
基于并行Apriori的铁路物流配送FPMA
2021-11-17 08:37张正义
计算机仿真 2021年6期
张正义,崔 健
(1. 西安航空学院,陕西西安 710077;2. 长安大学,陕西西安 710064)
1 引言
在当下的物流领域,针对铁路物流配送频繁路径数据的挖掘分析通常采用RFID、GPS等信息技术,对于货物运输的路径规律和物流配送的优化有十分重要的意义[1-2]。目前大多采用关联规则算法进行频繁项集的挖掘分析,但随着物流行业的快速发展,传统的数据挖掘算法面对类型多且数据量庞大的现实,已经很难适应当前的物流配送环境[3-4]。因此,很多专业提出利用处理平台完成传统算法的并行化方案,唐兵等研究的基于MPI和OpenMP混合编程的非负矩阵分解并行算法,将基于MPI的消息传递模型的优势与基于OpenMP的共享存储模型的优势相结合的方法,提高了运行的加速比和计算效率[5];彭自然等研究的一种在多核嵌入式平台上实现FFT的快速并行算法,将静态多项式奇偶项的不同特点代入数据计算中,以此提高并行算法运行速度[6]。虽然以上两种并行算法都能通过算法并行化提高计算机对庞大数据的处理速度,同时结合物流网络对频繁路径挖掘的特点,一定程度解决目前物流配送频繁路径挖掘等问题。
但是,在算法运行过程中的速度和效率还达不到理想的效果,为了提升并行算法的计算速度,提高运行效率和频繁径路挖掘的精准度,保证物流管理者能清晰地了解货物流向,本文提出的基于并行Apriori的铁路物流配送频繁路径挖掘算法,综合利用Fuzzy c-means算法和改进Apriori算法实现铁路物流配送频繁路径的有效挖掘,进而帮助物流管理者实时了解物流配送的状况,对物流环节进行优化,有效降低物流配送运输成本。
2 基于并行Apriori的铁路物流配送频繁路径挖掘算法
2.1 基于Fuzz c-means的Apriori并行算法
对数据集中的频繁项集利用逐层搜索的迭代方式进行分析的算法为Apriori算法,具有便捷、易实现等优势。Apriori算法要求对数据集进行多次扫描,在生成每个频繁候选集的过程中,必须对该数据集进行一次全面扫描,如果生成的频繁项集长度为S,则扫描次数通常为S+1次。当计算机处理较大数据集时,当计算机内存容量有限时,系统I/O会出现负载过大的情况,从而导致Apriori算法的运行效率降低,不利于频繁模式挖掘[7]。
