
面向视频结构化的细粒度车辆检测分类模型*
2021-11-04 05:49金立生胡耀光蒋晓蓓郭柏苍王武宏
汽车工程 2021年10期
石 健,成 前,金立生,胡耀光,蒋晓蓓,郭柏苍,王武宏
(1.北京理工大学机械与车辆学院,北京100081;2.燕山大学车辆与能源学院,秦皇岛066004)
前言
目前实现无人驾驶的技术方案可分为两种,一种是偏向个体的自主式无人驾驶,另一种是强调协同的网联式无人驾驶[1]。两种方案都以环境感知模块作为基础,为后续的规划决策提供支撑。从现有研究和已落地的成果来看,基于雷达的感知技术已日益成熟[2],但由于其存在着对目标实例感知较差的缺点,无法对复杂交通场景进行有效识别,因此,基于摄像头的感知技术是实现场景理解的关键。当前基于摄像头的感知主要围绕着深度学习所展开,其面向交通参与者的多类任务(分类,检测,跟踪,分割等)极大地提升了对复杂交通场景的识别效率。
在无人驾驶环境感知模块中,车辆检测分类是基础而重要的工作。国内外对于交通场景下的车辆识别进行了众多研究。可以简要总结为:从检测视角划分,面向自主式无人驾驶的自车视角(ego view)和面向网联式无人驾驶的鸟瞰路侧视角(topdown view);从检测算法划分,改进单阶段或两阶段检测算法以提升检测精度与速度,融合其他信息(如点云信息,深度信息等)的检测算法以提升检测效果。
文献[3]中提出一种改进SSD(single shot multi⁃box detector)算法,引入Inception⁃like block代替原始SSD中额外特征层来处理多尺度车辆检测,从而增强对小型车辆的检测,在鸟瞰视角下得到了较好的检测效果。文献[4]中提出一种改进YOLOv3算法,通过使用MobileNetV2替换Darknet⁃53作为特征提取的骨干网络,实现了模型轻量化,对自车视角下的3类车辆进行了有效检测。文献[5]中针对两阶段检测算法Faster⁃RCNN中候选区域生成网络(RPN)模块在进行目标检测时对目标特征提取不够充分的问题,提出一种基于改进RPN的Faster⁃RCNN网络SAR图像车辆目标检测方法,与传统RPN相比,其准确率更高,泛化性能更强。