
基于机器学习的肉鸡沙门氏菌污染风险敏感性分析
2021-11-18 01:39瞿孝云肖兴宁肖英平刘元杰张建民华汪
农产品质量与安全 2021年6期
瞿孝云 肖兴宁 肖英平 刘元杰 杨 力 张建民 杨 华汪 雯
(1.华南农业大学,人兽共患病防控制剂国家地方联合工程实验室,农业农村部人畜共患病重点实验室,广东省动物源性人兽共患病预防与控制重点实验室,广州510642;2.浙江省农业科学院农产品质量安全与营养研究所,农产品质量安全危害因子与风险防控国家重点实验室,农业农村部农产品质量安全风险评估实验室(杭州),杭州310021;3.中国农业大学信息与电气工程学院,农业农村部农业信息获取技术重点实验室,现代精细农业系统集成研究教育部重点实验室,北京100083;4.中国计量大学信息工程学院,杭州310018)
沙门氏菌(Salmonel l a)是人畜共患的革兰氏阴性病原菌。据统计,我国70%~80%的细菌性食物中毒是由沙门氏菌引起,每年病例约820万[1]。肉鸡是沙门氏菌的常见宿主,屠宰过程中的宰杀、沥血、浸烫、掏膛、内腔淋洗、预冷清洗等环节是造成产品污染的重要环节,据报道,我国屠宰环节的鸡肉沙门氏菌污染率高达62.9%[2]。本课题组前期基于模拟实验数据,构建了多元非线性回归沙门氏菌污染率预测模型,但传统的回归模型需对变量进行组合或剔除,易造成高维数据拟合的信息缺失,较难实现多维数据下的精准预测[3~4]。机器学习算法可从海量、复杂的数据中深度学习找到关键信息和变量之间的隐藏关系[5]。当前,我国大型肉鸡屠宰场引入了自动化系统,该系统运行积累了大量的温度、湿度、预冷水氯浓度等传感器检测数据,屠宰场日常微生物检测也积累了大量的细菌污染率数据。基于屠宰场监测数据,利用机器学习算法构建沙门氏菌污染率风险分析模型,对保障产品安全具有重要意义。
分类型机器学习算法是通过构建模型对数据进行分类,学习数据在构建模型的过程中起着重要的作用[6]。基于样本数据量的差异,支持向量机、朴素贝叶斯和神经网络模型被广泛应用于非线性问题的预测中。支持向量机和朴素贝叶斯算法适合解决小样本数据量问题。支持向量机通过超平面的边界将数据划分为具有近似值的组,对于非线性问题,通过线性核、多项式核、S形核、径向基核函数等核函数来解决[7~8]。朴素贝叶斯是通过比较测试样本各类别的条件概率进行预测[9]。神经网络是模拟生物神经系统,通过确定节点及节点之间关系以进行预测,其并行分布处理能力强,适合解决大样本数据量问题[10~11]。
本研究分别基于支持向量机、朴素贝叶斯和神经网络3种机器学习算法,建立以日屠宰量、环境温度、环境湿度、宰前污染率、浸烫环节交叉污染、掏膛环节交叉污染、预冷水氯浓度为输入值,肉鸡宰后污染率为输出值的肉鸡宰后沙门氏菌污染率预测模型,并通过随机森林算法对最优模型进行敏感性分析,为微生物污染率风险预警提供模型基础。
一、材料与方法
(一)数据来源
1.环境参数和加工参数。本课题组于2016-2019年在广州某家禽屠宰企业进行了数据收集。日屠宰量数据来源于现场调研;环境温湿度数据来源于生产线温湿度传感器的监测;预冷水氯浓度数据来源于有效氯测定仪对每小时预冷水氯浓度的监测,结果详见表1。
