
基于居民出行起讫点分布特性的集中交付点选址方法
2021-11-12 12:26渠志云
物流技术 2021年10期
边 军,丁 乔,渠志云
(1.包钢矿业有限责任公司,内蒙古 包头 014000;2.内蒙古第一机械集团有限公司,内蒙古 包头 014000)
0 引言
随着电子商务的飞速发展,物流行业迎来难得机遇的同时也面临着巨大的挑战。快递业务量的急剧增长使得最后一公里配送成为难题。由于快递员送货与客户收货时间窗经常无法匹配,导致出现配送延迟遭客户投诉以及多次配送增加配送工作量等问题。如何提高配送服务满意度和配送效率成为亟待解决的难题。针对这一难题,有研究学者提出CDP 配送模式,如Song L[1]指出为了应对中国网络购物市场的迅猛发展,最后一公里问题备受关注,但上门配送模式失败后会导致运营成本增加。同时,也有研究学者对CDP 配送模式的接受程度进行了调查,如Yuen K F[2]以创新扩散理论(IDT)为基础,分析了顾客是否愿意将CDP配送模式作为最后一公里交付方式,调查数据收集自164 名新加坡消费者,采用层次回归分析方法进行分析,结果表明CDP 模式明显优于其他最后一公里交付方式。CDP配送方式都能有效地解决上门配送中快递员和客户时间不一致问题,有效地缓解了最后一公里配送这一难题。随着CDP模式不断推广,CDP选址是否合理,将直接影响到客户使用的方便性、CDP的使用率、客户满意度及运营商收益等,因此,CDP选址成为亟待解决的问题,找到一种合适且高效的CDP 选址方法成为解决这一问题的关键。
1 研究现状
针对物流设施选址问题,国内外学者进行了大量研究,黄风春[3]在传统的最大覆盖模型的基础上,以快递公司投放快递柜后收益最大化为目标函数,建立数学模型,使用设计的BPSO 算法对模型求解,完成对智能快递柜的选址。G R Sutanto,等[4]通过k-means 聚类算法确定设施位置并且完成对客户的分配,然后使用三种聚类评估方法分别从选址结果的连通性、紧凑性、分离因子三个方面进行评价。