
小波变换结合连续投影算法优化茶叶中咖啡碱的近红外分析模型
2021-11-15 05:37赵静远熊智新宁井铭谢德红
分析科学学报 2021年5期
赵静远, 熊智新*, 宁井铭, 谢德红
(1.南京林业大学轻工与食品学院,江苏南京 210037;2.安徽农业大学茶树生物学与资源利用国家重点实验室,安徽合肥 230036)
茶叶中的咖啡碱是茶叶生物碱的主体成分,约占干物质质量的2%~4%,其有兴奋、利尿、解毒、强心,促进血液循环的作用[1 - 3]。咖啡碱可以作为茶叶的特征性化学物质之一,可用于判断茶叶的真假[4]。近红外光谱(Near Infrared Spectroscopy,NIRS)作为一种高效、快速、低成本、无污染的在线检测的分析技术,在农业[5]、医药[6]、烟草[7]和食品[8]等行业得到广泛地重视和应用。目前,国内外学者已利用近红外光谱对茶叶进行了定性分类和定量研究[9 - 13]。利用近红外光谱定量分析咖啡碱依赖于模型的可靠性,但是近红外光谱信息复杂和全谱建模的预测能力不足会影响模型的稳定,通常采用波长变量选择方法,筛选出信息强且对外界影响因素不敏感的波长,从而建立更稳健的模型[14]。已有文献报道[15 - 18]连续投影算法(Successive Projections Algorithm,SPA)能够有效消除众多波长变量间的共线性影响,降低模型复杂度,以其简便、快速的特点得到广泛应用,在多种样品组分的特征波长选取中取得了很好效果。
近红外漫反射光谱由于受到仪器条件、测量环境、样品状态等诸多因素影响,其中含有各种高频的随机噪声、基线漂移、信号本体、样品不均匀和光散射等干扰[19]。已有研究多采用多元散射校正等[20,21]方法尽可能消除这些因素对光谱的干扰,但究竟应该采用何种预处理方法更有利于SPA算法挑选波长,目前所见相关报道较少。本文研究重点即采用小波变换(Wavelet Transform,WT)、多元散射校正(Multiplicative Scatter Correction,MSC)、标准正态变量变换(Standard Normal Variate Transformation,SNV)以及一阶微分(First Derivative,1stD)等预处理方法单独或组合对光谱进行预处理,再结合SPA算法建立茶叶中咖啡碱的偏最小二乘回归(Partial Least Square Regression,PLSR)预测模型。通过比较各模型的精度,探讨SPA算法和各种预处理方法结合的最佳途径,以期在消除各种低频和高频噪声干扰的基础上,充分发挥SPA波长选择能力,获得最佳共线性的波长变量子集,提高所建模型的质量。
1 实验部分
1.1 仪器及试剂
德国布鲁克公司生产的MPA型多功能傅里叶变换近红外光谱仪,带有RT-PbS检测器、OPUS/OVP(OPUS validation program)自检功能,附有内置镀金漫反射积分球、样品旋转器和石英样品杯等配件。
茶叶样本包括2007年度不同地区的高、中、低档茶叶样本158个,由宁波市进出口检验检疫局、中国农业科学院茶叶研究所和镇江市林业局提供。其中包括龙井、碧螺春等优质名茶、大宗茶,市售一般绿茶等。由于样本大多数取自于各茶厂的送检样品,故每份样品只编号未标注具体的茶叶品种和送检单位。同时为扩大模型的适用性,实验中未细分绿茶品种。所有送检样品均已密封保存4个月。
1.2 实验方法
1.2.1 咖啡碱含量测定称取茶叶样品30±1 g,置于HY-02小型磨碎机(北京环亚)中研磨10 s,按照我国国家标准(GB/T 8303-2012)[22],将磨碎样品过100目筛(150 μm),按照国家标准(GB/T 8312-2013)[23]规定方法测定茶叶样品中咖啡碱的含量,每个样品进行3次平行检测。
1.2.2 光谱采集茶叶样品光谱采集范围:12 800~4 000 cm-1,分辨率:4 cm-1。实验温度:20 ℃,相对湿度:40%。均以仪器内置镀金为背景。因在8 000~4 000 cm-1波段茶叶近红外光谱图中的波峰较多且比较明显,故截取该波长范围内共1 038个波长点用于分析研究。图1为部分样品的近红外光谱图。

