
数据并行传输程序中代码坏味检测算法研究
2021-11-17 07:09于萧榕黄健荣
计算机仿真 2021年5期
于萧榕,黄健荣
(江苏科技大学计算机学院,江苏 镇江 212003)
1 引言
并行传输是指以分组的形式,通过多个并行信道同时传输数据。在传输过程中,多个数据一起在设备之间传输,并且一次可以传输一个字符,收发双方不需要同步,控制方式简单快捷。然而,并行传输需要多个物理信道,因此这种传输方式只适用于短距离、高传输速率的情况。程序中的代码坏味是由设计缺陷或不良的编码习惯引起的,它影响了软件程序和结构代码的质量[1]。针对代码检测问题,众多学者作出研究,其中,文献[2]探究坏味产生的影响以及坏味与软件演化之间的关系,有助于开发者更好地在不同的项目中呈现出不同的特征,将计划软件开发过程和重构软件代码,并在8个Java项目共计104个版本中进行了系统的实证研究,但是其准确率尚未验证。文献[3]基于梯度提升树,研究了恶意代码分类方法,使模型结果行为序列具有可解释性,客观地反映恶意代码的行为和意图本质,解决变种恶意代码、未知威胁行为恶意分析等问题,实现了智能恶意代码分类功能,但其模型召回率较低,计算量较大。文献[4]使用人工智能与机器学习技术,辅助软件工程中的代码编写、纠错、测试等具体工作在软件开发过程中,提升软件开发效率,进一步提升软件开发过程的自动化,但是其辅助软件工程信号处理环节尚不明确。
为此,本文提出一种基于数据并行传输程序中代码坏味检测算法研究,其关键在于利用贝叶斯网络将最新的检测规则转化为概率模型,实现代码坏味检测,该检测方法能够有效的对代码坏味进行准确、高效检测。
2 数据并行传输程序分析
并行数据传输系统的原理是依靠相邻通道,每个信道需要发送两组独立的数据序列,通过抑制载波幅度调制,分别调制成一对正交载波(频率等于信道的中心频率),各组数据序列码速是b/2,两组序列在时间上面交错为1/b。而相邻信道则反向交错,便于调制偶数信道上余弦载波数据的序列与调制奇数信道上正弦载波数据的序列同向,相反亦然。
具体并行数据的传输信号频谱如图1所示。
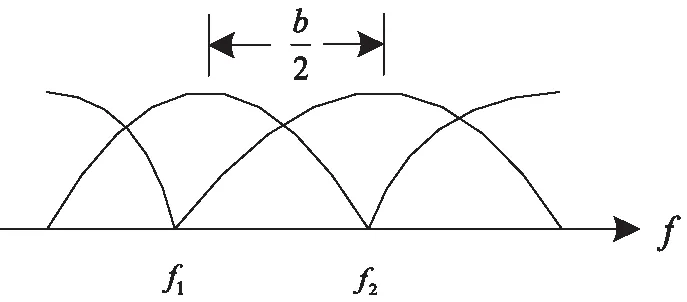
图1 并行数据传输程序频谱
如果全部的发送滤波器以及接收的滤波器都存在同样滤波器特性F(ω),并且它们受到相对信号码速ω的限制,全存在奈奎斯特的滚降现象,所以可以得到公式为
F(ω)=0,|ω|≥πb
(1)
式中,F表示加窗方式。以及公式为
F2(ω)+F2(πb-ω)=1,0≤ω≤πb/2
(2)
而传送信号公式为