2.沙门氏菌污染率检测。(1)主要实验仪器。QHZ-98A/QHZ-98B全温振荡培养箱(太仓市华美生化仪器厂);SHP-250生化培养箱(上海精宏实验设备有限公司);SYN-K电热恒温水浴锅(北京长风仪器厂);5424R高速冷冻离心机(德国Eppendorf公司);PTC-200 PCR扩增仪(美国MJ ReSearch公司);SBD-50水浴摇床(美国MJ Re-Search公司);Gel Doc XR凝胶成像系统(美国Bio-Rad公司);Power Pac universal TM核酸电泳仪(美国Bio-Rad公司)。(2)沙门氏菌的分离培养与鉴定。每月分别采集肛拭子、浸烫后、掏膛后、预冷后鸡胴体各20份,共30个月。按照GB/T 4789.4-2016《食品安全国家标准 食品微生物学检验 沙门氏菌检验》规定,经过预增菌、增菌、划线、纯化、鉴定等步骤进行沙门氏菌鉴定。污染率检测结果见表1。
3.宰后肉鸡沙门氏菌污染率分类。我国针对鲜(冻)畜禽产品(GB 2707-2016)和畜禽屠宰加工(GB 12694-2016)的国家标准均未考虑微生物指标。美国和欧盟制定了鸡肉产品沙门氏菌污染率限量标准,要求宰后鸡胴体中沙门氏菌的污染率不得超过15.4%和9.8%[2]。参考欧美沙门氏菌限量标准,定义宰后污染率变化范围<10%的数值为标签“0”,即低污染风险;宰后污染率变化范围≥10%且<15%的数值为标签“1”,即中污染风险;宰后污染率变化范围≥15%的数值为标签“2”,即高污染风险(见表1)。
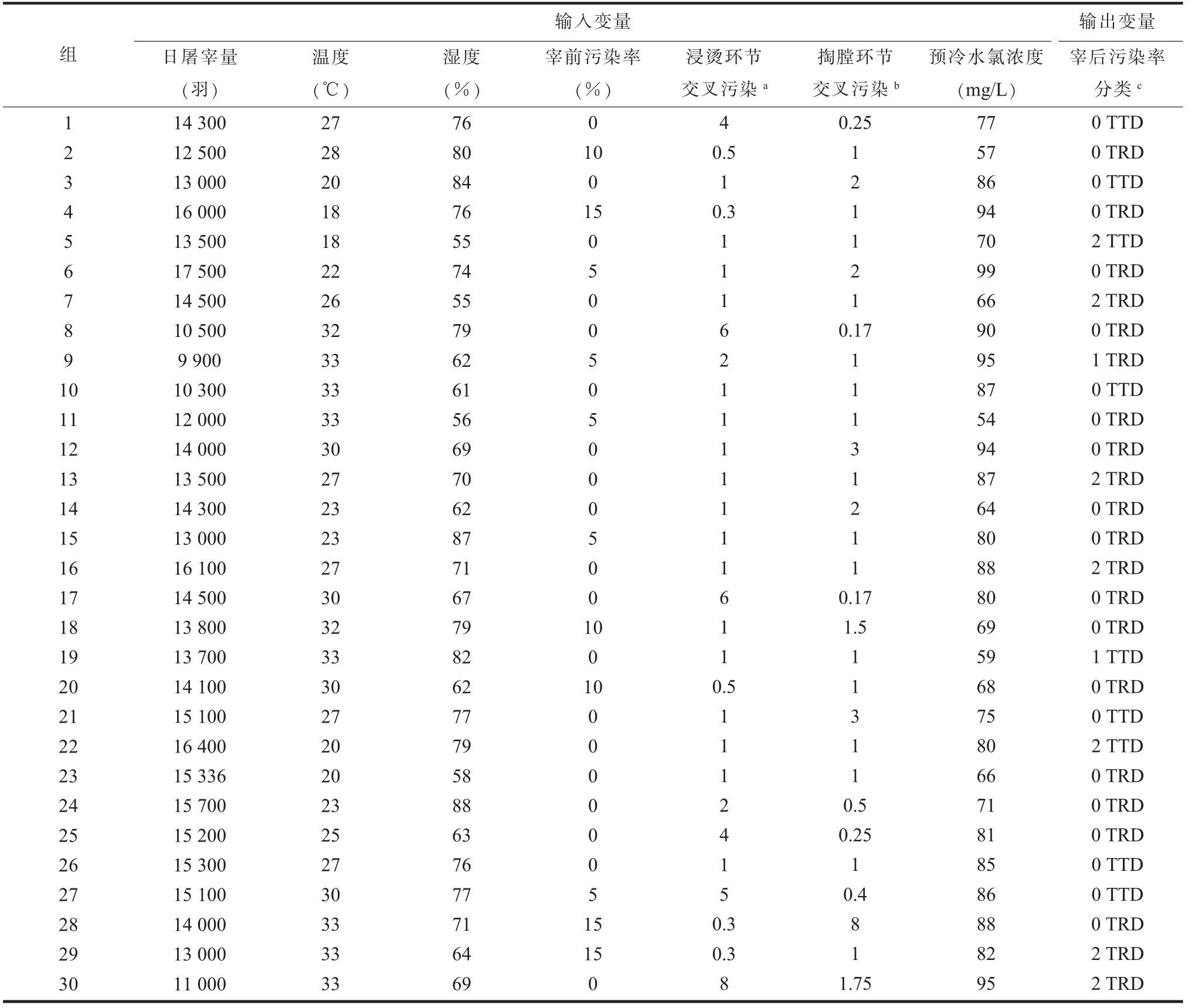
表1 肉鸡屠宰环节的数据变量
(二)污染率预测模型构建
1.支持向量机。支持向量机(Support vector machine,SVM)是一种监督学习算法,具有强大的分类鉴别能力。SVM算法通过构造一个(n-1)维的分离超平面来区分n维空间中的2个类,该超平面把输入数据转换到高维空间,生成一个n维向量,并且最大化2个数据组之间的余量来对不同类别进行最优分离。训练数据集设置见公式(1)[13]。
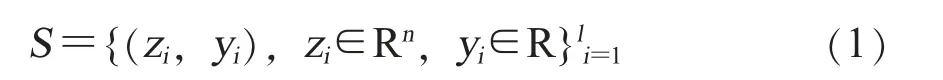
公式(1)中,zi为第i个输入特征向量,所有描述系统状态的输入特征向量组成z;yi为第i个样本的分类标识,yi∈{-1,1};l为样本数;n为向量空间维数,求解最优分类超平面[14]。
2.朴素贝叶斯。朴素贝叶斯建立在贝叶斯决策理论和贝叶斯网络的基础上,属于监督学习。算法主要分为2个阶段:第1阶段,对实验样本进行分类,分别计算不同条件下的概率;第2阶段,输入测试样本,计算不同条件的概率,比较其概率大小,从而完成对测试样本的分类。训练数据集设置见公式 (2)[15]。
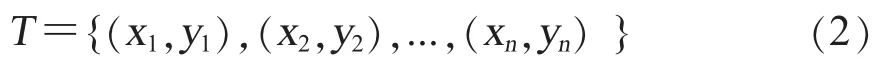
公式(2)中,X={x1,x2,...,xn}表示包含不同特征属性的屠宰环节输入参数特征集;Y={y1,y2,...,yn}表示不同宰后污染率集合。
