
基于多模态融合的加权网络重叠社区划分算法
2021-10-27 08:49吴发辉
黑龙江工业学院学报(综合版) 2021年8期
张 玲,吴发辉
(武夷学院 信息技术与实验室管理中心,福建 武夷 354300)
互联网技术的发展,使得人际交流越来越方便,人们之间的联系随之越来越密切。在此背景下,各类社交平台随之出现,如微博、微信、抖音、钉钉等。通过社交平台,将分布各地的人们联系在一起,形成了一个庞大的社交网络。在社交网络上人们可以就一个问题发表自己的观点和见解。由于个人在偏好和兴趣方面存在的差异,又分成了各个不同的社区[1]。例如,就微博而言,一个明星拥有了众多粉丝,这些粉丝都关注了该明星,以该明星为核心节点,就形成了一个社区。然而现实情况是一个人通常不会有一个兴趣点,这就造成了一个人可能属于多个社区的情况,即发生社区重叠现象。
社区重叠研究有着非常广阔的应用场景,比如,在社会消费方面,可以通过分析同一社区内消费者行为特征,在该社区内进行商品推荐,提高商品的销售量;在教育教学方面,可以根据同一社区内学生的学习特征,分析该社区内学生学习难点,并有针对性地推荐学习资源。基于此,关于社区重叠问题的研究有很多[2],面向属性网络,提出一种基于密度峰值聚类的思想的发现算法,实现了重叠社区的划分[3]。通过计算社区节点间H指数和局部影响力来判断节点重要性,以此进行重叠社区的识别[4]。提出了一个群体上两端之间的协同进化方案来解决网络的重叠划分问题。为表示网络的重叠划分,开发了一种由两段组成的编码方案,第一段表示不相交的划分,第二段表示允许多成员身份的划分的扩展,然后给出节点信息性的两个度量,以此来判断群体上两段是否发生重叠。
本文在前人研究的基础上,提出一种基于多模态融合的加权网络重叠社区划分算法。该算法主要提取网络社区间的不同特征,然后进行多模态融合,将融合后的特征输入到分类器中,进行重叠社区划分。最后将所研究算法应用到不同的社区网络当中,进行重叠社区划分,验证算法应用效果。
1 多模态融合的加权网络重叠社区划分算法研究
基于多模态融合的加权网络重叠社区之间就会存在重叠部分,其结构示意图如图1所示。
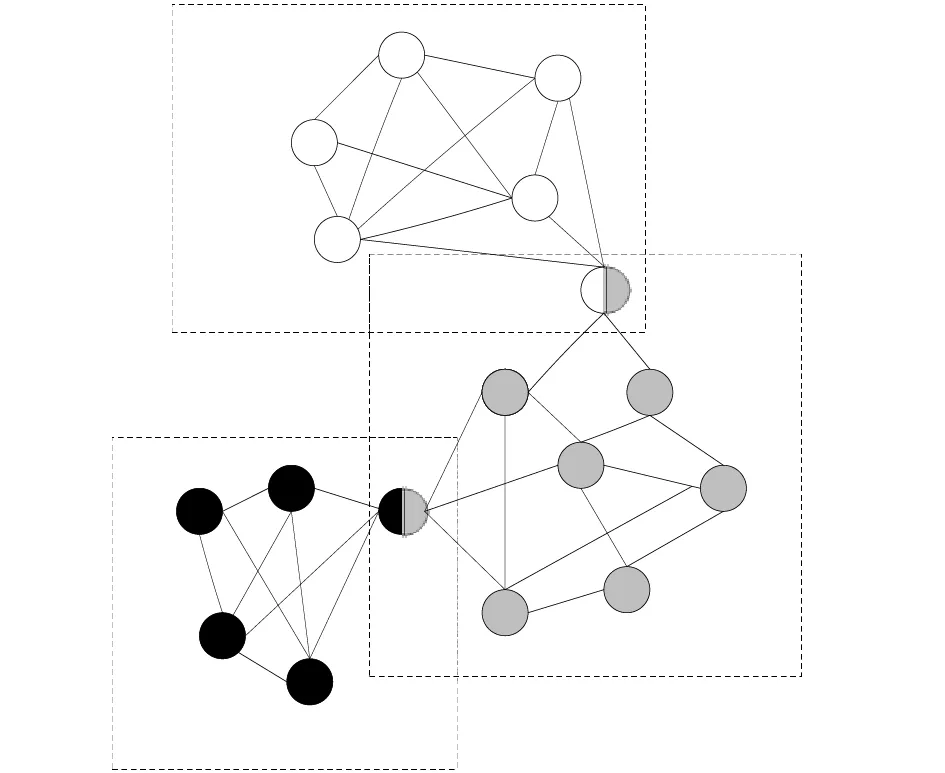
图1 重叠社区网络结构示意图
