
基于超复数小波和图像空域的卷积网络融合注视点预测算法
2021-11-02 03:01:22朱子重许大有高伟哲靳山岗
兰州理工大学学报 2021年5期
李 策, 朱子重, 许大有, 高伟哲, 靳山岗
(兰州理工大学 电气工程与信息工程学院, 甘肃 兰州 730050)
一个场景中哪些部分或者哪些特有的形式吸引人类的眼球,是视觉心理学研究的主要内容之一.同时设计注视点预测的计算模型,亦是计算机视觉中一个长期研究的课题[1].常见的注视点预测算法通常将注视点预测问题构建成一个视觉注意力或显著性的估计问题,通过提取图像特征,得到图像中的显著性区域,从而实现图像的注视点预测.Itti等[2]通过高斯金字塔模型生成多尺度图像,对原图像滤波提取颜色、亮度、方向特征,利用中心位置与周边区域之差获得三种特征,模拟人类视觉注意力机制,得到图像的注视点图.受此启发,许多学者利用不同的特征或不同的显著图计算方法,得到图像中人眼注视的显著区域.Hou等[3]提出了一种分析每幅图像的对数光谱并获取光谱残差的方法,该方法可以获得预注意视觉搜索行为的估计.Torralba等[4]基于图像全局上下文信息,提高观察者在真实场景中眼睛运动的预测性能.此外,将图像变换到频域中,Guo等[5-7]研究了图像频域的幅度谱和相位谱与人眼注视之间的关系,并取得了一定的成果,推动了注视点预测模型的发展.
然而,传统算法通过在空域或者频域中提取与注视点相关的低级特征信息,进行注视点预测,其结果与人眼真实注视位置差距较大.随着自然场景下眼动追踪大规模数据的采集,为了提高注视点预测准确度,基于数据驱动的机器学习技术和卷积神经网络变得更加实用.
Judd等[8]采用基于机器学习的方法,通过学习多种图像特征来训练视觉注意模型,从一组低级、中级、高级视觉特征中预测注视密度图,该方法认为图像中物体属性有助于注视点的预测.随着卷积神经网络在计算机视觉任务中表现出较好的性能,研究者提出了基于卷积神经网络的注视点预测模型.Vig等[9]提出深度网络集成eDN (ensemble of deep networks)模型,这是利用卷积神经网络预测图像显著性的第一次尝试.Kümmerer等[10]为了探讨低级特征和高级特征对注视点预测的贡献,提出了Deep Gaze II模型,取得了较好的效果.Cornia等[11]提出了多级融合的卷积神经网络ML-Net(multi-level network)模型,融合了卷积神经网络中不同层中提取的特征,由三个模块组成:一个特征提取卷积神经网络、一个特征编码网络和一个先验学习网络.Pan等[12]利用生成对抗网络SalGAN (saliency prediction with generative adversarial networks)模型获得注视点预测图,它由生成器和鉴别器两个模块组成,生成器可以更好地生成注视点图,判别器可以更好地分辨真实注视点图与生成注视点图.Cornia等[13]提出显著视注意模型SAM(saliency attentive model),将编码器产生的特征图送入到卷积长短期记忆网络,细化注视点预测图,最后通过添加中心先验获得最终的注视点预测图.Liu等[19]提出了空间上下文长期递归卷积网络DSCLRCN(spatial contextual long-term recurrent convolutional network)模型,首先利用卷积神经网络学习图像的局部显著性,然后对图像进行水平和垂直扫描,生成一个空间长短期模型来捕捉全局语义信息;DSCLRCN模型利用上述两个操作可以有效地结合局部和全局上下文信息来预测图像的注视点.
上述基于卷积神经网络的算法中,卷积提取特征过程往往是在空域中进行的,容易丢失图像的细节信息;同时常用的卷积核操作仅可获得单一尺度的特征图,导致获得的注视点预测精度不高;此外,对于比较复杂的场景图像,现有算法依然存在注视点预测不准确以及预测有误的现象.
