
融合注意力机制的BERT-BiLSTM-CRF中文命名实体识别
2021-11-10 08:13勾艳杰张顺香
阜阳师范大学学报(自然科学版) 2021年3期
廖 涛,勾艳杰,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
引言
命名实体识别技术是自然语言处理中最基础的技术,在自然语言理解中起着至关重要的作用。命名实体识别就是在一段自然语言文本中,标注有意义的实体的位置,并将其划分到相应的实体类型中。
传统的命名实体识别主要采用构建规则模板或统计机器学习模型的方法。尽管这些方法也能够取得较好的识别效果,但需要一定的语言学知识或者人工抽取特征,通常泛化能力差。近些年,深度学习方法由于不需要使用大量的人工特征就可以取得优良的识别结果而受到广泛关注和使用。例如,陶源等人[1]提出了一种混合神经网络模型,在中文数据集SIGHAN2006 上取得了优良的识别效果。Qin Y 等[2]使用了双向长短期记忆网络和条件随机场来识别临床命名实体,在i2b2/VA开放数据集上获得了较好的识别效果。
然而,现有的深度学习方法无法表征一词多义且未能充分挖掘文本的潜在语义特征。针对上述问题,本文提出了融合注意力机制的BERTBiLSTM-CRF 中文命名实体识别方法。该方法不仅可以获得丰富语义的词向量,还可以增强当前信息和上下文信息之间的语义相关性,挖掘文本之间的潜在语义特征,取得了不错的识别效果。
1 相关工作
早期采用基于规则的方法,通过规则模板来提取相应的信息。孙誉侨等人[3]通过使用基于规则的方法进行命名实体识别,在招标数据的识别中取得了较好的F1 值。孔玲玲等人[4]提出一种面向无标注数据的中文命名实体识别框架,取得了较好的F1 值。但是以上方法中,规则的构建需要大量专业的语言学知识,熟悉各实体出现的规律,并且还要注意规则之间的冲突与局限性,存在时间效率低、可移植性弱等缺点。
考虑到基于规则的方法具有上述问题,国内外学者提出了基于统计机器学习的方法。该方法自动抽取真实文本中的命名实体,构成规律,然后再进行语言模型的训练,使其自动识别命名实体。LONG 等人[5]通过CRF(Conditional Random Field)和字典相结合的方法进行命名实体识别,取得了较好的识别效果。王路路等人[6]使用CRF 和半监督学习的方法进行维吾尔文命名实体识别,取得了较好的识别效果。然而,该方法虽然降低了对语言学知识的要求,但还是需要人工抽取特征。