文献[6]中提取前车局部二值特征、Haar⁃like特征和方向梯度直方图特征的融合特征作为支持向量机分类器输入,结合卷积神经网络模型进行级联检测,获得了较好的车辆检测效果。文献[7]中提出一种“多层网格法”用来确定LSTM的超参数,并利用基于改进长短时记忆神经网络自适应增强算法(LSTM⁃AdaBoost)的多天气车辆分类方法,在多种复杂天气下对车辆进行了有效的检测与分类。文献[8]中设计了一种单目深度估计方法,将RGB信息转化为深度模态信息,利用RGB图像和深度图像作为输入,进行级联检测,提高了车辆检测性能。文献[9]中在雷达点云的基础上,提出了一种新的以视觉信息为导向的生成器(pro⁃posal generator),利用PointNet++学习点云的局部特征,并改进了交并比(IoU)预测分支附加到网络中,使得三维车辆检测的效果得到较大提升。
针对上述文献可以发现以下3点问题:第1,多数研究都围绕检测和分类算法开展,对算法工程化应用未作详细探讨,且由于算法研究与实际需求场景存在的差异性较大,使得当前的算法工程化难以落地;第2,由于深度学习模型易受数据维度和数据量制约,因此多数研究都以公开数据集中的粗粒度标签为基础,进行后续算法的调优和验证,但在细粒度车辆分类上的研究不够深入(细粒度的车辆分类是指大类下的子类识别,例如,一般只将车辆粗粒度的分为小型汽车、卡车和公交车,不会在小型汽车中细粒度的划分出轿车和SUV等),这使得复杂交通环境下的场景理解难以深入;第3,一般研究只在算法和模型上给出了理论上的论证,但从环境感知模块的整体技术结构方案上都未作说明,尤其是在后续输出如何与决策规划等模块的耦合联动上未作明确阐述。
基于以上分析,本文中从面向网联式无人驾驶的视角出发,提出使用视频结构化算法作为路侧端感知策略,通过对应用环境进行拆解,对视频结构化框架进行设计,并在此基础上,提出适用于本文视频结构化算法的细粒度车辆检测分类模型。对轻量化的细粒度车辆检测分类具有较强的研究价值,对无人驾驶环境感知技术方案的设计和实现具有一定的工程意义。
1 视频结构化算法设计
1.1 视频结构化算法与逻辑
