
基于机器学习的网络拥塞控制研究
2021-11-05 02:48管毓瑶
上海电力大学学报 2021年5期
李 婧, 管毓瑶
(上海电力大学 计算机科学与技术学院, 上海 200090)
互联网发展到今天的规模,人们的生活和工作越来越离不开计算机网络。近年来,网络流量的空前增长对互联网的性能提出了更高的要求。许多新兴应用对吞吐量、可靠性和延迟性都提出了更高的要求。虽然强力部署更高容量的有线和无线链路的方法有助于缓解这个问题,但更可行的方法是重新考虑更高层协议的设计,以便更有效地利用增加的物理层链路容量。
拥塞控制问题是一个经典的网络课题,在互联网的发展中,扮演着重要的角色。网络拥塞控制主要用于调节和控制网络数据传输需求和网络传输/处理能力之间的不匹配引起的拥塞问题,确保用户之间有效和公平地共享网络资源。
网络拥塞控制的一个重点问题是讨论丢包与拥塞之间的关系,并根据感知到的拥塞来采取缓解拥塞的调控。TCP的拥塞控制经过了多次的迭代和改进,每一次都经过研究者的精心设计和大量实验验证,且方案的设计基于对来自网络的特定反馈信号的预定义动作的硬连线映射。然而,随着网络变得更加复杂化和动态化,设计最佳“奖励—行为”映射变得更加困难。
近年来,机器学习、深度学习和强化学习的兴起,给拥塞控制提供了新的思路,利用强大的学习能力来学习网络交互的行为引起了广泛关注。因此,针对基于机器学习的网络拥塞控制协议展开研究,对于优化网络性能具有重要的意义。
1 拥塞控制模型
现有的拥塞模型可分为两种:在端系统上,网络数据包的到达速度超过了位于接收端的缓存能力,导致数据包排队甚至溢出,产生拥塞现象;在网络中,设备(如交换机)的存储转发能力不及数据包的到达速度,从而引起了排队甚至丢包,也产生了拥塞现象。
发生在端系统上的拥塞模型,可以通过协调接收窗口大小来解决,而经常讨论的拥塞控制问题都是针对发生在网络设备上的拥塞模型。网络中的拥塞问题更为复杂,对此产生了大量的经典的拥塞控制方案,如Tahoe,Reno,New Reno,CUBIC,BBR等,包含了慢启动、拥塞避免、快重传和快恢复等机制。
2 国内外研究现状及发展动态
1986年10月,互联网第一次出现了的“拥塞崩溃”事件。研究者在TCP协议中引入了慢启动、双向时变估计和AIMD(Additive Increase Multiplicative Decrease)控制规则等一系列机制[1]来应对拥塞,实现了网络的稳定性和可用性。目前,国内外的研究者针对TCP拥塞控制展开了深入的研究,取得了一系列的研究成果。从算法的原理进行分类,可以将有代表性的解决方案分为基于规则的解决方案、基于路由反馈的解决方案和智能解决方案3类。
2.1 基于规则的解决方案
网络拥塞问题出现以来,研究者们设计了许多基于规则的算法,根据规则可以将这些算法分为3类:基于丢包的算法、基于时延的算法以及基于丢包和时延的算法。