近年来,深度学习以其不需要人工干预,可以自动提取词语特征的优点,成为命名实体识别的主流研究方法。张聪品等人[7]使用LSTM(Long Short-Term Memory)和CRF 对电子病历进行命名实体识别,F1 值达到了93.85%。殷章志等人[8]通过一种融合字词BiLSTM(Bi-directional?Long Short-Term Memory)模型的方法,取得了较好的F1 值。Bin Ji 等[9]通过BiLSTM-CRF 模型对电子健康记录中400 份住院病案进行识别,取得了较好的F1 值。刘宇鹏等人[10]引入了CNN(Convolutional Neural Networks),提出了BiLSTM-CNNCRF的命名实体识别模型,可以获取到字符和词语级别的表示,在医疗领域和新闻领域取得了较好的F1 值。冀相冰等人[11]引入了注意力机制(Attention),提出了Attention-BiLSTM 模型,取得了不错的识别效果。Luo 等[12]提出了atts-BiLSTMCRF的命名实体识别模型,在身体部位,疾病和症状等实体中取得了较好的识别效果。
然而,深度学习方法没有考虑到相同的词语在不同的语句中具有不同的含义的问题。而且,一段文本中,不同的词语对识别的结果也会产生不同的影响,从而导致识别的准确率不高。谷歌发布的 BERT(Bidirectional Encoder Representations from Transformers)预训练语言模型[13],可以充分表征一词多义。此外,注意力机制为文本中的不同文字分配不同的权重,增强了当前信息和上下文信息之间的潜在语义相关性。受此启发,为了能够更好的表达一词多义并且充分挖掘文本之间的潜在特征,提出了本文的研究方法。针对中文命名实体识别,主要做了如下贡献:①引入BERT 预训练语言模型,用来表征一词多义;②将注意力机制与深度学习模型结合;③通过实验验证了本文提出的方法具有不错的识别效果。
2 融合注意力机制的BERT-BiLSTMCRF 模型
2.1 模型概述