视频结构化算法多用于安防与智能监控[10-11]领域,其核心思想是对视频图像中关注的人、车、非机动车等目标提供更深层次的结构化解析,如出现在视频中人的样貌、衣着,车辆的类型、颜色等。而在当前的无人驾驶环境感知任务中,实现复杂交通环境的场景理解是关键且必要的。因此,视频结构化从任务实现的角度是适用的,并且在保证视频结构化稳定准确输出的前提下,可以利用输出结果,为后续决策控制模块提供支撑。在面向网联式的无人驾驶环境感知的技术方案中,对于路侧端设备有着较高的计算需求,且与设计成本存在着较难平衡的关系。综上,如何定义适用于网联式无人驾驶的视频结构化场景并设计各算法模型在视频结构化之间的逻辑,是视频结构化算法在工程实现中亟需解决的难题。
1.2 面向路侧端的视频结构化框架设计
视频结构化的基础是通过训练得到精度高,速度快,泛化性好,鲁棒性强的轻量化深度学习模型,而其难点在于以下两点。
首先,通常来说,单阶段检测算法和两阶段检测算法在检测速度和检测精度上难以平衡。单阶段检测算法在检测速度上有优势,但在检测精度上差于两阶段检测算法。
其次,深度学习受数据集数量和质量的影响很大,手工标注数据的成本过高,而当前基于弱监督和半监督标注的标注精度还有待提高[12]。
视频结构化通过调用整合不同深度学习模型,可以较好地解决过度依赖数据标注的问题,但其带来的新挑战是:(1)多深度学习模型的堆叠使得轻量化模型的任务更加紧迫;(2)由于计算资源的限制,各模型间的逻辑关系需要通过硬件平台连续组织调试,使得模型工程化的要求更加严苛。
视频结构化作为一个系统性输出,其对计算资源的分配和要求是十分严苛的,需要考虑的不仅包含模型的训练和优化,更需要考虑模型的移植和加速,因此不同硬件平台下的处理能力(如FLOPS)和编译工具(如NCNN/MNN)都是需要考虑的重要内容。
本文中设计了一种面向路侧端的视频结构化框架。具体的框架结构如图1所示。
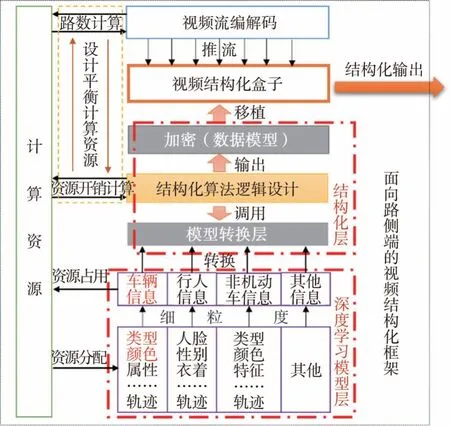
图1 面向路侧端的视频结构化框架