为此,本文提出了一种基于超复数小波和图像空域的卷积网络融合注视点预测算法.从超复数小波变换[14]的频域中提取图像的细节信息,并且结合图像空域特征信息,作为注视点预测的输入信息来源;同时在卷积网络中,利用不同步长的空洞卷积,获得图像频域和空域特征图下多尺度的注视点预测信息,有效解决了由于特征图尺度单一导致的注视点预测偏低问题;进而引入通道和空间的注意力机制,有效抑制了特征图中背景信息的干扰,提高了注视点预测精度.
1 基于超复数小波和图像空域的卷积网络融合注视点预测算法
针对已有注视点预测模型存在特征细节缺失、尺度单一和背景信息干扰导致的注视点预测精度偏低等问题,本文提出了一种基于超复数小波和图像空域的卷积网络融合注视点预测算法.首先,利用卷积神经网络提取图像经过超复数小波变换的频域注视点预测信息,与卷积神经网络获取的图像空域注视点预测信息结合,得到图像的注视点预测特征信息;然后,将获得的图像频域和空域特征图作为空洞空间金字塔池化模块[15]ASPP(atrous spatial pyramid pooling)的输入,得到不同感受野的注视点预测信息,能够解决卷积操作获得特征图的尺度单一问题;最后,引入残差卷积注意力模块[16]Res_CBAM(residual convolutional block attention module),有效抑制了特征图中背景信息的干扰,从而实现了图像注视较好的预测.在公开的数据集SALICON[17]和CAT2000[18]上,分别从主观和客观对比实验中验证了所提算法的可行性.
本文所提算法框架如图1所示,分为4个模块:

图1 本文所提模型结构图Fig.1 The architecture of the proposed model
1) 图像频域信息获取模块,利用超复数小波变换[14]获取图像的细节信息;
2) 特征提取模块,使用双分支网络(FDFN和SDFN)分别从频域和图像的空域中提取与注视点相关的特征信息;
3) ASPP模块,获取不同感受野的特征信息,提高注视点预测准确度;
4) Res_CBAM模块,结合空间和通道的注意力机制,获取输出特征图中与注视点预测相关的特征信息,利用网络模型推理注视点位置,获得较为准确的注视点预测图.
1.1 图像频域信息获取模块
超复数小波变换具有良好的平移不变性和方向选择性,同时能够有效提取图像的细节信息,因此本文利用超复数小波变换获得图像的频域信息,将其作为注视点预测的细节信息输入到卷积网络中,解决由于卷积网络提取空域特征时图像部分细节信息容易丢失的问题,提高注视点预测精度.图像经过超复数小波变换后,可以产生4幅近似图和12幅子带图.本文中所使用的超复数小波变换是指双树四元数二维离散小波变换,二维的四元数解析信号被定义为
其中:f(x,y)表示一个实数范围内的二维信号;fHi1(x,y)和fHi2(x,y)分别表示信号f(x,y)沿着x轴和y轴方向的希尔伯特变换;fHi3(x,y)表示f(x,y)在两个方向上的希尔伯特变换;σ(x)表示在x轴方向的脉冲函数;σ(y)表示在y轴方向上的脉冲函数.
图像经过超复数小波变换后,获得的频域图可以表示为
(5)
其中:φ(·)和ψ(·)分别表示对应方向上的尺度函数和小波基函数;每一个超复数的实部表示近似部分,i、j、k三个方向上的虚部分别表示水平细节、垂直细节和对角细节;LL代表低频子带;LH、HL和HH代表三个高频子带.
本文中,用超复数小波变换将图像由RGB空间转换到频域空间,而利用超复数小波变换的目的是获取注视点预测细节信息,因此所提算法仅使用超复数小波变换的子带图,即令实部为零,通过频域特征提取网络(frequency domain feature network,FDFN)提取与注视点相关的细节信息.