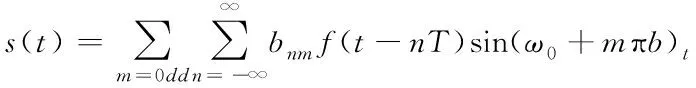
(3)
式中:T=2/b表示f(t)反向傅里叶的变换,anm与bnm都是数据m或n的序列,f(t-nT)表示部分频率的信号受到的较大时间系数t的抑制阈值T[5]。
由于系统的对称性,与线性扩散传输介质相比,只需考虑一个子信道。无论是偶数信道、奇数信道、正弦信道还是余弦信道,它们的结果都是相等的。由于系统是线性的,失真可以由在每个子信道中传输的单个脉冲的响应来确定。
将传输媒质频率的响应设为
H(ω)=A(ω)exp[jφ(ω)]
(4)
忽略任何恒定的时间延迟,如果没有出现一般损失状态,那么下面利用第k个信道余弦子的信道作为例子进行失真情况分析。
与子信道相比,需要考虑六个失真分量。它们是正交信道和同一信道产生的失真,以及相邻比高低信道中串扰产生的失真[6]。
在子信道内单个脉冲进行传输时,具体的接收信号频谱公式为
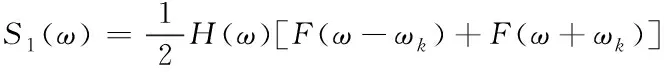
(5)
式中,ωk=ω0+kπb代表信道中心的频率,此信号与2cosωkt相乘,且利用F(ω)滤波,生成频率公式为
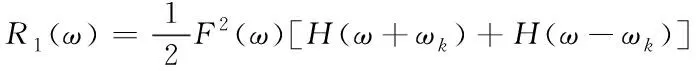
(6)
当t=t0时刻对此信号进行采样,方便恢复数据。其失真被定义成在全部其它采样时刻的信号绝对值总和nT以及中心采样的时刻信号幅度r1比值,具体公式为
D1=r1(t0+nT)
(7)
在这里为
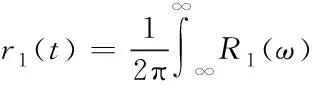
(8)
式中,R1(ω)表示对称子信道线性函数。当正交子信道中,对于单一脉冲接收的信号公式为
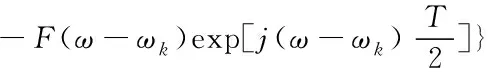
(9)
式中,出现相位因子的原因是脉冲时间偏移了半个信号周期。在经过2cosωkt调节和F(ω)滤波之后,传输至同相子载波采样器信号的频谱内,具体公式为
R2(ω)=F2(ω)[H(ω-ωk)-H(ω+ωk)]
(10)
此种干扰信号全部采样值生成的失真公式为
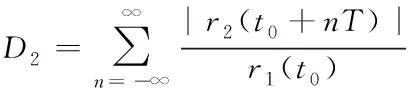
(11)
基于相似原理,对源于第(k+1)与(k-1)个信道同相以及正交子信道干扰的分量进行分析,其中最相似的分量查找结果表示为
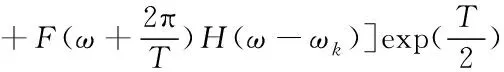
(12)
以及
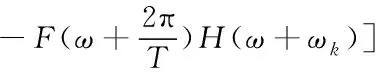
(13)