通过训练不同深度学习模型来突破数据集限制(例如,标注限制,数据量限制等),通过组合多深度学习模型来丰富细粒度信息,通过设计算法策略来稳定输出有效内容。利用深度学习模型层,结构化层与计算资源的交互、申请与分配使得结构化输出更加合理稳定,实现复杂交通场景的有效理解。
2 细粒度车辆检测分类模型
车辆检测分类是实现复杂交通场景理解的基础,探究适用于视频结构化的轻量化细粒度车辆检测分类模型具有理论研究意义和实际应用价值。现阶段,常用的轻量化模型方法是使用轻量级的网络代替单阶段和两阶段检测算法中较重的网络作为特征提取的骨干网络(例如,用MobileNets或ShuffleNet代替YOLO系列中的Darknet网络)。但经过实际的工程化模型测试,类似于MobileNetV2代替Darknet-53得到的改进模型,由于其中含有大量的1×1和3×3卷积,频繁申请交换内存,使得网络前向推理速度不能达到符合预期的在视频结构化中应用的速度。因此,本文中使用“检测+分类”的思想,利用YO⁃LOv4[13]作为基础检测算法,并使用剪枝策略对所得模型进行压缩处理,使用ResNet18作为分类网络的骨干网络,最后将两模型级联得到细粒度的车辆检测分类模型。
2.1 基于剪枝优化YOLOv4的车辆检测模型
YOLO系列[14-16]算法是主流的单阶段检测算法。YOLOv4在算法理论上集成了很多优秀的思想,且进行了大量实验论证,因此是目前最新、效果最好的版本。其较YOLOv3的主要改进在于,在使用YOLOv3头部的基础上,使用CSPDarknet⁃53(网络结构如图2所示)替换了Darknet⁃53作为骨干网络,并利用SPP模块增加了感受野,在数据增强和激活函数等处理方式上都进行了调整。
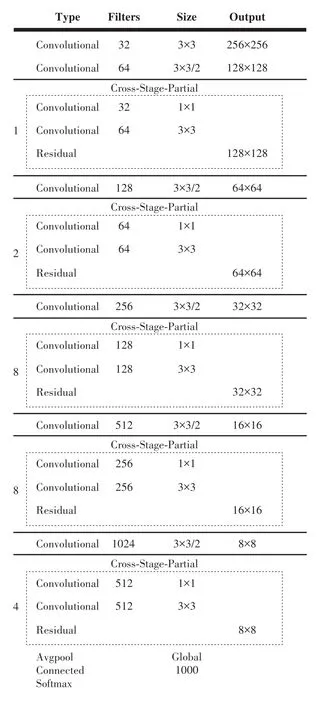
图2 CSPDarknet⁃53网络结构
剪枝作为模型压缩的重要手段之一,可以分为结构剪枝和非结构剪枝,由于非结构化剪枝需要定制化软硬件的支持,因此,本文中采取结构化的手动剪枝策略[17-20]。
通道剪枝是目前常用的剪枝策略,本文中通过调整通道稀疏性来实现灵活性和易操作性的平衡。由于通道剪枝需要修减与通道所关联的所有输入与相关连接。因此,无法对预训练模型进行权重剪裁。针对此问题,在每一个通道上都引入了一个乘以通道输出的尺度因子γ,通过对网络权重和γ的联合训练,对γ进行稀疏正则化处理。而后利用γ进行通道剪枝,并微调剪枝后的网络。γ的引入公式为