黄涛[5]提出了一种结合地理空间信息的快递自提点选址方法,通过对地理空间信息分析确定快递自提点备选地址,利用距离惩罚成本函数对CFLP模型进行改进建立快递自提网点选址模型,实现自提网点选址。Irawan,等[6]针对两阶段供应链中的多产品设施选址问题,以配送点的固定成本和运输成本最小为目标函数,建立数学模型,并设计了一种结合聚集法和精确算法的求解方法对模型进行求解,并验证了其建立模型和算法的有效性和优越性。Kedia,等[7]在消费者对CDP 可接受性研究中指出:CDP 与住宅和工作区的距离是影响CDP 接受度的一个重要因素。Esser和Kurte[8]在对CDP使用过程的调查中发现有80%的人更愿意把到CDP行程与其他出行行程相结合。
综上可知,居民更倾向于把到CDP 取寄快递和其他的行程相结合,比如,在上下班的路上顺便到CDP 取寄快递。所以,CDP 的选址应该结合居民的出行规律,尽可能使到CDP 取寄快递的行程与居民的日常出行行程结合更为便利,但目前还没有针对CDP这一特性的选址方法。
2 方法概述
在CDP 选址研究中充分考虑居民出行OD 点分布特性,便于居民将到CDP 的行程与日常行程进行关联。如图1(a)所示,将到CDP 行程作为日常行程一部分,避免了把CDP 单独作为出行行程造成时间和距离的浪费,如图1(b)所示。在对OD样本点分析时,还应该考虑OD样本点的相对位置关系,如:靠近住宅区要比靠近购物中心的OD 点对选址结果的贡献更大,因此,需要根据OD 点对选址结果的贡献度为其设置不同的权重值。计算权重值应考虑OD 点在一定范围内包含POI 数量和各POI 与其的距离。然后,使用Mean Shift 聚类算法对不同权重值的OD点进行聚类分析,得到OD点聚类簇用于反映居民出行起讫点规律,聚类簇成员越密集,表示该区域居民日常访问越频繁,聚类簇中心表示CDP 设施地址的备选点。