以上式(12)和(13)和式(11)相同,所以,总失真即为此6个分量累加,具体公式为
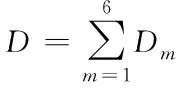
(14)
至此,得到数据并行传输程序的具体描述和失真效应的分析[7]。
3 程序代码坏味检测算法
程序代码坏味的检测过程如图2所示。
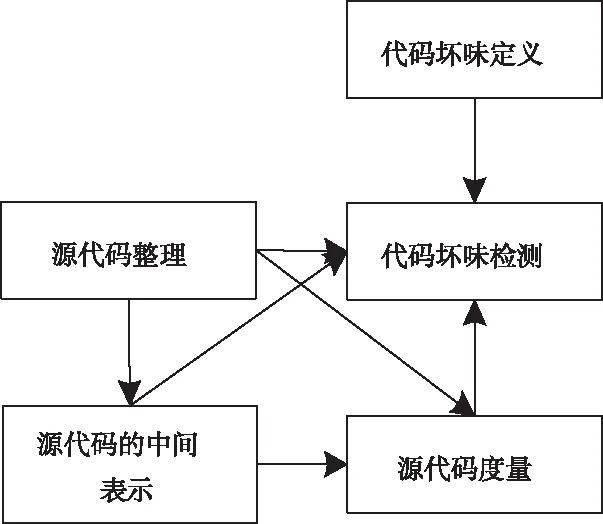
图2 程度代码坏味的检测流程
如图2所示,源代码或源代码度量定义可以用作输入。在大多数检测技术中,都使用从源代码中提取的度量。
数据并行传输程序通常完成相同的功能模块,而设计较差的程序也需要更多的代码,这也导致代码在不同的区域使用相同的语句来完成相同的事情。因此,重复代码坏味会对程序设计产生非常严重的影响,重复的次数越多,修改程序的难度就越大。如果某个区域被修改,数据并行传输程序将变得更加困难,它将无法按预期运行。代码臭味的定义没有统一的标准,定义代码臭味会因指标不同而产生不同的结果。程序的质量评价标准是以人为中心的,所以相对于一个班级是否有臭味,总会有一定程度的不确定性。贝叶斯方法可以将最新的检测规则转化为概率模型,具体的检测结果将以概率的形式呈现出来,从而使一个类属于不良品味度。
贝叶斯网络是作为一个表示概率分布非周期性的图表,此图表内,每一个节点就代表一个随机变量Xi,这两个节点间的边代表一个概率,此概率是父节点代表变量和子节点代表的变量间依赖程度度量。假设贝叶斯网络内表示各个节点为Xi,只是某一些条件之下所独立于父节点,各个节点Xi所关联一个条件的概率表,此条件概率表代表全部概率分布的可能值[8]。
贝叶斯网络的构建需要两种信息:条件概率表和网络结构,其中网络结构由节点和节点之间的弧构成,条件概率可以利用历史数据进行学习,其主要功能是描述每个节点的决策过程。
将贝叶斯分类器应用于贝叶斯网络分类问题。程序代码的异味检测可以看作是一个分类问题。与给定类的检测结果相比,只有一个输出:C={smell,notasmell},不过输入是叙述类特征的向量。相对于各个分类的问题,检测的结果会对应一个概率,此概率度量了检测结果不确定的程度,在分类d维向量时,能够决策类别c是概率最大类,具体公式为:
c=arg maxckp(ck|a1,…,ad)
(15)
式中,ck是覆盖了C内全部类的集合,ai代表d维向量,通过具体度量值所构成的[9]。
针对坏味代码在其它区域反复出现,但尚未修改问题,根据检测规则构造贝叶斯网络。具体过程分为两个步骤:将检测规则中的输出变量转换为具有概率分布输入的节点;将检测规则内的操作进行转换,使其具有条件概率决策节点,具步骤如下所示:
1)输入的属性
相对于代码坏味的检测结构以及语义规则,它们的概率不是0即是1,而度量值,它的概率通过三组(高、中、低)进行计算,且要分析属于各个组的度量值,以此来估算概率值,限制的组数通过三组简化结果证明。在检测的过程内,较高与较低的概率全指1,而其它值概率是经过自身计算的值以及附近的阈值相关距离获取的[10]。
2)运算符设置
在不同检测的规则内,合并信息存在两种操作:并集以及交集。所有操作都能够作为决策节点进行编码至叶贝斯网络内,此节点概率值能够在已经证明的历史数据内获取。
3)输出节点
通过坏味检测出一个二元的结果,那么贝叶斯的就是输出节点一个概率p,此概率p能够依据重要程度完成对类排序[11]。
4)当数据经过分割和验证后,应用贝叶斯网络对模型进行修正。条件概率表描述了实际臭味的产生[12]。因此,贝叶斯网络的结果通常比正则模型的结果更准确。
在决策过程中,决策与输入之间没有必然的联系,决策会因噪声而产生错误。利用历史数据的学习概率表,将噪声的影响降到最小。至此,实现代码坏味检测。
4 仿真证明
为了验证本文坏味检测算法的有效性,设准确率、召回率和度量值挖掘效果验证代码坏味检测程度。
准确率是指在程序所检测坏味时,真实的坏味比率。假设A是程序内所检测出的坏味集合数量,那么B就是程序内真正的坏味集合数量,那么准确率(Precision)的具体计算公式为

(16)
式中:|A|表示集合A内元素个数。通过将新旧程序进行对比,清除程序功能的更改,把获得的程序变化状况,对旧程序清除坏味。把此种实际情况整理分析,可以获得程序内真正的属于坏味集合B。
召回率是指全部坏味内被检测出比率。具体召回率(Recall)计算的公式为
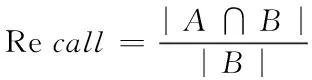
(17)
度量值是信息挖掘效果评价体系中确定最优路由路径的指标,可以有效测试决策过程中的贝叶斯网络对类排序结果,度量值最小则程序内实际的坏味个数挖掘效果最优。同时,代码坏味并不完全就是代码错误,编码正确并且可以实现全部预定功能程序内,代码坏味依旧存在,不过存在这些坏味会在一定程度上影响程序的整体质量,主要体现在程序的质量设计,因此利用度量值体现坏味代码模型定位效果即挖掘效果。
设需检测程序代码存在595个类,一共有3286个属性与8012个方法,程序代码的总行数会超出10万行。
4.1 准确率
当程序得到且统计每个实体到类调用的数据,同时计算文献[2]、文献[3]、文献[4]以及本文检测方法的数值。在实体到其它某类距离比本类距离大时,通过计算r(x,B)>1,那么就认为出现坏味代码。通过版本对比技术,程序内实际存在坏味具有300处。
