
基于SVM的粮食霉变预测分类方法研究
2021-11-12 00:55苑江浩赵会义
中国粮油学报 2021年9期
苑江浩 常 青 赵会义 唐 芳
(国家粮食和物资储备局科学研究院,北京 100037)
粮食霉变在粮食储藏过程中极易发生,是影响粮食品质的一项重要因素,据统计,我国因粮食霉变造成的产后损失占总产量的4.2%[1]。为降低粮食损失,国内外研究者从粮食霉菌生长规律、粮食霉变快速检测、储粮安全和粮情预测等方向开展研究。Genkawa等[2]研究了不同水分的稻谷储藏过程中霉菌数量的变化;唐芳等[3-6]从实验室和实仓的角度开展了储粮危害真菌生长及演替规律的研究;刘慧等[7]以安全水分稻谷为研究对象,开展在不同储藏温、湿度中的霉菌生长规律研究,并建立生长动力学模型;蔡静平等[8-11]开展了不同粮食品种在储藏过程中霉菌活动特性差异性研究。亦有研究者通过电子鼻技术[12, 13]、机器视觉技术[14]、高光谱技术[15, 16]等开展了粮食霉变无损快速检测的研究。同时,很多研究者[17-20]从储粮安全和粮情预测角度出发,建立储粮安全风险预警模型,结合粮堆温度、湿度、水分和CO2等因素,用于分析检测粮食霉变的可能性,以保证储粮安全。而针对霉变预测的方法较少,邓玉睿等[21, 22]研究了基于朴素贝叶斯和BP神经网络进行霉变预测技术的研究,但其仅针对稻谷进行了初步探索,且建模所需的训练样本集较大,面临小样本时,准确率较低。