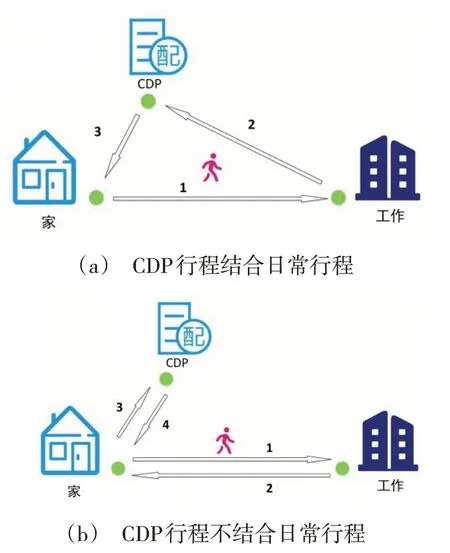
图1 居民行程对比示意图
2.1 均值漂移聚类分析
Mean Shift 是基于密度的非参数聚类算法,根据当前点与给定空间内样本点的偏移向量计算出当前点的偏移均值,然后,按照该偏移均值向量更新当前点位置,并以此位置作为新的起点,重新计算偏移均值,以此方法迭代计算,直到满足算法设定的终止条件。由于其计算速度快且具有较强的鲁棒性,所以,本文选用此聚类算法完成对OD点的聚类分析。
假定d维空间Rd中的n个样本点xi(i=1,2,...,n),对于任意一点x,其Mean Shift 偏移向量的形式为:
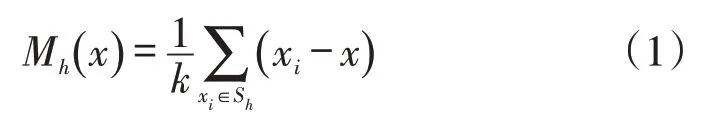
其中Sh表示在半径为h的区域内样本点的集合:
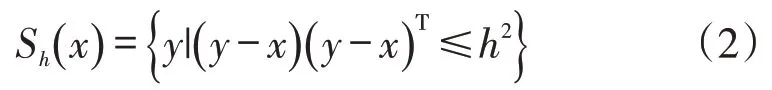
k表示落入Sh区域样本点的数量。
将球心x沿着偏移向量更新:

其中xs为偏移后的球心。将终止条件设为Mh(x)≤ε,ε为容许误差。
考虑到样本点个体的差异性,不同的样本点对Mh(x) 会产生不同的贡献度,因此,在基本的Mean Shift 算法中引入核函数和样本权重,偏移向量扩展形式为:
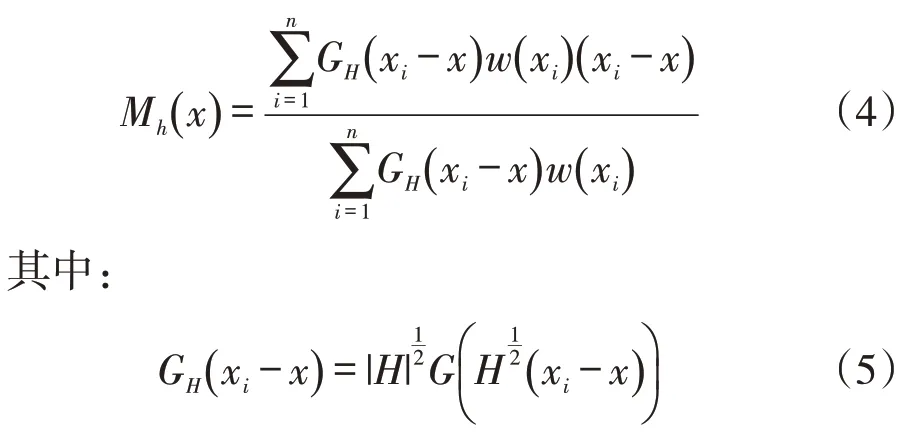
G(x)为单位核函数;H是一个正定的对称d×d矩阵,一般称之为带宽矩阵;w(xi)≥0 为样本点xi的权重值。
Mean Shift中,常用的两类核函数为:
(1)单位均匀核函数,见式(6),如图2(a)所示。
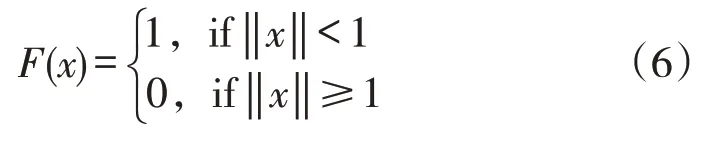
(2)单位高斯核函数,见式(7),如图2(b)所示。

在本文聚类方法研究中,距离中心点越近则对偏移向量的贡献度越大,表明不同的样本点对偏移向量的贡献度是不同的,而单位均匀核函数并不能反映这个特性,所以选择单位高斯核函数,如图2 所示。
