标注可能性,如表2所示。
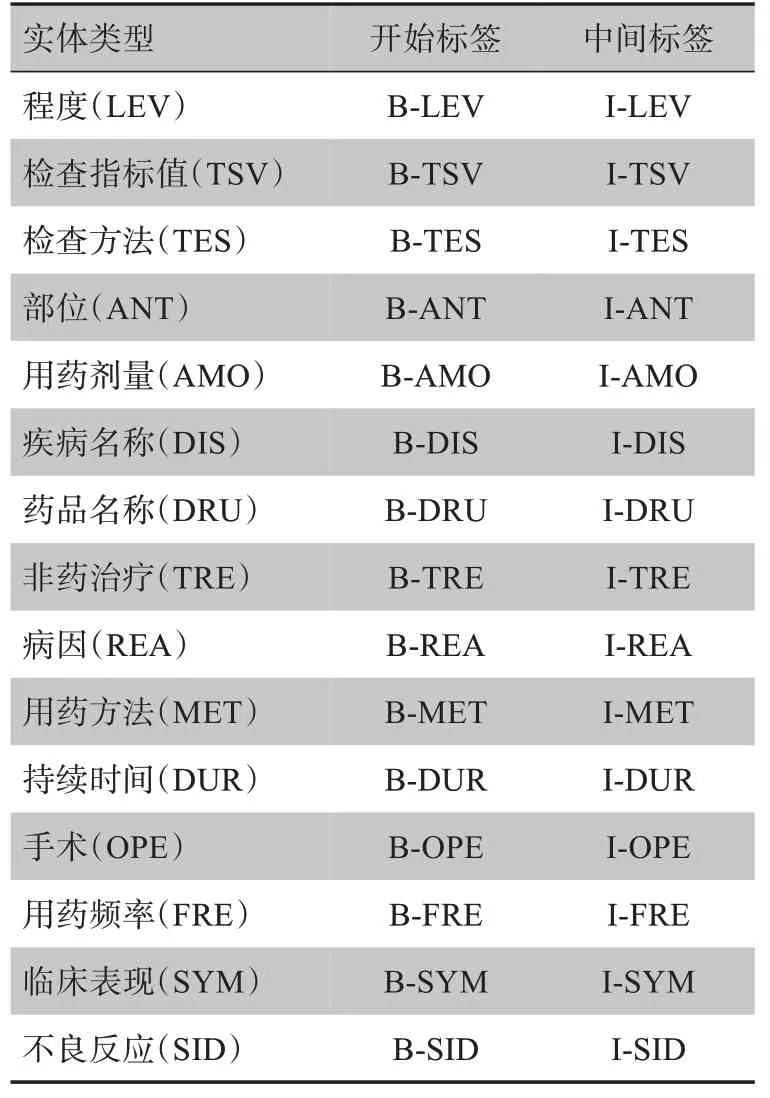
表2 实体标签定义Tab.2 Entity tag definition
3.3 评价指标
糖尿病NER 采用精确率P、召回率R 和F1 值作为评价指标,具体公式如下。

其中,TP 为识别到正确实体的个数;FP 为识别到非实体的个数;FN为未识别到正确实体的个数。
3.4 参数设置
本研究采用谷歌发布的ALBERT_BASE 模型,其模型嵌入层尺寸128,隐藏层共12 层,隐层维度768,采用12 头模式,并使用gelu;BILSTM 的隐藏层节点数为100。ALBERT-BILSTM-CRF 模型训练参数如下:最大序列长度为128,batch_size 为32,epoch为9,ALBERT的学习率为5e-5,其他模块的学习率为0.001,dropout为0.5。
3.5 实验过程
为了证明ALBERT-BILSTM-CRF 明显提升了糖尿病NER 效果,本研究设计了几种方法进行对比:(1)BILSTM-CRF 模型,该模型为NER 的经典模型,使用word2vec 词嵌入作为文本的输入表示,然后输入BILSTM-CRF 模型进行编码以及预测。(2)IDCNN-CRF 模型,该模型同样使用预训练好的word2vec 词嵌入作为输入表示,语义编码部分使用的是IDCNN,与BILSTM-CRF 模型对比。(3)BILSTM-ATT-CRF 模型,在BILSTM 后添加一层注意力机制,根据相关程度选择序列特征。(4)BERTBILSTM-CRF 模型,模型使用预训练模型BERT 提取语义表征。
3.6 实验结果与分析
实验设置不同epoch 值,研究模型随着迭代次数的拟合状况,从而确定合适的epoch 值。实验结果如图4所示,横坐标为epoch值,纵坐标为实体识别的性能百分数。图中折线分别是F1、精确率和召回率的变化情况。由图可知,在第8 个epoch 时,F1 和精确率的值分别为70.02%和71.04%,达到最高;召回率在第9 个epoch 时达到最优值71.12%。随着训练次数的增加,模型逐渐拟合并趋于平稳状态。综合考虑,本研究选择9为实验的epoch值。