3.神经网络。人工神经网络由大量的节点相互连接构成。每个节点代表一种特定的输出函数,称为激活函数。每2个节点间的连接都代表一个对于通过该连接信号的加权值,称为权重。网络的输出则依据网络的连接方式、权重值和激活函数的不同而不同[16]。本研究采用的是反向传播人工神经网络,应用tan h激活函数,神经网络的结构如图1所示。
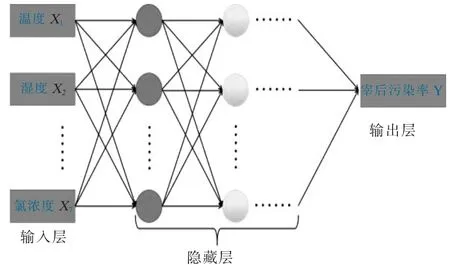
图1 神经网络结构
(三)模型评价利用SAS软件的“预测建模”模块进行支持向量机、朴素贝叶斯和神经网络建模。误分类率(Error rate,ER)表示被分类器错误分类的元组所占百分比,反映了分类器对各类元组的正确识别情况,可通过混淆矩阵来计算。受试者工作特征曲线(Receiver operating characteristic curve,ROC)是以灵敏度为纵坐标,“1-特异度”为横坐标绘制的曲线,若曲线下面积(Area under the curve,AUC)越接近于1,则模型的预测性能越好。均方根误差(Root mean square error,RMSE)是用来衡量观测值同实际值之间的偏差。采用ER、AUC和RMSE指标来评价模型预测精度,其中ER和RMSE越小,A UC越大,表示模型预测精度越高[17]。
(四)风险敏感性分析预测模型中各解释变量对目标变量的影响存在差异,随机森林算法可衡量单一解释变量对目标特征的敏感性,根据逐一移除变量后模型准确性的降低程度来衡量变量重要性[18]。基于SAS软件的随机森林算法对日屠宰量、环境温度、环境湿度、宰前污染率、浸烫环节交叉污染、掏膛环节交叉污染、预冷水氯浓度等因素进行重要度排序。
二、结果与分析
(一)模型评估与比较支持向量机模型对训练数据集的拟合能力较好(AUC>0.7,ER=23.8%,RMSE=0.42)(见表2和图2)。朴素贝叶斯和神经网络模型的AUC值较低,模型的预测效果一般,存在欠拟合风险(见表2)。研究发现,支持向量机在解决小样本、非线性、高维的数据预测问题上有很大优势,在解决分类问题方面表现出色[13]。袁彦彦和王兴芬[19]基于21条实验数据量,比较了支持向量机与神经网络模型对速冻水饺变温冷藏的货架期的预测效果,发现支持向量机模型的预测结果更能接近实际情况。在疾病风险预测方面,ALMANSOUR等[20]分别使用支持向量机和神经网络来分类4种肾脏疾病,结果发现,支持向量机方法的准确率高达76.32%,并且处理时间相比神经网络缩短一半以上。支持向量机模型的最终决策函数由少数的支持向量所确定,结果不易受到模型中存在的数据扰动、噪声及离群点的影响[14]。神经网络更适用于大样本量的数据集,计算结果受初值影响大,系统训练需要较长的时间。系统训练不稳定,当学习速率过大时,权值在修正过程中会超出误差的最小值而永不收敛[13]。

表2 3种机器学习算法统计分析结果

图2 支持向量机模型训练集(A)及验证集(B)ROC曲线
