
基于机器学习算法的脑卒中疾病早期预测模型研究*
2021-12-01 14:07:42郭志恒刘青萍王成武阮旭凌
计算机与数字工程 2021年11期
郭志恒 刘青萍,2 刘 芳 王成武 阮旭凌
(1.湖南中医药大学信息科学与工程学院 长沙410208)(2.湖南中医药大学中医学国内一流建设学科 长沙 410208)(3.湖南中医药大学药学院 长沙 410208)
1 引言
脑卒中是由脑血管破裂出血或者血栓形成导致脑部出血性或缺血性损伤的一组疾病[1]。根据世界卫生组织统计数据可知,脑卒中是全球第二大死亡疾病[2],具有高发病率、高死亡率、高致残率的特点[3]。临床上针对不同类型脑卒中的治疗方法存在差异,且一直缺乏有效的疾病治疗手段,目前预防是延缓脑卒中发病的最好措施。
近些年,国内外学者非常关注心脑血管疾病预测模型研究。具有代表性的模型包括美国Fram⁃ingham风险评估模型、欧洲冠心病风险评估计划模型、上海市健康教育所与“101健康管理”共同研发的“预防脑卒中”APP。随着大数据、人工智能等技术在医学领域的广泛应用,最新研究侧重于患者电子病历数据的跟踪和处理,以及采用机器学习、数据挖掘等方法构建较高精度的脑卒中风险预测模型[4~5]。目前临床上用于脑卒中预测的方法较多,例如吴菊华等[6]运用神经网络方法构建了脑卒中预测模型,采用神经网络中多层感知机构建模型,以Relu函数作为激活函数并取得较好的实验效果,完善了脑卒中的风险因素识别。邵泽国等[7]通过优化决策树方法对脑卒中日常生活习惯风险因素进行分析,在C4.5基础上将原始数据分为“有”“无”两类并嵌套生成树,依据知识规则得出风险因素的高低。李鹏等[8]基于逻辑回归算法对缺血性脑卒中发病率进行研究,通过逻辑回归算法对缺血性脑卒中的10个风险因素构建模型,以小批量梯度下降法求得模型解。
本研究采用支持向量机、逻辑回归、随机森林三种算法分别与SMOTE算法结合,构建脑卒中预测模型,通过三种算法的对比研究,找到更加适合构建脑卒中预测模型的算法,为脑卒中的预测和预防提供依据。
2 算法原理
2.1 SMOTE算法
SMOTE算法[9]是2002年Chawal等对数据分布不均衡提出的智能过采样算法。该算法在随机过采样算法基础上的通过对原有少数类样本进行分析并根据原有少数类样本人工合成新样本。对少数类中的每一个样本,以欧氏距离计算到少数类样本中所有样本的距离并得到其K近邻,再根据不平衡率确定采样倍率,从K个近邻中随机选出若干样本,原样本与新样本按照公式构建新样本。
2.2 支持向量机
SVM(Support Vector Machine,支持向量机)的基本思想是找出能将数据集划分的几何间隔最大的分离超平面,换言之,找到对分类结果的泛化能力最好、鲁棒性最优的线性方程。对待分类样本可构建的分离超平面为
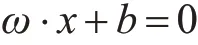
其中,ω为垂直平面的法向量,b为偏移量。
下面是最大间隔分离超平面的获得方法,可以表示为下面的约束最优化问题:
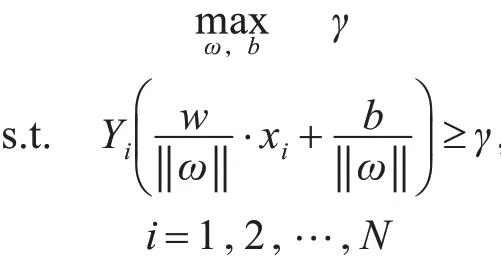
即希望最大化超平面(ω,b)关于数据集的几何间隔γ,约束条件表示的是超平面(ω,b)关于每个样本点的几何间隔至少是γ。
2.3 逻辑回归
逻辑回归属于广义线性回归模型,与线性回归类似,主要思想是通过已有数据拟合出一条直线,用拟合出的这条直线进行预测。其公式如下:
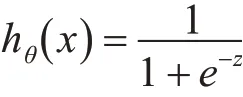
通过逻辑回归算法将线性函数得到的结果映射到sigmoid函数y=1/(1+e^(-x))中,通过极大似然估计来推导损失函数,再利用梯度下降法来求解参数来对数据进行二分类。