基于丢包的算法包括Tahoe,Reno,NewReno,BIC-TCP,TCP-CUBIC等算法,适合早期简单的网络环境,但存在在未检测到丢包时,不断增大发送窗口探测网络带宽,过度占用路由器缓冲区的缺点。
JACOBSON V等人[1]设计了Reno算法,引入了一系列机制(即慢启动、拥塞避免、快速重传和快速恢复)。Reno算法对拥塞窗口(Congestion Window,CWnd)的控制如图1所示。它是由更原始的Tahoe算法改进而来。这些机制已经成为许多拥塞算法方案的基石。Reno算法的缺点在于:Reno算法是以数据包的丢失作为拥塞的信号,当检测到丢包时,就会重传所有丢失与检测到所丢包事件的所有的包[2]。NewReno是基于Reno的改进算法,利用一个确认字符(ACKnowledge Character,ACK)来确定部分发送窗口,立即重传余下的数据包,避免了Reno在快速恢复阶段的许多重传超时,提高了网络性能。但是NewReno算法的缺点是在高速网络中不能有效利用带宽。

图1 Reno算法对拥塞窗口的控制
高速网络中,对于单个丢包,经典的AIMD算法需要经过多轮往返时间(Round-Trip Time,RTT)才能恢复到拥塞窗口,然后再进行乘法约简,导致信道利用率较低。BIC-TCP算法把拥塞控制视为一个搜索问题,利用二分查找算法来调整拥塞窗口[3]。BIC的缺点是每进行一次二分查找,需要一个RTT的时间,因此不同RTT数据流查找的频率不一样,即RTT小的数据流更易获得较高的带宽。
TCP-CUBIC算法是BIC-TCP的升级版本,利用一个包含凹、凸两部分的三次函数代替BIC-TCP的凹和凸窗口增长部分,既模拟了BIC-TCP的窗口调整算法,又解决了RTT的不公平问题,因为其拥塞窗口的增加依赖于两个连续拥塞事件之间的时间[4]。
上述Tahoe算法、Reno算法、NewReno算法、BIC-TCP算法和CUBIC算法都是以数据包的丢失作为拥塞信号来做出调整以应对拥塞,适合早期简单的网络环境。在未检测到丢包时,不断增大发送窗口去探测网络的带宽,而当检测到丢包时,便认为链路拥塞,并减小发送窗口。
基于时延的算法通过对连接的RTT的监测来确定拥塞窗口的调整,对链路拥塞的响应比基于丢包的算法更早,其中包括TCP-Vegas,TCP-Westwood,FAST TCP等算法。但仅将时延作为拥塞信号是片面的,时延变大不一定是由于网络拥塞。
TCP-Vegas[5]用于测算在RTT上期待的吞吐量和实际吞吐量的差值δ。当δ小于低阈值,认为该路径并不拥挤,因此提高了发送速率。当δ大于高阈值,这是一个强烈拥挤的信号,TCP-Vegas重新降低发送速率;否则,TCP-Vegas将保持当前的发送速率。通过将当前拥塞窗口除以最小RTT来计算预期吞吐量,该最小RTT通常包含路径不拥塞时的延迟。对于每个往返时间,TCP-Vegas通过将发送的数据包数量除以采样的RTT来计算实际吞吐量。