1.2 特征提取模块
由于卷积提取注视点特征信息过程中,图像的细节信息不可避免地会有一些丢失;而超复数小波变换产生的子带图补充了注视点预测的细节信息,同时图像空域中的颜色、纹理、亮度等信息也是与注视点预测高度相关的特征信息.因此,本文提出了一种双分支卷积网络,利用FDFN和SDFN(spatial domain feature network,融合空域特征提取网络)同时学习图像频域和空域中与注视点相关的有效信息,提高注视点预测精度.本文使用经过修改的VGG16卷积网络提取注视点预测特征,为了保证特征图中注视点信息的完整性,在后两个池化层(Pool4,Pool5)中去掉了下采样过程,从而使特征图的尺寸不再降低.对于FDFN模块,图像的频域信息来源于超复数小波变换第一、二、三级分解的子带图(HWT1,HWT2,HWT3).在超复数小波变换的子带图中,一方面通过卷积方式获取与注视点预测相关的细节信息;另一方面,由于池化操作会改变特征图的尺寸,为了保证特征图尺寸大小的一致性,对于超复数小波变换二级分解的子带图(HWT2),去掉Conv1模块中提取特征图的池化操作.这样,在Conv2模块中,由超复数小波变换一级分解子带产生的特征图与二级分解子带产生的特征图尺寸一致,通过融合二者,可以有效增加超复数小波变换不同级分解之间的信息互补,获取丰富的注视点预测细节信息,从而更加有效地进行注视点预测.同样的,对于超复数小波变换三级分解的子带图(HWT3),去掉Conv1和Conv2模块中的池化操作.具体过程如图2所示.其中,使用VGG16去掉后两个池化层(Pool4,Pool5)下采样后对HWT1进行特征提取,而对于HWT2和HWT3在使用上述网络提取特征时,又去掉部分池化层(如红色虚线框所示).对于SDFN模块,其输入图像(Img)空域的特征提取过程与HWT1一致.

图2 VGG16提取超复数小波变换多级分解特征示意图
由FDFN和SDFN模块得到的频域和空域的注视点预测特征图,本文中通过卷积的方式将二者进行融合(如图1中频/空域特征融合模块),得到融合了频域和空域信息的注视点预测特征图.
1.3 ASPP模块
在注视点预测模型中,注视点的产生不仅要考虑图像的局部信息,还要考虑图像的全局信息,因此本文利用不同步长的空洞卷积,获取特征图不同感受野信息,从而更好地得到注视点预测位置.ASPP[15]在输入特征图上利用不同感受野的空洞卷积操作,多次提取输入特征图的信息,在获得特征图更多感受野信息的同时,将获取到的不同感受野特征图池化,减少网络模型参数量.为了获取图像频域和空域中不同尺寸感受野的注视点预测信息,本文将双分支网络获得的图像空域特征和超复数小波变换频域特征融合后作为ASPP模块的输入,所提算法中使用采样率为rates={4,8,12}、卷积核为3×3的空洞卷积从输入特征图提取不同感受野的特征图信息,如图3所示.此外,对输入特征图进行正常的卷积提取特征和特征图的平均计算,与原文的ASPP模块相比,本文通过ASPP模块获取图像频域和空域的不同尺寸感受野中注视点预测相关的信息,从而获得更好的注视点预测准确性.
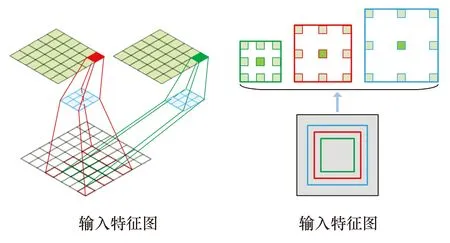
图3 ASPP模块示意图
1.4 Res_CBAM模块
卷积操作能够提取图像中的显著特征,对于注视点预测模型,由于提取的注视点特征图中,有一部分表征的是背景干扰信息,容易导致模型预测的注视点位置分散,降低注视点预测的精度.由于Res_CBAM模块[16]在图像分类和目标检测中能够抑制图像背景信息,取得提高目标分类精度和目标检测准确度的效果,因此本文将Res_CBAM模块引入到注视点预测任务中,选择性地整合多层次的上下文语义信息,可以减少背景的干扰,增加注视点预测相关信息的权重,从而使注视点预测模型取得更好的性能.
如图4所示,当给定特征图F∈RW×H×C作为输入(C表示特征图的通道,W×H表示特征图的尺寸),MC∈R1×1×C表示通道注意图,MS∈RW×H×1表示空间位置注意图,则Res_CBAM模块可以表示为

图4 Res_CBAM模块Fig.4 Res_CBAM module
(6)
其中:⊗表示对应位置元素相乘;F′表示通道注意输出特征图;F″表示空间位置注意输出特征图;Fout是残差卷积注意模块的输出.