2.4 随机森林
随机森林算法是Breiman[10]等提出,该算法实际上是一种特殊的bagging方法,用bootstrap方法生成训练集,在决策树的基础上以随机的方式建立一个森林,森林里面有很多的根据训练集构建的决策树,各个决策树之间没有关联,有新样本输入,就放入之前得到的森林,由森林内的决策树分别进行判断,被选择较多的一类就为样本的分类。随机森林为了保证强大的抗过拟合和噪声能力,在构建每一棵CART决策树是采用了行抽样和列抽样的随机化方法。
3 对象和方法
3.1 研究对象
本文采用kaggle网站的healthcare-datas⁃et-stroke-data数据集。数据集样本总数为5110,包括2994名男性、2115名女性和1名不知性别者。其中,4861例为非脑卒中患者,249例为脑卒中患者。
3.2 实验方法
3.2.1 数据处理
1)数据量化及缺失值处理
数据集中每个样本具有11个特征属性和1个类别标签属性。其中,类别标签标明患者是否患脑卒中,11个特征属性分别记录每位患者的编号(id)、性别(gender)、年龄(age)、高血压病史(hyper⁃tension)、心脏病史(heart_disease)、婚姻史(ev⁃er_married)、工作类型(work_type)、居住类型(Resi⁃dence_type)、平均血糖水平(avg_glucose_level)、体重指数(bmi)和吸烟状况(smoking_status)。其中bmi属性中有201个缺失值,采用平均值法进行数据填充。为进一步提高模型的泛化能力以及方便对数据处理,本研究对性别、婚姻史、工作类型、居住类型和吸烟状况的数据分别进行量化。即性别(gender)中Female为1,Male为0;婚姻史(ev⁃er_married)中Yes为1,No为0;工 作 类 型(work_type)中Never_worked为0,Private为1,Self-employ为2,Govt_job为3,children为4;居住类型(residence_type)中Urban为1,Rural为0;吸烟状况(smoking_status)中never smoked为0,Formerly smoked为1,smokes为2,Unknown为-1。
2)数据不平衡处理
本文通过可视化发现卒中与非卒中患者分布差别明显,并对其进行不平衡率计算得出数据集不平衡率为5%,具体如图1所示。

图1 数据分布图imbalanced_ratio=stroke/non-stroke=0.0512
对于数据不平衡处理方法分别采用ADASYN算法和SMOTE算法,经对比发现SMOTE算法对数据处理效果更好。且考虑到ADASYN算法是根据分布来自动决定每个少数类样本所需要合成的样本数量,相当于给每个少数类样本施加了一个权重,周围的多数类样本越多则权重越高。由于卒中患者较少,使用ADASYN算法会使其权重变得相当大,导致生成过多的卒中样本。而SMOTE算法是对于少数类样本以欧氏距离为标准计算其到少数类样本集的距离,得到其近邻,避免了权重过高问题。
3.2.2 模型构建
在Windows10平台python3.8环境下构建SVM、LR、RF分类预测模型。对数据集做预处理并计算不平衡性,对不平衡数据中的少数类用SMOTE算法经行处理,然后与均衡数据构成新的“人工”数据集,再通过算法模型对数据集进行分类预测。具体流程如图2所示。

图2 模型构建流程图
3.2.3 性能指标
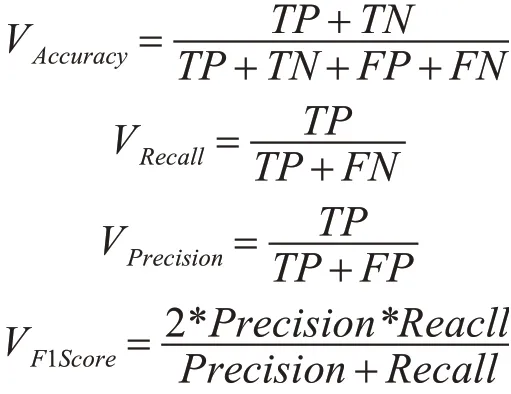