图1 部分茶叶样品的近红外光谱图Fig.1 Near-infrared spectra of tea samples
1.2.3 样品集的划分本文采用主成分分析(Principal Component Analysis,PCA),利用提取的光谱主成分得分向量来代替光谱向量计算样本的马氏距离(Mahalanobis Distance)[24],将超出设定的马氏距离阈值的异常样本进行剔除,最终从158个样本中剔除两个异常样品,然后采用SPXY[14]将剩余的156个样本划分为校正集和预测集。SPXY在计算样品距离时同时将变量x和变量y考虑在内,分别计算各变量和变量之间的距离,分别见式(1)和式(2):
(1)
(2)
在式(1)和式(2)中,n和m表示任意两个样品,Z是总的样本数,l为光谱的波数点,dx(n,m)表示两条光谱的空间距离,dy(n,m)表示对应咖啡碱之间的距离。
两个样品间的SPXY标准距离计算公式如式(3)所示。
(3)
最终156个样本用SPXY法以3∶2的比例,划分为93个校正集样本和63个预测集样本。校正集用于建立茶叶咖啡碱近红外模型,预测集用于验证所建模型的准确性和可靠性。样品集划分结果见表1。

表1 茶叶样本中咖啡碱的含量分布Table 1 Content of caffeine in tea samples
1.2.4 光谱预处理方法分别采用WT、MSC、SNV以及1stD对光谱进行预处理,探讨各种方法及它们之间的组合对模型精度的影响。小波变换的实质[25]是将信号x(t)投影到小波基函数ψa,b(t)上,即x(t)与ψa,b(t)的内积,得到小波变换系数。按照分析的需要对小波变换系数进行处理,然后利用处理后的小波系数得到反变换信号。小波变换用于处理光谱原始数据的一般方法为:首先对原始光谱进行小波分解变换分解得到高频和低频小波系数;然后通过阈值法去除小波系数中被认为是表示噪声的元素(滤噪),或去除小波系数中的高频(低尺度)元素;最终用经过处理系数进行反变换即可得到滤噪后的光谱信号。
由于小波变换中用到的小波函数不具有唯一性,同一问题用不同的小波函数进行分析有时结果相差甚远,因此小波函数的选用是小波变换实际应用中的一个难点,目前都是基于经验或不断实验后通过结果比较来选择最佳的小波函数[14]。本文即采取实验方法选择不同小波函数处理茶叶近红外光谱并建模,结果表明采用db3小波函数并分解为7层能较好地分辨光谱低频和高频信号并予以处理,建模精度较高。本文后续即选择db3小波7层分解开展光谱数据处理研究。
1.2.5 变量筛选方法SPA是一种前向循环变量选择方法[26]。从选定一个波长开始,每次循环都计算在未入选波长上的投影,将投影向量最大的波长引入到波长组合。每一个新入选的波长,都与前一个线性关系最小。在波长选择中,假设n为初始波长数,为m波长点个数,k(0)为初始波长点。SPA的计算步骤如下:
(1)第一次迭代(Z=1)开始前,在光谱矩阵中任选一列波长向量Xj。记为Xk(0),即k(0)=j,j∈1,…,n;
(2)将未入选的列向量位置集合记为S,S={j,1≤j≤n,j∉{k(0),…k(Z-1)}};

(4)提取最大的投影值的波长变量序号:k(Z)=arg[max(‖Pxj‖)],j∈S;
(5)令xj=Pxj,j∈S;
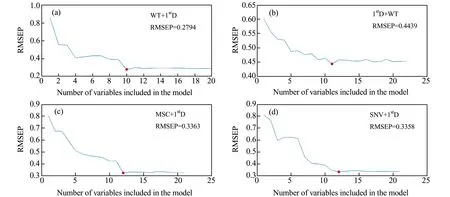