通道注意图MC和空间位置注意图MS可由下面的公式计算获得:

在本文中,使用Res_CBAM模块作为注意力机制,对卷积提取频域信息过程中最后四个池化层的输出进行约束增强处理.将Res_CBAM模块的输出与解码过程融合,提高网络推理过程中注视点预测的准确性.最终,解码后可以获得与图像尺寸大小一致的注视点预测图.
1.5 损失函数

(9)
其中:i表示图像第i个像素;ε是一个正则化常数.利用KL-Div衡量注视点预测结果与标注的显著性密度图之间的分布差异,L1值越小说明差异性越小,即注视点预测结果越好.为了更好地拟合KL-Div,提高算法精度,通过Adam优化算法逐步最小化损失函数,获得较好的网络模型参数.
2 实验分析
为了对模型性能进行全面的评估,在所提模型的训练和测试过程中,使用SALICON[17]和CAT2000[18]两个公开的注视点预测数据集完成本次实验.本文使用实验平台的CPU型号是Intel Core i7 9700K 8GB,GPU型号是GTX 2080 8GB显存,操作系统是Ubuntu16.04.算法是基于Tensorflow 1.14.0版本实现.程序中,卷积网络的权重初始化为在ImageNet上训练的VGG16模型的权重.网络中,将学习率设置为10-5,batch_size设置为1,训练20个批次.在20个批次训练中,将在验证集上损失函数最小的一次作为最优模型.图5是20个批次在验证集上的损失函数曲线,可以看出随着训练批次的增加,损失函数逐渐降低,13次以后损失函数的变化不是很大,在第18个批次时最小,因此本文采用第18个批次的训练参数作为本文所提算法中最终的模型参数.并且应用线性相关系数CC(Pearson’s correlation coefficient)、Shuffled ROC曲线下的面积sAUC(shuffled area under curve)、相似度度量SIM(similarity)和标准化扫描路径显著性NSS(normalized scanpath saliency)等评价指标对所提模型进行全面的评价[19].

图5 在验证集上的损失函数曲线Fig.5 Loss function curve on the validation sets
CC是衡量注视点预测图与密度分布GT图之间线性关系的随机变量,如下式所示:
(10)
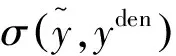
SIM以直方图的形式度量两个分布之间的相似度,如下式所示:
(11)

NSS指标是专门为评价注视点预测模型而定义的,其思想是量化眼睛注视点处的显著性映射值,并将其与显著性映射方差进行归一化,如下式所示:
(12)
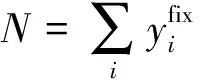
Shuffled ROC曲线下的面积sAUC是AUC的一种变体,它使用其他图像的人类注视图作为非注视点分布.AUC指标定义为ROC曲线下的面积.
本节首先从主观和客观上与其他模型比较分析.此外,本次试验中,针对模型的每一个模块进行了控制变量实验,在SALICON数据集上利用评价指标定量分析预测效果.
2.1 在SALICON数据集上主客观实验对比
在SALICON数据集[17]上,表1与现有的注视点预测算法进行了客观结果对比,其中*表示引用论文中的实验结果.可以看出,本文所提算法在CC、sAUC和SIM三个评价指标上均能取得较好的注视点预测结果.在评价指标CC和SIM上,本文所提算法与CEDN[15]算法相比,分别提高了5%和9%;而在sAUC评价指标上,本文所提算法虽然没有完全达到DSCLRCN[19]的性能,但其值仅降低了0.86%,相差较小.