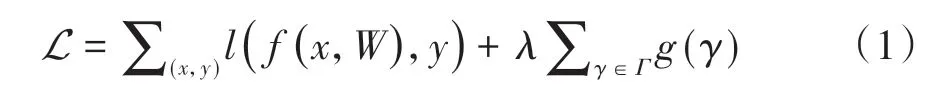
式中:(x,y)为训练数据标签的输入与输出;W为训练的权重,可认为整体为常规卷积神经网络训练的损失函数;g(γ)为稀疏函数;λ为平衡因子。
具体的优化流程可表示为图3。
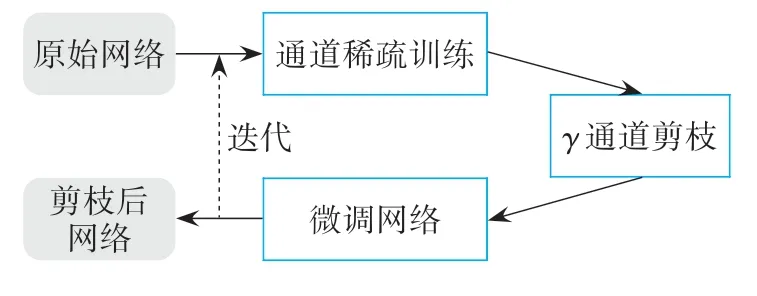
图3 通道剪枝流程
通道剪枝的本质是删除“不重要”通道上所有的输入与输出连接,因此,可以通过通道剪枝获得一个较窄的网络,由此进行模型的轻量化。可以将γ作为中间变量,且由于其与网络权重共同优化,网络可以识别出“不重要”的通道,去除这些通道不会对泛化性能产生很大的影响,如图4所示。
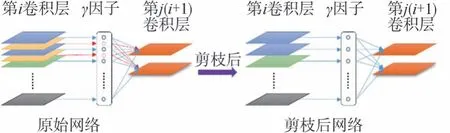
图4 网络剪枝示意
批处理归一化(batch normalization,BN)[21]被看作是目前的标准方法来实现快速收敛和获得更好的泛化性能。利用BN层使用小批次(mini-batch)数据将内部激活函数正则化,设zin和zout为一个BN层的输入与输出,B为当前的小批次的Batch,那么BN层可表示为

式中:μB和σB是在B下的输入激活的平均值和标准差;γ和β是可被训练的尺度和变换参数,这两个参数在理论上提供了将正则化激活函数线性转换回任何尺度上的可能性。一般来说,BN层都会被放在卷积层的后面,因此,本文中直接在BN层使用γ因子用于剪裁通道,从而实现通道剪枝。在网络剪枝优化以后,重新对网络进行微调。得到基于剪枝优化的YOLOv4车辆检测模型。
2.2 细粒度车辆分类模型
对于视频结构化来说,细粒度属性是实现结构化输出的关键内容。本文中在考虑车辆相关信息的基础上,将车辆种类(type)分为16类,车辆颜色(color)分为12种,具体属性如表1和表2所示。本文中通过细粒度的车辆类型和颜色组合基本可以覆盖当前交通场景下所需理解的所有车辆。
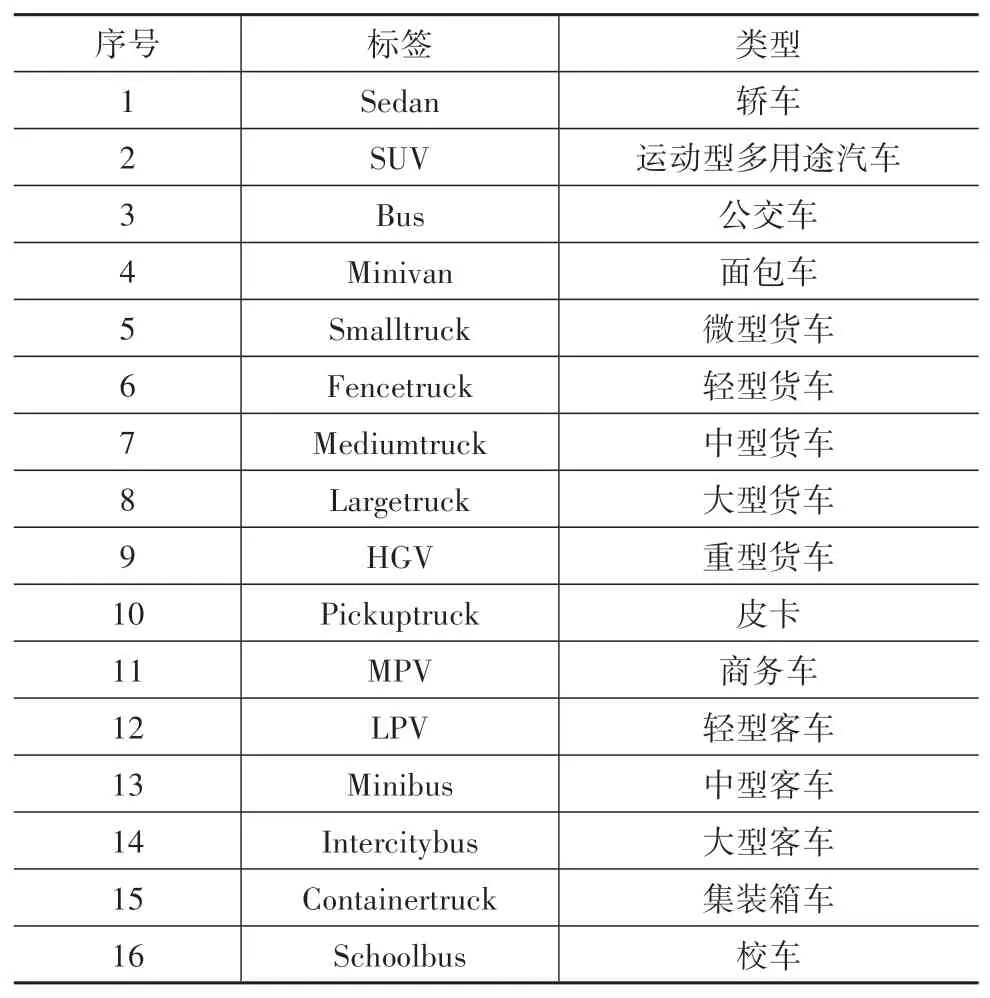