Apriori算法的并行化通过编辑模型MapReduce实现,具备提高Apriori算法运行效率的作用。Apriori算法可挖掘分析整体数据集中的频繁模式,就物流配送来说,某些局部区域存在偏少的路径数据,致使该区域为频繁路径的序列,因其不能满足最小支持度而在整体频繁路径挖掘分析过程中被忽略[8]。基于此,本文将基于Fuzzy c-means的Apriori并行算法建立在Hadoop数据处理平台之上,利用Fuzzy c-means算法对数据集进行聚类分析,根据内部相似度将数据集划分出多类具有较高相似度的数据簇,利用Apriori算法对所包含的频繁模式进行分类,然后对合并后的数据进行分类分析,得到每个区域的频繁路径序列[9]。利用Hadoop中的子项目 MapReduce和Mahout,利用大数据的处理特性,实现算法的并行性,以此提升算法的处理效率和适应性,具体算法流程图如图1所示。
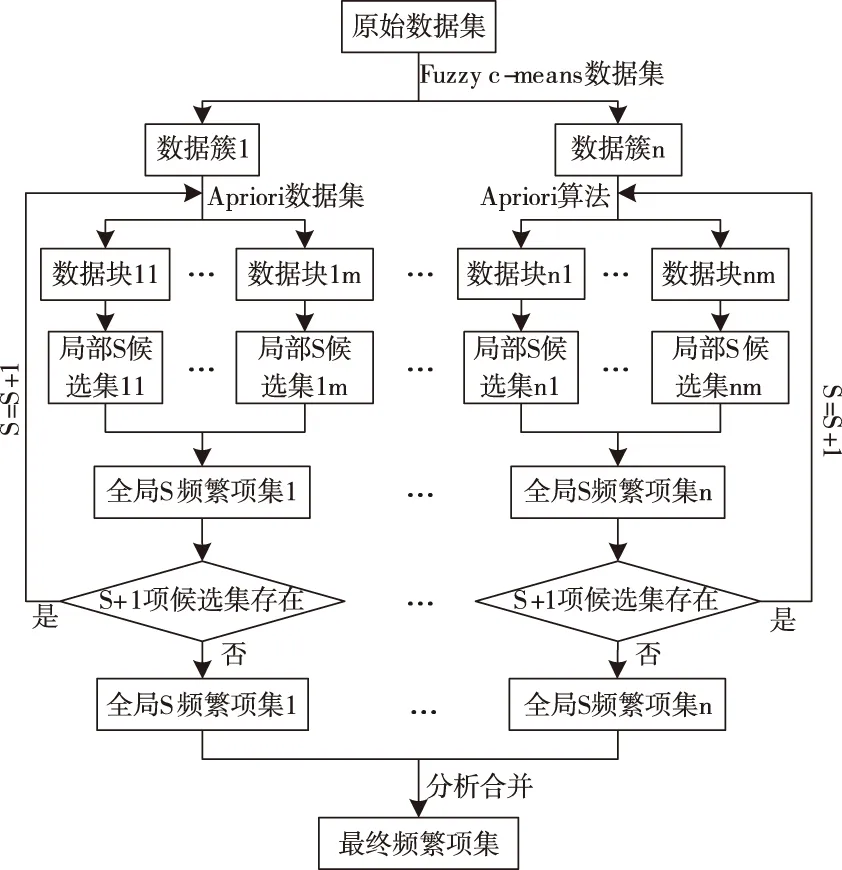
图1 基于Fuzzy c-means的Apriori并行算法流程图
通过Apriori并行算法得到频繁模式后,各数据类的结果经过合并分析得到的物流频繁路径结果,该结果通过采用物流网络中频繁路径的某些性质获取,具体性质主要分三种,分别为:
1)运输货物时,没有重复的移动路径,因此在最终的路径数据中,回路不可能出现。
2)如果在两条频繁路径中存在一条为另一条子路径时,该子路径应被舍去。例:频繁路径K1=〈a1,a2,…,ae〉和频繁路径K2=〈b1,b2,…,bf〉,如果整数e和f满足f>e,且a1=b1,a2=b2,…,ae=bf,则K2的子路径为K1,合并K1、K2,在最终结果中只显示频繁路径K2。
3)分析合并是根据物流网络特有的特点进行,从两方面表现,即:①网络中任意相邻的两点在路径序列中都是相邻的,假定甲点和丙点之间不相邻,需要通过乙点或丁点连接,则在最终频繁路径结果中就不能出现甲→丙,只允许出现甲→乙→丙或者甲→丁→丙。②如果一条频繁路径舍去第一个节点的子路径为另一条频繁路径的S-1序列,设频繁路径甲→乙→丙和乙→丙→丁,那么就能够合并成甲→乙→丙→丁。基于上述物流路径性质,分析了合并后的频繁路径序列,从而实现最终的物流频繁路径序列。
2.2 Fuzzy c-means算法及并行化实现
Fuzzy c-means算法是一种其具有明确的数学理论依据和可行性高的常用聚类算法,Fuzzy c-means聚类算法需要提前预设一些参数,如聚类类别参数和终止条件阈值参数等,利用聚类中心与距离度量数据的相似度对聚类中心进行持续更新,将原始数据集划分为多个数据簇,数据簇之间秉承着对内相似度高,对外相似度低的原则[10]。Fuzzy c-means算法采用模糊理论的观点,利用数据对每个数据簇的归属程度体现各数据簇的归属概率,其思想表示为:
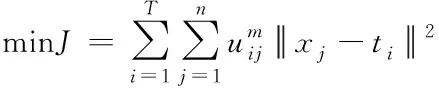
(1)
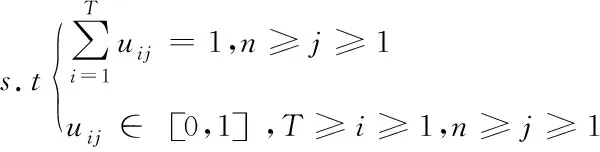