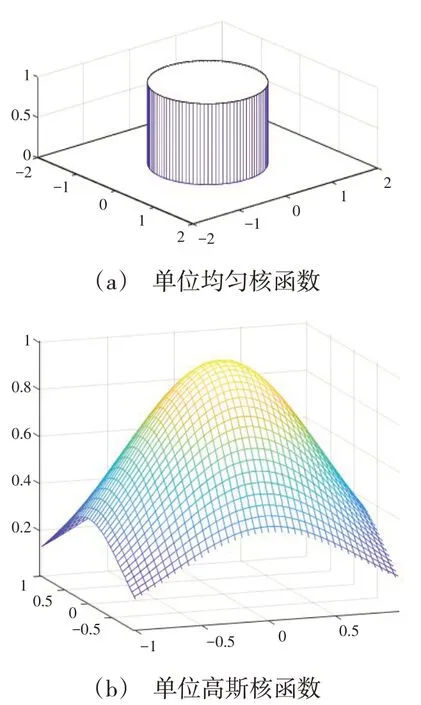
图2 单位核函数
Mean shift聚类基本流程如图3所示:
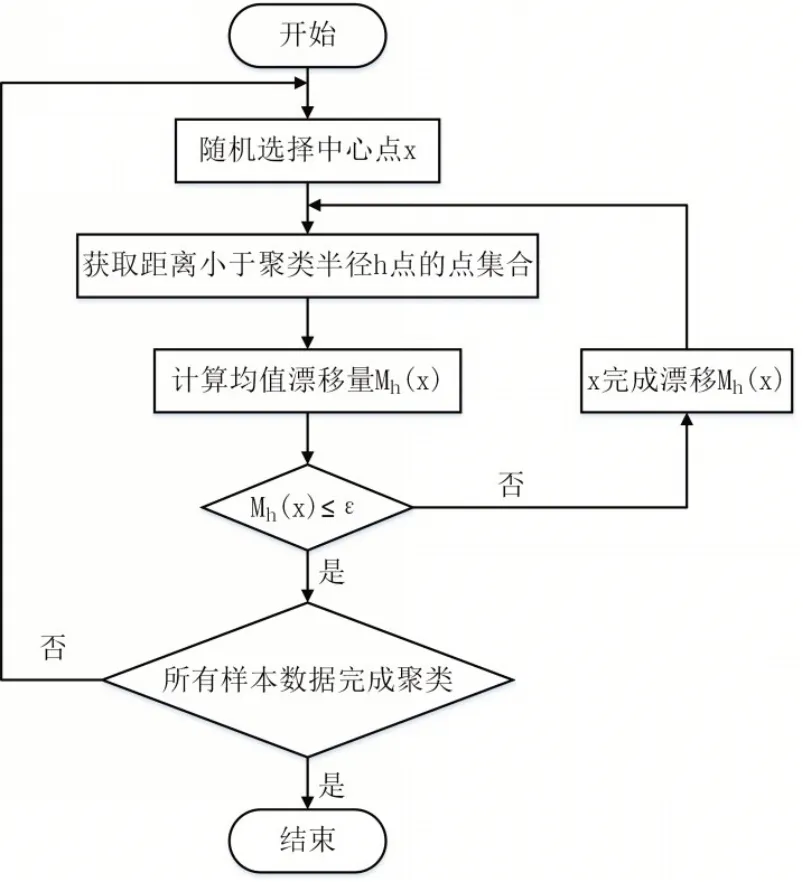
图3 Mean Shift算法流程图
(1)在样本空间随机挑选一个未分类的样本点x作为初始中心点。
(2)获取满足条件的样本点集合,记为Sh。
(3)以初始点x为中心,以x为起点和Sh集合的点为终点分别作向量,根据式(4)计算Mh(x)。
(4)判断Mh(x)是否满足终止条件,若满足,则结束循环,重新执行步骤(1)-(4),否则重复步骤(2)-(4)。
(5)直至所有样本数据都完成分类,结束算法,输出聚类分析结果。
2.2 居民日常出行样本数据权重值设置
住宅区作为一种参与居民日常出行最频繁的POI类型,距离住宅区的远近将直接影响居民是否方便将CDP 行程与日常出行相结合,从而影响CDP 的使用率,所以在为每个OD 样本点赋予权重值时,主要考虑样本点在规定区域内所包含的住宅区POI 数量和距离,即样本点在一定范围内所包含的住宅区POI点越多且与这些POI点的距离越近,则该样本点的权重值越大。具体计算公式见式(8)。
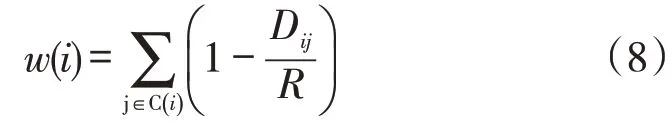
w(i)表示OD样本点i的权重值;C(i)表示OD样本点i在半径R内所覆盖住宅区POI 集合;Dij表示OD样本点i与C(i)中住宅区j的距离。
式(8)表示样本数据权重值由OD样本点覆盖的住宅区数量和与其距离决定。通过对OD 样本数据进行聚类分析,聚类簇中心可以反映出居民出行OD点分布规律,同时也能保证对住宅区的覆盖率,提高CDP使用的便利性和使用率。
2.3 最优聚类半径选取
