
组合多任务与迁移学习的故事发展预测
2021-11-16 02:47冯一铂
安徽大学学报(自然科学版) 2021年6期
方 红,冯一铂,张 澜
(上海第二工业大学 文理学部,上海 201209)
随着科技进步、信息技术及人工智能技术的发展,愈加庞大的数据需要计算机代替人处理.故事(stories)这种由文本构成的海量数据,记录着人类发展和社会生活,因此发掘大量故事中潜在的语义关系并推断故事发展方向是一个全新且充满挑战的任务.
故事发展预测又被称为故事完形填空测试(story cloze test, 简称SCT),它与自然语言中的知识问答相似,属于机器阅读理解(machine reading comprehension, 简称MRC)的一种.SCT任务于2016年被提出,该任务的数据集——ROC stories全部采样于生活事件,内含6句话及一个正确选项的标签.SCT任务要求从最后2句话中选择出由前4句话组成的不完整的故事的正确结局.由于数据集来源广泛,需要借助多种自然语言处理(natural language processing,简称NLP)技术来解决问题.图1为一个SCT任务中的典型实例.
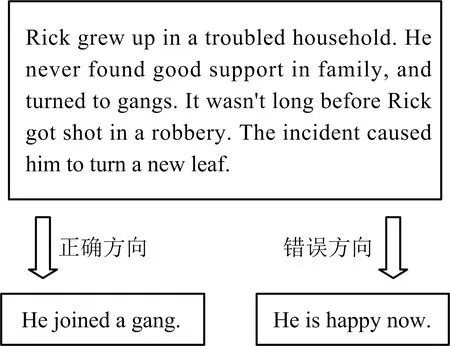
图1 SCT典型实例
近年基于深度学习的方法在SCT任务研究中应用广泛.Huang等将故事主体与发展结局投影到同一个向量空间中,计算两者距离.Wang等以生成错误选项为策略,提出了一种条件生成式对抗网络.Cai等利用Bi-LSTM(bi-directional long short-term memory)神经网络进行句子序列和词序列的编码,计算故事主体与不同发展方向的相似度.上述研究本质上皆通过文本间余弦相似度预测故事发展方向,缺乏对故事语义的理解,预测精度较低.而Chaturvedi等和Li等利用神经网络,创新性地组合情感和故事发展逻辑等多个语义特征,更好地挖掘上下文中的信息,使预测精度有所提升.但随着自然语言的发展,研究发现神经网络模型能够提供的表征能力有限,而语言模型成功解决了这个问题.GPT(generative pre-training)和BERT(bidirectional encoder representations from transformers)通过在开放域的无标签语料库上使用多层transformer预先训练语言模型,再进行微调操作,更好地理解故事上下文含义.受文献[10-11]的启发,Li等针对语言模型训练前获得的知识不足以学习到每一个目标任务的不足,提出trans-BERT模型.通过上述研究可以发现,现阶段方法存在两个主要问题:①神经网络模型无法在大量无标签的语料库上获取常识,对文本理解的能力有限,无法深入挖掘文本的有效信息.②除Chaturvedi等和Li等组合多个任务结构,其他方法在处理SCT任务时,模型的关注点皆基于挖掘单个语义信息的任务,导致模型泛化性能弱,无法融合不同的语义信息.
BERT和GPT等语言模型的提出,有效解决了第一个问题.针对第二个问题,论文在Li等提出BERT的信息迁移的基础上,构建组合多任务与迁移学习模型(trans-multi-task of incorporating structured,简称TMTIS).该模型有效解决了上述缺点:①它利用语言模型与多任务学习(multi-task learning,简称MTL)及多任务深度神经网络的组合,强化机器对文本的理解能力,同时关注多个任务,提升模型整体泛化能力,使学习到的信息在任务之间具有普遍性.②通过迁移学习,迁移多个源任务中信息,在目标任务中学习,挖掘多个语义信息,使机器能更好理解文本.③将多个语义信息融合,实现各语义信息之间的相互补充.
与Li等论文结果进行比较,TMTIS在精度上更优,达到93.5%,提升了2.9%.通过消融实验验证TMTIS中不同特定任务对语义信息获取的贡献情况.
