
融合分割权重和注意制的CNN图像分类算法
2021-11-17 08:37黄鹤鸣张会云更藏措毛
计算机仿真 2021年6期
李 伟,黄鹤鸣,张会云,更藏措毛
(1. 青海师范大学计算机学院,青海 西宁 810008;2. 藏文信息处理教育部重点实验室,青海 西宁 810008)
1 引言
随着大容量存储设备的广泛使用和数字化技术的普及,出现了大规模的图像数据库。图像已成为人们获取信息的主要方式。从浩瀚的图像数据库中搜索图像,需要对数据库中的图像进行分析处理,前提是对这些海量图像进行分类。
近年来,随着大数据和硬件计算能力的发展,神经网络作为一种新兴的深度学习方法,在各个领域不断取得了突破性进展[1]。Yann Le Cun于1998年提出的卷积神经网络(Convolution Neural Network, CNN)[2]能更好地获取图像的空间和位置信息,有利于图像分类。Dave Steinkraus等人于2005年发现了图形处理器(Graphics Processing Unit, GPU)在机器学习(Machine Learning, ML)方面的独特优势[3],提出了基于GPU的高效CNN训练方法,大幅提高了CNN的运算能力。Alex Krizhevsky等人于2012年提出了AlexNet[4]网络,采用ReLU激活函数并使用GPU分组卷积方式进行并行训练。Christian Szegedy等人于2014年提出了GoogLeNet[5],在分类结果和运算效率上均取得了较大提升。Sergey Loffe等人于2015年将批标准化(Batch Normalization)[6]应用于神经网络,保证了网络中各层的输出分布基本稳定;同时,大幅降低了网络对初始参数的依赖,提升了网络性能。
CNN具有良好的扩展性和鲁棒性,但利用CNN进行图像分类时,会存在过拟合、梯度爆炸或梯度消失等问题。文献[4]使用Dropout技术有效缓解了网络过拟合问题。受图像自身特性的启发,提出了一种融合分割权重和Attention机制的CNN图像分类算法:基于分割权重的二次预训练方法,通过降低图像背景噪声的干扰,有效抑制了训练过程中出现的过拟合现象。在训练好的网络上,使用三种不同Attention类型的激活函数充分进行实验。结果表明:不同Attention类型的激活函数对网络模型的作用不尽相同,混合Attention的实验效果最优;同时,将其应用于标准图像库Corel-1000进行分类时,分类精确度有了较大提高。
2 融合分割权重和Attention机制的CNN图像分类算法
2.1 二次预训练方法
在神经网络的学习和训练过程中,过拟合是一个普遍存在的问题。过拟合指仅能拟合训练数据,但不能很好地拟合训练数据以外的数据,其原因是:①模型拥有大量参数、表现力强;②训练数据少。而神经网络学习的目标是提高网络泛化能力,即便是没有包含在训练数据里的未观测数据,也希望模型可以进行正确的识别。因此,在搭建复杂有效的网络模型时,寻找有效抑制过拟合的方法很重要。
受图像自身特性的启发,提出了一种基于分割权重的二次预训练方法,通过降低图像背景噪声的干扰,对训练过程中出现的过拟合现象起到一定程度的抑制作用。其具体方法是将图像I分割成4*4的16块,选取靠近中心点的4块作为图像的中心块,提取出原始图像I的中心块域Ω,剩余的块作为背景块B,如图1。具体图像分割后的效果图如图2。

图1 图像的中心块区域Ω