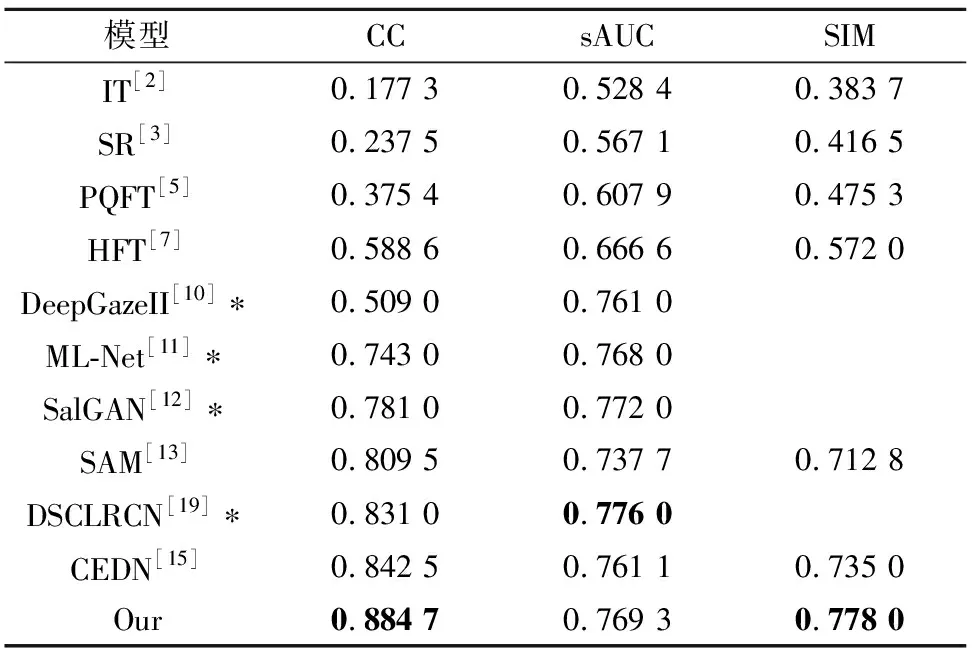
表1 SALICON数据集上客观对比结果Tab.1 Objective results on the SALICON dataset
从主观结果上看(如图6所示),可以观察到,基于卷积神经网络(本文所提算法、CEDN[15]、SAM[13])的算法效果远远优于传统算法(HFT[7]、IT[2]).对于较简单的图像场景(图6前两行),本文所提算法的注视点预测位置相对比较精确.对于复杂的图像场景(图6后三行),本文所提算法依然能找到符合人眼注视的位置,CEDN[15]、HFT[7]、IT[2]算法在第四幅图像上的注视点位置预测有误.
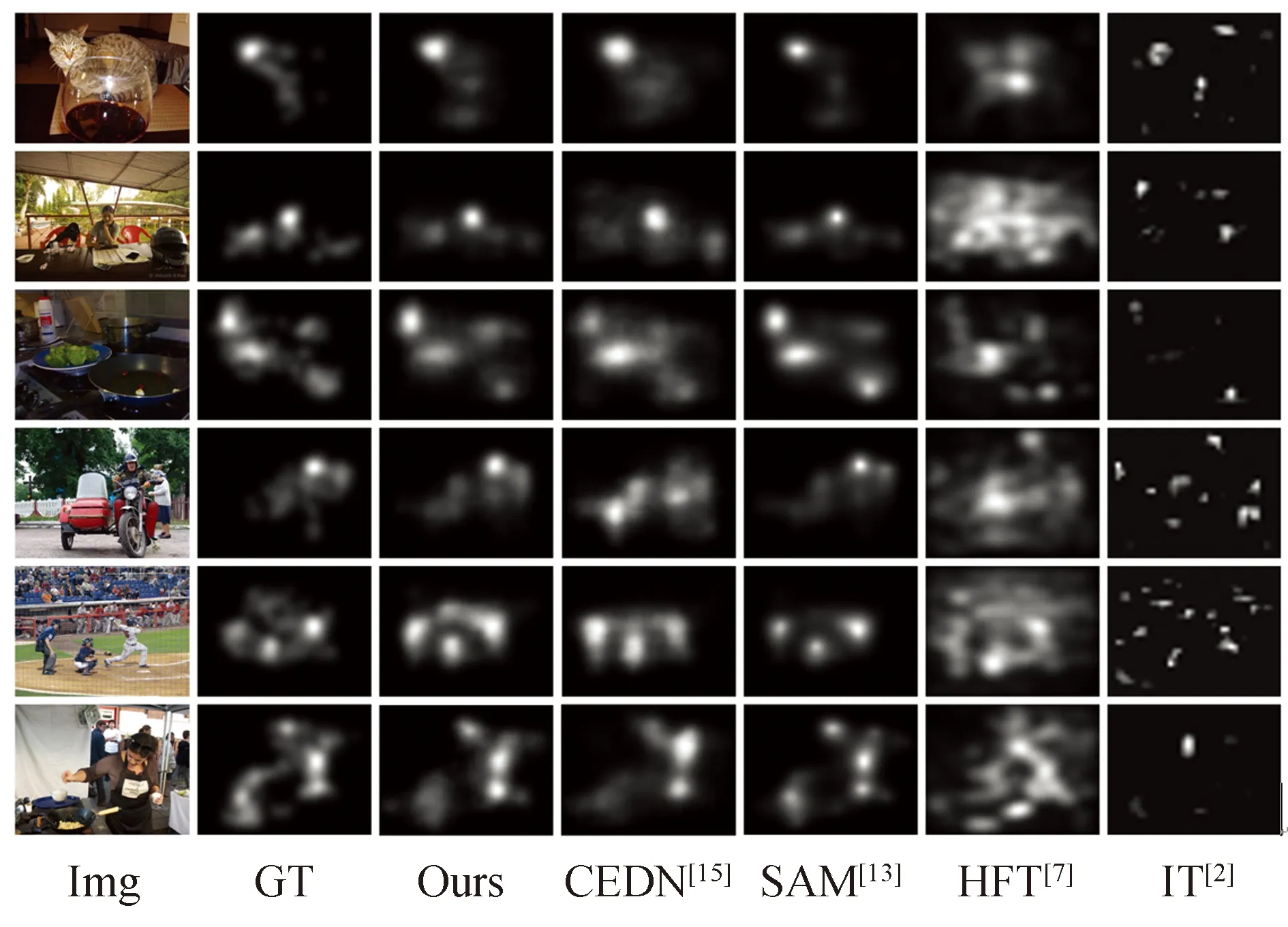
图6 SALICON数据集下主观结果对比Fig.6 Subjective results on the SALICON dataset
2.2 在CAT 2000数据集上主客观实验对比
为了验证模型的泛化性能,在CAT2000[18]数据集上进行训练和测试.CAT2000数据集的图像尺寸较大,因此相应地增加了注视点预测难度.实验的客观结果见表2,其中*表示引用论文中的实验结果.从表2可以看到,与CEDN[15]算法相比,本文所提算法在CC、sAUC和SIM三个评价指标上分别提高了9.4%、4.8%和4.7%.

表2 CAT 2000上客观结果对比Tab.2 Objective results on CAT 2000 dataset
主观结果如图7所示,可以看出,相对于其他算法,本文所提算法在CAT2000数据集上依然能够获得较好的注视点预测效果,说明本文所提算法具有较好的鲁棒性.