四种方法具体检测结果数据统计,如图3所示。
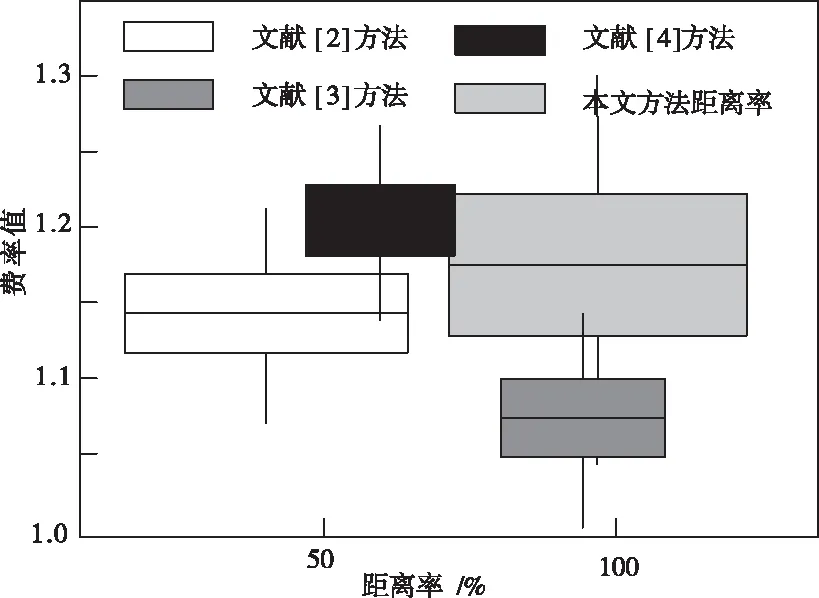
图3 不同方法坏味检测结果统计
如图3所示,其它方法所检测到的最多代码坏味具有290处,而本文方法检测到的坏味为299处。和本文方法所检测的坏味代码大致相同。
4.2 召回率
理想模型下,代码坏味只会在数据并行传输程序中表述一次,不存在单个重复的代码坏味现象,以此为背景,进行不同方法的代码坏味距离比检测结果对比,具体对比结果如表1所示。
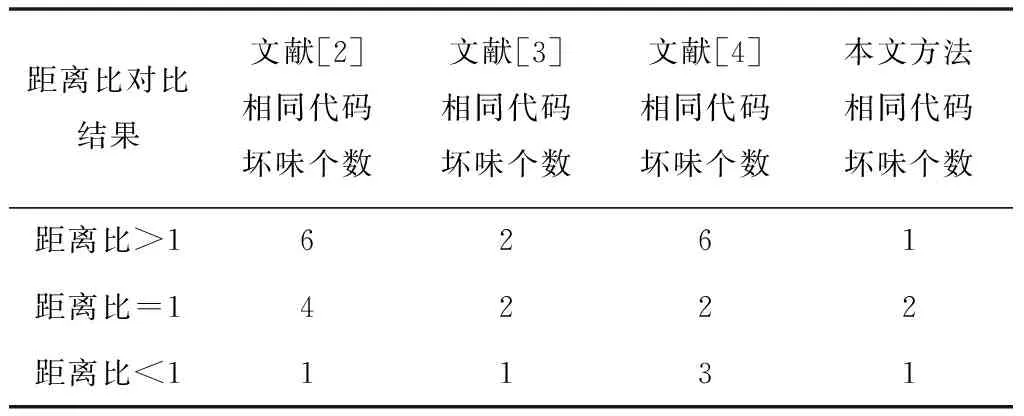
表1 不同方法的代码坏味相同代码坏味检测结果
通过表1可知,其它方法的代码坏味检测结果与本文方法的坏味检测所获得的结果对比下,最多有2种是相同的代码坏味。本文方法参与了距离率的计算后,致使权重的距离比要比1小,代码坏味检测为1。
4.3 度量值
不同方法的度量值对比结果如图4所示。
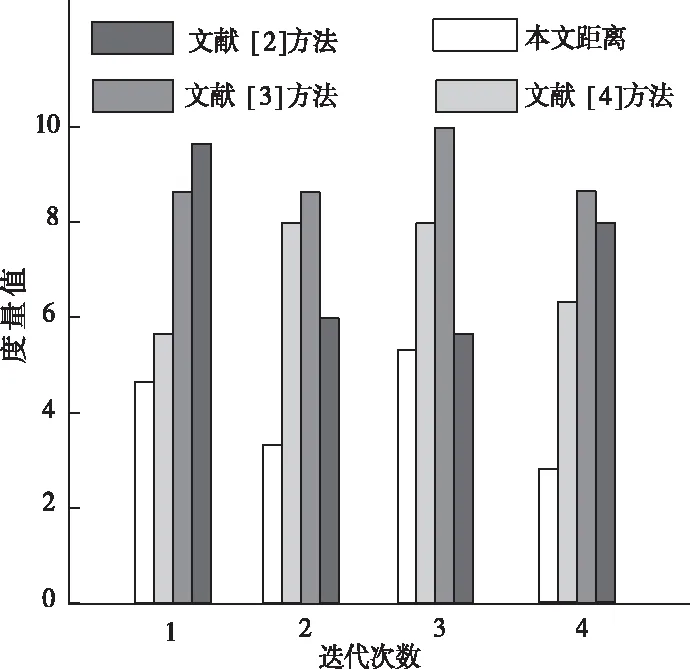
图4 不同方法的度量值对比结果
由图4可知,本文方法在度量值对比过程中,可以具有较低的度量值,即对坏味代码的定位路径更近,效率更高,说明具有较高的鲁棒性。
5 结束语
1)本文方法能够很好的检测出程序内的代码,并且和其它检测方法对比,本文方法检测结果准确率提升了1.9%,而召回率提升6.1%,本文方法的检测结果准确度要更高。
2)利用贝叶斯网络将最新的检测规则转化为概率模型,并从源代码中提取代码坏味度量,度量值可以使坏味代码的定位路径更近,总体应用效率更高。
3)由于程序内的代码坏味种类非常多,本文方法并不适用于所有的坏味代码检测,所谓未来本文需要进一步研究坏味代码特性,争取实现更优的坏味检测。
猜你喜欢
杭州电子科技大学学报(自然科学版)(2022年4期)2022-08-23
移动通信(2022年7期)2022-08-10
上海文化(文化研究)(2022年3期)2022-06-28
作文与考试·初中版(2019年15期)2019-04-28
江西教育B(2019年2期)2019-04-12
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
软件导刊(2018年1期)2018-02-01
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
科教导刊·电子版(2017年32期)2018-01-09