在重叠社区网络结构中可以看出,一个节点可以属于多个社区,而重叠社区主要是围绕这些节点建立的,重叠社区中节点就被称为重叠节点。本文研究的加权网络重叠社区划分算法就是以加权网络为基础,找出其中重叠节点,完成不同社区之间重叠部分的识别。
1.1 加权网络模型
根据是否加权,社交网络大致分为两种类型,即无权网络和加权网络,如图2所示。

(a)无权网络
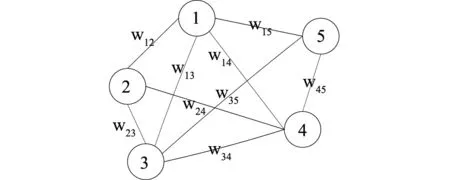
(b)加权网络图2 社交网络类型
在图2中,wij是节点i和节点j之间的权重,代表了两个节点之间的联系紧密度。
在进行网络重叠社区划分之前,为更好地刻画现实网络特征,需要对社交网络进行建模。由于本文研究的是加权网络中重叠社区的划分,因此针对图2(b)进行建模。在这里就用到了图论(是利用图为研究对象,是数学的一个分支)的知识,即将网络中的所有事物用图模型中的节点进行表示,而事物之间存在的相互联系就用图模型中的边表示[5]。由此可见,一个具体的社交网络就是一个抽象的图。
通过G(V,E,W)来描述加权网络,其中,V为加权网络中的节点集;E为加权网络中两两节点连接边的集合,W为两两节点连接边的权重集合,W={wij},wij值越大,两两节点联系越密切。加权网络通过邻接矩阵表示如下。
(1)
1.2 加权网络节点特征选择
基于建立的加权网络模型,对网络中节点特征进行选择。重叠社区中各个节点的特征具有相似部分,因此只要明确节点特征,就能够在后期很轻易地将其划分为重叠部分[6]。
以往研究的大部分重叠划分算法都以一种或者两种算法作为基础,因此导致后续识别精度不足,因此在本文当中选择多个特征,然后在下一步进行多模态融合,将其作为分类器分类的依据。加权网络节点特征主要包括以下平均路径长度、节点度分布、节点从属度、聚类系数、共邻节点相似度等五种[7]。下面进行具体分析。
1.2.1 平均路径长度
平均路径长度求取过程如下。
Step 1:明确加权网络中节点间最短的路径。
Step 2:计算最短路径上边的长度。
Step 3:对最短路径上所有边的长度进行求和。
Step 4:求取求和结果的平均值,即平均路径长度[8]。
平均路径长度计算公式如式(2)所示。
(2)
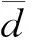
1.2.2 节点度分布
