
基于句法抽取与图结构编码的患者问询意图识别*
2021-12-01 14:17龚庆悦戴彩艳
计算机与数字工程 2021年11期
陈 燕 龚庆悦 戴彩艳
(南京中医药大学人工智能与信息技术学院 南京 210023)
1 引言
近年来,随着社交媒体的出现,挖掘文本主题的系列模型被持续更新。其中,在医疗领域,在线问诊系统、医疗问答系统、诊疗关联分析、临床评价语义挖掘等医疗文本研究取得突破性进展,中西医问询意图识别便是其中一项关键任务。现有的中西医文本数据挖掘模型(例如:LSTM[1~2]、CRF[1~3]、BERT[3~5]、FCA[6]等)的研究对象多数为长文本类型,而近10年中面向短文本的模型数量骤增,采用
基于神经网络分类模型[5,7~8]、传统分类器[9~11]等主流方法,详见表1。医疗问询短文本研究工作难度较大,原因在于患者在线问询过程中的单个问句一般不超过50字,没有丰富的上下文语义信息,意图识别中存在文本特征稀疏与主题匹配不精确两大难点。
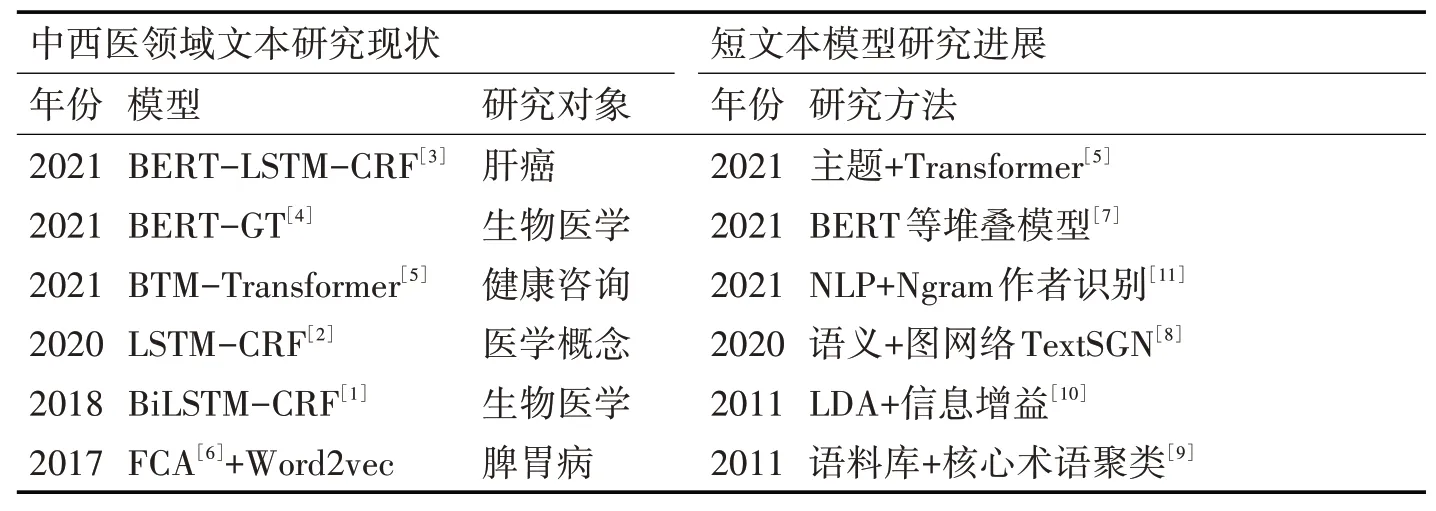
表1 中西医文本的分析模型
1967年Clifton K.Meador撰写 的《Short Text⁃book of Medicine》[12]中,以“医学教科书”为例,针对与长文本相比短文本删除了什么内容?剩余短文本内容如何处理?这两个问题做了详细解释说明。由此可以归纳当前短文本意图分类中所采用的研究技术可大致分为两大类:1)补充关联信息,即通过整合特征向量(例如:相关外部信息、短文本级联等),迁移使用长文本模型,例如LDA、BERT+word2vec抽取临床概念[13]等。2)提炼内部特征,即归纳短文本共现词语或交互关联等自身特点,例如BTM等。图神经网络短文本抽取模型既可以融合文本内部核心词的属性信息,同时整合短文本间的关联特点,正如王永剑等[14]在2020年提出采用GNN提取文本特征,黄金杰等[15]在2021年利用DNN与关联图增强实体表达,胡国勇[16]在2020年提出M-GCN注意力模型训练具有强泛化能力的特征生成模型等。图神经网络在编码短文本的技术发展中,也被用来与传统分类模型做对照实验或组合模型[17~18]。