1 相关工作
BERT模型由于其采用双向transformer编码器,克服了传统词嵌入模型对不同任务定义不同网络结构的缺点.在文本分类、文本相似度计算等领域已经得到广泛应用,并在Devlin等和Li等的研究中验证了BERT模型有效提升SCT任务的预测精度.MTL通过正则化,使共享参数在一定程度上弱化了单个网络能力,防止模型过拟合,对于模型泛化能力的提升有显著效果,并在杨荣钦的研究中验证了MTL有助于机器对文本的理解.由于许多 NLP 任务具有共享语言的常识、任务之间可以相互学习等特点,迁移学习能从已学习的相关源任务中迁移信息来改善目标任务,提升模型在目标任务上的性能.王禹潼将迁移学习的思想与注意力机制相结合,解决MRC问题.论文提出的新方法中采用由BERT模型与MTL相结合的MT-DNN(multi-task deep neural networks)模型,其通过迁移学习,将特殊任务中的信息迁移至SCT任务上,以提升新模型对文本的理解能力.
1.1 BERT模型
随着语言模型研究深入,从ELMo(embeddings from language models)到GPT再到BERT,皆利用大量未标记的数据训练而成,不同的是前者使用双向LSTM结构,后两者则使用transformer结构.由于GPT是单向transformer结构的语言模型,仅能考虑文本单侧信息,而BERT依赖双向transformer,在处理文本时能考虑文本左右两侧的上下文信息,对文本理解能力更强.BERT模型吸取了自编码器(auto-encoder)、词编码模型(word2vec)等无监督模型的设计思想,又结合所要捕获的无序关系和句与句关系等信息的特点,提出了对于transformer全新的无监督目标函数.因此越来越多NLP的下游任务采用BERT处理.
为实现在开放域语料库上进行无监督训练,BERT提出了两个新的预训练任务:掩码语言模型(masked language,简称ML)和后句预测(next sentence prediction,简称NSP).BERT处理任务过程如图2所示,其核心基于图2中编码层,通过双向transformer编码器组合更多信息.