支持向量机[23, 24](Support Vector Machine, SVM)算法简单,且鲁棒性较好,可有效解决非线性分类等问题,其主要应用于分类预测研究,特别是在小样本分类预测领域应用效果很好,目前该算法已在图像识别[25, 26]、文本分类[27, 28]等领域得到广泛应用。该算法在粮食领域内亦得到广泛应用,郑沫利等[29]通过SVM对数据建模,以对粮食在储藏过程中的损耗智能评估;段珊珊等[30]利用SVM建立粮堆表层平均温度预测模型,通过气象8因素预测粮堆表层平均温度;吕俊[31]利用海量的粮食通风控制数据训练SVM模型,以用于粮食通风控制的预测。本文将该算法应用到粮食霉变预测分类中,克服现有技术存在的主要问题,为粮食霉变预测提供新思路。
1 材料与方法
1.1 实验设备
HPS-250生化培养箱,PL3002-IC电子分析天平,HG-9246A型电热恒温鼓风干燥箱,SMART显微镜,DJSFM-1粮食水分测试粉碎磨。
1.2 实验样品数据的获取
将不同含水量的稻谷、小麦样品密封分别置于不同储藏温度(10、15、20、25、30、35 ℃)的生化培养箱模拟储藏180 d,每10 d取样检测水分和真菌孢子数。其中水分的检测方法参照GB 5009.3—2016《食品安全国家标准 食品中水分的测定》[32]中直接干燥法检测,真菌孢子数参照LS/T 6132—2018《粮油检测储粮真菌的检测 孢子计数法》[33]计算。
2 模型建立与分析
2.1 支持向量机理论
设训练样本集D={(x1,y1),(x2,y2),…,(xm,ym)},yi∈{-1,1},SVM最基本的思想是基于训练集D找到一个划分的超平面,从而将不同类别样本分开。即存在如下划分超平面:
ωTx+b=0
(1)
式中:ω=(ω1;ω2;…;ωd)为法向量,b为偏置项。此时分类的最大间隔为:
(2)
为更好地解决这个凸二次规划问题,引入拉格朗日乘子法(αi≥0)得到其“对偶问题”。