本文提出的模型主要分为4 层。第一层是BERT 层,由于BERT 可以表征一词多义,语料经过BERT 预训练语言模型,获得含有丰富语义的词向量;第2 层是BiLSTM 层,BiLSTM 使用前向LSTM 和后向LSTM,捕捉文本的上下文特征;第3 层是Attention 层,对不同的上下文信息给予不同的关注程度,为其分配不同的权重,捕捉文本之间的潜在语义特征;第4 层是CRF 层,CRF 可以为预测的标签添加一些约束来保证预测标签的合法性。利用CRF 对输出结果进行解码标注,对实体进行提取分类。模型整体结构如图1 所示。
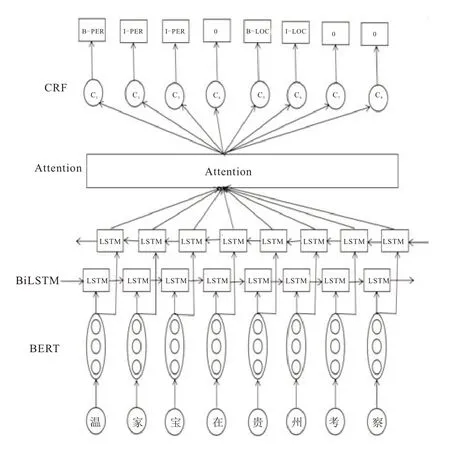
图1 融合注意力机制的BERT-BiLSTM-CRF 模型
2.2 BERT 层
BERT 模型采用双向Transformer 作为编码器,并使用开放域语料库进行预训练。谷歌开源实现了两个版本的BERT 模型,分别是BERT Base,BERT Large。二者本质是一样的,区别在于参数的设置。BERT Base 是十二层的,而另一个是二十四层的,训练时间长。本文实验采用的是BERT Base 版本。BERT 模型的网络结构如图2所示。
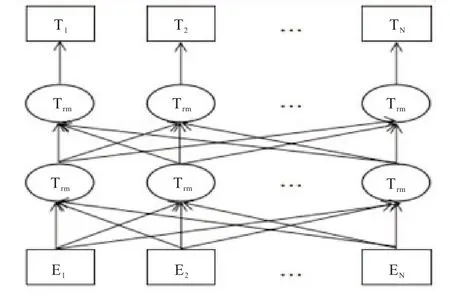
图2 BERT的网络结构
2.2.1 BERT 输入表示
对于任意序列,先进行分词处理得到分词文本序列;然后对此序列的部分词随机Mask,在序列开头添加特殊标记[CLS],句间标记[SEP摘要此时序列的每个词的输出Embedding 由3 部分组成:Token Embedding (词向量)、Segment Embedding(句子切分向量)和Position Embedding(位置向量)。将序列向量输入到双向Transformer 进行特征提取,最后得到含有丰富语义特征的序列向量。BERT 模型输入示例如图3 所示。
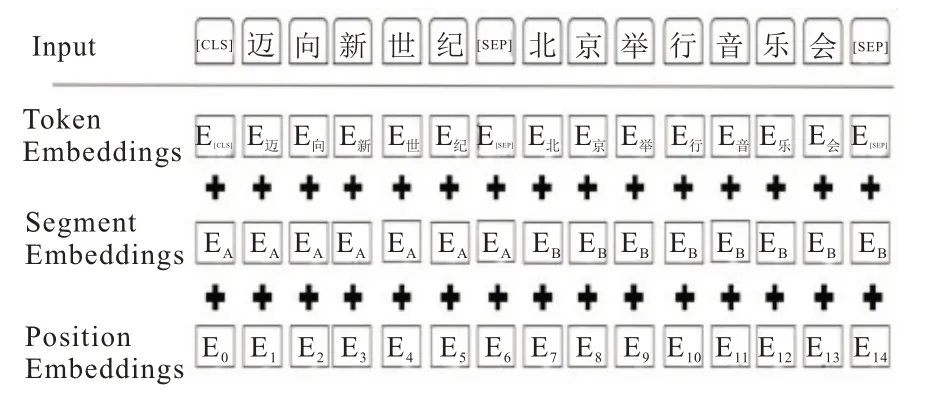
图3 BERT 预训练语言模型输入
2.2.2 BERT 模型预训练
BERT 模型使用:Masked 语言模型和下一句预测进行模型预训练。