(6)Z=Z+1,如果Z {k(Z),Z=0,…,m-1}为最终选取的波长变量组合。算法对每次选择的结果进行建模预测分析,以最小均方根误差(RMSEP)来决定所建模型的优劣,它所对应的即为波长集合的最佳初始波长点n和最佳波长点个数m。 研究中采用粉末状茶叶样品测量近红外光谱,因此由茶粉颗粒分布不均匀及颗粒大小不同产生的散射误差将是信号中的主要干扰,其通常表现为基线的平移、旋转(低频)和二次和高次曲线(高频)等[25]。在各种预处理方法中,SNV、MSC通常用于校正低频散射信号、1stD可以消除信号的旋转,而WT基于多分辨分析原理,则可以同时消除光谱信号中的高频和低频噪声。分别以WT、MSC、SNV和1stD预处理光谱后采用PLSR建模统计结果列于表2。使用验证集相对分析误差(RPD)对模型进一步评价,如果RPD≥3.0,说明定标效果良好,建立的定标模型可以用于实际检测;如果2.5 表2 采用不同预处理方法的全波段PLSR模型性能Table 2 Performance of full-band PLSR models using different preprocessing methods 分别用WT、MSC、SNV和1stD处理近红外光谱,再利用SPA算法挑选波长并建立相应的PLSR预测模型,模型的预测结果见表3。从表3可看出,通过三种预处理方法结合SPA波长选择方法,能有效地减少入选波长数量(从原始1 038个波长减少到31个以下),且模型的精度总体上也有了一定地提升,其中1stD入选波长最少(11个)。 表3 不同预处理方法结合SPA的PLSR模型预测结果Table 3 PLSR model prediction results of different pretreatment methods combined with SPA 图2分别为WT、MSC和SNV分别结合1stD预处理方后的光谱图,为便于比对,图中还列出先1stD再WT处理结果(图2(b))。表4则是在1stD+SPA基础上分别与MSC、SNV、WT等预处理方法结合后的建模效果。 表4 小波变换结合1stD+SPA的PLSR模型预测结果及比较Table 4 Prediction results and comparison of PLSR models combined with wavelet transform and 1stD+SPA 从图2中可以看出,茶粉近红外光谱经WT-1stD或1stD -WT预处理后在6 000~4 000 cm-1波段有较明显的吸收峰,几乎不受噪声干扰,而MSC-1stD和SNV-1stD处理后峰信息则完全淹没在噪声信号中。从表4中可以看出,WT结合1stD(WT-1stD或1stD -WT)最终建模效果总体优于其它几种预处理方法,而又以WT-1stD -SPA-PLSR组合所建模型最好,且只用10个入选波长建模。这说明利用WT预先消除光谱信号中的大部分高频噪声,有利于1stD方法提高分辨率和提供更清晰的光谱轮廓变化,减少近红外原始重叠谱带波长之间高共线性,挑选出更有代表性的特征波长。其挑选出的波长数10和通过交叉验证确定的最佳PLS成分数7也比较接近,表明WT-1stD预处理后采用SPA方法所选波长具有较好的代表性和相对独立性,由此建立的模型比较稳健,故其校正精度和预测精度均较高。 从表4还可以看出,1stD和MSC、SNV、WT结合处理先后顺序对模型结果影响明显,而且先1stD后进行其它预处理总体建模效果略差。其原因可能在于原始信号经1stD处理后,有效信号和被放大的高频噪声混叠严重,后续的WT、SNV和MSC分别采用频域方法和统计方法抑制高频信号的同时也削弱了有效信号。比较图2(a)和图2(b)可以看出,对于1stD -WT处理,由于WT对1stD放大的噪声以及微分信号都进行了去高频处理,故其信号较WT-1stD平滑,可能损失部分谱峰信息而降低建模效果。 图2 茶叶近红外光谱分别经WT、MSC和SNV并结合1stD预处理图Fig.2 The near-infrared spectra of tea pretreated by WT,MSC and SNV combined with 1stD 图3是不同方法与1stD及SPA组合预处理光谱并建模计算RMSEP值的结果。由图3(a)可以看出,经过对校正集数据进行WT-1stD预处理后,在SPA选择过程中均方根误差的变化情况。在选择4个光谱波长变量之前曲线下降趋势很大,表明茶叶中咖啡碱含量的光谱波长变量应该至少选择4个以免产生过拟合的问题;选择4个到10个光谱波长变量时均方根误差曲线下降至最低值;之后选择10个以上的光谱波长变量时,曲线虽有升降但总体趋于平缓。