(3)
在实际的应用中,会存在大量线性不可分问题,原始样本空间中并不存在一个合理的超平面,以保证样本的正确划分。为解决该问题,引入核函数概念,以代替对偶问题和非线性映射后的点积运算,常见的核函数[14]有线性核、多项式核、高斯核、拉普拉斯核、Sigmoid核。同时为了克服无法完成严格分类、过拟合等问题,引入惩罚因子C和松弛变量g两个参数。
2.2 SVM建模与参数优化
本研究使用的SVM模型总体框架如图1所示。数据预处理:将原始数据集参照LS/T 6132—2018中的附录C储粮安全评价参考表[33]进行数据处理,详见表1。将“Ⅲ级-危害”确定为是否发生霉变的标准(以对粮食造成危害为标准),划分数据类别。
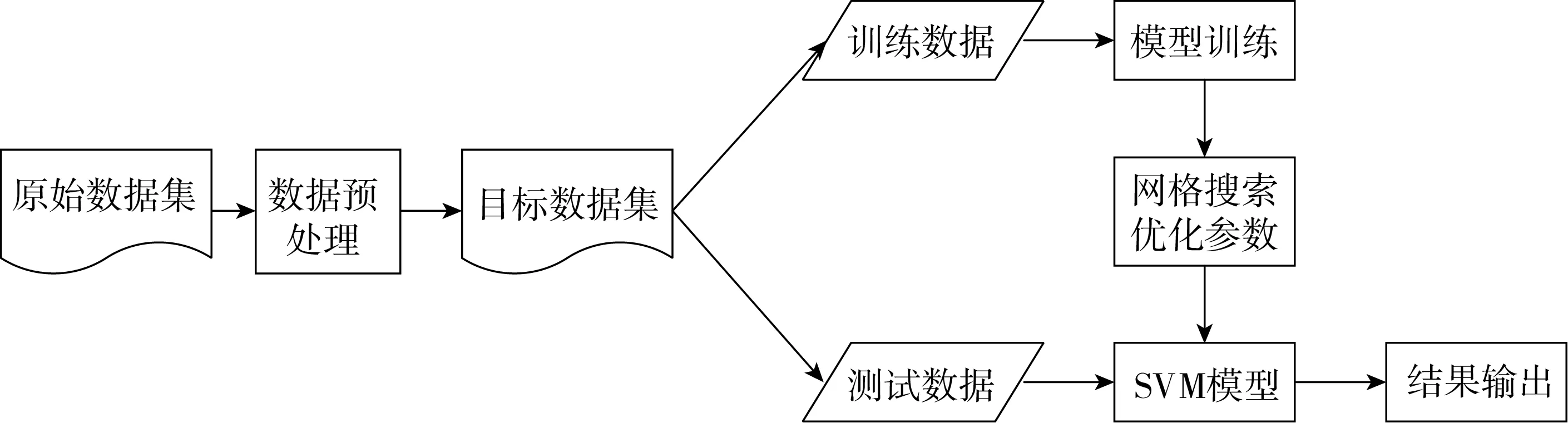
图1 SVM模型总体框架图

表1 储粮安全评价参考表
参数优化:在SVM的建模过程中,惩罚因子C和松弛变量g两个参数是影响模型精准度的主要因素[34],为了提升模型的准确度,保证参数最优化,本文采用网格搜索(Grid Search)方法优化参数,寻求最适应模型。其基本原理是通过遍历网格内所有的点进行取值,得到一组令训练集分类准确率最高的C和g的值作为最优参数。
2.3 实验设计与分析
实验针对稻谷和小麦两种粮食品种分别采用经网格搜索寻优参数后的SVM模型处理,若粮食已发生霉变,以“1”标识,若未发生霉变,以“-1”标识。实验结果将预测值与实际值进行求差运算后取绝对值,如值为0,则表示预测值与实际值相符,预测分类正确;如值为2,则表示预测值与实际值不符,预测分类错误。实验结果评定标准如表2所示。