本文以中西医在线问询数据为研究对象,抽取问询文本中患者所表达的真实意图,构建SGM(Syntactic+GAE+ML),编码部分一方面通过半监督学习构建短文本向量的关联句法依存树,获得来自同诊室患者问询语句的表达序列,克服意图匹配不准确的难点;另一方面采用双层图卷积神经网络结合机器学习分类器,克服短文本信息稀疏的难点,完成问询短文本意图分类工作。
2 相关工作
2.1 短文本的分类模型
短文本的特征表达技术中,常用的词频分析方法是BTM[19](Biterm Topic Model)模型,在捕捉短文本(例如标题[20]、问句[5]等)的主题信息环节中,增加了模拟单词共现和聚合语料库的环节;新兴的复杂网络模型,则是将短语、句子、段落作为神经网络的输入,从而训练得到文本的特征向量,例如BERT[21]、BiLSTM[22]、TextCNN[23]等模型。虽然较传统机器学习分类器学习专业文本更优,但迁移性较差,数据预处理繁琐。
短文本虽然内容稀疏,但仍具有中文句法结构信息,例如主语、谓语、宾语等句子主干成分。对此,在文本编码前利用句法结构标注技术分割句子短语,同时梳理句法成分。由此,也可以解决中文文本处理存在的一词多义问题,即同样的词语在不同的意图文本中所属的成分却不尽相同、所关联的短语句法关系也有差异。
2.2 图神经网络的文本分类模型
文本分类本质也是一种特征学习与标签分类的任务,随着图神经网络的发展,越来越多的学者在短文本分类中引入图神经网络技术,除了学习文本词/短语节点特征外,也融合了短文本间关联的相似性信息,通过构建提取文本特征信息的图编码网络[24],对微博[25]、Citnet[26]、抽象意义表示图[27~28]等数据开展了文本特征提取等相关工作,且取得较优的结果。