图2 图像分割前后的对比效果
基于图像分割权重的二次预训练方法有两种:①首先,使用图像中心块对网络进行预训练;其次,使用完整图像进行第二次预训练。②通过设定阈值减小图像的背景块像素值。使用减小后的背景块像素值和原始中心块像素值预训练神经网络,再使用完整图像对神经网络进行第二次预训练。
二次预训练方法减小背景块像素值的算法,用伪代码描述如下:
Begin
图像I分割成4*4的16块;
提取原始图像I的背景块域B;
将背景块像素值存于矩阵BG;
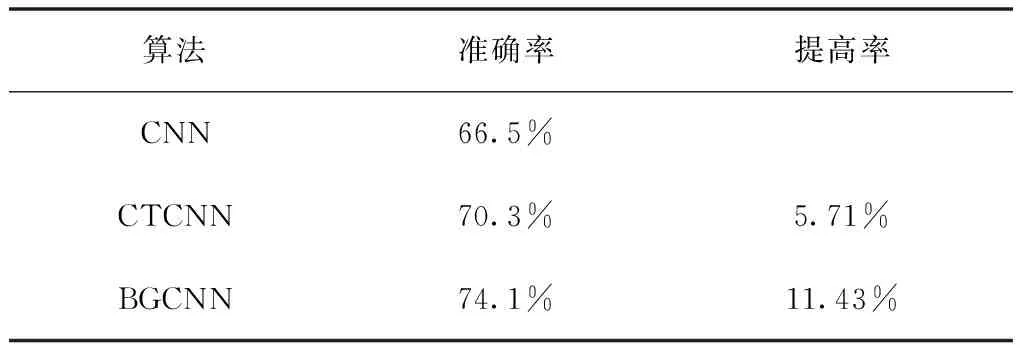
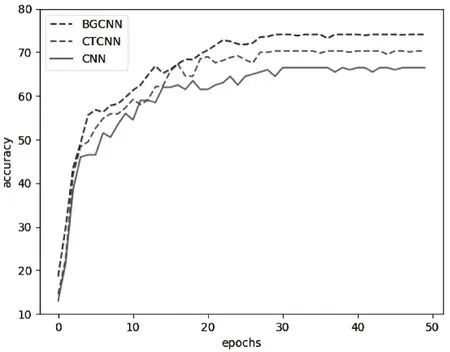
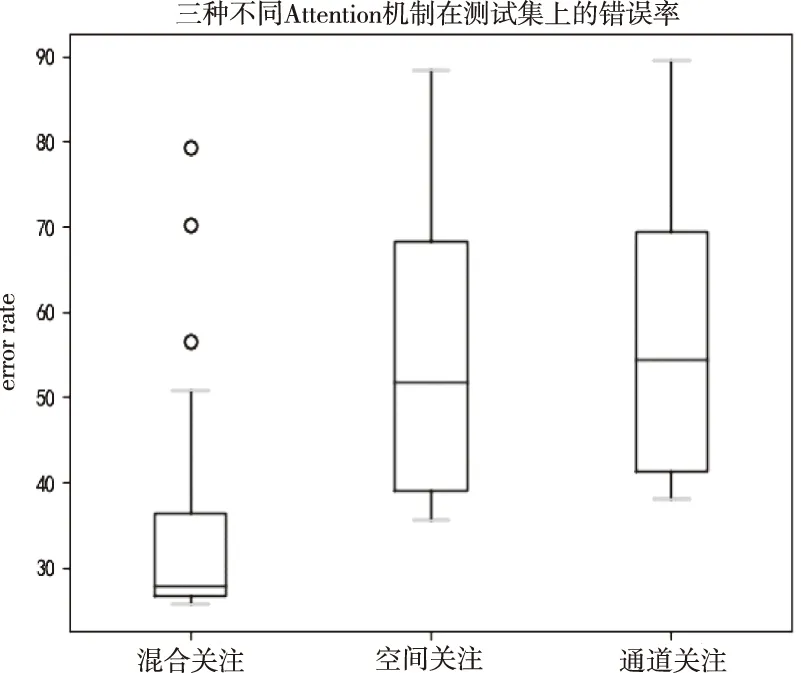
for(i=0;i for(j=0;j BG[i][j]=BG[i][j]*threshold value; end for end for End 仅获取一种类型的关注,如比例关注[7]或空间关注[8],需要通过权重共享或归范化对网络结构施加额外的约束。文献[9][10]研究了混合关注。混合关注在没有附加约束的情况下,通过改变不同的关注度,可以获得最佳的网络性能。文献[11]使用了Sigmoid混合关注、通道关注和空间关注三种类型的激活函数。混合关注f1是在没有施加额外约束的条件下,针对每一个通道和空间位置,使用激活函数Sigmoid。通道关注f2对所有通道内的每个空间位置的像素点执行L2标准化,达到移除空间信息的目的。空间关注f3的作用与通道关注f2相反,对每个通道的所有特征图进行标准化,移除通道信息仅保留空间信息。其计算公式如下方法 (1) (2) (3) 其中,i表示所有空间位置,c表示所有通道,meanc和stdc分别表示第c个通道的均值和标准差,xi表示第i个空间位置的特征向量。 由于Sigmoid为饱和非线性函数,而ReLU为非饱和非线性函数,所以ReLU比Sigmoid的训练速度快;同时,ReLU函数具有单侧抑制作用,使得网络具有稀疏激活性,能够更好地学习数据特征,所以ReLU还具有学习准确度高的特点。综上所述,使用了带有随机失活和数据增强的ReLU激活函数[10],其计算公式如下方法 (4) (5) (6) 实验使用的图像库是Corel公司提供的标准图像素材库Corel-1000。该库包含了人物、建筑物、公交车、花卉、动物等10类共1000幅图像,800张作为训练集,剩余200张作为测试集。为了方便网络读取,对图像库进行了预处理操作,将图像尺寸由原来的3*100*128压缩成3*48*48。 实验中使用二次预训练方法对图像库进行分类实验时,将图像填充为正方形后,将其等分为16块,取靠近中心点的4块作为中心块,剩余的块作为背景块。神经网络模型的Epoch设为50,每次迭代次数为8,批处理大小为100幅图像。第一层卷积有2304个神经单元,卷积核大小是3*3;中间卷积层有100个神经单元,卷积核大小是2*2,滤波器是40个。卷积步长设为1,填充设为0。池化层步长设置为2,池化窗口大小为2*2。最后,Softmax层有10个神经单元,表示将图像分为10类。 通过最小化损失函数来获得最优解。本研究使用交叉熵误差函数[12]作为损失函数,其表达式为 (7) 要使损失函数最优化,需要用到优化方法,实验采用Adam优化器[13]。结合AdaGrad和RMSProp两种优化算法的优点。