表2 实验结果评定标准表
2.3.1 稻谷霉变预测分类
稻谷样品数据共计2 592组,实验随机选取2 492组数据作为训练数据,100组数据作为测试数据。经多次实验验证得到,SVM建模后预测分类准确率可达98%,平均准确率在96%以上。预测分类结果如图2所示,此时SVM选用的核函数为高斯核RBF网络,惩罚因子C=45。该模型预测分类准确率与文献[22]中基于BP神经网络模型的预测准确率基本一致。

图2 基于SVM模型的稻谷霉变预测分类结果图
2.3.2 小麦霉变预测分类
小麦样品数据共计876条,实验选取776条数据作为训练数据,100条数据作为测试数据。经多次实验验证得到,SVM建模后预测分类准确率可达94%,平均准确率在92%以上。预测分类结果如图3所示,此时SVM选用的核函数为高斯核RBF网络,惩罚因子C=60。

图3 基于SVM模型的小麦霉变预测分类结果图
本研究通过复现文献[22]的实验程序,并应用于小麦样品的预测分类中,依然选取776条数据作为训练数据,100条数据作为测试数据。其预测结果如图4所示。经过多次实验验证,预测准确率为82%~91%,其稳定性较差,平均准确率仅为86%。
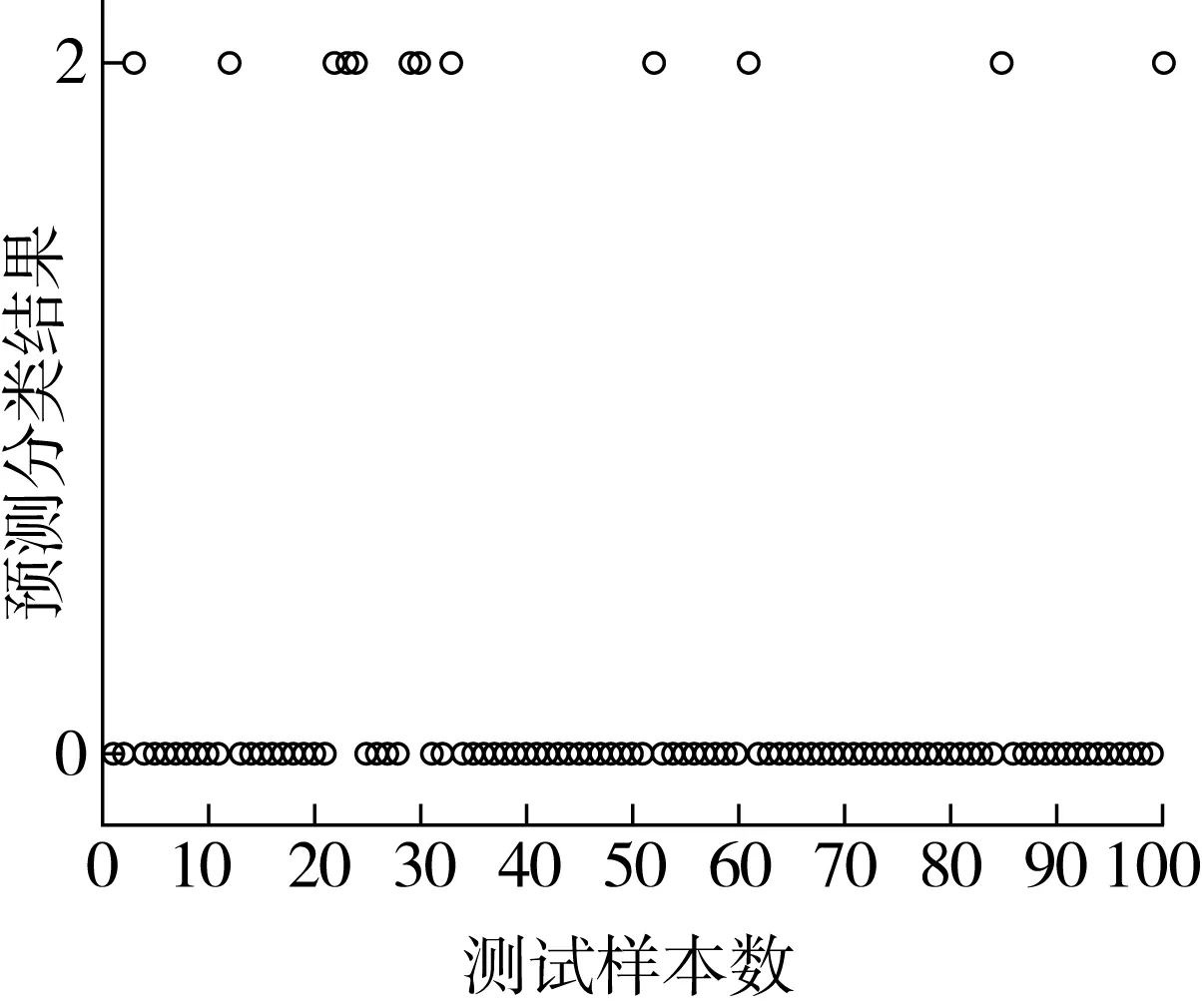
图4 基于BP神经网络的小麦霉变预测结果图
2.3.1和2.3.2证明SVM模型可以有效预测分类粮食是否发生霉变。并且在小麦的预测上更具有优势,推断可能原因是小麦的训练样本集较小,SVM发挥其自身小样本的优越性。因此,本研究为验证SVM针对于小样本的预测分类能力,通过不同规模的训练样本集进行SVM小样本预测分类实验。
2.3.3 SVM小样本预测分类