(2)
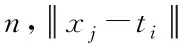
1)对算法进行初始化,确定聚类数据簇T,n≥T≥2,n表示数据总量,初始化隶属度矩阵可描述为U=[uij],以U表示,初始化聚类中心可描述为T=[ti],以T表示。
2)对聚类中心向量T进行更新,公式为

(3)
3)对隶属度矩阵U(s),U(s+1)进行更新,公式为
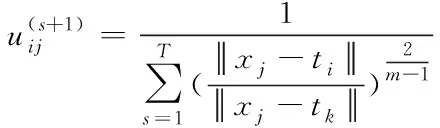
(4)

Fuzzy c-means算法的并行化完成是利用Hadoop平台的Mabout实现的,在算法的并行化过程由循环部分和循环体部分组成。
循环部分:根据预设阈值进行准则函数的判断,当准则函数满足预设阈值时,循环结束,反之则继续执行循环。
循环体部分:主要作用是实现算法的计算过程,算法运行效率利用Fuzzy c-means Combiner任务得以提升。
初始聚类中心点文件和输入数据文件为Fuzzy c-means算法的核心输入,初始中心点为设置参数在原始数据集中自动提取的n个值。经过对上次中心点和新输入数据的计算,获得新的聚类中心,并将其保存到新的中心点文件路径;Fuzzyc-means Mapper数据 setup函数读取,采用预设方法对数据根据就近原则进行划分到聚类中心簇中;根据Mapper任务的输出结果,Fuzzy c-means Combiner进行整合后得到最终输出。
2.3 改进Apriori算法及并行化实现
改进的Apriori算法的原理是通过数组储存的数据降低数据库的扫描次数,根据表1的事务数据库详细介绍算法获取频繁项集顺序。

表1 事务数据库
1)对事务数据库进行遍历后储存于数组
TID为项目集的唯一标识符,根据标识符把遍历后的数据存储于数组X中,同一标识符中不一样单项间隔符号为“,”,不同的标识符间隔符号为“;”,则X[ ]={I1,I2;I3,I4;I2,I5,I6}。
2)遍历数组X中产生的频繁项集
参照预设的最小支持度产生的频繁多种项集进行数组X遍历,在数组{X1,X2,…,Xn}内存储产生的项集及相应的支持度,其中n用来描述项目集的长度。项目集与支持度之间的分割符号为“、”,不同的项集之间分隔符号为“;”,根据表1的事务数据库设最小支持度为0.2后产生频繁项集,即:
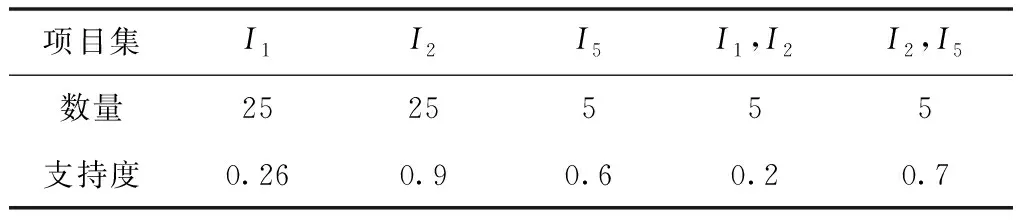
表2 频繁项集
把频繁项集存储进数组中,即X1[ ]={I1、0.26;I2、0.9;I5、0.6}。
3)产生备选频繁相集
备选k相集通过数组X(k-1)与其自己连接来生成,将生成的备选相集根据最小支持度生成频繁k相集,对比Xk数组中相集,若数组中无相集,则根据产生的顺序依次储存于Xk数组内。