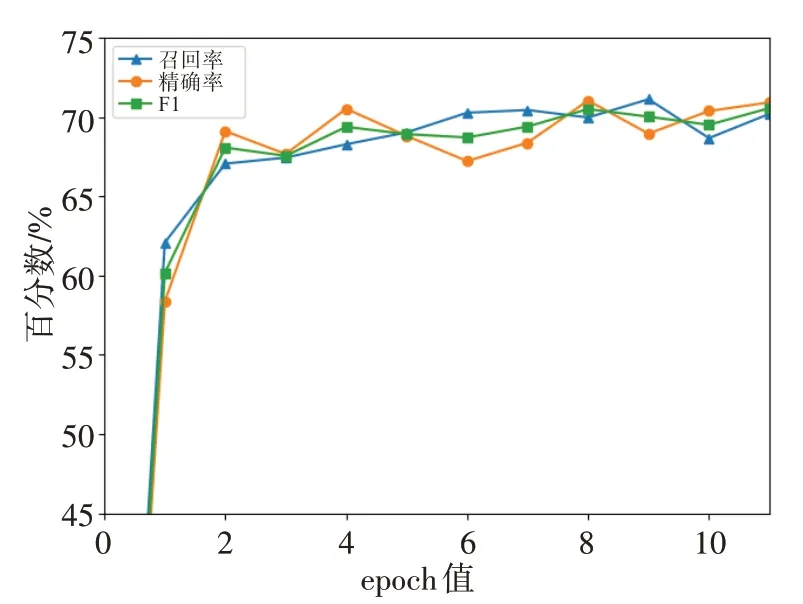
图4 ALBERT模型的各项指标变化Fig.4 Changes in various indicators of ALBERT model
为了体现出动态词向量模型的优越性,本研究对比了在糖尿病数据集训练过程中不同模型F1值的变化情况。从图5可以看出,BILSTM-CRF 和IDCNN-CRF收敛较为缓慢,在第7个epoch时开始收敛,而融合了ALBERT 模型的BILSTM-CRF 收敛更早速度更快,并且训练期间F1值波动较为平稳,远高于word2vec 词嵌入模型的F1 值,说明ALBERT 提供了更深层次的语义信息,进一步证明了动态词向量的优越性。除此之外,与其他模型的训练结果见表3。
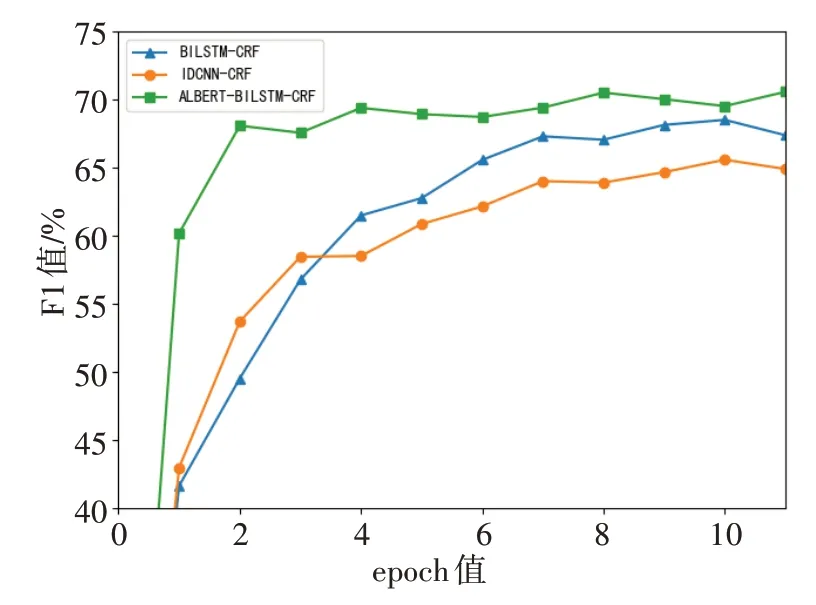
图5 不同模型的F1值对比Fig.5 Comparison of F1 values of different model

表3 不同模型的精确率、召回率、F1值对比(%)Tab.3 Comparison of precision,recall rate and F1 value of different models(%)
由表3可知,在糖尿病数据集中,BILSTM-CRF与IDCNN-CRF 实体识别的F1 值分别为65.25%和61.93%,BILSTM-CRF 添加注意力机制后F1 值达到66.47%,较之前提升1.22%。其中,BILSTM 最大的优点是具有强大的记忆力,在长文本处理中,距离较远的两个单词仍有依赖关系;IDCNN 更关注实体周围的信息;加入一层注意力机制的BILSTM,注意力权重矩阵会根据每个单元特征向量对于单词的重要程度分配不同的权重,对特征向量进行加权。实验结果说明BILSTM 在序列特征抽取方面优于IDCNN,基于注意力机制的模型相比无注意力机制的模型实体识别的F1 值提高1.22%左右。对比模型ALBERT-BILSTM-CRF 与BILSTM-CRF,F1 值提高了2.67%,说明ALBERT相对于传统的word2vec词向量,可以更准确地捕捉上下文的语法和语义层面的信息,具有更好的语义表征能力。