综合考虑梯度的一阶矩估计(梯度的均值)和二阶矩估计(梯度的未中心化的方差),计算更新步长。 更新步骤可总结如下: 1)计算时刻t的梯度 gt=∇θJ(θt-1) (8) 2)计算梯度的指数移动平均数 mt=β1mt-1+(1-β1)gt (9) 其中,将m0初始化为0,系数β1为指数衰减率,控制权重分配(动量与当前梯度),默认为0.9。 3)计算梯度平方的指数移动平均数 (10) 其中,v0初始化为0,β2为指数衰减率,控制之前梯度平方的影响情况,默认为0.999。 4)对梯度均值mt进行偏差纠正 (11) 5)对梯度方差vt进行偏差纠正 (12) 6)更新参数,默认学习率α=0.00 (13) 其中,ε=10-8,避免除数为0。步长通过梯度均值和梯度均方根进行自适应调节。 本研究将基于中心块的二次预训练方法的卷积神经网络(Center-based Convolution Neural Network, CTCNN)和降低背景噪声的二次预训练方法的卷积神经网络(Background Convolution Neural Network, BGCNN)统称为TPCNN(Two pre-training Convolution Neural Network, TPCNN)。背景块阈值设为0.5时,CNN和TPCNN在测试集上的实验结果见表1。 表1 CNN和TPCNN在测试集的准确率比较 其中,分类算法的提高率为: (14) 从表1可以看出:由于CTCNN算法在第一次预训练时突出了图像中的目标物体,分类准确率有了一定提高;而BGCNN算法在第一次预训练时,不仅突出了图像中的目标物体,还降低了背景噪声的干扰,从而较大程度地提升了分类效果。CTCNN比CNN分类准确率提高了5.71%,BGCNN比CNN提高了11.43%。TPCNN抑制了训练过程中出现的过拟合现象,从而提高了分类准确率。 从图3中看到,BGCNN和CTCNN比CNN都有效提高了分类精度。并且,由于BGCNN降低了背景噪声的干扰,从而性能比CTCNN和CNN相对稳定。 图3 TPCNN和CNN在测试集的曲线精度对比图 使用BGCNN模型对图像库进行分类时,选取不同的背景块阈值会产生不同的实验效果。将背景块阈值分别设为0.3、0.5、0.7时,其在测试集上的实验结果见表2。 表2 不同背景块阈值的实验效果比较 当背景块阈值分别选取0.3、0.5、0.7时,准确率分别为71.7%、74.1%和72.9%。从准确率分析来看,当阈值是0.5时,实验效果最优。这是由于阈值为0.3时,过度降低了背景块区域对图像分类所产生的影响。其准确率接近于CTCNN的实验效果,原因在于选取的背景块像素值过小,对图像分类的影响不大。阈值为0.7时,选取了过高的背景块域值,容易造成过拟合,使实验结果未达到最优。而阈值为0.5时,选取了恰当的背景块域值,实验性能最优。 混合关注分别是Sigmoid激活函数和ReLU激活函数时,BGCNN神经网络模型在测试集上的实验效果见表3。 表3 两种不同混合关注的实验效果比较 通过实验看出,与Sigmoid函数相比,ReLU函数能够更好地学习数据特征,错误率更低。 通过图4的曲线图可以看出,与Sigmoid函数相比,ReLU函数还能够更快地学习数据特征,不但错误率更低且收敛速度也较快。 图4 Sigmoid和ReLU函数在测试集上的错误率 当BGCNN模型第一个卷积层使用三种不同Attention类型的激活函数进行实验时,在测试集上得到的实验结果见表4和箱线图5。 