表1 细粒度车辆类型
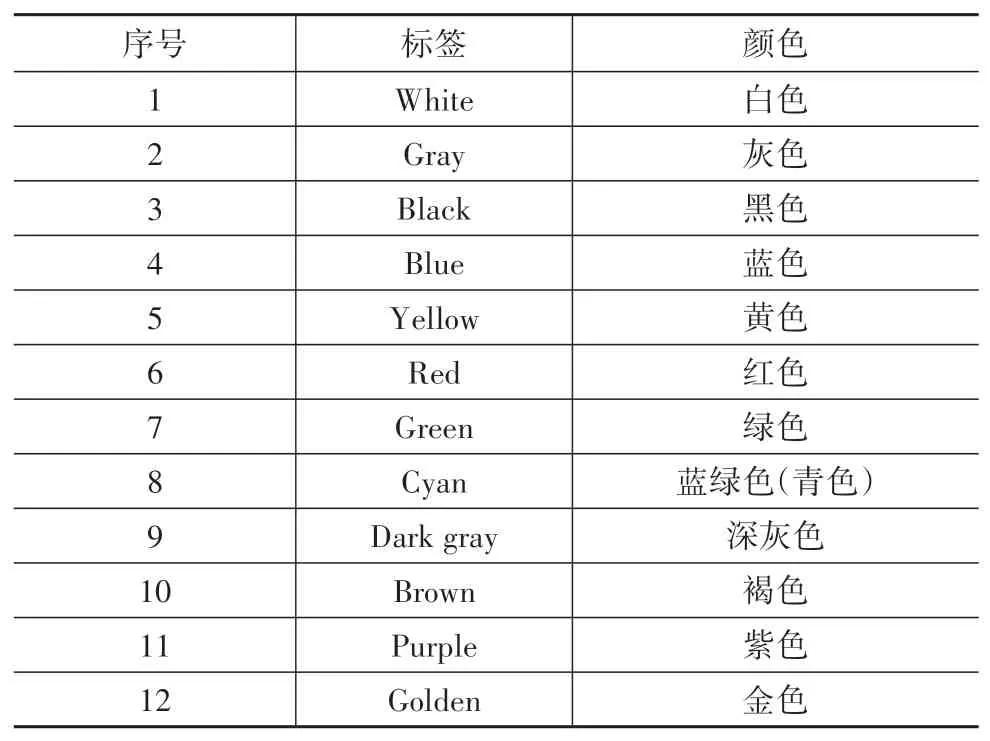
表2 细粒度车辆颜色
在车辆分类模型中,采用ResNet18作为特征提取的骨干网络[22],其网络结构示意如图5所示。
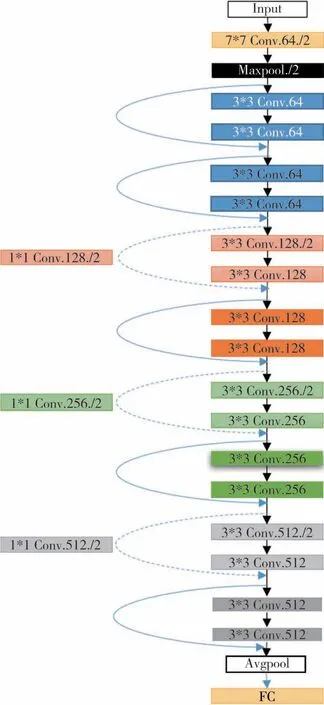
图5 ResNet18网络结构示意图
图像分类经常使用的损失函数是Softmax损失(Softmax loss),可表示为
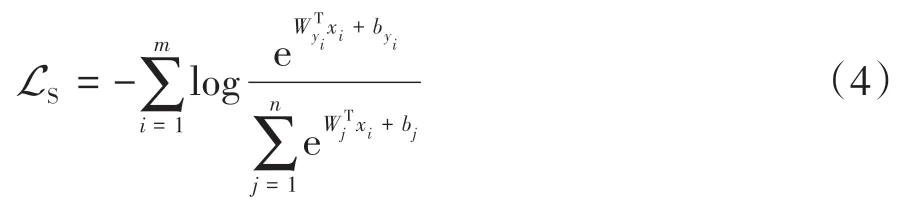
式中:LS为Softmax loss;Wx+b为全连接输出;log为xi属于类别yi的概率;m表示mini⁃batch的大小。
使用Softmax loss分类时可能会导致类别的界限不清晰,因此,本文在使用Softmax loss的基础上,加入了Center loss[23],可表示为

式中:LC表示Center loss;cyi表示第yi个类别的特征中心;xi表示全连接层之前的特征;m表示mini⁃batch的大小。从实际意义上来说,Center loss是希望一个Batch中的每个样本的特征离特征中心距离的平方和越小越好,即类内距离要越小越好。本文最终损失函数可表示为
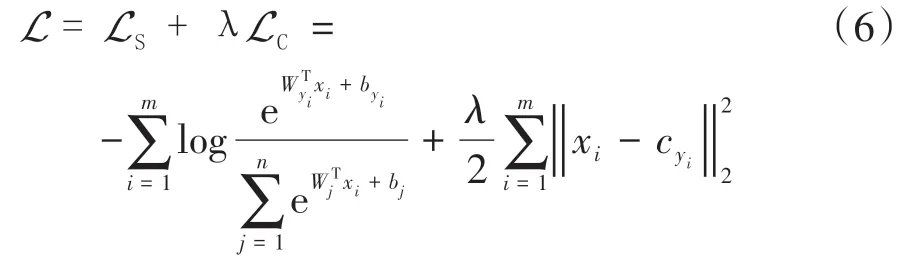
2.3 检测分类级联模型
在得到剪枝优化的车辆检测模型和细粒度的车辆分类模型以后,对两模型进行了级联,具体的级联策略为:视频流推流进网络后,利用检测模型的检测框(bounding box),作为分类模型的输入,最终的标签输出组成为“检测框+类型+颜色”。
3 实验
3.1 实验设备与环境
训练设备与环境主要包括:Intel(R)Xeon(R)Gold 6129@2.30GHz CPU,NVIDIA GeForce RTX 2080Ti*4 GPU,Ubuntu18.04,Pytorch1.7,Darknet,Tensorflow1.13。
由于希望在实际工程下进行模型验证,因此在海思平台下进行了模型移植,主要的设备与环境包括:海思Hi3516DV300模组套件,Caffe1.0。
