
基于遗传优化的自然语言文本数字水印方法
2021-10-27 08:49:44保海军
黑龙江工业学院学报(综合版) 2021年8期
保海军
(青海民族大学 计算机学院,青海 西宁 810007)
随着图像加密技术的发展,采用数字水印技术实现自然语言文本数字水印加密,提高图像加密的可靠性和稳定性,在进行自然语言文本数字水印加密过程中,受到自然语言文本数字水印分辨参数及像素参数的混沌性影响,导致自然语言文本数字水印加密的可靠性不高,需要结合对自然语言文本数字水印图像的边缘轮廓分析,建立自然语言文本数字水印图像编码模型,提高自然语言文本数字水印检测和加密能力,相关的自然语言文本数字水印加密算法设计研究受到人们的极大关注[1]。
在进行自然语言文本数字水印加密过程中,结合对图像的加密密钥参数分析,采用图模型参数识别,实现自然语言文本数字水印加密和输出特征分析,传统方法中,对自然语言文本数字水印加密的方法主要有基于颜色参数分析的自然语言文本数字水印图像加密方法、基于混沌序列重构的自然语言文本数字水印图像加密方法等[2-4],文献[5]中提出基于超混沌密钥控制的自然语言文本数字水印加密方法,通过对图像水印量化特征编码,实现自然语言文本数字水印加密,但该方法进行自然语言文本数字水印加密的特征辨识度不高,密钥置乱性不好。文献[6]中提出基于分布式结构重组的自然语言文本数字水印加密方法,采用多通道的图像滤波分析,实现自然语言文本数字水印的混沌加密,但该方法的计算开销较大。
针对上述问题,本文提出基于遗传优化的自然语言文本数字水印加密方法。首先采用多尺度的遗传进化算法实现自然语言文本数字水印的边缘特征检测,然后通过先验知识特征分解结果,实现对自然语言文本数字水印的密钥构造和图像融合处理,根据对自然语言文本数字水印图像的融合结果,最后采用遗传进化迭代的方法,对自然语言文本数字信息融合和水印特征点定位,实现数字水印设计,并通过仿真测试得出有效性结论。
1 自然语言文本数字水印向量量化和预处理
1.1 自然语言文本数字水印向量量化处理
为了实现基于遗传优化的自然语言文本数字水印加密设计,采用非线性向量量化编码方法进行自然语言文本数字水印图像分组检测,结合改进神经网络和遗传进化方法,建立自然语言文本数字水印的混沌检测模型,构建自然语言文本数字水印图像分组检测像素样本序列加密的密钥信息,采用随机线性组合控制,使用Feistel结构加密,构建自然语言文本数字水印的向量量化分解模型,得到自然语言文本数字水印加密的向量量化模型[7],实现结构图如图1所示。

图1 自然语言文本数字水印向量量化实现结构图
根据图1所示的自然语言文本数字水印向量量化结构模型,采用RGB分解方法,获得自然语言文本数字水印的边缘特征信息,根据自然语言文本数字水印图像的字典集分布[8],得到自然语言文本数字水印的灰度字典量化分布模型如式(1)所示。
(1)
其中,ctr为二维到三维特征的转换参数,cz为Z轴的向量量化参数,cy为Y轴的向量量化参数,{cz-cy}为自然语言文本数字水印字典集相似度特征量,构造特征图信息融合参数模型,通过Image2Mesh和 RNN特征融合,构建自然语言文本数字水印加密的遗传进化寻优模型,描述如式(2)、式(3)、式(4)所示。
(2)
(3)
(4)

1.2 自然语言文本数字水印分割
结合对自然语言文本数字水印图像加密区域的边缘信息特征分解结果,采用自适应的遗传进化控制算法[9],得到自然语言文本数字水印空间区域映射如式(5)所示。
ORz=δ{jv(e,k)+|w(k,l)|}
(5)
其中δ取值如式(6)所示。