TCP-Westwood[6]通过计算返回ACK的速率来估计端到端可用带宽,对于包丢失,不像TCP盲目地将拥塞窗口减少到原来的一半,而是将慢启动设置为一个估计数。这种机制是有效的,特别是在无线链路上,频繁的信道损失被错误地解释为拥塞损失,因此TCP错误地减少了拥塞窗口。
FAST TCP[7]根据一个路径上的往返延迟和包丢失来确定当前拥塞窗口的大小。通过快速更新发送速率来实现对网络拥塞的控制。该算法利用RTT估计路径的排队时延。当时延远低于阈值时,算法会大幅增加窗口;当时延越接近阈值时,算法会缓慢降低增加速度;当延迟超过阈值时,先缓慢地降低窗口,然后急剧地降低窗口。当包丢失时,快速地将拥塞窗口减半,并像TCP一样进入丢失恢复。
基于丢包和时延的算法采用协同的方式,将基于丢包的方法与基于时延的方法结合起来进行拥塞控制,代表算法有TCP-Veno,TCP-Illinois,Compound等。这种兼顾丢包和时延的方法有利于发送端感知链路的拥塞情况,因此后来的拥塞控制算法的思路大多沿用了这个拥塞信号。这类算法依然建立在一些基本假设之上的;当网络环境变得更加复杂时,这些规则将不再适用。
TCP-Veno[8]确定的拥塞窗口大小非常类似于TCP-NewReno,但它使用TCP-Vegas的延迟信息来区分非拥塞损失。当包丢失发生时,如果延迟增加所推断的队列大小在一定的阈值内,这是随机丢失的强指示,TCP-Veno将拥塞窗口减少20%,而不是50%。
TCP-Illinois[9]采用排队延迟的方法,在窗口增量阶段实时确定增加因子α和乘减因子β。准确地说,TCP-Illinois在平均延迟d值很小时,设置一个较大的α值和一个较小的β值,用来表示拥塞不是迫在眉睫;而当d值很大时,考虑到即将到来的拥堵而设置了一个较小的α值和一个较大的β值。通过动态调整α和β值实现更好的对带宽的探索。
Compound[10]是Windows操作系统中的速率控制算法。当链路未充分利用时,它的拥塞窗口会急剧增加。Compound的关键思想是在标准TCP中添加一个可伸缩的基于延迟的组件。这个基于延迟的组件有一个可伸缩的窗口增长规则,不仅可以有效地使用链接容量,还可以通过感知RTT中的变化及早响应拥塞。如果检测到瓶颈队列,则基于延迟的组件可以优雅地降低发送速率。
2016年,由Google提出的BBR[11]算法在拥塞信号中完全无视了丢包,第一次指出了传统拥塞控制算法的问题所在。BBR算法收敛点分析如图2所示。
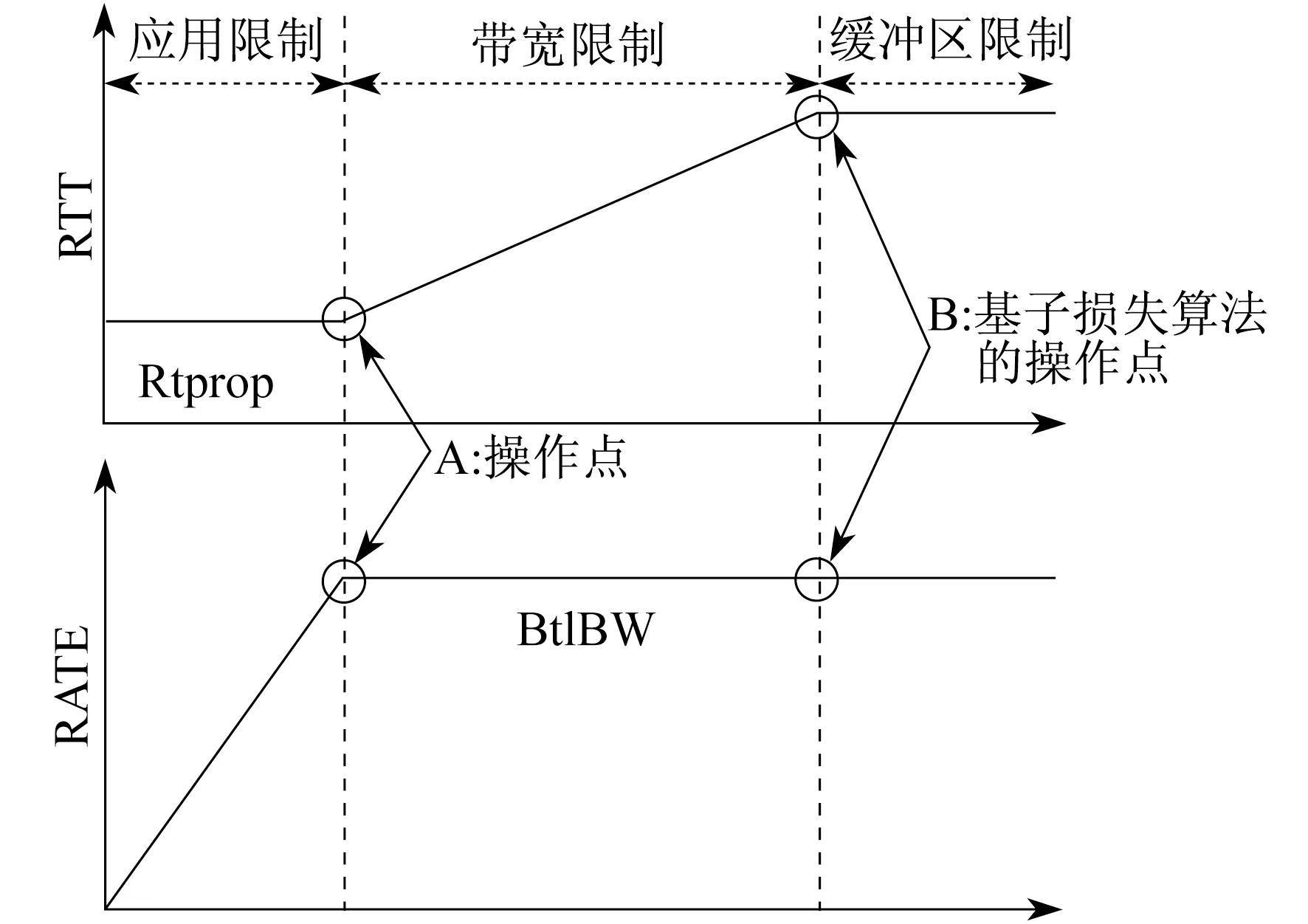
图2 BBR算法收敛点分析
图2中,传统的基于丢包信号的Reno和CUBIC等算法基本等网络状态已经达到B点才开始采取措施解决拥塞问题,然而传输速率早在A点就不再增加,A点到B点这段时间的数据包的发送是徒劳的,BBR算法实现了在A点处收敛,在拥塞即将发生的“隐患”时期及时降低了网络发生拥塞的可能性。