节点度是指随机选取一个节点,围绕该节点周围的相邻节点的数量[9]。在加权网络当中,节点度是指邻接矩阵中行或列相加之和,计算公式如式(3)所示。
(3)
式中,ki为节点i的节点度;aij为邻接矩阵中行或列。
1.2.3 节点从属度
节点从属度是指节点对于核心社区Qk的从属程度[10]。计算公式如式(4)所示。
(4)
式中,F(Ok,i)为节点i相对于核心社区Ok的从属程度;Si,j为节点i与核心节点j之间边的距离;wi为节点的权重。
1.2.4 聚类系数
聚类系数是指节点与之相邻节点之间的连接紧密度,聚类系数越大,越有可能是重叠节点[11-12]。计算公式如式(5)所示。
(5)
式中,Z为聚类系数;Ei为节点i与之相邻节点之间的连接边的数量。
1.2.5 共邻节点相似度
共邻节点相似度计算过程:随机选择两个节点,然后寻找与之相邻的节点,然后判断两个节点是否存在共同的邻居节点[13]。二者之间拥有的共同邻居数目越多,相似度越高,越有可能是重叠节点。计算过程如下:
Step 1:随机选择两个节点,记为x和y;
Step 2:以x和y为核心,建立两个邻域网络,即X和Y;
Step 3:计算X中每一个节点与Y中每一个节点的匹配程度;
Step 4:将匹配成功的X和Y中的节点分别组成邻域网络I和J。
Step 5:计算邻域网络I和J中匹配的所有节点的和,得到节点度量值,记为H(X)。
Step 6:重复上述步骤,得到网络Y的度量,记为H(Y);
Step 7:计算X和Y之间的相似度,即为x和y之间的相似度。计算公式如式(6)所示。
(6)
式中,Qx,y为节点x和y的相似度;K(I,J)为邻域网络I和J中成功匹配的节点数量。
1.3 节点特征多模态融合
为方便后期分类器识别重叠节点,划分重叠社区,需要将上一章节提取出来的节点特征进行融合。在这里需要用到多模态特征融合的方法[14]。多模态特征融合是指利用特征之间的关联性将不同特征融合成一个总的特征向量。根据融合位置的不同,多模态融合策略分为三类,即特征层融合,决策层融合以及模型层融合[15-16],如表1所示。
在这里采用特征层融合策略进行融合,即采用基于多数投票的算法给每个特征赋予不同的权重,以代表对于重叠社区划分的重要程度[17]。融合公式如式(7)所示。
(7)
式中,Y为总的特征向量;wi为权值。
1.4 基于分类器的重叠社区划分