表4 三种不同Attention机制实验效果 图5 三种不同Attention机制在测试集上的错误率 表4可以看出:通道关注和空间关注,仅关注了一种类型,分别去除了空间位置信息和通道信息,与混合关注相比,实验结果数据不够理想;而混合关注同时考虑了空间位置和通道信息,其性能最优。 从图5的箱线图中,可以观察到,混合关注的最大、最小和中值错误率均小于空间关注和通道关注。此外,混合关注的下四分位数均小于其它两种关注的上四分位数。因此,混合关注不仅有较低的错误率,而且性能也相对稳定。相比于通道关注,空间关注性能略有提高。 当BGCNN模型两个卷积层均使用三种Attention机制时,在测试集上得到的实验结果见表5。 表5 三种不同Attention机制实验效果 可以看出:当两层卷积都使用通道关注或空间关注时,实验结果差距明显。表4空间关注比通道关注的分类错误率低;而表5中当两层卷积仅使用单一关注时,相比于通道关注,f1(xi,c)空间关注不但未达到表4中的性能,反而错误率迅速上升。 本文提出了一种基于分割权重的二次预训练方法,通过降低图像背景噪声的干扰,抑制了CNN图像分类训练过程中出现的过拟合现象;同时,使用三种不同Attention类型的激活函数,在二次预训练方法上充分进行验证。实验结果表明,二次预训练方法对图像分类效果有较大程度的提升;同时,加入混合Attention的实验效果最优。在未来的研究工作中,逐渐尝试将优化算法用于参数优化,使模型性能达到更优。2.2 Attention机制

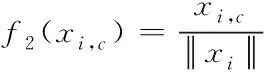
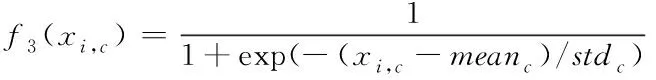
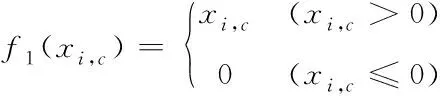
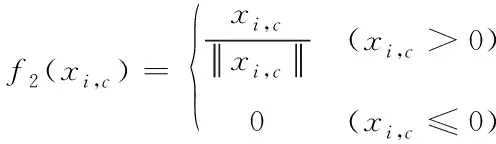
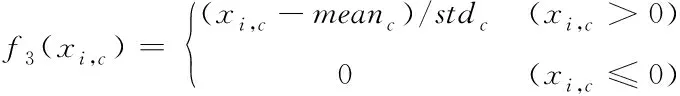
3 实验结果及分析
3.1 实验参数与图像库
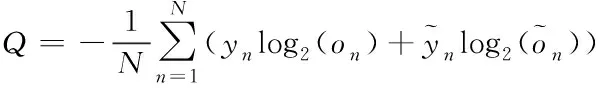
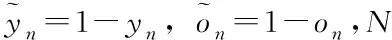
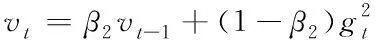
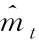

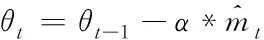
3.2 实验结果
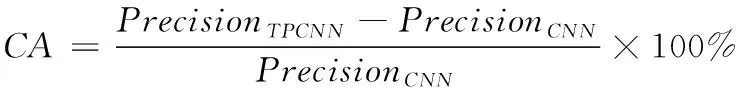





4 总结
猜你喜欢
农业工程学报(2022年12期)2022-09-09现代电子技术(2022年11期)2022-06-14计算技术与自动化(2022年1期)2022-04-15建材发展导向(2021年19期)2021-12-06北京航空航天大学学报(2021年9期)2021-11-02北京航空航天大学学报(2021年9期)2021-11-02现代计算机(2021年10期)2021-05-28华东师范大学学报(自然科学版)(2019年3期)2019-06-24福建基础教育研究(2019年3期)2019-05-28西部资源(2018年1期)2018-11-01