改进Apriori算法的优势在于:①通过对数据库的一次性扫描有效降低系统I/O的负载,提升算法的运行效果;②在数组中储存相应的频繁集和支持度方便后续强关联规则快速产生;③强关联规格可通过数组中依次储存的频繁相集顺序进行判定,根据判定结果能够轻易分辨是由候选频繁项集产生还是由原数据产生,便于在应用中进行针对性的选择。
MapReduce模型最大的优势为wed数据的词频挖掘,改进Apriori算法完全满足其性质,基于MapReduce的改进Apriori并行算法流程图如图2所示。

图2 改进Apriori并行算法流程图
3 实验结果与分析
本文利用Hadoop数据处理平台进行实验,采用的服务器为联想System x3650 M5(5462I05),开发工具为Qt Design Studio 2.0版本,通过Java和HDFS完成语言编码和数据存储。为验证本文算法的优越性,分别采用本文算法与文献[5]基于MPI和OpenMP混合编程的非负矩阵分解并行算法和文献[6]一种在多核嵌入式平台上实现FFT的快速并行算法进行性能比较。实验中所需进行挖掘实验的数据库为包含53647条记录和23614个事务集的微软实例数据库Adventure Works-DW。事务标识符为OrderNumber,事务项为Model。
在不同支持度,相同事务数的条件下进行获取频繁相集需要的时间对比,事务数为5000,对比结果如图3所示。
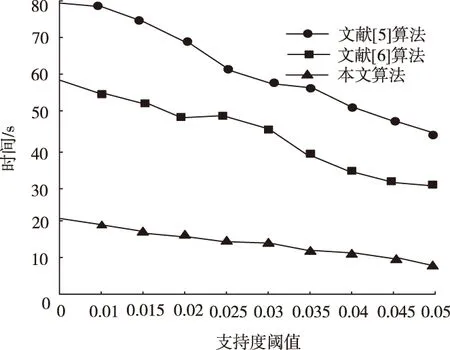
图3 不同支持度条件下获取频繁项集所需时间对比
由图3可知,本文算法在不同支持度情况下获取频繁项集所需时间最少、波动最小,说明本文算法在运行过程中速度更快,稳定性更高。
在相同支持度,不同事务数的条件下进行获取频繁相集需要的时间对比,支持度为0.05。对比结果如图4所示。
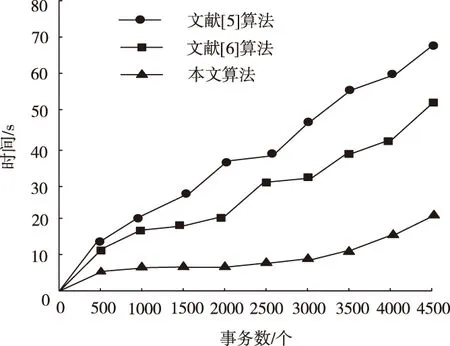
图4 不用事务数条件下获取频繁项集所需时间对比
由图4可知,在支持度相同,事务数不同的条件下,随着事务数的逐渐增加,三种算法的执行时间都在随之增加,但是本文算法从起始速度和执行时间增长幅度明显较小,表明本文算法可有效提高关联规则挖掘的运行效率。
在相同支持度条件下进行强关联规则的对比实验,设最小支持度为0.1,遍历数据库中所有记录,结果如表3所示。

表3 强关联规则对比结果统计表
由表3可知,在相同支持度条件下,本文算法能够以最短的时间快速找到所需求的强关联规则,且本文算法找出的强关联规则和频繁项集个数最少,对比两种并行算法,表明文献[5]算法比本文算法多找了76个冗余频繁项集,文献[6]算法比本文算法多找了47个冗余频繁项集,实验验证,本文算法挖掘频繁项集的效率更好。