输入的是一个单词序列(可以是一个句子,也可以是两个句子连接在一起的序列):首先通过嵌入层将每个句子的单词标记类别、位置特征、段特征表示为嵌入向量序列;再经由编码层中每个transformer的自注意力机制,捕获单词的上下文信息,生成一系列上下文嵌入,作为输出嵌入;最后通过使用最小的特定于任务的参数进行微调,将其应用于每个下游任务.
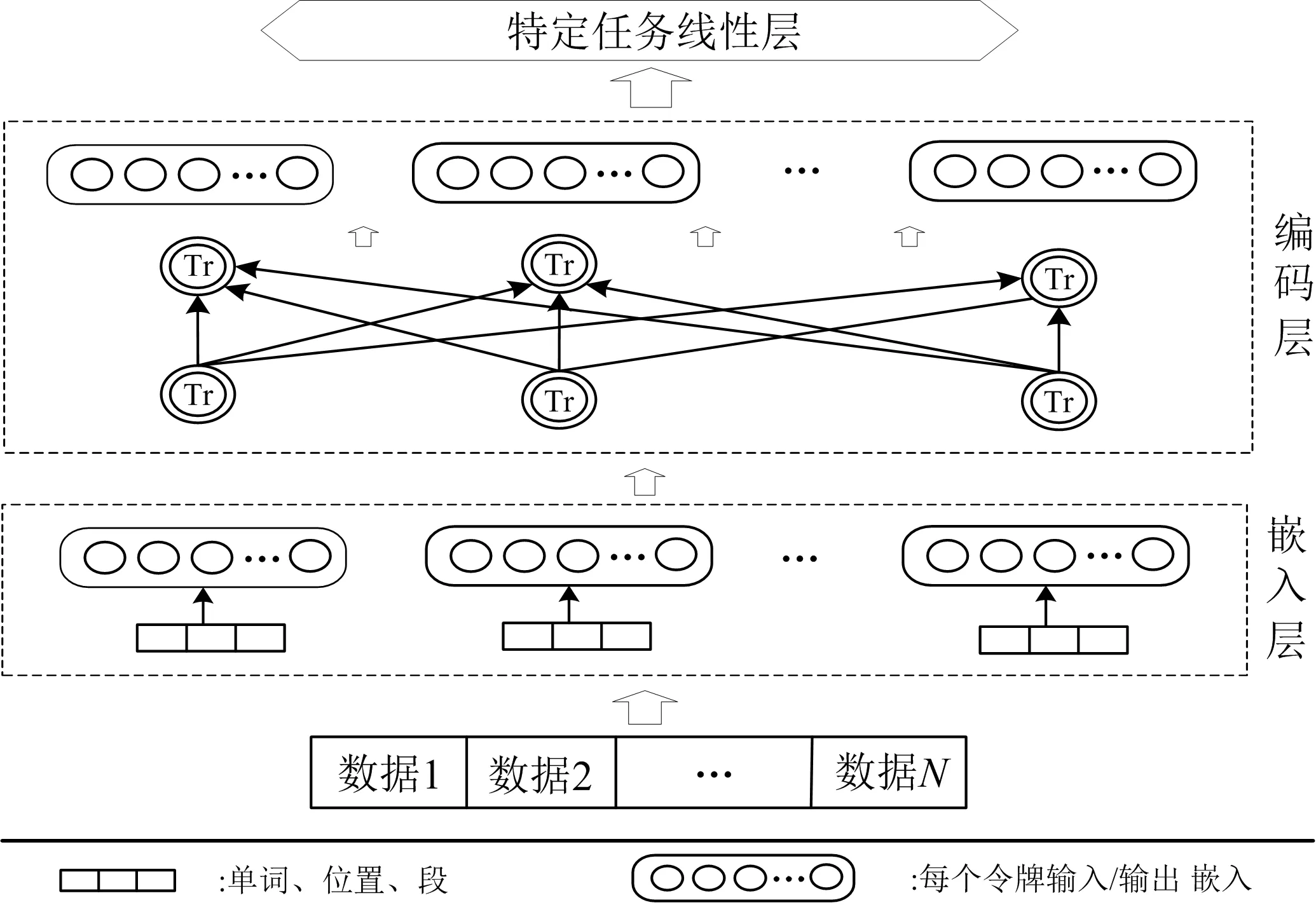
图2 BERT模型
1.2 MTL
MTL包括soft参数共享和hard参数共享.在共享soft参数时,各任务有单独的参数和模型,通过正则化模型之间的参数距离,鼓励参数相似化.共享hard参数是基于神经网络的MTL最常用的方法.实际中,隐藏层在所有特定任务之间共享,并保留任务的输出层.
MTL的共享hard参数同时学习多个任务,模型同时捕获多个任务的同一参数表示,极大降低了模型过拟合的风险,提高模型整体的泛化能力,故论文模型中将采用hard参数共享,结构如图3所示.
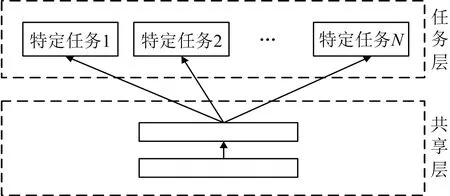
图3 MTL的hard参数共享
1.3 迁移学习
迁移学习是迁移源任务中信息,并在目标任务中学习该信息的过程.迁移学习分为基于特征与基于共享参数两种方法.基于特征的迁移学习关注的是源领域与目标领域之间共同的特征表示,利用特征进行信息迁移.基于共享参数的迁移学习是找到源数据和目标数据的空间模型之间的共同参数或者先验分布,以此迁移信息.
Phang等和Li等在研究中利用基于共享参数的迁移学习,通过实验验证:当源任务和目标任务在语义上相互关联,即两个任务拥有共享的信息时,源任务可以被用作迁移.故论文模型中采用基于共享参数实现迁移学习.
2 TMTIS模型
论文提出组合多任务与迁移学习模型,解决了神经网络理解文本能力有限以及传统语言模型仅能通过单个语义理解文本的不足.新模型结构如图4所示,该模型一共包含4个部分:共享层、特定任务层、迁移层以及组合层.整个模型可以看作一个分类器,用于选择最合适的故事发展方向.