在医学诊断中,评价分类器的优劣通常采用准确率、召回率和精确度等指标。准确率(accuracy)表示对给定的是测试数据集,正确分类的样本数与总数的比值[11];召回率(recall)表示预测为正例的样本与实际为正例的样本的比值。精确度(preci⁃sion)表示实际为正例与预测为正例的比值。F1Score表示精确度和召回率两者之间的调和平均值。混淆矩阵表示分类器在测试集上的预测是否为正确,如表1所示。

表1 混淆矩阵
其中,P为正类样本的数目,N为负类样本的数目。关于四个评价指标的公式:
ROC曲线是真正例(True Positive Rate)为纵坐标,假正例(False Positive Rate)为横坐标所绘制的曲线,能反映不同的分类算法性能。ROC曲线越靠近纵轴,则模型预测效果越好。ROC曲线下面的面积为AUC,面积值越大,则算法性能越好。
4 结果与讨论
实验以healthcare-dataset-stroke-data数据集的70%为训练集,30%为测试集分别构建SVM、LR和RF算法预测模型。结果如下所示。
从表2与表3可以看出,数据集经过SMOTE算法处理,支持向量机、随机森林、逻辑回归预测模型在各项指标都有很大程度提高。支持向量机在Ac⁃curacy、Reacll、Precision、F1Score、ROC_AUC分别提高4%、34%、65%、63%、21%;逻辑回归在Accura⁃cy、Reacll、Precision、F1Score、ROC_AUC分别提高5%、12%、64%、59%、13%;随机森林提升不明显。为了更好的对比各个算法的性能,对SMOTE算法处理后的数据模型进行ROC曲线的绘制。从图可以看出,RF算法的ROC曲线最靠近纵轴,即AUC值最大,值为0.98,其可以更好地拟合数据,反映数据的真实性。
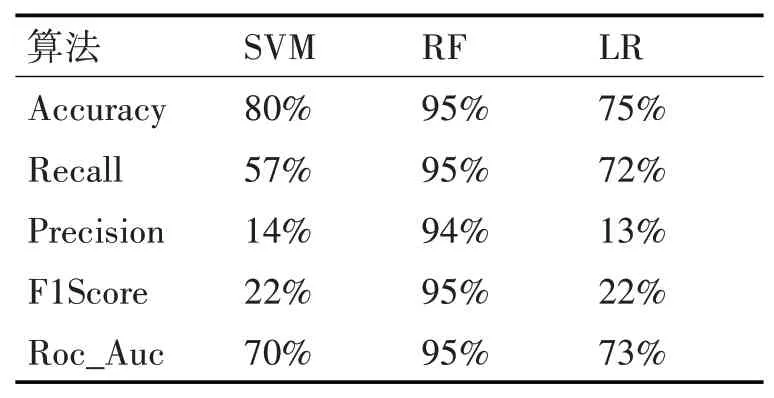
表2 算法对脑卒中测试集预测指标
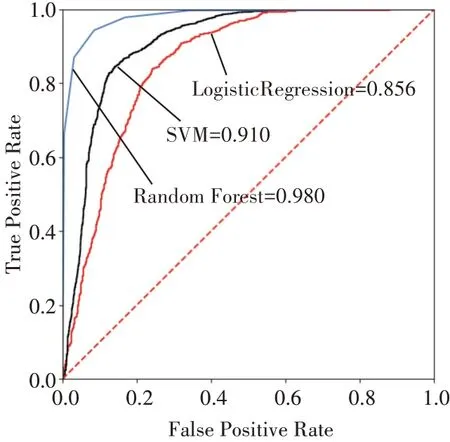
图3 不同分类算法的ROC曲线
经实验结果对比发现,随机森林算法在准确率、召回率、AUC值等都优于其他机器学习算法,可以作为辅助诊断工具应用到实际医疗诊断中,为脑卒中的早期预防提供科学依据。
通过实验结果发现,随机森林算法能较好地平衡不均衡数据集,对数据集的适应能力强,减小实验误差。随机森林属于集成分类算法,相对于单一分类算法性能更优,泛化能力更强。
5 结语
如今,脑卒中已成为全球第二大死亡疾病,且发病有年轻化趋势[12],目前预防是延缓脑卒中发病的最好措施。而急性缺血性卒中的快速识别与诊治对预后的影响至关重要[13~14],因此提高脑卒中的诊断效率,提高医生和患者的风险意识,对脑卒中的防治具有重要意义[15]。本研究通过SMOTE算法处理数据集的不平衡,选用机器学习算法中支持向量机、随机森林、逻辑回归算法构建预测模型。实验结果显示随机森林和SMOTE算法构建的脑卒中预测模型具有更好的预测效果,可以辅助医生提高脑卒中的诊断效率,为我国的在脑卒中诊断方面提供技术手段。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学年刊A辑(中文版)(2021年3期)2021-11-05 08:36:32
数学年刊A辑(中文版)(2021年2期)2021-07-17 08:37:58
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
数学物理学报(2019年1期)2019-03-21 05:26:12
电子制作(2018年16期)2018-09-26 03:27:06
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