ALBERT-BILSTM-CRF 与BERT-BILSTM-CRF相比,9 轮次的训练后,识别准确率分别为68.14%和66.51%,F1 值分别为67.92%和67.72%;另一方面,BERT-BILSTM-CRF 训练耗时逼近50 min,而ALBERT-BILSTM-CRF 模型耗时40 min。总体看来,在各项评价指标相差不大情况下,ALBERT 的模型训练效率更为出色。这是由于ABLBERT 采用了参数共享机制,模型参数量仅为BERT 的十分之一。在训练过程中,需要梯度更新的参数大幅度减少,训练速度加快,在NER 任务上达到了相同的表现。从实验结果中可以看出,在削减参数量后,ALBERT 模型识别速度提高但性能并没有下降,这也说明BERT中存在冗余参数。因此,将ALBERT 引入输入表示层表现更为出色。
4 结束语
针对大多数动态词向量模型训练耗时长、资源成本高的缺点,本研究采用ALBERT 模型,提出ALBERT-BILSTM-CRF,ALBERT 通过参数共享机制,减少训练时长,提高实体识别的效率。该模型在糖尿病数据集上取得了良好的结果,与传统模型方法相比有所提高,但识别效果仍有提升空间,可以利用文本的其他特征,通过双通道特征融合继续进行研究。在接下来的工作中,将在糖尿病NER 的基础上,进行关系抽取,对糖尿病领域知识图谱基本框架进行设计。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30 01:29:23
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
中国外汇(2019年18期)2019-11-25 01:41:54
电子制作(2019年19期)2019-11-23 08:41:50
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