Masked 语言模型,其思想来自英语的完形填空。训练过程中,每个序列随机掩盖15%的标签。比如“党中央国务院关心西藏雪灾救灾工作”这句话中的“雪”会出现以下三种情况:1、80%的可能性用[MASK]直接替换所选字。如:党中央国务院关心西藏[MASK]灾救灾工作。2、10%的可能性把所选字随机替换成一个字。如:党中央国务院关心西藏西灾救灾工作。3、最后10%的可能性不进行任何改变。掩盖完成后,通过上下文内容对被掩盖的单词进行预测。
下一个预测是为了获得粗粒度(句子)级别的关系,这一任务是在上一任务的基础上进行的。首先,在预训练语料中随机选择两个句子;例如句子a:党中央国务院关心西藏[MASK]灾救灾工作。句子b:灾区各级政府全力组织抗[MASK]。然后,预测句子b 是不是句子a的下一句;最后,使用IsNext/NoNext 标签标记。在这一任务中,句子b 有一半的概率为句子a的下一句,也有一半的概率不是其下一句。
2.3 BiLSTM 层
2.3.1 LSTM
传统的神经网络,没有记忆的功能。即上一时刻的有关信息,无法用于下一时刻。递归神经网络却有这一功能。然而,当预测点与依赖的相关信息相距较远时,就难以学到相关信息。LSTM就可以很好的解决此问题,学习到长期依赖信息。其单元结构如图4 所示。
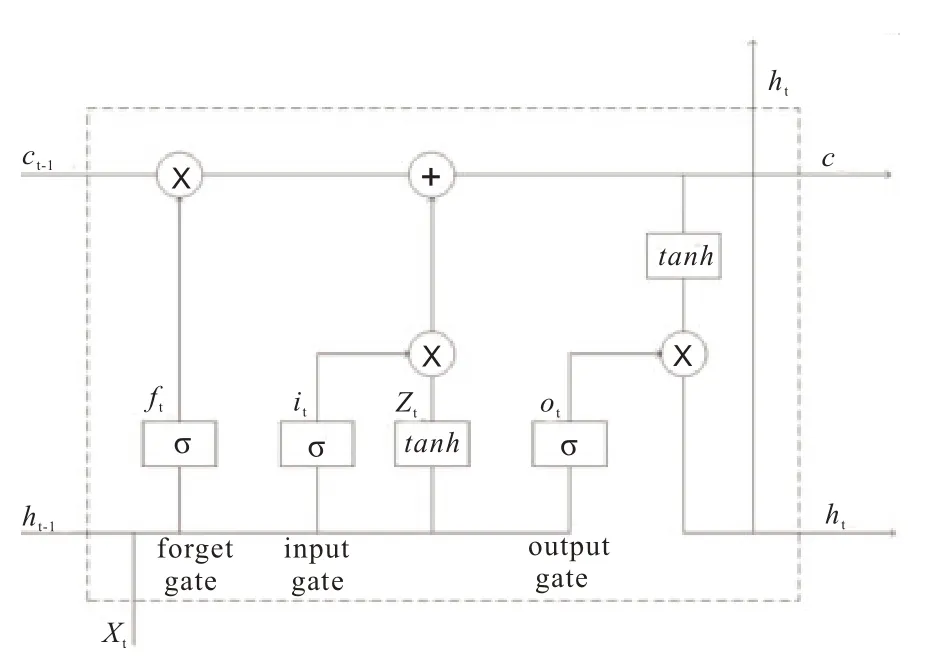
图4 LSTM 单元结构
LSTM的计算公式如下:
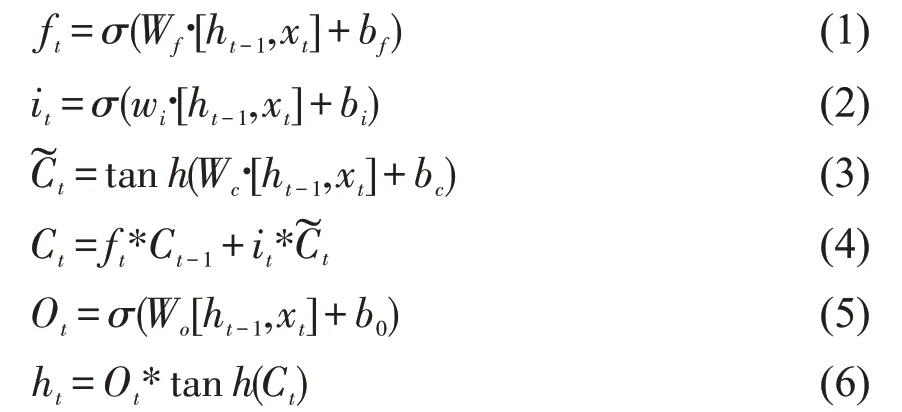
其中,xt是输入,it,ft,ot分别为输入门、遗忘门及输出门,σ 为Sigmod 函数,tanh 为双曲正切函数。W 是权重矩阵,b 是偏置向量,为细胞的临时状态,~Ct为t 时刻的状态,ht为t 时刻的输出。
2.3.2 BiLSTM
单向的LSTM 模型只能通过上文信息推测当前结果,无法同时利用下文信息。为了弥补这一不足,模型采用BiLSTM。通过前向LSTM 和后向LSTM,充分利用上下文信息。其具体结构如图5 所示。
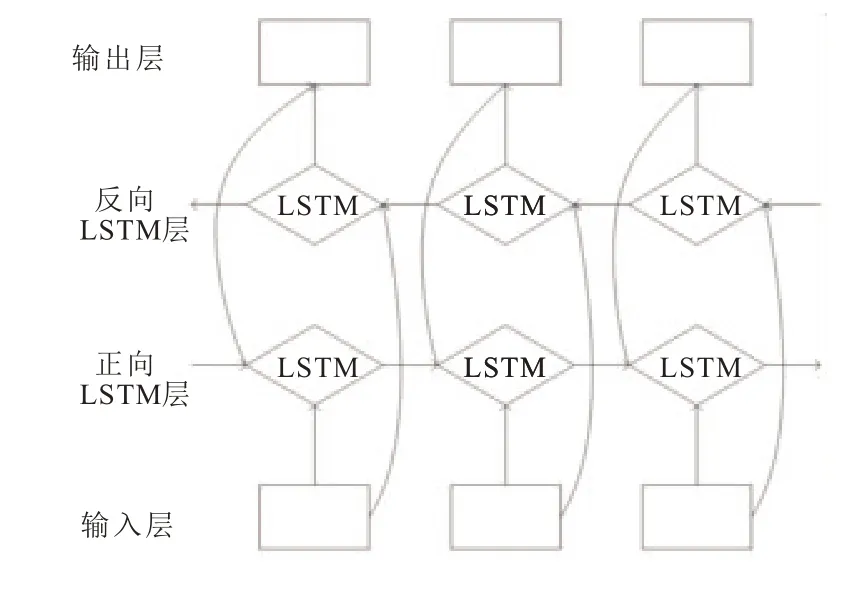
图5 BiLSTM 模型结构
在中文命名实体识别中,将由BERT 模型得到的词向量序列输入到前向LSTM 中,其计算过程使用上述公式,得到前向特征信息ht。与上述方式类似,可以得到后向特征信息h’t,再将ht 与h’t 按位拼接,得到最终的隐藏状态Ht,即Ht=[ht,h’t],其中[,]是拼接符号。这样就汇总了双向语义特征。