本文采用统计分析方法选取最优聚类半径。首先,结合实际情况和参考文献选取最大聚类半径hmax和最小聚类半径hmin,然后以Δh为间隔取多组聚类半径hi,取每组聚类半径hi将样本点进行聚类分析。对每次聚类分析结果进行统计分析,将每次聚类后所得的聚类簇按照成员数量Ci进行降序排列,计算每个聚类簇成员数量在总样本数据中的占比Pi,见式(9)。

其中Pi为第i个聚类簇所含成员数量在总样本数据中的占比,Ci表示第i个聚类簇成员点个数,n表示形成聚类簇的数量。将Pi进行依次累加,见式(10),其中Pa为累加比例,k为累加的聚类簇数量。

若聚类簇成员较少,可判定该区域居民日常出行访问的频率较低,为了保证CDP 使用的便捷性和使用率,则此类聚类簇中心不适合作为CDP 选址点。故本文设置样本数据占比PT对此类无效聚类簇进行清洗。Pa与Ck的关系示意如图4 所示,即Pa=PT时,将对应第k个聚类簇成员数量Ck作为聚类簇的清洗条件,即当Ci≤Ck,则该聚类簇被清洗,反之保留。
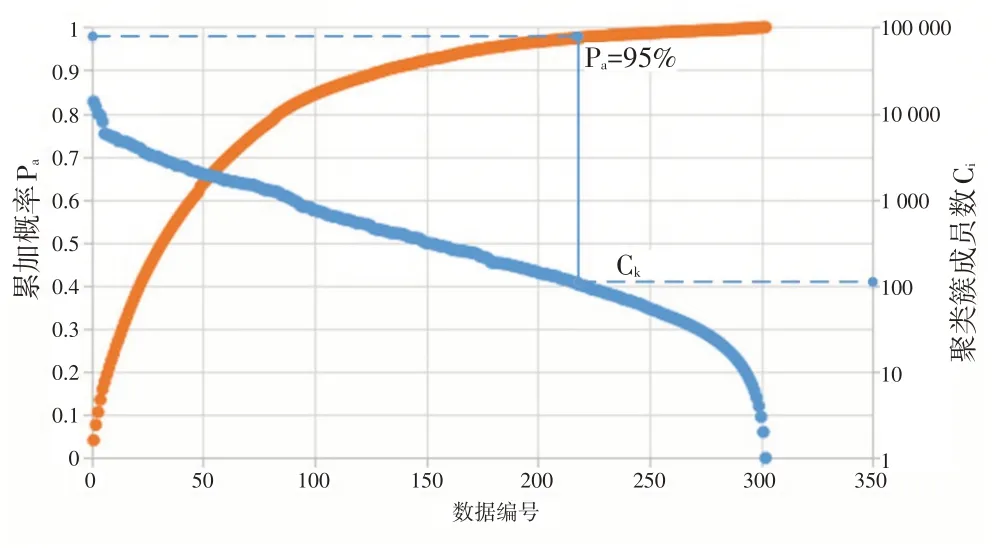
图4 Pa_Ck 关系示意图
将每组聚类半径依次进行聚类分析,统计每次聚类分析中的聚类半径h和对应的Ck值,最后将h和Ck数值进行函数拟合,得到拟合函数曲线,通过数据特性分析确定Mean Shift算法的最优聚类半径。
3 实例分析
3.1 数据准备
出租车作为一种重要的公共交通方式,其出行的起讫点完全由乘客决定,能够非常贴切地反映居民出行的规律。出租车与其他出行方式相比,其轨迹更易收集且数据量大,因此,本文将出租车运行GPS 轨迹数据作为实例分析的样本数据来源之一。选取山东省济南市历下区1 005 辆出租车一个星期的运营数据。数据的主要字段信息见表1,其中tflag表示是否有载客,即0表示空载,非0表示载客,将其数值由零变为非零或由非零变为零作为判定乘客上下车点的依据。将tflag数值突变时对应的经纬度进行提取,作为居民出行的OD 数据样本点,用于聚类分析。

表1 字段信息表