在大多数的图神经网络中做短文本意图分类任务时,先对图结构数据编码处理,融合节点特征与节点间的关联信息后,得到各节点的特征表示,最后特征预测环节可以选择一般的特征分类器完成。对此,在解码环节中选择SVM等机器学习(ML)与图卷积神经网络(GNN)对同一数据集进行对照实验,分析对于训练得到的短文本特征向量更适合采用ML与GNN二者哪种方法。
3 SGM框架
SGM将患者问询语句转化为短语特征网络做分类,需要训练两个模型:短语抽取模型与意图分类模型,详见图1。
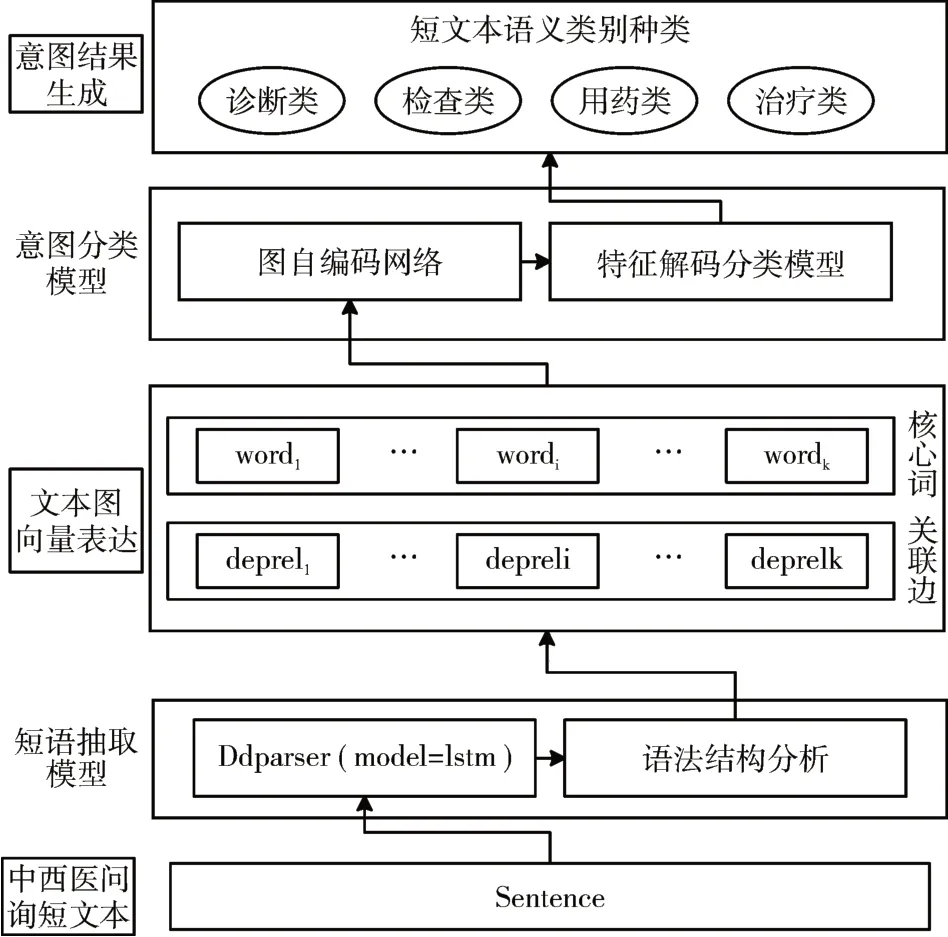
图1 SGM技术框架图
3.1 短语抽取模型
短语抽取模型分两步进行,详见图2。第一步,分析句子的句法结构,通过百度开源的DDPars⁃er模型[29]训练获得图注意力模型,为每个短语打词意标签,从而判断问询语句中患者的需求(即疾病诊断、检查、用药、治疗)。
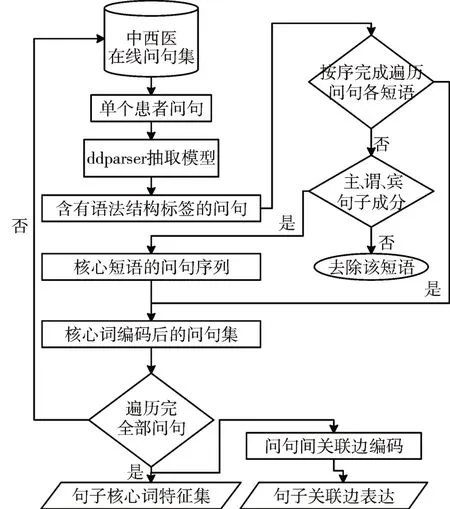
图2 短语抽取模型流程图
第二步,结合中文句子结构的特点,筛选句子主干成分(即主、谓、宾),从而进一步降低训练短文本数据的噪声,以“想请教下医生这个是确诊了食道癌吗”为例,展示了筛选患者问询语句后各短语所构成的语法关系图,详见图3。
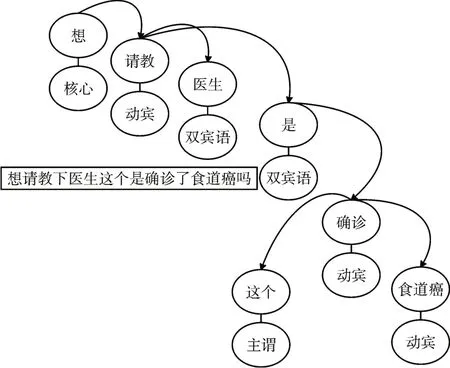
图3 患者问句核心短语的语法关系图
3.2 意图分类模型
传统的短文本类别分类常采用BTM(Biterm Topic Model)方法,依次进行共轭先验分布、共轭分布建模等工作。其中,第一步需要完成特征生成环节,详见图4,其核心就是绘制类别分布的Dirichlet函数Dir(α),其中,α≥0,α数值越大,则Dir(α)函数越离散。

图4 BTM主题分类模型
然而,在中西医患者问句分类任务中,来自同一个诊室的患者常具有相类似的意图需求,即问询句间的共同特征无法在特征学习中体现。与采用变分贝叶斯方法的BTM(详见图5(a))相比,基于图结构的编码器G(E,V)(详见图5(b))可以表达来自同一科室的患者间构建的关联边V与患者问询句的特征向量,将句法结构筛选后的短语序列表示作为输入节点E的属性特征,输出128维特征向量。