2.4 注意力机制
BiLSTM 可以得到上下文信息,但没有突出当前信息和上下文信息之间的潜在语义相关性。因此,在BiLSTM 网络后加入注意力层,挖掘文本之间的潜在语义特征。例如“印度尼西亚总统苏哈托呼吁全国人民团结起来”。“全国人民”对识别出人名实体“苏哈托”作用较小,而“印度尼西亚总统”对识别出人名实体“苏哈托”有较大的意义。注意力机制会给“全国人民”分配较少的注意力,给“印度尼西亚总统”分配较多的注意力,有助于人名实体“苏哈托”正确识别出来。
在中文命名实体识别任务中,利用注意力机制进行文本特征提取的过程如下:首先,把词向量序列输入到BiLSTM 网络中进行上下文特征的提取;然后,利用注意力机制给上一步获得的不同的特征向量,赋予不同的权重,提取文本潜在语义特征;最后,生成包含文本上下文特征和潜在语义特征的联合特征向量序列。
首先,计算注意力权重vt。ht 是BiLSTM 层输出的特征向量。公式如下:

然后,计算注意力权重概率向量Pt。
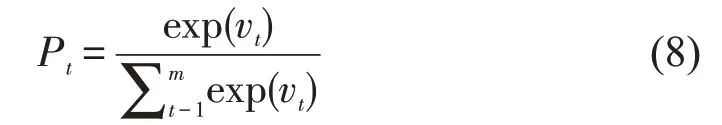
最后,计算注意力权重配置at。

2.5 CRF 层
常用的序列标注模块方法有两种:一种是条件随机场模型,另一种是使用softmax 函数直接进行分类。条件随机场在预测标签时,充分的考虑了文本的上下文关联性,为预测标签添加一些约束来保证预测标签的合法性。因此,模型选择了条件随机场来进行序列标注。
在本次命名实体识别中,CRF 层的参数为(m+2)*(m+2)的矩阵A,m 为标签个数。Ai,j表示由标签i 到j的概率。P 为BiLSTM 层输出的权重矩阵。Pi,j表示矩阵中第i 行第j 列的概率。对于输入序列x={x1,x2,…,xn}和标记序列y={y1,y2,…,yn},模型可定义为:
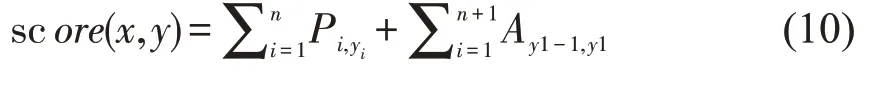
对所有可能的序列路径进行归一化,得到预测序列y的概率:
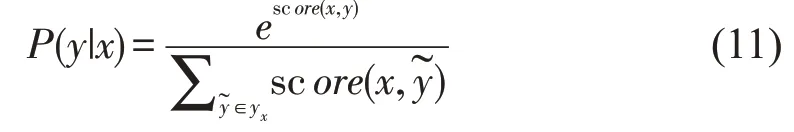
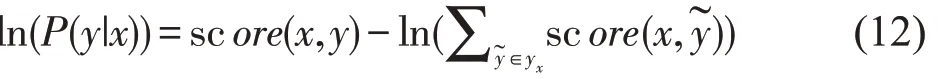
解码后得到最大概率的输出序列:

3 实验结果与分析