公交车作为上班族通勤最常用的交通方式,所以其运营数据能够充分体现上班族的出行规律,故选取了济南市历下区包含的共28个公交车站点的运营数据,根据乘客上下车刷卡信息,提取出乘客的上车点经纬度,与上面的出租车数据共同作为居民出行OD数据样本点。
将OD样本数据和历下区638个住宅区POI数据分别通过分布图和热力图直观地展示在百度地图上,如图5和图6所示,通过对比图5(a)和6(a)可知:OD样本点和住宅区POI点在千佛山等风景区区域中都没有分布;从大明湖公园到千佛山景区之间主要分布有商业区以及娱乐场所,所以,该区域表现为OD样本点热区,但住宅区分布却稀少。
由图5(b)和图6(b)可知,除了以上特殊区域,其余区域OD点热力分布与住宅区POI热力分布基本吻合。由此反映出OD点与住宅区分布具有相关性,以上特殊区域的分布情况也体现了二者也具有差异性。不同OD点对选址结果的影响不同,也证明了为OD点赋予不同权重值的必要性。
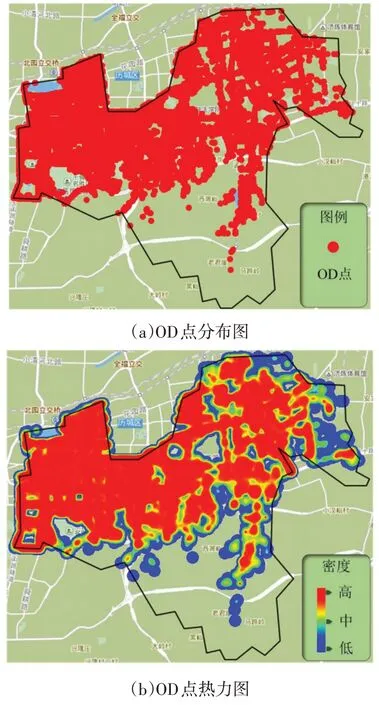
图5 历下区OD点分布情况
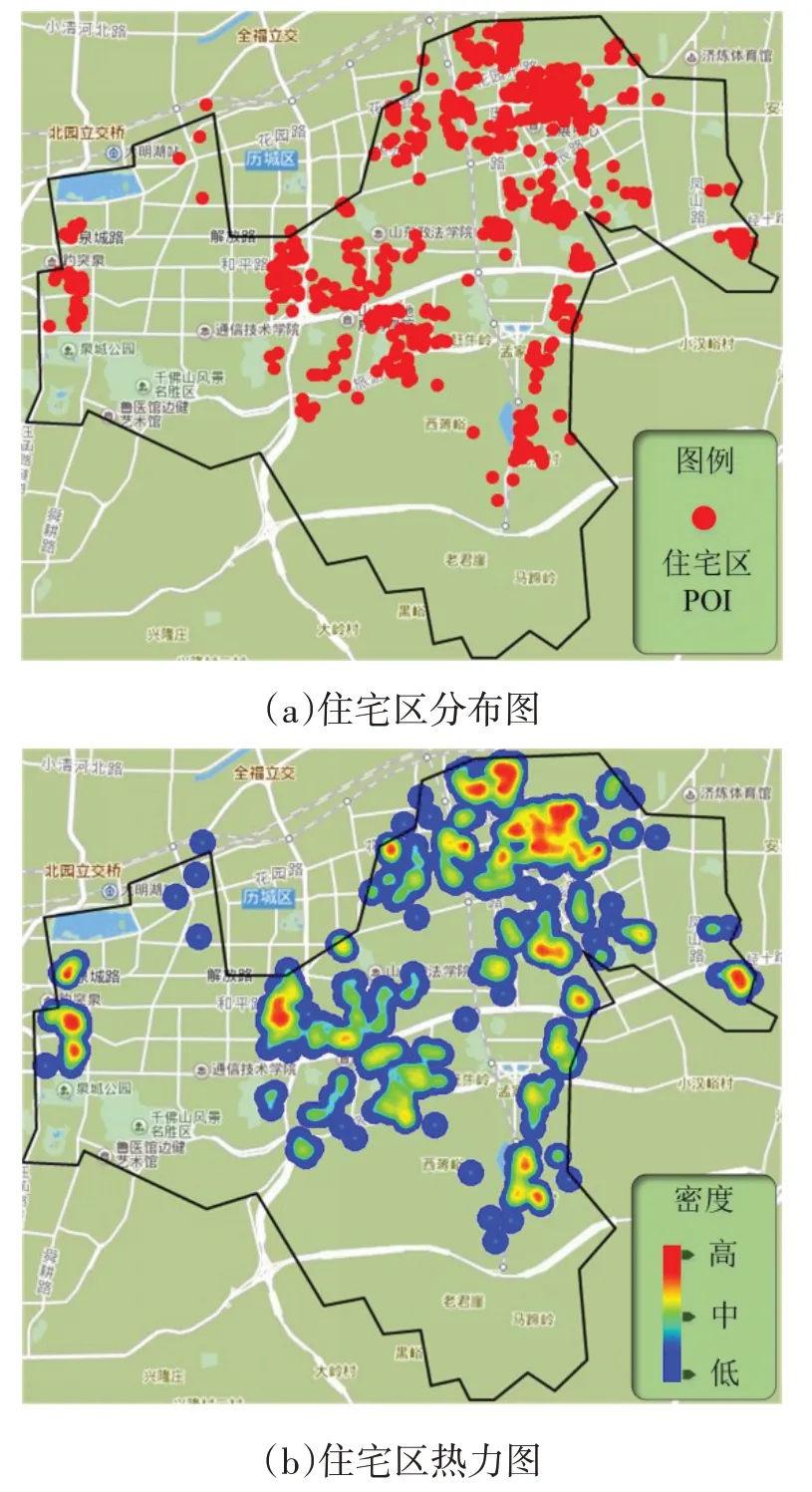
图6 历下区住宅区分布情况
3.2 聚类分析
根据肖卡飞[9]关于服务性公共设施服务半径与客户满意度关系的研究,500m 为客户普遍认为的最大可接受步行距离,超出这个距离客户会产生抵触心理,据此选取范围半径R=500m,代入式(8)计算每个OD 样本点的权重值。设置聚类半径系列hi,hmin=50m、hmax=800m和Δh=50m。考虑现有普通民用GPS 精度约为10m,设置容许误差ε=10m作为算法终止条件。分别完成对聚类半径系列hi的聚类分析,获取每次聚类分析后得到的Ck值,统计值见表2。
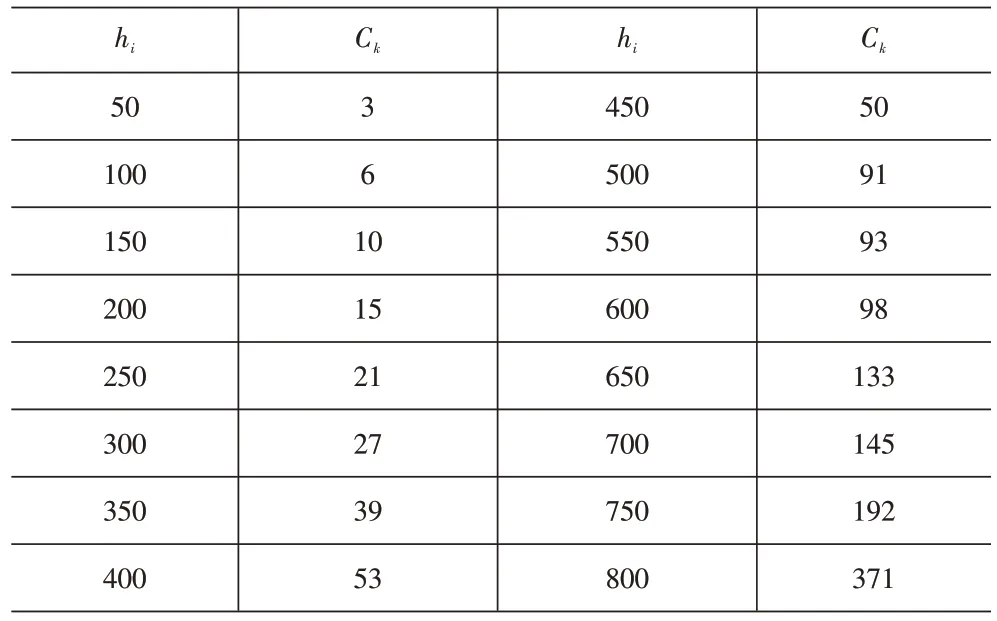
表2 hi-Ck 值实验数据结果
利用MATLAB 分析软件将得到的hi-Ck数据进行曲线拟合,拟合函数使用三阶多项式函数。所得拟合函数见式(11),拟合曲线如图7所示。