图4 TMTIS模型
针对神经网络在理解文本能力有限的不足,新模型前两层组合语言模型和MTL构成MT-DNN,其中第一层为所有特定任务共享的语言模型;第二层基于hard参数共享的MTL,通过微调得到特定任务输出,挖掘NLP下游任务中语义信息供迁移层学习;第三层利用基于共享参数的迁移学习,将其上一层任务中的语义信息传递至SCT任务;第四层融合SCT中多种语义信息,解决以往模型仅能从单个语义信息理解文本的不足,并预测出故事的发展方向.
2.1 共享层与特定任务层
模型中的共享层以BERT模型为基础,该模型基于庞大的数据训练而成,解决了神经网络模型无法通过大型语料库学习常识知识的问题,提升了模型对文本的理解能力.该层将数据(一个句子或一对句子)输入嵌入层,首先表示为一个嵌入向量序列,每个向量对应一个单词.编码层的transformer捕获每个单词的上下文信息,并生成共享的上下文嵌入向量传入下一层.
在共享层的基础上设立特定任务层,多个特定任务共享BERT模型,使模型能同时捕获多个任务的同一参数表示,极大降低了模型过拟合的风险,提高模型整体的泛化能力.特定任务层是通过添加线性全连接层,并在训练过程中利用下游任务数据微调BERT的权重,以适应当前的任务.现阶段这些下游任务主要包括文本分类、文本相似度评价、相关性排序等,其中文本分类又分为单句文本分类和成对文本分类.
TMTIS模型与以往BERT模型不同的是,其利用MTL的hard参数共享,多个任务共享相同的语言模型,并在共享层的基础上使用基于小批量的随机梯度下降SGD(stochastic gradient descent)来微调所有共享层和特定任务层的参数,以此提高模型的泛化性能.
2.2 迁移层与组合层
迁移层通过共享参数的迁移学习,将上一层不同特定任务学习到的语义信息迁移至目标任务SCT上.操作过程与微调操作相同.下列公式表示不同语义信息迁移至SCT任务后,得到的条件概率为
P
(y
|x
,x
,…,x
,e
)=softmax(W
·K
),i
∈(1,2),(1)
其中:e
为两个故事发展方向;y
∈(0,1)为是否正确的标签;x
,x
,…,x
为不完整故事的主体;T
为不同的特定任务;W
为学习到的参数;K
为学习到之前特定任务语义信息的向量.组合层融合SCT任务学习到不同特定任务的语义信息,并预测故事发展方向.分别计算各向量K
与其他向量的总余弦相似度,并将其连接成向量h.
h
=sum(cos_sim(K
,K
)),m
,n
∈T
,m
≠n
,(2)
H
=softmax(W
·h
+b
),(3)
其中:W
和b
为线性层中的参数,H
为学习到的多个特定任务语义信息的不同条件概率的权重.利用向量H
组合多个条件概率得到TMTIS的最终预测结果P
(y
|x
,x
,…,x
,e
)=softmax(sum(H
⊙[K
;K
;…;K
])),i
∈(1,2).(4)
3 实 验
鉴于迁移学习基于源任务和目标任务在语义上相互关联的准则.考虑到SCT任务的数据ROC stories讲述现实故事,文本之间必然存在包含语义推理关系、情感极性关系、事件时序的发展关系.因此,为能挖掘故事中多种潜在的语义关系,实验在特定任务层设定自然语言推理(natural language inference,简称NLI)、情感分类(sentiment classification,简称SC)、行为预测(next action predict,简称NAP)、文本语义相似度(text similarity,简称TS)4个特定任务,供目标任务SCT学习不同的语义信息.在实验最后,设立消融实验展示不同语义信息对于预测故事发展方向的贡献情况.
截至目前,ROC stories共有两个版本,即SCT_v1.0版和SCT_v2.0版.SCT_v1.0是目前运用最广泛的版本,它的训练集和测试集都包含1 871个由4句话组成的不完整故事、2句不同的故事发展方向、正确发展方向的标签.SCT_v2.0与SCT_v1.0结构相同,含1 571个由4句话组成的不完整故事、2句不同的故事发展方向及正确发展方向的标签.