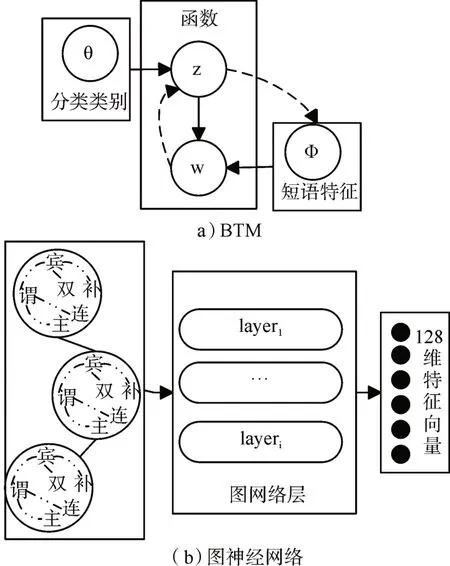
图5 文本特征编码模型
4 实验
本节主要评估患者问询意图识别结果,比较SGM与其他方法的实验结果,以F1值作为评价指标。
4.1 实验配置
1)数据集
实验数据选用患者在线问询数据,从“好大夫在线”(https://www.haodf.com/)官方网站公开信息检索2016年部分数据,参考网络社区的健康主题的八大特征分布[30],选取其中的诊断和检查、治疗两大主题并细分为“诊断类(通过描述指标、症状、病史等询问的病可能性)”、“检查类(各种确诊得病的检查或得病后的例行检查)”、“用药类(用药询问)”、“治疗类(医治咨询)”四种数据类型,共计16597条。
每条短文本字数均小于50,按照8∶2划分训练集与测试集,详见表2。实验中解答患者问询信息的医生来自全国,详见图6,涉及科室类型(外科、妇产科等)共计25种。

表2 实验数据划分对照表
图6 数据来源的地域分布图
2)基线方法
实验通过Pytorch+DDParser框架完成短文本图编码模型搭建,针对同一训练语料开展8种不同分类器模型的训练与测试,分别是DecisionTree、RandomForest、GBDT、AdaBoost、LR(LogisticRegres⁃sion)、Bayes、SVM、GCNs。
4.2 实验结果
通过ddparse处理后的问句中,所存在的语法类型有以下14种,详见表3。其中,能表达句子主题的内容基本均位于动宾、主谓、核心、连谓、双宾语这五个结构关系中,匹配中文句子核心结构(主+谓+宾)。

表3 句子语法类型表
将筛选出核心短语序列的问询语句集进行BTM主题概率分析与未筛选前进行比较,结果详见表4。
从“贡献率”可以发现筛选后数据的贡献率分布更加均匀,最高值较未筛选低0.243%,最低值较未筛选高0.002%;从“主题词集合”描述内容可以看出,筛选后分类的类别2(检查类)与类别3(用药类)分类效果良好,而其他两类分类(诊断类、治疗类)与未筛选的四个集合的特征均各有重合部分,各类别间的区分度不显著。由此也证明了筛选环节的必要性,以及BTM无法高效编码中西医问句文本特征。