3.2 实验数据
实验使用了BDD100K[24]数据集、VERI-Wild[25]数据集和自采标注的数据集。由于BDD100K数据集中的图像数据是面向自车视角,因此使用其作为YOLOv4原始网络模型的预训练数据集,得到的网络模型及权重经通道剪枝后,使用鸟瞰视角的自采标注数据集进行微调。重新对VERI-Wild数据集进行了图像分类和整理,并在其中添加了自采标注的数据集,在图像类别数量不平衡的问题上,使用了数据增强。重构的数据集如表3和图6所示。
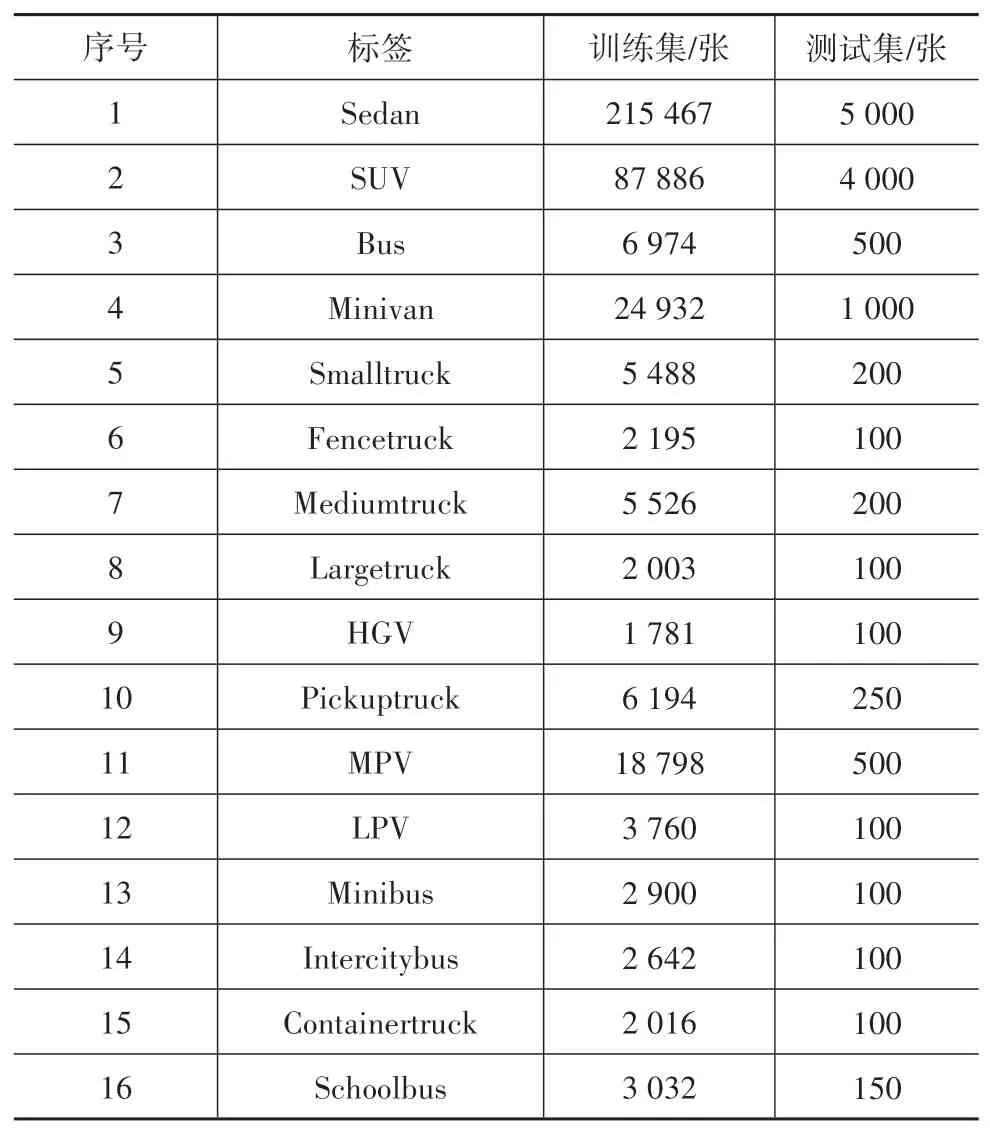
表3 重构VERI-Wild数据集
3.3 实验结果与分析
选取不同角度的路侧端视频对级联模型进行了可视化,选取的部分车辆检测分类效果如图7所示。

图7 不同视角下车辆检测分类效果
针对YOLOv4车辆检测模型,其和经通道剪枝优化的YOLOv4车辆检测模型(微调后)的模型体积、前向推理时间(输入1920×1080)和测试集mAP如表4所示。为平衡模型体积和mAP,本文中在多版本剪枝优化模型中,选取了mAP下降0.006,模型体积减小约60%的YOLOv4-Pruned模型。
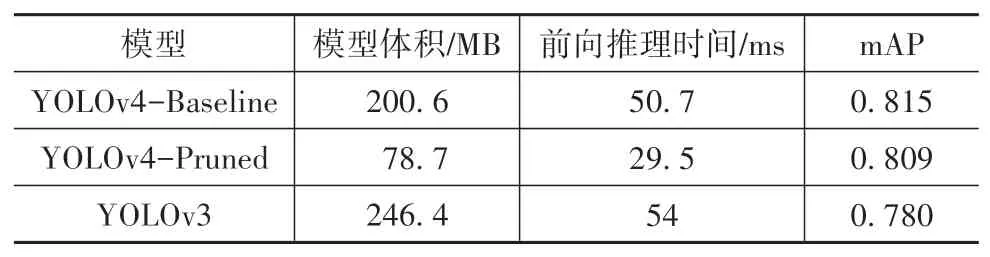
表4 车辆检测模型指标
针对细粒度车辆分类模型,模型体积、前向推理时间(输入416×416)、分类准确率(类型、颜色均正确)如表5所示。

表5 细粒度车辆分类模型指标
针对细粒度的车辆检测分类级联模型,模型体积、FPS(输入1920×1080),和在测试集上的mAP如表6所示。

表6 细粒度车辆检测分类级联模型指标
在海思平台Hi3516DV300(算力为1.0Tops)上进行了模型的移植与测试,由于海思仅支持Caffe模型,因此,将多框架模型转化统一为Caffe模型,具体为:Darknet模型转为Caffe模型,Pytorch模型先转为ONNX模型,后将ONNX模型转为Caffe模型,在海思平台上进行了模型移植,针对细粒度的车辆检测分类级联模型,模型体积、FPS(输入1920×1080)和在测试集上的mAP如表7所示。