基于上述融合的总的特征向量,通过构建分类器的方法来识别不同社区中发生重叠现象的节点,完成重叠社区划分[18]。由多个决策树组成随机森林,森林中每个决策树就是一个分类器,如图3所示。
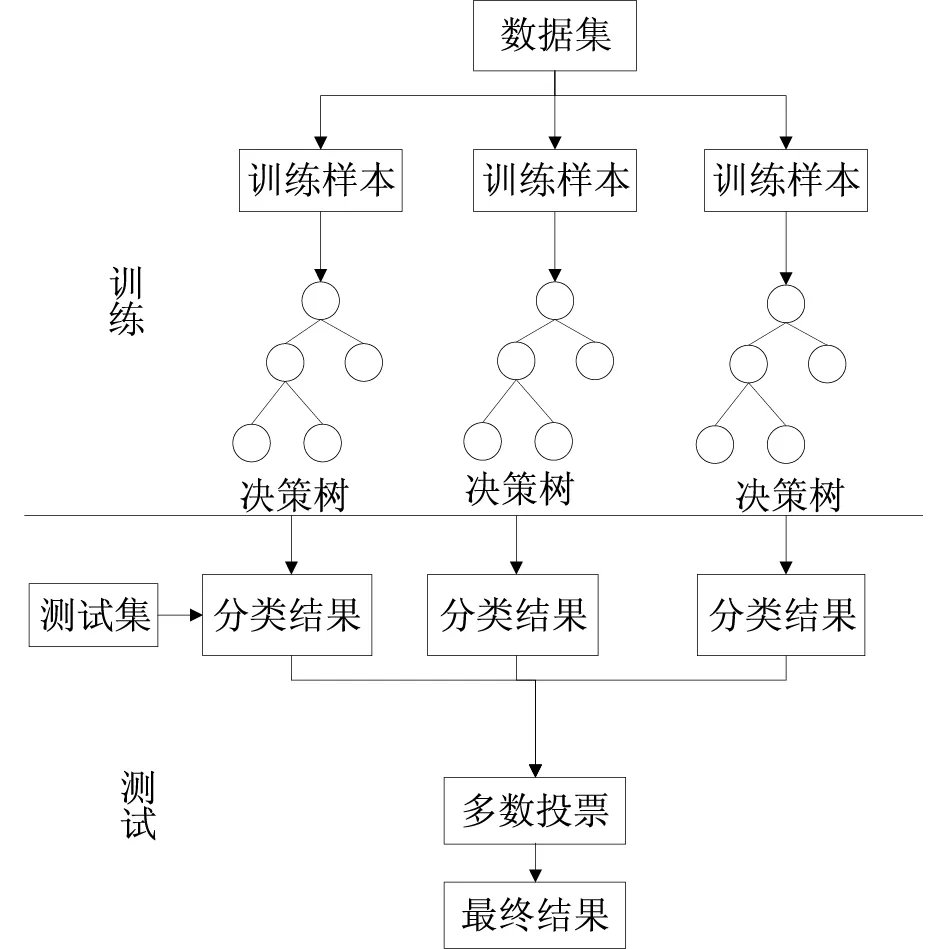
图3 随机森林结构示意图
随机森林建立基本流程如下:
Step 1:利用bootstrap算法在n个样本的集合中有放回地抽取n个样本形成一个数据集。
Step 2:利用随机森林建立n个决策树分类器。
Step 3:当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选
取出m个属性,满足条件m Step 4:从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。 Step 5:重复上述过程,一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。 Step 6:按照上述建立大量的决策树,由此构成了随机森林。 在随机森林建立完成后,最后采用多数投票的方法,识别社区重叠节点,完成重叠社区的划分。 本次仿真实验中总共用到了四种数据集,其中一种为人工合成的加权网络,其余三种为真实加权网络,并以文献[2]和文献[3]划分算法作为对比。 2.1.1 人工合成加权网络 利用LFM准则生成4种不同类型社区,这4种不同类型社区构成了一个大的加权网络。构成的人工合成加权网络基本参数如表2所示。 表2 人工合成加权网络基本参数表 在人工合成加权网络中共包含30个节点和70条边,权重范围为(0,1]。 2.1.2 真实加权网络 加权网络分别为空手道俱乐部网络、Les Miserables网络以及橄榄球社团网络,这些网络的基本构成参数如表3所示。 表3 三个真实加权网络的基本构成参数表 评价社区划分算法性能的指标有两个,一个是在这里标准化互信息指数和模块度。这两个指标的计算公式如下。 2.2.1 标准化互信息指数NMI 标准化互信息指数用来判断利用所研究的算法划分的社区结果与真实结果之间的相似程度。该数值取值范围[0,1],数值越靠近1,划分的结果越接近真实结果,算法的划分精度越高。计算公式如式(8)所示。 (8) 式中,N表示节点的个数;Cij表示在同时属于社区A和B;CA和CB表示社区A和B中节点的个数;Ci、Cj表示网络C中元素的总和。 2.2.2 模块度R 模块度是最能判断算法划分质量的指标,其值一般取值范围为[0.3,0.7],数值越靠近0.7,划分的质量越高。其计算公式如式(9)所示。 (9) 式中,m表示网络中边的个数;Aij表示网络的邻接矩阵;wi、wj表示节点i和j的权重;f(CiCj)为罚函数。 利用本文所研究的算法以及文献[2]和文献[3]划分算法对四种数据集进行重叠社区划分,然后统计标准化互信息指数NMI和模块度R,得到的结果如表4所示。 表4 标准化互信息指数和模块度统计结果 从表4中可以看出,利用本文所研究的算法对四种加权网络进行重叠社区划分,得到的标准化互信息指数NMI和模块度R均要大于文献[2]划分算法和文献[3]划分算法的划分结果,说明所研究的算法划分性能更高。 随着社交平台出现和广泛应用,社交网络体系越来越庞大,使得人们之间的联系越来越密切。人的兴趣不同,因此在社交网络中会存在若干个社区,而这些不同社区又因为一个人拥有的多种偏好存在重叠的问题。基于此,本文就重叠社区的划分进行研究。通过提取重叠节点特征并融合,利用分类器实现了重叠识别和划分,最后通过四种加权网络验证了所研究算法的划分性能。然而,本研究仍有很多的地方需要进行改进,即由于提取了多个特征,虽然划分精度增加,但运行时间相对延长。2 仿真实验分析
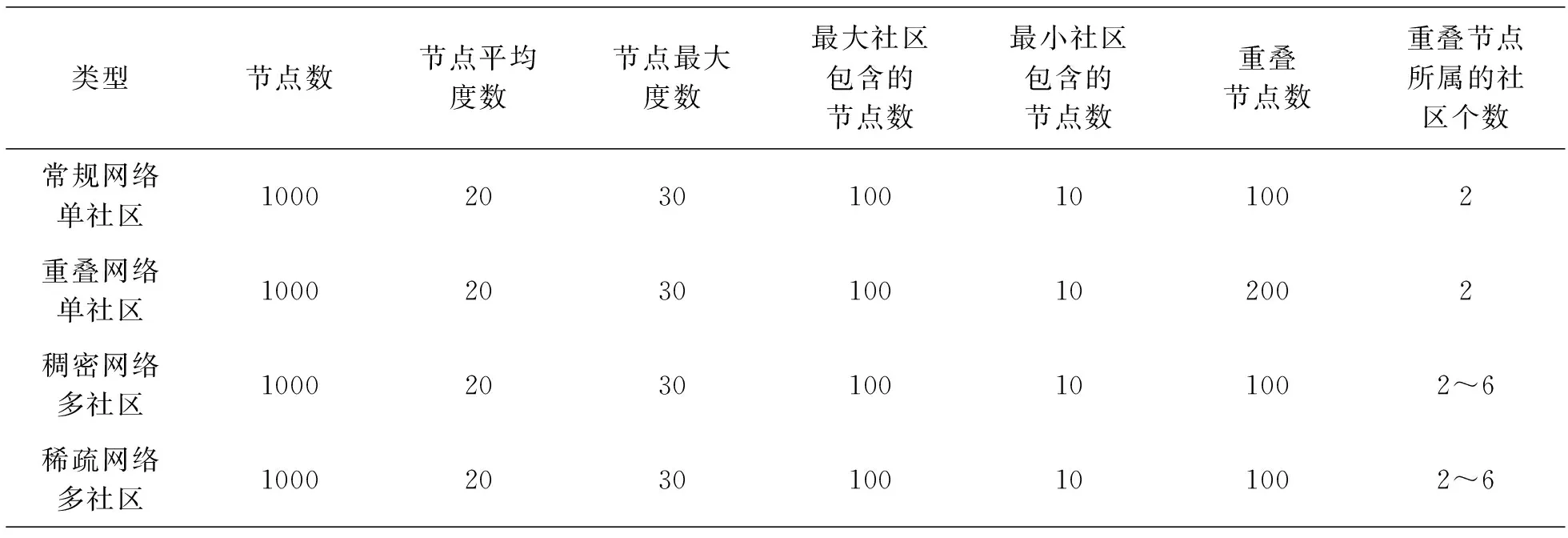
2.1 数据集介绍

2.2 社区划分评价指标
3.3 结果统计与分析

结语
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
电子产品世界(2022年4期)2022-04-21
昆明医科大学学报(2022年3期)2022-04-19
计算机应用与软件(2021年10期)2021-10-15
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
计算机系统应用(2021年2期)2021-02-23
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
计算机应用与软件(2020年1期)2020-01-14