3.1 实验数据预处理及标注
采用1998 年上半年的人民日报语料进行相关实验研究。经统计,该语料已经标注好了34 种词性类别。实验主要识别人名、地名、组织机构名等实体。由于BIO 可以逐字标记,因此本文使用BIO 进行标记,B 表示实体的第一个词,I 表示实体中间词,O 表示不是实体。因此要识别的标记有:B-PER,I-PER,B-LOC,I-LOC,B-ORG,I-ORG,O。将标注好的数据集以7:2:1的比例划分为训练集、测试集和验证集。具体预料数据如表1 所示。
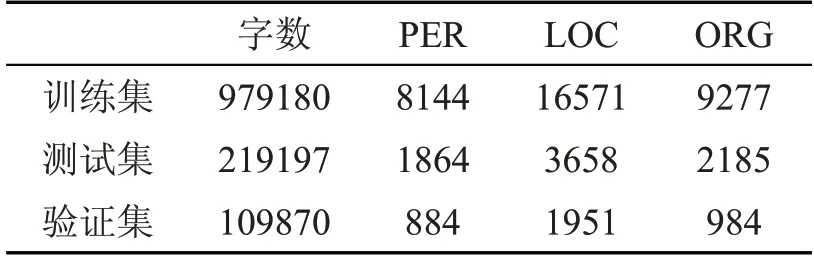
表1 1998 年人民日报语料数据(单位:字)
3.2 实验结果
3.2.1 不同模型的性能对比
在数据集上,采用LSTM、LSTM-CRF、BiLSTM、BiLSTM-CRF、BERT-BiLSTM-CRF 和本文方法进行性能分析。人名、地名、组织机构名的识别结果分别如表2 至4 所示。
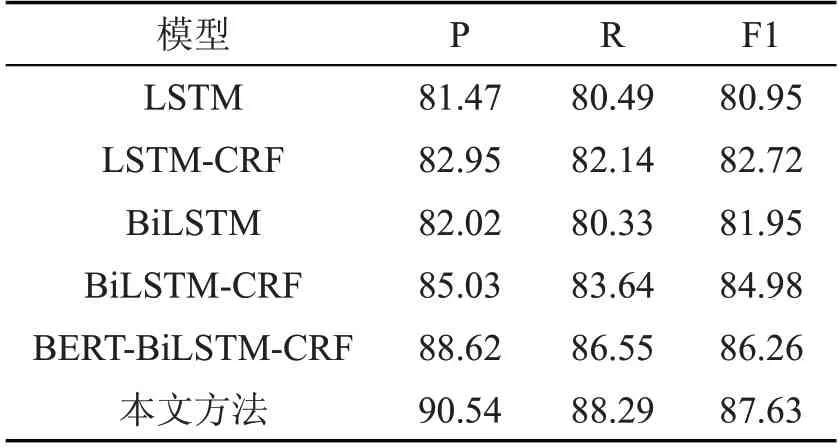
表2 人名识别各模型效果对比(单位:%)
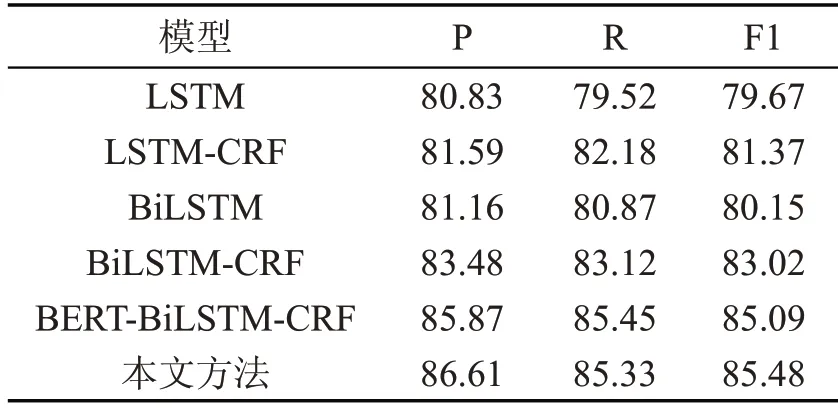
表3 地名识别各模型效果对比(单位:%)
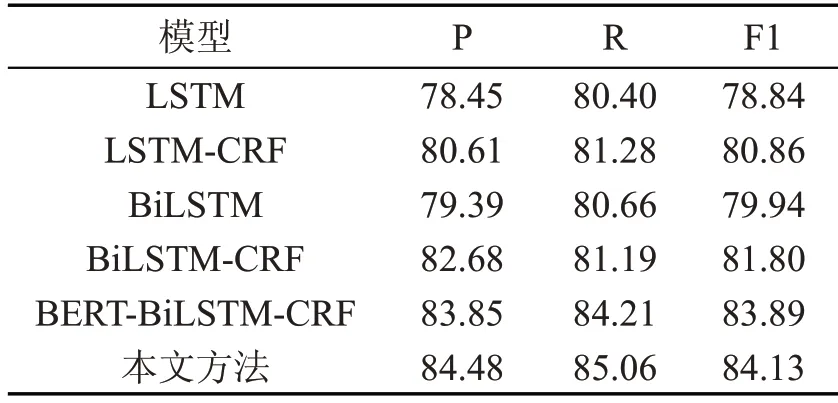
表4 机构名识别各模型效果对比(单位:%)
对比LSTM 模型和LSTM-CRF 模型的实验结果,可以看出增加了CRF 模块后,F1 值提高了。这是因为CRF 能充分利用相邻标签的关联性。
对比LSTM-CRF 模型和BiLSTM-CRF 模型的实验结果,可以看出BiLSTM的表现优于LSTM,因为LSTM 只能利用上文信息,无法利用下文信息。而BiLSTM 能同时利用上下文信息。
对比BiLSTM-CRF 模型和BERT-BiLSTMCRF 模型的实验结果,可以看出F1 值取得了比较明显的提高,这是因为BERT 模型能够深层次地提取文本语义信息,充分表征一词多义。
对比BERT-BiLSTM-CRF 模型和本文模型的实验结果,可以看出准确率取得了明显提高,归因于注意力机制使模型更专注于寻找与当前输出更关的输入信息,强化了当前信息与上下文信息之间的潜在语义关联性,有利于识别出不易识别的实体,提高了识别的准确率。