在实验中,视SCT_v1.0数据集整体为实验的训练集,SCT_v2.0中1 571条测试数据为实验的测试集.特定任务层数据主要来自GLUE库和一个MRC数据集,分别为属于NLI的MNLI(multi-genre natural language inference)和QNLI(question-answering natural language inference),属于SC的SST(the stanford sentiment treebank)和IMDB(internet movie database),属于NAP的SWAG(situation with adversarial generations),以及属于TS的MRPC(microsoft research paraphrase corpus).表1展示了几个特定任务的数据量和任务类型.

表1 特定任务数据集
整个实验过程共4步.首先,实验将不同特定任务的数据打包输入共享层.其次,在MTL阶段,在每个批次选择一个小批量数据,并根据特定任务的目标更新模型.该阶段保留微调后的模型和参数在迁移层使用.第三步为迁移过程,为学习源任务中的语义信息,目标任务SCT使用在特定任务层中训练好的模型和参数,得到迁移学习后的预测结果.最后,模型在组合层将学习到的语义信息融合,以此预测故事发展方向.
4 实验结果与分析
4.1 实验结果
该节通过对比实验及消融实验验证模型的有效性.根据Devlin等提供的模型,实验将BERT-base-uncased作为共享层中加载的语言模型.BERT-base-uncased是BERT模型的基本版,它由12个双向transformer编码器构成,包含768个隐藏层,12个自注意头,共计110 Mb参数.