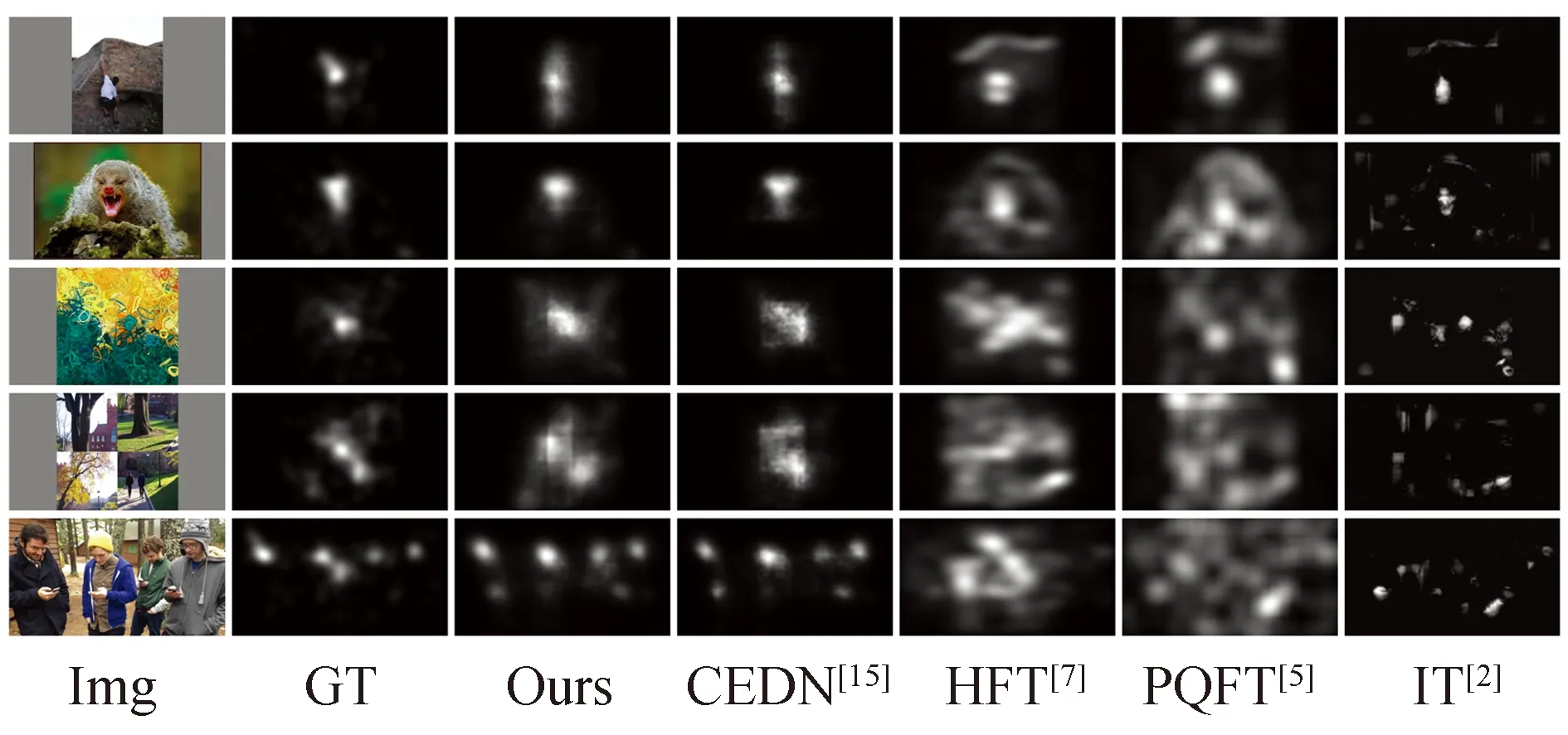
图7 CAT 2000测试主观对比结果Fig.7 Subjective results on the CAT 2000 dataset
2.3 超复数小波变换、ASPP和Res_CBAM模块分析
为了说明本文所提算法中每个模块的有效性,本节对超复数小波变换级数、ASPP模块和Res_CBAM模块在注视点预测中所起到的有效性进行验证.结果表明,所提算法中每个模块都能有效提高注视点预测准确度.
2.3.1超复数小波不同级数变换性能分析
由于超复数小波可以进行多级变换,因此在卷积网络中,超复数小波的哪一级或者哪些级的信息有利于注视点预测是需要考虑的.对此,利用超复数小波不同级的分解训练网络模型,在SALICON数据集上通过CC、sAUC、SIM和NSS评价标准确定超复数小波变换特征图的选取,具体实验结果见表3.由图8可以看出,利用超复数小波多级变换的子带图可以增加注视点预测的细节信息,提高注视点预测精度.然而,当加入超复数小波变换的第四级分解子带图时,模型性能提升不大,有些评价指标还有略微的下降,相对于仅用一级超复数小波变换,使用前三级超复数小波变换的结果在CC、sAUC、NSS和SIM评价指标上,注视点预测准确度提高了8.4%、3.0%、8.9%和7.0%.因此,所提模型中使用了超复数小波变换的前三级分解子带图.超复数小波变换将图像从RGB三通道的空域变换到含有图像细节的频域,利用频域的细节信息,有效丰富了注视点预测特征.上述实验表明,使用超复数小波变换可提高注视点预测的准确度.