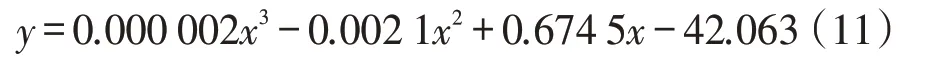
由图7可知,Ck随着hi整体呈递增趋势,但在不同hi范围,函数的斜率不同,反映了Ck随hi变化的快慢,当拟合函数的一阶导数为零时,表示函数变化趋于稳定,即此时hi小幅度变化,Ck变化量很小,故选择拟合函数一阶导数为零时的hi作为最优聚类半径。通过计算求得当拟合函数一阶导数为零时对应的hi分别为h1=249.5m和h2=450.4m。以这两个聚类半径分别进行聚类分析,得到的聚类结果见表3。通过将聚类结果进行对比分析,可知这两个聚类半径下聚类簇数量相差多达153 个,但对500m 范围内住宅区覆盖率相差很小,仅2.50%。考虑对物流体系建设成本的控制,故选择450.4m为最优聚类半径,可以较低的成本,实现对住宅区较高的覆盖率。
图7 hi-Ck 拟合曲线

表3 聚类结果数据对比
3.3 选址结果对比分析
将最优聚类半径下的聚类簇中心通过百度地图进行可视化展示,如图8(a)所示,将该结果与不为OD样本点赋予权重值的聚类簇分布结果进行比较,如图8(b)所示,可知加权值的聚类簇中心更加趋向于住宅区密集区域,极大地提高了对住宅区的覆盖率,满足本文CDP 选址的需求。不加权重值的聚类簇分布趋于平均分布,即使在没有住宅区分布的商业娱乐区依然有聚类簇中心点分布,违背了本文选址需求的初衷,也从侧面反映出赋予权重值的必要性。
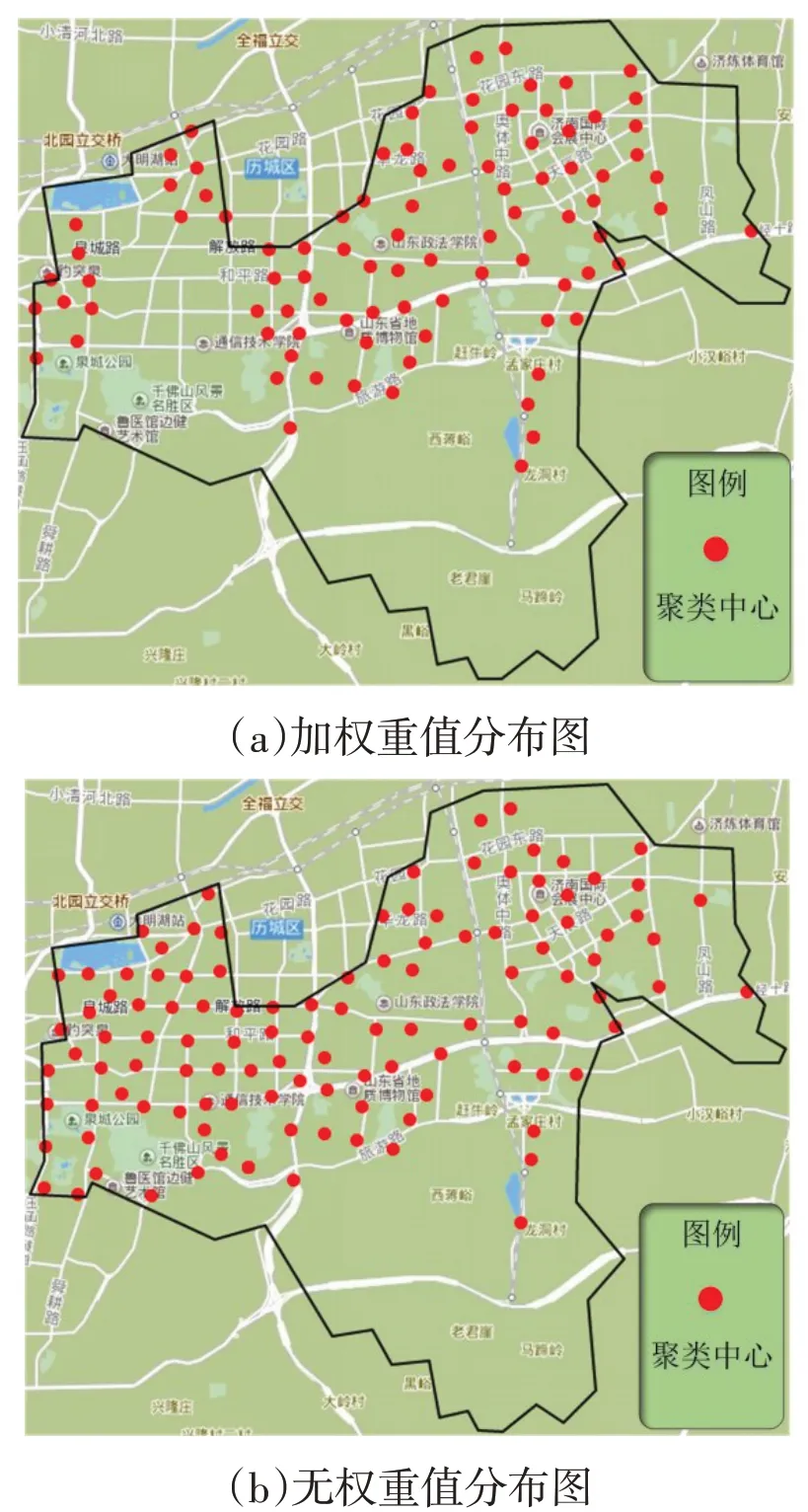
图8 聚类结果分布图
根据Liu C[10]提出的趋近于便利店和交通便利区域的调整原则,将不合理的CDP 设施地址备选点进行局部调整后,得到CDP 选址点91 个。菜鸟驿站作为目前我国最后一公里服务的典型代表,主要为消费者提供多元化的最后一公里配送业务,故选取了本文选址区域内所有菜鸟驿站站点,共93个,与本文选址结果进行数据对比分析,二者站点分布图如图9所示,对住宅区覆盖率对比数据见表4。经对比分析可知,本文选址结果中选址点的数量与菜鸟驿站站点数量相差不大,但相较菜鸟驿站本文选址结果对住宅区具有更高的覆盖率。