表2展示了以往研究与该研究的实验结果.该次实验提出的TMTIS较Li等的trans-BERT模型,准确率提升了2.9%,充分证明该方法在融合多种特定任务中学习到了更多的语义信息,有效提升了预测精度.
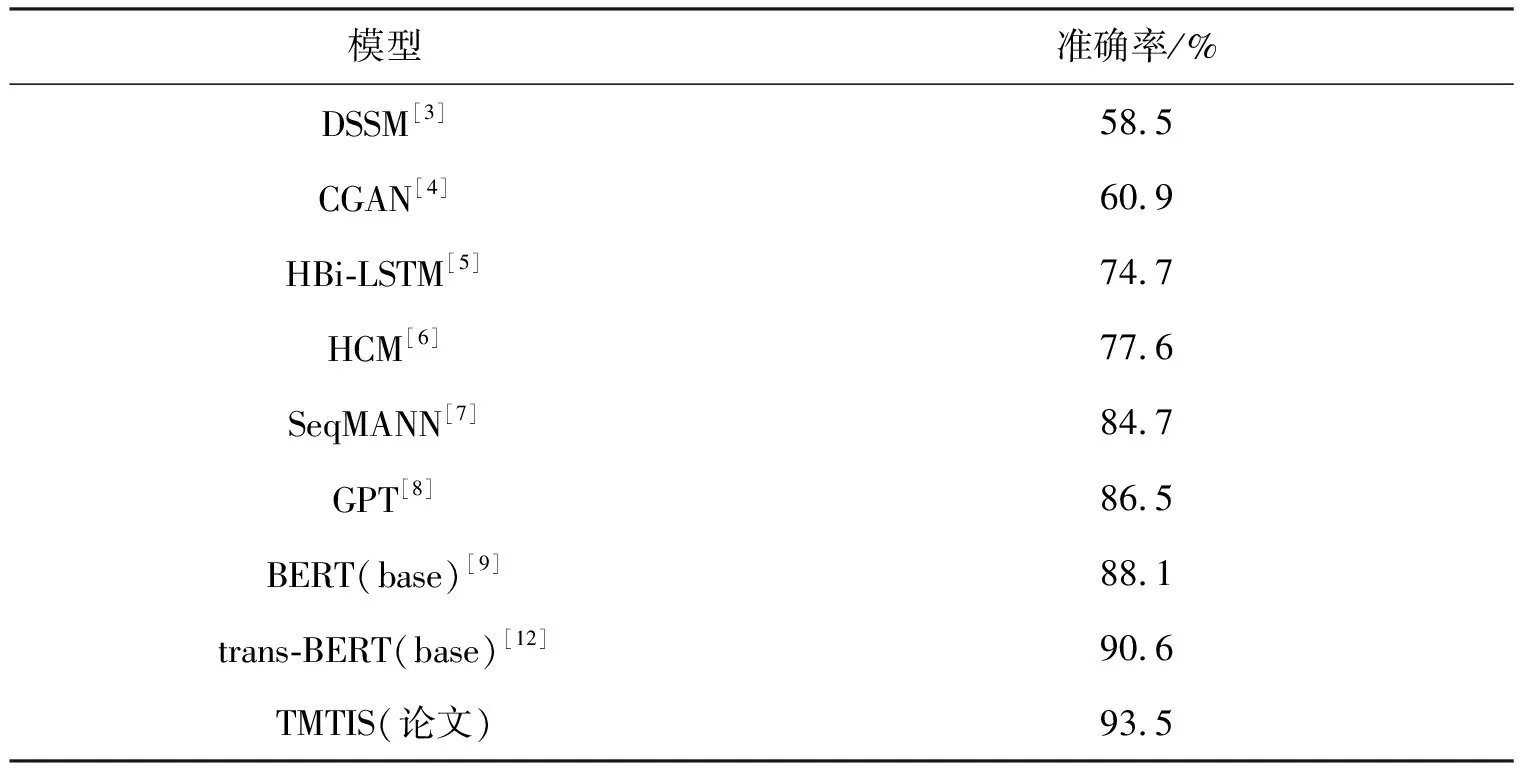
表2 不同方法的性能比较
基于迁移学习的各个特定任务预测精度如表3所示.其中属于NLI的MT-DNN(base)+MNLI预测精度最高,达到了91.2%;MT-DNN(base)+QNLI的预测精度略低,为90.1%.属于SC的MT-DNN(base)+IMDB与MT-DNN(base)+SST的预测精度分别为86.8%与88.4%.MT-DNN(base)+MRPC与MT-DNN(base)+SWAG分别取得了89.7%与89.5%的预测精度.同时与trans-BERT模型结果相比,除情感分类任务,其他特定任务在SCT上基于迁移学习后的预测精度皆有提升.实验结果发现,当模型只学习一种特定任务的语义信息时,预测表现比使用所有语义信息时差,这表明单一类型的语义信息对于故事结尾选择是不够的.

表3 特定任务迁移后预测结果
融合不同任务的语义信息,得到模型最终的预测精度,如表4所示.实验结果发现,将所有信息融合后的预测准确率仅有91.7%,而论文达到93.5%.
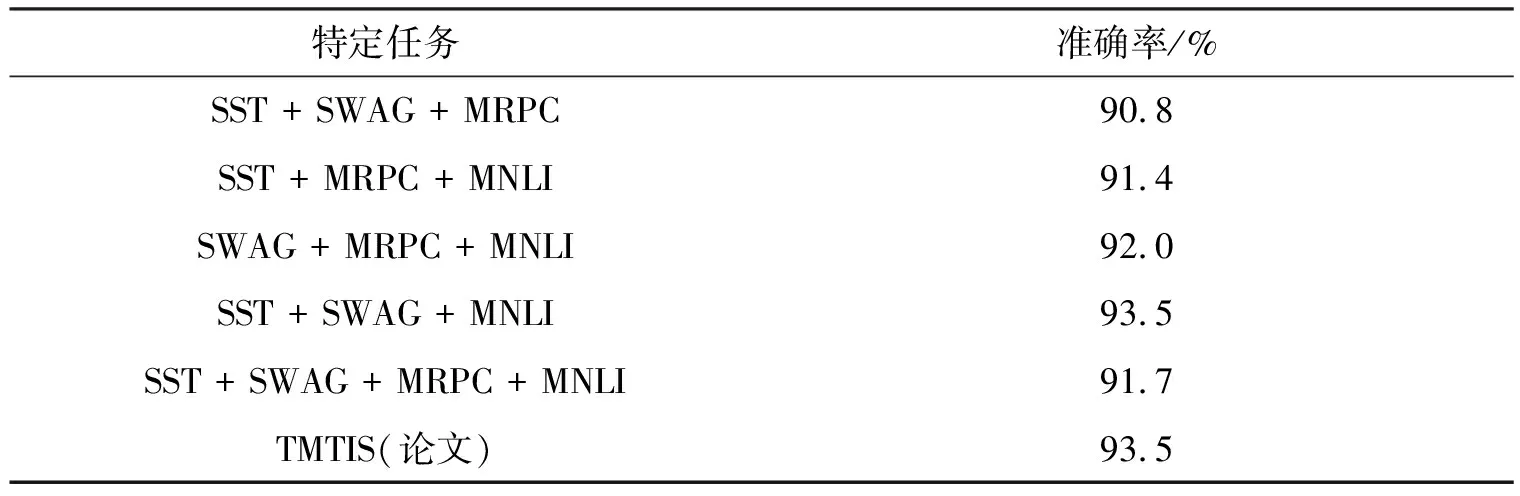
表4 多任务的组合
表5展示了消融实验的结果,验证不同特定任务对理解文本的贡献情况.不难发现,模型在组合特定任务SST,SWAG,MNLI时,剥离NLI任务后,模型预测精度仅为89.8%,下降最多.剥离SC任务后,模型精度下降1.1%.剥离NAP任务后,模型精度下降最少,仅下降0.3%.