2.2 基于路由反馈的解决方案
基于路由反馈的解决方案涉及到拥塞控制过程中的交换机或路由器。引入显式拥塞通知(ECN)作为拥塞信号的损失替代[12]。在主动队列管理(AQM)方案中,例如RED和CoDel等,路由器在初始拥塞时标记或丢弃数据包。
RED是部署在分组交换网络中的网关,用于避免拥塞。网关通过计算平均队列大小来检测初始的拥塞。网关可以通过丢弃到达网关的数据包或在数据包报头中设置1 bit来通知网络连接拥塞[13]。
CoDel用于解决Internet中的缓冲区膨胀问题[14]。CoDel的工作方式是在每个包接收和排队时向其添加一个时间戳。当数据包到达队列头部时,计算在队列中花费的时间;它是对单个值的简单计算,不需要锁定,因此速度很快。如果一个包在队列中花费的时间高于一个定义的阈值,该算法设置一个定时器在dequeue中丢弃一个包。只有当时间窗口内的排队延迟超过阈值且队列至少持有一个MTU的字节数时,才会执行此删除操作。
这些方法需要修改路由器和中间设备,在实际应用中会比较困难,无法扩展到大量TCP流。
2.3 智能解决方案
随着人工智能的蓬勃发展,基于机器学习的解决方案已经成为一种针对所有问题的筛选,拥塞控制也不例外。
Remy将机器学习的思路第一次用在拥塞控制的速率决策问题上[15]。Remy的核心思想是通过一个目标函数定量判定算法的优劣程度。在生成算法的过程中,针对于不同的网络状态采取不同的方式调节发送窗口,反复修改调节方式,直到目标函数最优。最终会生成一个网络状态到调节方式的Map。在真实网络中,可以根据Table和网络状态,直接选取调节发送窗口大小的方法。但是,Remy最大的问题就是过分依赖训练数据,当真实网络情况有所差异时,性能会大幅下降。
PCC是一种面向性能的拥塞控制,每个发送方不断地观察其行为和经验的性能之间的联系,使其能够始终如一地采取导致高性能的行为[16]。PCC设定了一个目标函数,公式为
ui(xi)=Ti·Sigmoid(Li-0.05)-xiLi
(1)
式中:Ti——第i个发送端的吞吐量;
Sigmoid( )——神经网络里的激活函数;
Li——第i个发送端的丢包率;
xi——第i个发送端的发送率。
根据这个目标函数,PCC算法不断尝试新的发送率,直到目标函数值达到最优。PCC是一种在线学习的算法,优点在于在线调整发送速率以适应当前网络状态,缺点是抛弃了过去学到的经验,收敛速率慢。
PCC Vivace[17]是PCC的升级版,PCC Vivace在目标函数中结合了时延,公式为
(2)
0
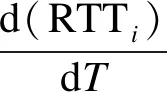
相比于PCC,PCC Vivace有更好的TCP友好性,收敛速度更快。
上述算法都是以基本机器学习思路解决拥塞控制问题。近年来,一些研究者尝试用深度学习和强化学习[18]解决网络拥塞问题。