图8 使用超复数小波变换不同级分解的主观结果对比Fig.8 Subjective results of different levels of quaternion wavelet transform

表3 加入超复数小波变换不同级分解的客观结果分析
2.3.2ASPP和Res_CBAM模块
为了评估ASPP和Res_CBAM模块的作用,所提模型中去掉ASPP模块(-ASPP)或者去掉CBAM模块(-CBAM)进行注视点预测,通过在评价指标CC、sAUC、NSS和SIM上对比测试结果,验证模块的有效性.
本节从客观评价标准和主观注视点预测图两个方面对注视点预测算法中所使用的模块进行评价.在表4(其中-ASPP和-CBAM分别表示在本文所提模型中去掉ASPP或者Res_CBAM模块)中可以看到,使用ASPP模块在CC、sAUC、NSS和SIM
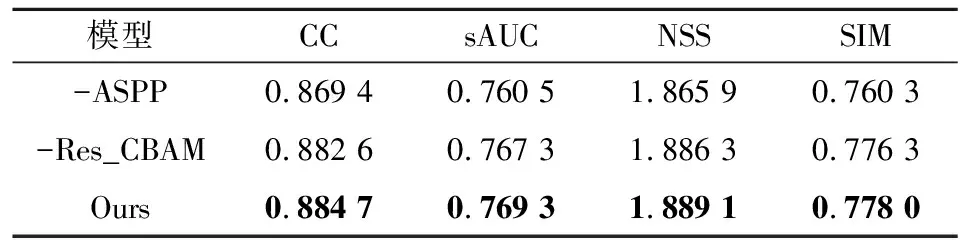
表4 加入ASPP和Res_CBAM模块的客观结果分析Tab.4 Analysis of objective results by using the ASPP and Res_CBAM modules
评价指标上能够提高1.8%、1.1%、1.2%和2.3%,使用Res_CBAM模块在CC、sAUC、NSS和SIM评价指标上注视点预测准确度也有相应的提高,分别提高了0.5%、0.3%、0.1%和0.2%.
主观结果如图9所示.可以看出,ASPP模块可以模拟人类视觉系统,从特征图中获得不同感受野信息,结合这些不同感受野信息,预测出较为准确的注视点位置(图9最后一行);对于大量的注视点预测特征图,在特征图空间位置和通道中,除了含有大量与注视点相关的信息外,一些特征图是对背景信息的表达,而Res_CBAM模块能够从特征图空间位置和通道中筛选出与注视点相关的信息,抑制背景信息的干扰;对于比较复杂的图像,也能够获得较准确的注视点预测(图9第三行).

图9 ASPP和Res_CBAM模块的主观对比Fig.9 Subjective results of different levels of quaternion wavelet transform
3 结语
超复数小波变换能够从频域角度为注视点预测提供相关的图像细节信息,与现有的深度卷积算法结合,可以更加全面地得到注视点预测特征信息,进而提高算法精度.ASPP模块可以增大感受野,在网络模型学习参数时,模拟人眼观察图像的过程,由局部到全局,判断注视点位置的正确性和准确性.而Res_CBAM模块在网络模型中能够学习推理注视点预测过程,提高注视点预测精度.从主观和客观实验结果对比表明,本文所提算法取得了较好的注视点预测效果.今后将结合图像中人与人、人与物体、物体与物体之间的语义关系,从图像中获取更加符合人类视觉的注视点预测结果.此外,本算法今后将从模型压缩入手,减少模型的参数量,使模型进一步满足实时性的要求.
猜你喜欢
智能建筑与智慧城市(2022年9期)2022-09-28 12:07:56
中学生数理化(高中版.高考数学)(2021年11期)2021-12-21 05:34:28
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:48
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20 07:18:46
新世纪智能(数学备考)(2020年12期)2020-03-29 02:15:34
雷达学报(2018年3期)2018-07-18 02:41:34
体育时空(2017年6期)2017-07-14 09:24:48
复旦学报(自然科学版)(2016年4期)2016-09-21 05:30:42
数学学习与研究(2016年9期)2016-05-14 03:00:37
火控雷达技术(2016年1期)2016-02-06 02:17:55