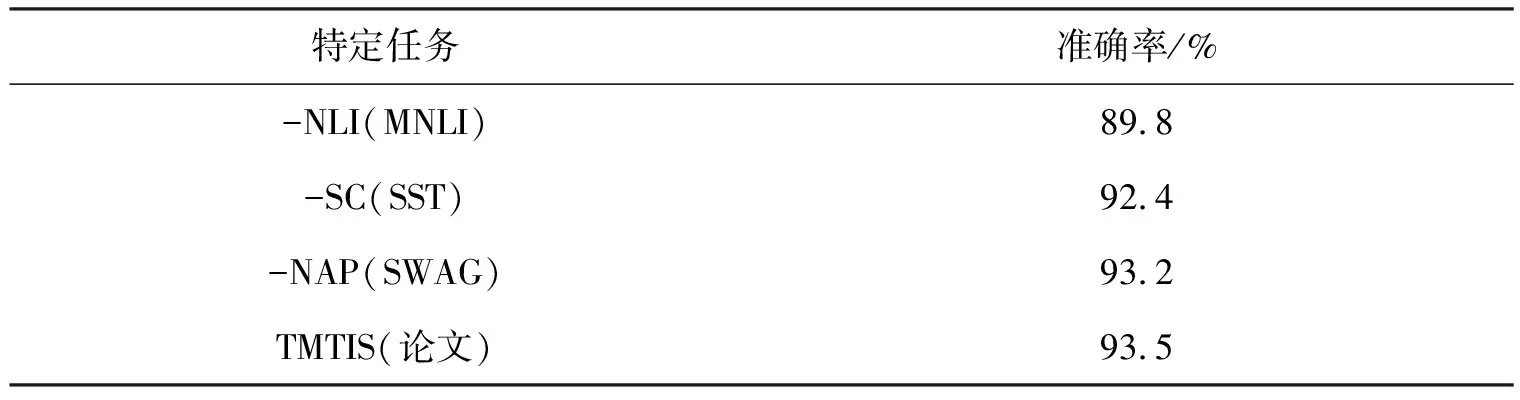
表5 消融实验对比
4.2 结果分析
如表2所示,文中提出的TMTIS模型相较trans-BERT模型提升了2.9%,原因是:相较于其他模型,TMTIS使用MTL提升模型整体的泛化能力,同时从不同角度理解文本,组合多个语义任务并融合其中信息,实现故事发展方向的预测.
在各个结构中,目标任务在特定任务NLI上迁移效果最好,QNLI和MNLI分别达到了90.1%和91.2%,原因是NLI任务能在成对文本关系分类的任务中更好理解上下文潜在含义,从而判断两个文本之间到底是“冲突”、“蕴含”还是“中立”的关系.SCT作为一种阅读理解任务,恰好需要分析整个文本中存在的各种关系,其中不乏类似MNLI的关系分类,因此该特定任务的迁移学习效果最好,达到了91.2%.情感极性预测是一种常见的分类任务,由于一个词在不同上下文中可能存在歧义,其情感也会发生改变.在迁移学习的过程中,由于无法保证个别单词在源任务与目标任务中保持相同的情感极性,因此最终预测效果最差,SST与IMDB的预测精度只有88.4%与86.8%.SCT任务中,故事主体的行为是连续的,许多行为都随着事件的时序发展而出现,这与特定任务NAP预测主体下一步行为的要求一致,属于事件时序发展的预测,因此SWAG在迁移学习后预测精度达到了89.5%.