实验数据集与2.3.1和2.3.2保持一致,分别采取SVM模型与文献[22]中的BP神经网络模型两种模型进行,随机选取400、200组数据作为训练数据,剩余数据作为测试数据开展实验。
2.3.3.1 稻谷
采用SVM模型进行实验,预测分类结果如图5所示。实验结果表明,当训练数据为400组时,预测分类平均准确率约为91.97%;当训练数据为200组时,预测分类平均准确率约为90.76%。
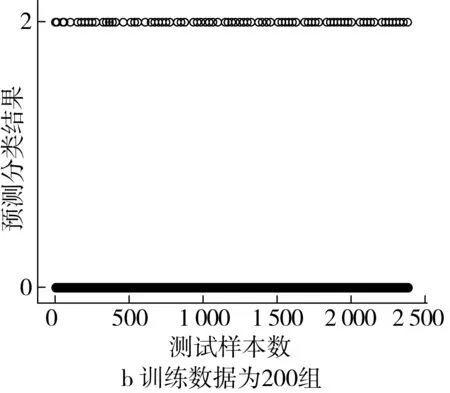
图5 基于SVM的稻谷小样本预测分类结果图
采用BP神经网络模型进行实验,预测分类结果如图6所示。实验结果表明,当训练数据为400组时,预测分类平均准确率约为86.34%,当训练数据为200组时,预测分类平均准确率约为71.47%。


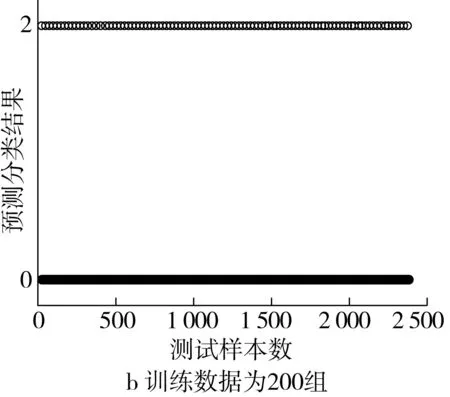
图6 基于BP神经网络的稻谷小样本预测分类结果图
2.3.3.2 小麦
采用SVM模型进行实验,预测结果如图7所示。实验结果表明,当训练数据为400组时,预测分类平均准确率约为88.1%,当训练数据为200组时,预测分类平均准确率约为86.55%。

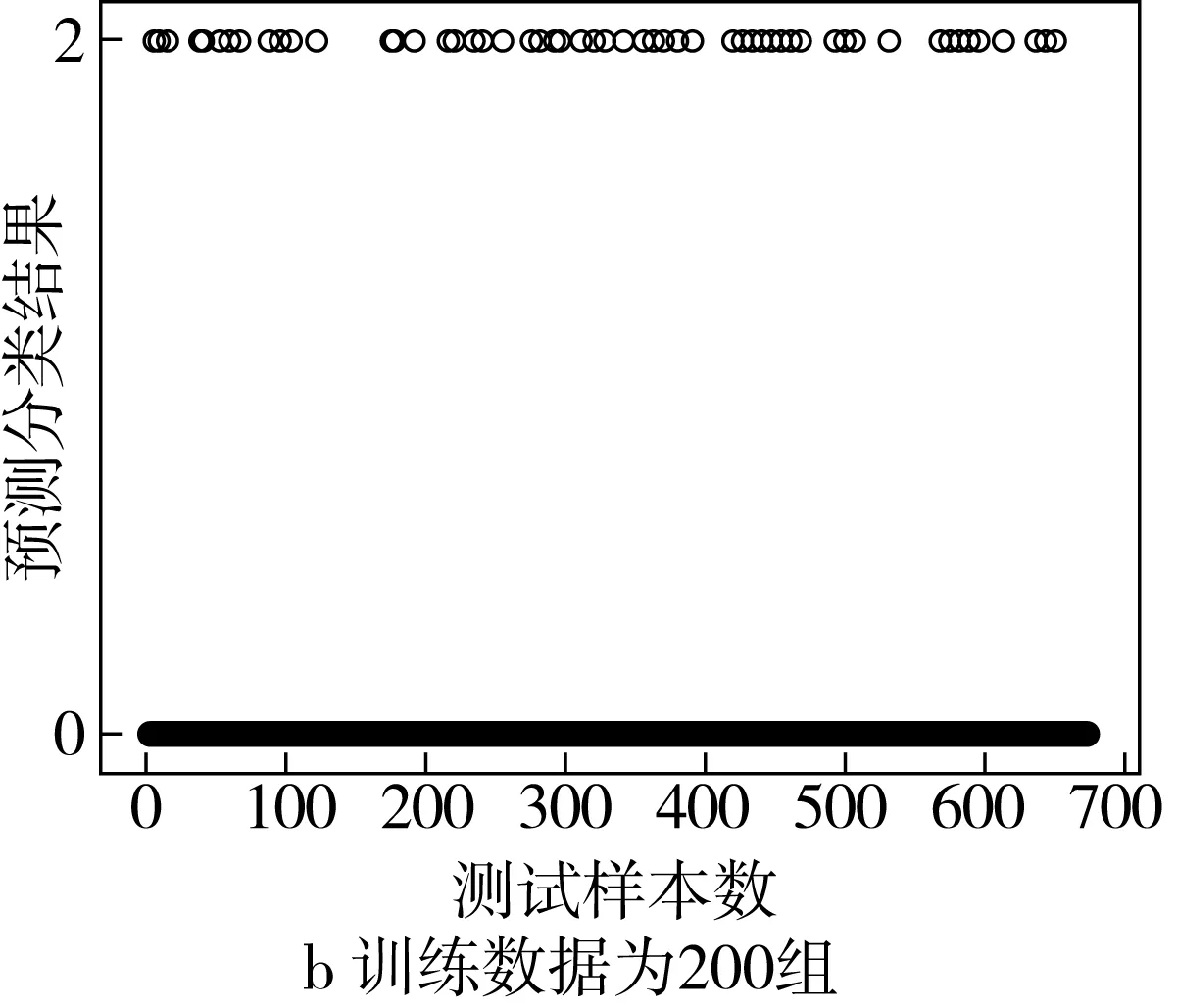
图7 基于SVM的小麦小样本预测分类结果图
采用BP神经网络模型进行实验,预测结果如图8所示。实验结果表明,当训练数据为400组时,预测分类平均准确率约为84.45%,当训练数据为200组时,预测分类平均准确率约为70.76%。

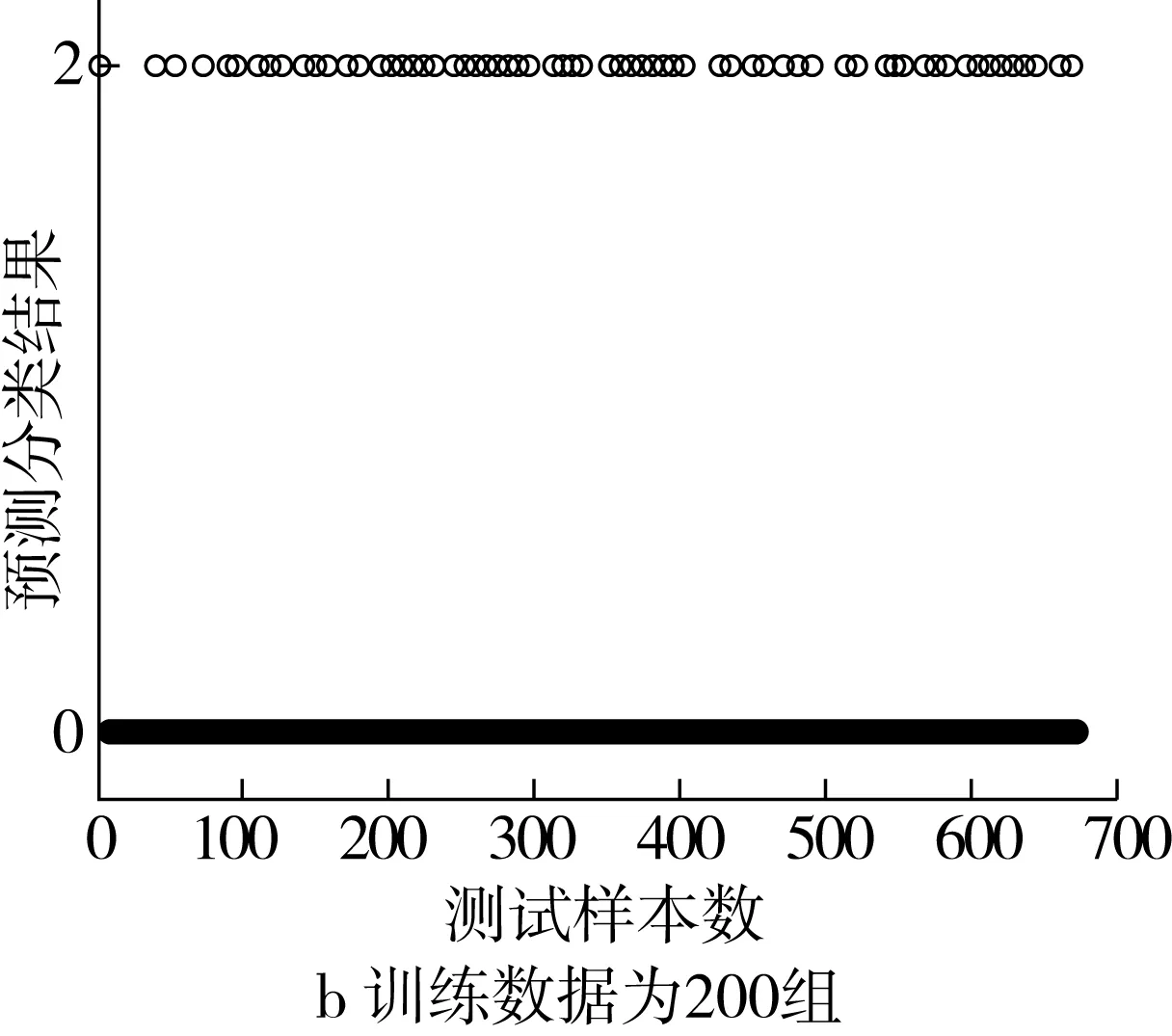