对比三个表,在所有模型中,人名、地名实体的识别效果优于组织机构名。这是因为大多数的机构名都有简称,包含大量的未登录词,且其长度极不稳定,导致识别难度很大。
3.2.2 本文模型与他人方法性能对比
将本文方法与目前主流方法进行了实验,结果如表5 所列。
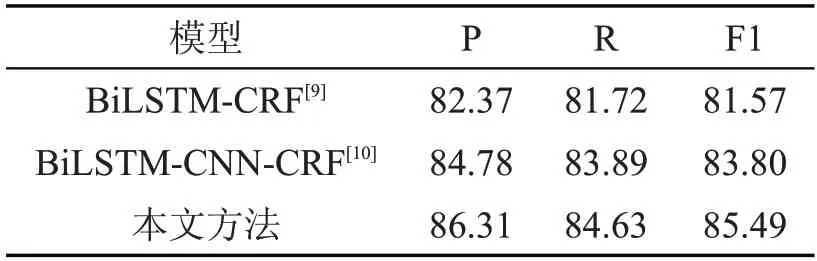
表5 本文方法与目前主流方法识别效果对比(单位:%)
BiLSTM-CRF 与BiLSTM-CNN-CRF 实验结果对比,可以看出后者的识别效果更好。这是因为CNN 可以进行字符级别的特征提取,提高了模型的识别结果。相比于增加CNN,本文方法融合了注意力机制,强化了当前信息与上下文信息之间潜在的语义关联性,能够捕捉到文本间的潜在语义特征,提高了模型的准确率。此外,还引入了表征能力更强的BERT 模型,使得本文方法在中文命名实体任务上取得了较高的F1 值。
4 结束语
针对目前深度学习方法无法表征一词多义且未能充分挖掘文本潜在语义特征的问题,提出了融合注意力机制的BERT-BiLSTM-CRF 中文命名实体识别方法,BERT 作为预训练语言模型,不仅可以获取词语或字符级别的特征信息,而且还可以挖掘句法结构及语义信息;加入注意力机制,使模型更专注于与当前输出有关的信息,捕捉文本的潜在语义信息。实验表明,此方法使得P、R、F1值均有了较大的提升,在命名实体识别上具有较好的识别效果。但是命名实体识别任务仍有提升空间。比如,实验的语料库规模较小。因此,下一步工作是解决语料规模较小的问题,对语料库进行数据增强,以进一步提升命名实体的识别效果,展示出该模型具有较好的通用性,可移植性较好。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
当代陕西(2019年5期)2019-03-21
东方女性(2018年3期)2018-04-16
21世纪商业评论(2018年3期)2018-03-02
散文诗(2017年17期)2018-01-31
中国诗歌(2017年12期)2017-11-15
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
长江学术(2016年4期)2016-03-11