QTCP[19]是一种基于Q-learning的TCP拥塞控制协议。在线观察周围网络环境的情况下,该协议能够自动识别最优CWnd的变化策略。为了加快学习过程,该算法使用了函数逼近——Kanerva算法。这是一种有效的方法,可以减少使用抽象状态来表示搜索和探索所需状态空间的大小。Kanerva在编码时考虑了整个状态空间由一个精心选择的状态空间子集表示,根据这个子集存储训练值并评估派生策略,从而显著降低了训练的内存消耗和计算复杂度。
TCP-Drinc[20]是一个基于DRL(深度强化学习)的代理,在发送端执行。这里结合的是知名的DQN[21]算法。在DQN算法中,将强化学习中的状态和动作的历史转换存储在经验池中,然后引入一个附加的目标网络来计算目标值。此协议认为,TCP拥塞控制的一般问题应视为一个延迟的分布式决策问题,并且TCP拥塞控制是一个部分可见马尔可夫决策过程。因此,考虑到了在深度强化学习中,一个动作at开始影响环境之前可能有个时延,agent收到rewardr(st,at)也有个时延。将此时延设计成了特征输入到深度卷积神经网络(Deep Convolutional Neural Network,DCNN)中。
在TCP-Drinc的设计中,分为如下步骤:特征的选择、reward的设置、状态和动作的定义、经验池的形式、基于DCNN的agent的最终设计。TCP-Drinc所应用到的DCNN结构如图3所示[20]。

图3 DCNN结构
ns3-gym是为强化学习应用于网络研究的第一个框架[22]。它是基于OpenAI开发的gym和ns3网络模拟器开发的工具包。ns3-gym将ns3仿真表示为gym框架中的环境,实现来自仿真器的实体的状态和agent的交互,以满足agent的学习目的。
3 结 语
现有的基于规则的拥塞控制协议仅利用丢包、时延等信息作为拥塞信号,并不能很好地掌握网络带宽的利用情况,适应日渐复杂的网络环境。虽然目前已提出了不少基于机器学习算法的网络拥塞控制协议,但由于网络结点的反馈信息十分有限,发送端无法及时探知网络真实环境的拥塞状态,该领域仍旧是个开放的课题。采用更合适的手段来描述网络环境拥塞状态,更准确地探索可用带宽,从而更精确地调节CWnd,不仅可以保证网络的稳定和高效运行,同时也是保证各种其他互联网服务质量的基础和前提。
猜你喜欢
计算机与数字工程(2022年3期)2022-04-07
民用飞机设计与研究(2020年4期)2021-01-21
科学导报·学术(2020年26期)2020-10-21
通信电源技术(2020年8期)2020-07-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
探索科学(学术版)(2020年1期)2020-03-26
电子制作(2019年23期)2019-02-23
军营文化天地(2018年2期)2018-12-15
物联网技术(2018年8期)2018-12-06