图8 基于BP神经网络的小麦小样本预测分类结果图
由实验数据可知,当样本训练集较大时,SVM模型和BP神经网络模型准确率相当,但当降低样本训练集后,SVM模型表现出较为突出的优势,尤其是当样本训练集仅为200组数据时,准确率相差较大。因此,当测试样本数为小样本时,SVM模型准确率更高,效果更好,能够为预测分类提供更为可靠的支撑。2.3.1、2.3.2和2.3.3中的平均准确率对比情况见表3。
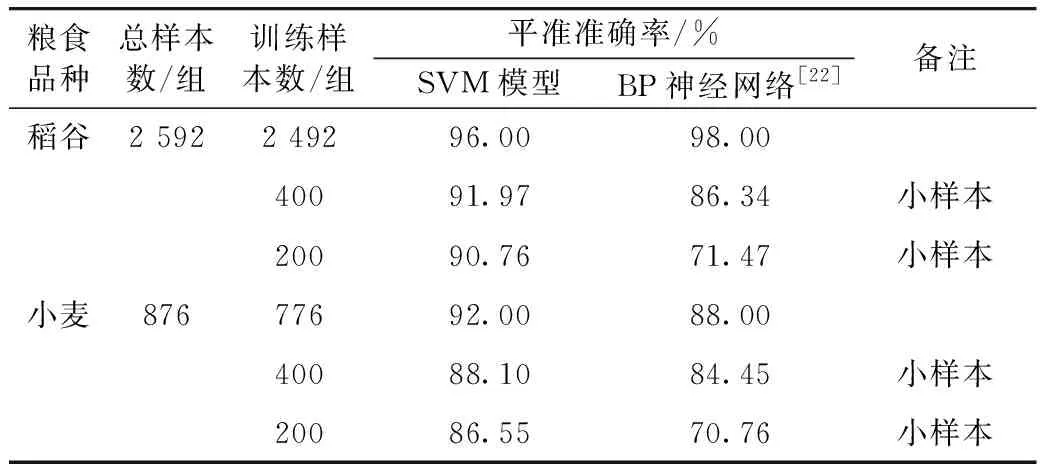
表3 预测分类平均准确率对比表
3 结论
本研究利用python建立了基于SVM的粮食霉变预测分类模型,通过稻谷的2 592组数据和小麦的876组数据进行实验,分别选用不同规模的数据量作为训练样本集建立模型,预测平均准确率分别为96%和92%,该实验结果证明SVM模型可以有效分类预测粮食是否发生霉变。同时本研究复现BP神经网络模型,将SVM模型预测结果与其对比,发现针对于大量样本进行训练后,两种模型准确率基本一致。针对小样本进行训练后,SVM模型表现良好,准确率高,且表现稳定,明显优于BP神经网络模型。
猜你喜欢
品牌研究(2022年26期)2022-09-19
快乐语文(2021年36期)2022-01-18
小天使·一年级语数英综合(2021年10期)2021-10-20
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年19期)2019-11-23
中国粮食经济(2018年11期)2018-12-27
中国交通信息化(2018年5期)2018-08-21
重型机械(2016年1期)2016-03-01