表7 海思平台细粒度车辆检测分类级联模型指标
从以上各表对比可以看出,经剪枝优化后的检测模型与细粒度的车辆分类模型级联后,在1920×1080输入,NVIDIA GeForce RTX 2080Ti下,可在微小精度损失的情况下,FPS达到23,在海思平台下,FPS达到13。需要说明的是,海思平台下的模型未经量化。
4 结论
本文中分析当前无人驾驶环境感知技术面临的难题,提出了一种面向视频结构化的解决方案,其可以概括为:通过合理分配计算资源,优化多深度学习模型,制定深度学习模型间交互逻辑,合理结构化输出图像,以涵盖丰富信息,实现复杂交通场景理解。
根据所提出的视频结构化算法框架,设计了一种适用于视频结构化算法的细粒度车辆检测分类模型。针对检测模型,通过对YOLOv4进行通道剪枝,使得模型体积减小约60%,前向推理时间减少约40%。提供了16种类型、12种颜色的细粒度车辆分类模型,基本可以覆盖目前交通场景下常见的所有车辆。级联检测分类模型在GPU下的测试可达到23 FPS,且本文进行了工程上的模型移植验证,在海思平台Hi3516DV300上,未经量化的模型可以在不掉精度的前提下稳定在13 FPS。Hi3516DV300的算力有限,在实验中仅作工程化演示,后续实际应用需在大算力平台下进行,如NVIDIA Jetson Xavier NX等。
后续可在本文提供的多路侧端设备视频结构化输出下,围绕车辆重识别(用于身份合并)和多车交互决策与规划等内容进行研究。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
农业工程学报(2022年6期)2022-06-27
计算机应用(2022年5期)2022-06-21
课堂内外·好老师(2022年3期)2022-04-25
学习与科普(2022年17期)2022-04-23
云南教育·小学教师(2021年12期)2021-03-23
福建基础教育研究(2020年3期)2020-05-28
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