(二)风险敏感性分析随机森林算法分析重要度发现,影响宰后污染率的关键因素依次为环境温度、环境湿度、宰前污染率、掏膛环节交叉污染、预冷水氯浓度、浸烫环节交叉污染、日屠宰量(见图3)。HWANG等[21]采用随机森林算法研究发现,环境温度、湿度是影响肉鸡污染率的关键因素。据报道,微生物检测结果易受季节变化的影响,研究发现,夏季肉鸡沙门氏菌污染率显著高于其他季节,可能是由于沙门氏菌在高温、低湿的环境下抗性较强[20]。XIAO等[12]基于斯皮尔曼相关性分析,发现宰前污染程度和屠宰环节预冷水消毒剂浓度是影响肉鸡沙门氏菌患病风险的关键因素。因此,通过加强屠宰环境温湿度的控制、屠宰过程适当添加杀菌剂等措施可有效降低宰后的沙门氏菌污染率。
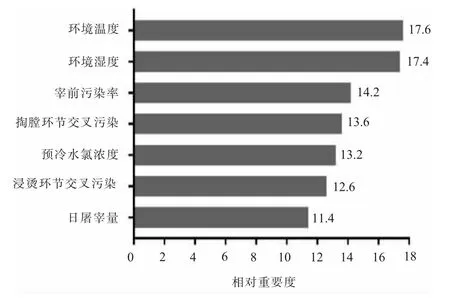
图3 影响宰后污染率的关键因素排序
三、讨论
在细菌污染率的分类预测研究中,机器学习方法的应用是一个重要的研究方向。如HWANG等[21]基于温度、湿度、风速、降雨量等83个气象变量监测数据,通过随机森林算法构建了养殖环节沙门氏菌的污染率预测模型。肖兴宁等[3]建立了初始污染率、初始污染水平、次氯酸钠浓度为显著影响因素的广义回归神经网络污染率预测模型。在算法优化方面,机器学习的集成算法可将多个单一算法集成在一起,减少模型的不确定性和误差,使得机器学习的效果更好,如聚合多个分类或回归模型的Stacking算法,可考虑应用机器学习算法的集成来预测细菌污染率[22]。
机器学习的各类算法,本质在于提取特征和标记的相互关系,因此对于特征和标记的质量要求较高。特征和标记的质量越高,其算法的分类效果越好[23]。算法比较依赖输入数据的质量,由此可见,机器学习在微生物污染风险分析中的应用效果与相关指标检测技术的发展息息相关。沙门氏菌的传统检测方法有菌落培养和计数、聚合酶链式反应,但是其制样过程复杂、耗时,无法应用于实时检测。生物传感器分析技术与传统的检测方法相比具有选择性好、灵敏度高、分析速度快等优点[24]。因此,在现有的温度、氯浓度等物理和化学传感器的基础上,结合微生物快速检测生物传感器,通过数据无线传输技术,可实现沙门氏菌污染率的实时风险分析和预警。
四、结论
本研究以日屠宰量、环境温度、环境湿度、宰前污染率、浸烫环节交叉污染、掏膛环节交叉污染、预冷水氯浓度为输入值,肉鸡宰后污染率为输出值分别构建了支持向量机、朴素贝叶斯和神经网络模型,支持向量机模型对沙门氏菌污染率风险预测效果优于其他2种模型。敏感性分析表明,环境温湿度是影响宰后污染率变化的重要因素。然而,本研究也存在一定的局限性,如样本量较少、分类模型的预测准确性不高、模型的泛化能力还有待验证等。在后续的研究中将进一步扩充用于构建模型的数据样本量,尝试用更科学的算法构建模型以提高模型分类准确率,使得机器学习方法能够更好地应用于肉鸡沙门氏菌污染率的风险分析。
猜你喜欢
动物医学进展(2022年9期)2022-09-06
今日农业(2021年7期)2021-11-27
中国饲料(2021年17期)2021-11-02
食品安全导刊(2021年20期)2021-08-30
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
今日农业(2020年14期)2020-08-14
疯狂英语·读写版(2019年10期)2019-09-10
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