与直接使用机器学习方法相比,将Syntactic+GAE编码后的问句向量输入到机器学习中,分类结果的F1值均有不同程度得提升,最高可提升17.6%,详见表5。
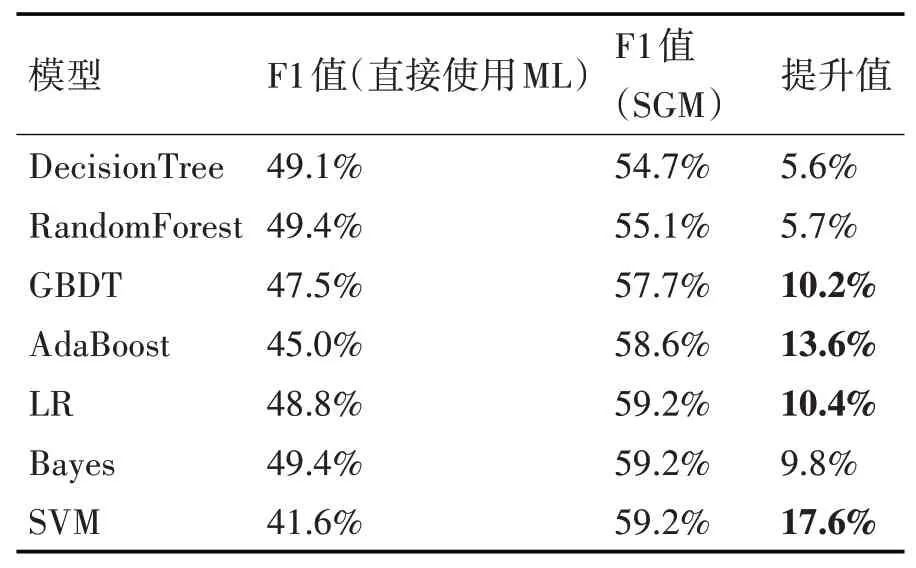
表5 SGM分类效果表

表4句子语法类型表
最后,实验也对经过Syntactic+GAE学习后的特征向量进行双层图卷积神经网络(Bi-GCNs)分类,F1值41.8%,效果也不如SGM。
5 结语
本文提出的SGM,通过构建两层图编码器,学习短文本间关联规律的同时,完成句法层词特征的融合,得到128维的句子特征向量,最后使用传统分类器完成意图分类任务,该方法具有以下优势:1)易迁移性,即分析句子语法结构,模型研究对象可切换为各领域中文数据,均能充分提取句子特征表达;2)可拓展性,即特征分类器可采用多种特征分类模型,模型具有较好的泛化能力。
实验过程中生成的关联矩阵数据量超过两千万,在存储、读取等环节中存在内存溢出等问题,对此本文提出调整相关代码或采用python的多进程技术来解决。虽然本文提出的SGM在实验分类中F1值最优,但没有特别高的客观因素是,当前国内没有含标签的、标准公开的、医疗问询意图划分数据集,关键的主观因素是影响患者问询意图的多条因素没有涉及,需要结合知识图谱推理进一步提升模型性能。
本文为提高SGM实验结果的精确度,后续将采取以下改进措施:1)深入清洗训练集中的脏数据,加强对中西医专业名称的规范化处理;2)在短语抽取环节中加入知识图谱关联机制,增强模型文本的特征表达。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
海峡姐妹(2016年2期)2016-02-27
延河(下半月)(2014年3期)2014-02-28
阅读与作文(英语高中版)(2013年12期)2013-12-11
阅读与作文(英语高中版)(2013年11期)2013-11-13