为了更详细地验证本文算法在物流频繁路径挖掘中的有效性,基于相同条件下的运行结果详细测试,设最小支持度为0.75,频繁序列中的项目数为5,数据集不变,运行结果如表4到表6所示。
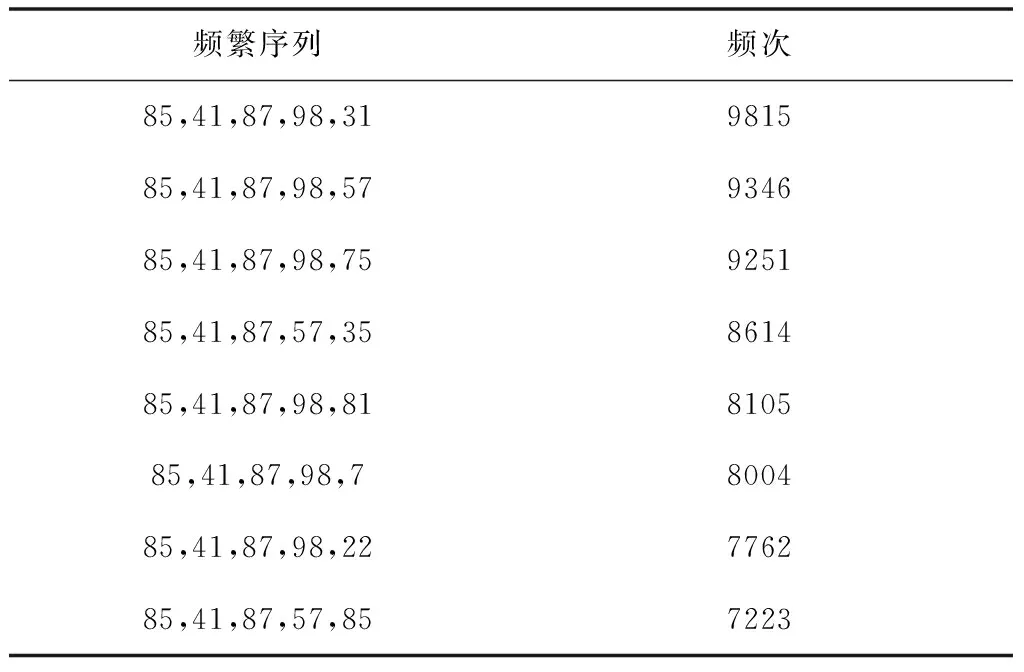
表4 文献[5]算法运行结果统计表

表5 文献[6]算法运行结果统计表
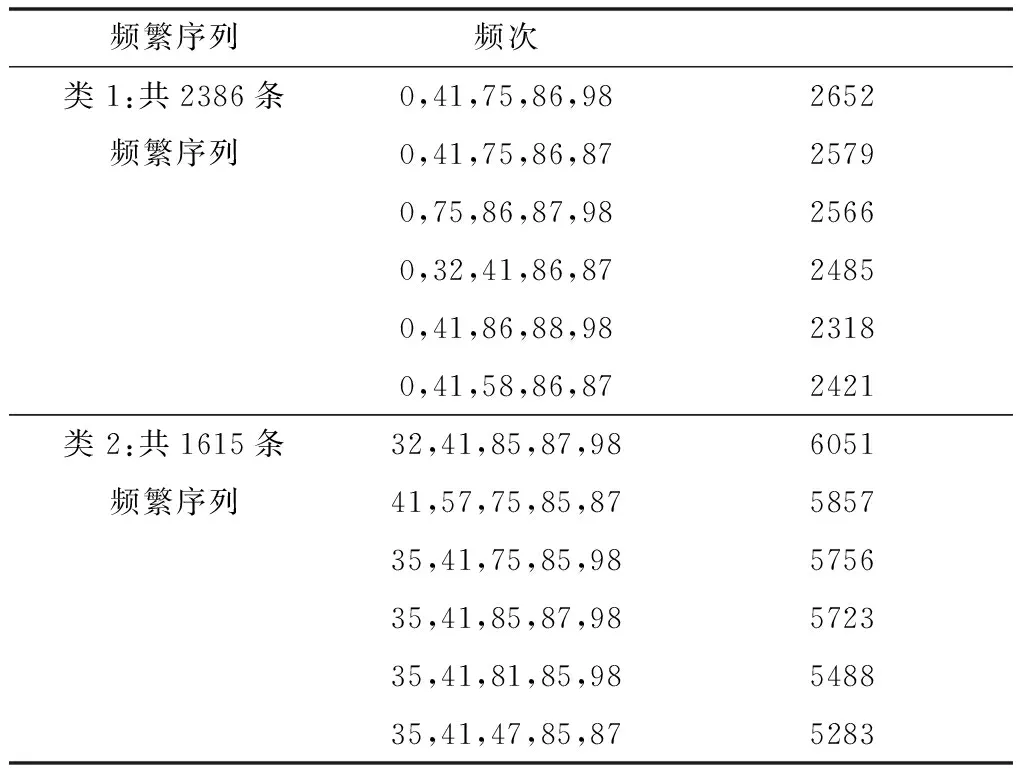
表6 本文算法运行结果统计表
由表4到表6可知,文献[5]算法获取的频繁序列数为8条,各频繁序列在数据集中的频次为7200-9900;文献[6]算法获取的频繁序列数为14条,各频繁序列在数据集中的频次为5100-9800,而本文算法类1和类2的频繁序列总和为4001条,各频繁序列在数据集中的频次为2600-5300,并且本文算法类1中的频次与两种对比并行算法存在着较大的差距,表明文献[5]和文献[6]的算法中不涵盖数据类1的结果,可以理解在算法运行过程中,如果某区域的物流配送路径在全局数据集中分量很小,那么两种对比的并行算法就很容易忽略掉该区域在频繁径路的挖掘,导致该区域的有物流路径在最后的结果中不能得到体现,而在物流配送的实际应用中,所有物流路径都非常重要,因此,本文算法在频繁径路的挖掘中的精确度更高,也更具备实际应用价值。
4 结论
本文基于Fuzzc-means的Apriori并行算法实现铁路物流配送频繁路径挖掘,利用Hadoop数据处理平台和数据挖掘技术进行物流配送环节中产生的庞大数据信息的挖掘分析,为了提升数据处理速度、运行效率和精准度,对Fuzzy c-means算法与改进Apriori算法进行并行化,实现对铁路物流配送中庞大数据的挖掘分析,满足当前对物流路径频繁模式的挖掘需求。在后续的研究中,需要进一步对物流频繁路径进入配送中心等决策性问题展开研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
电脑报(2022年13期)2022-04-12
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
电脑报(2020年24期)2020-07-15
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电脑爱好者(2017年22期)2017-12-04
科学家(2016年13期)2017-09-29
企业技术开发·中旬刊(2016年10期)2016-11-12
中国市场(2016年36期)2016-10-19