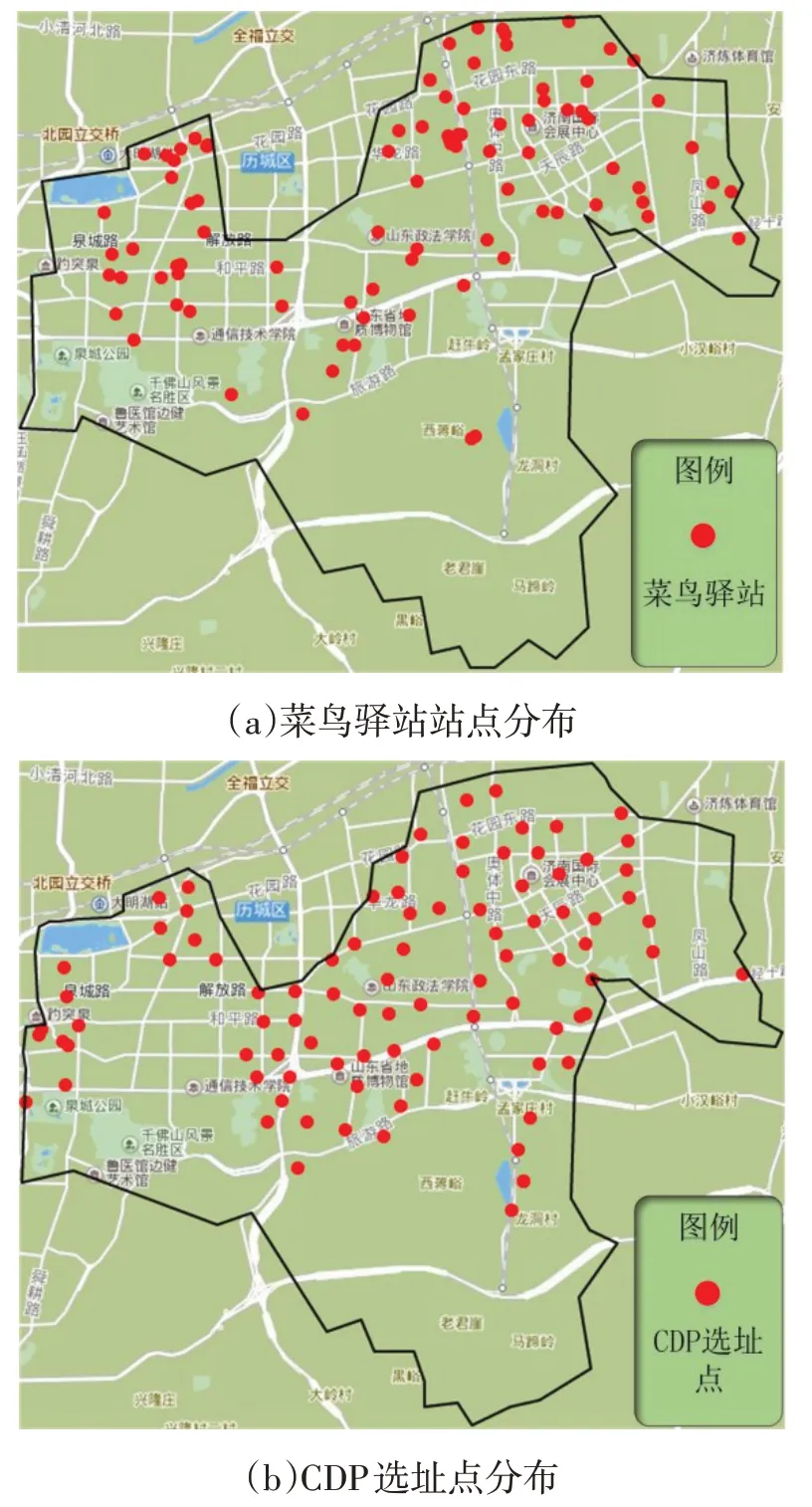
图9 选址点分布对比图
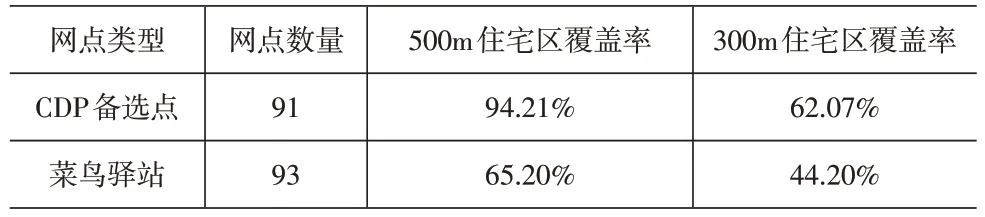
表4 住宅区覆盖率对比表
4 结语
本文通过使用济南市出租车和公交车的运营数据作为分析居民日常出行OD分布规律的试验数据,结合POI 分布进行了Mean Shift 聚类分析,最终实现济南市历下区的CDP地址的选取。本文将居民日常出行OD分布规律与CDP选址相结合,提高CDP的使用率,节约居民日常出行时间和行程。通过将本文的选址结果与菜鸟驿站网点分布情况进行对比,在相同的服务半径条件下,得到本文选址结果对POI的覆盖率更高,选址点数量也更少。最后,通过调整不合理的聚类簇中心点,在不改变聚类中心数量的情况下,提高了POI覆盖率,确定CDP选址点。
本文为最后一公里集中交付点选址提供了新的思路,也存在不足之处,同时也是以后致力要实现的,由于缺少相关数据的支撑,本文没有对CDP选址点容量进行研究,因为CDP 的容量和它所覆盖区域POI使用人数和频率的数据有关,本文尚未涉及相关数据。
猜你喜欢
矿产勘查(2020年7期)2020-12-25
铁道通信信号(2019年6期)2019-10-08
制造技术与机床(2019年6期)2019-06-25
小猕猴智力画刊(2018年7期)2018-08-08
现代园艺(2017年22期)2018-01-19
雷达学报(2017年6期)2017-03-26
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
互联网天地(2016年1期)2016-05-04
中国房地产业(2016年8期)2016-03-01
智能系统学报(2015年4期)2015-12-27