选择并组合NLI,SC,NAP,TS 4个任务中预测精度最高的特定任务,融合其语义信息,即组合MNLI,SST,SWAG,MRPC,结果如表4所示.实验发现,融合所有语义信息,模型理解文本的效果并非最好,预测精度仅有91.7%,比单一的MT-DNN(base)+MNLI提升了0.5%.各组合中含有MRPC,即包含TS任务的组合,预测精度提升皆不明显.考虑到检测文本语义的相似度仅能判断两个句子是否在语义上等效,机器虽然可以在单个任务上取得较高的预测精度,但完整的故事中包含多种语义信息,在融合时与其他语义信息重合,导致模型理解文本的能力提升不显著,则预测精度提升较少.因此论文选择SST,SWAG,MNLI的组合,其预测精度达到了93.5%.
选择MNLI,SST,SWAG代表的NLI,SC,NAP作为TMTIS模型内的特定任务,并进行消融实验.通过每次剥离一种特定任务,验证了不同结构对整个模型的贡献程度.表5中首先剥离NLI任务,模型预测精度下降最高,精度降低了3.7%,表明NLI任务贡献最大.原因是NLI任务能够有效为其他任务服务,使预测故事发展变得简单.在剥离SC任务时,预测精度下降了1.1%,表明情感的极性影响了故事发展的预测.在剥离NAP任务时模型预测精度下降最少,分析认为NAP任务与SCT任务的数据在语义上相差不大,导致该特定任务贡献较小.同时侧面验证了NLI与SC任务的组合能够更好理解上下文,并做出合理的预测.
5 实例研究
图5为3个典型实例,从图5可以直观反应搭建的组合模型在故事发展方向上如何做出决策.
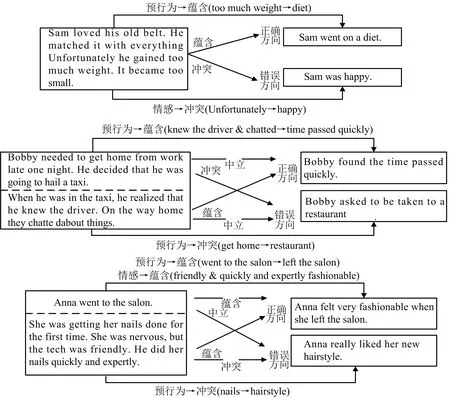
图5 3个典型实例
第一个实例讲述了“Sam”非常喜爱他的腰带,但因为肥胖无法穿上它的故事.在正确的故事发展方向中,考虑到NLI和NAP任务,从他因为“too much weight”到“diet”减轻体重符合逻辑推理与行为发展.而错误的方向中通过NLI和SC任务分析,“unfortunately”与“happy”是截然相反的两种情感,相互冲突.第二个实例讲述了“Bobby”由于很晚下班乘坐出租车回家,在发现司机是熟人并进行交流.在正确的故事发展方向中,考虑到NLI和NAP任务,从他与司机“knew”和“chatted”到“time passed quickly”符合行为的发展与逻辑的推理.而错误的方向中同样通过上述两个任务,“get home”与“restaurant”显然不是一个连贯的行为,故判断它为错误方向.第三个实例讲述“Anna”第一次去沙龙修指甲,虽然她很紧张但技师的非常友好,非常专业.在正确的故事发展方向中,基于NLI,SC和NAP任务,“went to the salon”与“left the salon”连贯且符合逻辑,“friendly & quickly and expertly”与 “fashionable”在情感上都是积极的.在错误的发展方向中,故事主体中提到“nails”与这里的“hairstyle”相互冲突明显不符合逻辑推理.
可以从上述实例中看到,模型组合MTL和TL后,在故事发展方向判断时能考虑更多的信息,达到了建立模型的预期效果.
6 结束语
论文针对故事预测发展研究中模型通过单个语义难以深入理解文本的不足,将模型的关注点集中在多个语义任务上,基于迁移学习并融合任务中多个语义信息.实验验证了所提出的TMTIS模型在融入语言模型、多任务、迁移学习的基础上,有效提升了模型的泛化能力及预测故事发展方向的精度.