最终选择10个光谱波长变量,其均方根误差(RMSEP)达到最小为0.2794。其它几种预处理方法组合也有类似趋势,但最终入选波长均大于10个,但大都少于未用1stD处理入选波长数(表3)。这都说明正是1stD提高了光谱分辨率,利于后续SPA算法挑选出少数特征波长。 图3 WT、MSC和SNV结合1stD及SPA选取特征波长数及RMSEP值Fig.3 The number of selected characteristic wavelength and RMSEP by WT,MSC and SNV combined with 1stD and SPA 图4谱图上标出了经WT-1stD -SPA预处理并建立咖啡碱近红外分析PLSR模型所选择的10个波长点(4 003、4 350、4 473、4 627、4 812、5 175、5 244、5 275、5 583和5 984 cm-1)位置。咖啡碱又名1,3,7-三甲基黄嘌呤,其碳氮嘌呤环结构由一个嘧啶环和一个咪唑环稠合而成,杂环上含有三个-CH3和两个C=O[4]。由于茶叶作为组分复杂的自然产物,各有机组分官能团在近红外光谱带重叠严重,一般很难清晰地指出各谱峰对应的具体基团信息,但根据近红外主要谱带归属仍可对所选波长合理性做出必要分析。由于甲基吸收谱带位于4 200~4 440 cm-1,为C-H键伸缩振动与弯曲振动的合频区;羰基吸收谱带位于5 050~5 210 cm-1,为C=O键伸缩振动的二级倍频区[14]。而且由于核酸中的嘌呤核苷酸,蛋白质中的蛋氨酸、甘氨酸、谷酰胺、天冬氨酸等都和咖啡碱的合成有关[4],因此可以推断在蛋白质的特征吸收区4 545~4 655 cm-1、4 854~4 878 cm-1,以及蛋白质仲酰胺(CONH)中的C=O伸缩振动二级倍频吸收(5 208 cm-1)等[28]波段附近应该存在茶叶咖啡碱的特征吸收。对照已选出的10个波长点可以看出,它们大部分都落在以上谱带区域内或附近,表明挑选出的各峰位较好地反映了咖啡碱的吸收特征[29,30]。 图4 最佳模型选取的最优特征波长点Fig.4 Optimal characteristic wavelength points selected by the best model (1)利用全波段建立茶叶咖啡碱近红外分析模型,处理数据量大,建模时间长,同时可能引入更多的背景干扰。SPA方法则可以通过挑选特征波长,简化模型,并消除多重共线性,有利于提高模型的简洁性和精度,但该方法易受到重叠峰、高低频噪声和基线漂移的影响。 (2)采用WT-1stD相结合预处理光谱,可实现两者优势互补,即WT有去高、低频噪声及基线漂移的作用,1stD则进一步提高重叠峰的分辨率,方便后续SPA算法挑选更具代表性的最小共线性的波长变量子集。建模实验表明,WT-1stD预处理方法显著地提高了茶叶咖啡碱近红外SPA+PLSR预测模型的精度。 (3)通过WT-1stD预处理后,SPA算法提取特征波长较好地分布于茶叶咖啡碱主要官能团吸收区域,提高了咖啡碱近红外分析模型的可解释性。2 结果与讨论
2.1 不同预处理方法结果分析

2.2 不同预处理方法结合波长选择结果分析




3 结论
猜你喜欢
安徽农业大学学报(2022年2期)2022-11-21材料与冶金学报(2022年2期)2022-08-10杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08温州大学学报(自然科学版)(2022年2期)2022-05-30阅读(科学探秘)(2021年8期)2021-09-01粉末冶金技术(2021年3期)2021-07-28建材发展导向(2021年23期)2021-03-08热带农业科学(2018年6期)2018-09-26家庭医药·快乐养生(2017年6期)2017-06-16家庭科学·新健康(2016年5期)2016-05-12