(6)
图像的多维特征融合如式(7)所示。
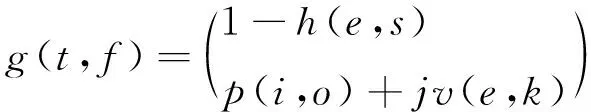
(7)
式(6)、式(7)中,δ为自然语言文本数字水印加速深层进化的随机相位矩阵,jv(e,k)为二维图像所包含的边缘像素集,w(k,l)为自然语言文本语义参数,p(i,o)为特征图通过边缘参数,g(t,f)为图像的多维特征融合参数,h(e,s)为图像纹理分布集,采用图卷积网络分析,构建自然语言文本数字水印字典参数分析模型,得到自然语言文本数字水印Image2Mesh和 RNN纹理分布集如式(8)所示。
(8)
式(8)中,jk为自然语言文本数字水印的关联分布特征分量,jbf为自然语言文本数字水印的模糊度检测系数,ck为图像的浅层特征嵌入维数,c为多维多视角嵌入维数,k为检测统计分量,以像素点j为中心进行自然语言文本数字水印特征分割,提高自然语言文本数字水印检测和识别能力[10]。
2 自然语言文本数字水印加密优化
2.1 自然语言文本数字水印密钥控制
通过先验知识特征分解结果,构建对自然语言文本数字水印的密钥构造和图像融合处理模型,自然语言文本数字水印图像混沌加密的的密钥分布序列为A=1,2,…,n,表示自然语言文本数字水印图像混沌加密的差异度,AD表示Image2Mesh_rnn,D≠0,自然语言文本数字水印加密的光流场分布如式(9)所示。
s(k)=AD{c(m)+c(n)+c(mn)}
(9)
式(9)中,c(m)为联合分布特征序列,c(mn)为初始特征分量,c(n)为自然语言文本语义特征分量,选择直方图模板匹配方法,得到自然语言文本数字水印图像的混沌映射编码序列分布式如式(10)所示。
(10)
定义:
(11)
式(10)、式(11)中,j(k,l)为混沌映射编码序列分布图的模糊度函数,j(i,p)是自然语言文本数字水印的增强系数,采用空间区域模型动态切换的方法[11],提取自然语言文本数字水印的模糊度,得到自然语言文本数字水印的二维编码输出如式(12)所示。
(12)
式(12)中,i(o)为每个卷积层的像素,T为边缘尺度,t(o)为自相似度特征量,t(x)为边缘补零参数,根据5×5卷积核的特征分析方法,得到自然语言文本数字水印的整流单元如式(13)所示。
(13)
式(13)中,ed(h)为自然语言文本数字水印图像的目标直方图重建系数,cd(h)为自然语言文本数字水印图像分布的光流场幅度图。根据上述分析,建立自然语言文本数字水印图像加密区域的匹配特征量,通过先验知识特征分解,实现水印的密钥控制[12]。
2.2 自然语言文本数字水印图像加密输出
采用低秩学习和模糊度检测的方法,构建自然语言文本数字水印的滤波模型,得到自然语言文本数字水印的稀疏特征点用f(y,z)描述,得到自然语言文本数字水印的模板函数fl(y,z)如式(14)所示。
(14)
式(14)中,f表示出区域层级的特征图,(n,d)为相似度坐标分布,采用冗余信息的滤波和遗传优化算法,得到自然语言文本数字水印的分组样本加权模型如式(15)所示。
(15)
式(15)中,wcr为线性加权控制系数,wtr为边缘分布阈值,当wcr=|1-wtr|,生成更密集的特征图,采用匹配滤波和遗传变异算法,得到自然语言文本数字水印的深层的特征信息逐级加权分布如式(16)、式(17)所示。
End=|ak+bk|
(16)
(17)
式(16)、式(17)中,ak、bk代表自然语言文本数字图像融合和滤波系数,若xve为原始自然语言文本数字水印图像纹理线性分布序列,afg、bfg分别为自然语言文本数字水印图像特征融合系数。采用遗传进化迭代的方法生成自然语言文本数字水印如式(18)所示。
(18)
综合上述,自然语言文本数字水印图像加密实现流程如图2所示。

图2 自然语言文本数字水印图像加密实现流程
3 实验测试
为了验证本文方法在实现自然语言文本数字水印图像加密的性能,采用Matlab进行在测试,设定水印图像样本数为240,相关参数设定见表1。

表1 自然语言文本数字水印加密参数设定
根据上述表1参数设定,构建自然语言文本数字水印图像加密模型,待加密的自然语言文本数字水印图像如图3所示。

图3 待加密的自然语言文本数字水印
以图3的待加密的自然语言文本数字水印为研究对象,实现水印融合,如图4所示。


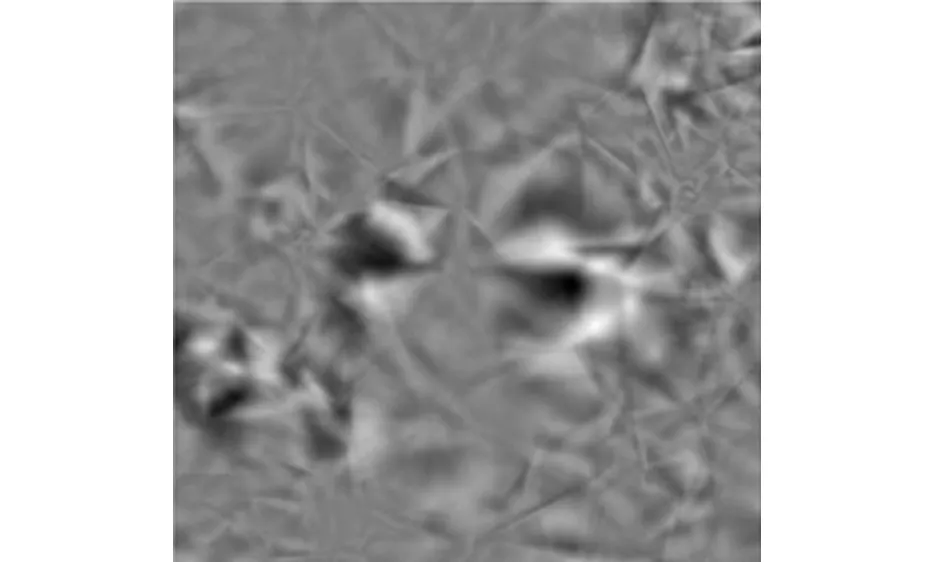
图4 水印融合处理
根据对自然语言文本数字水印图像的融合结果,采用遗传进化迭代的方法,实现对自然语言文本数字信息融合加密,得到加密输出如图5所示。
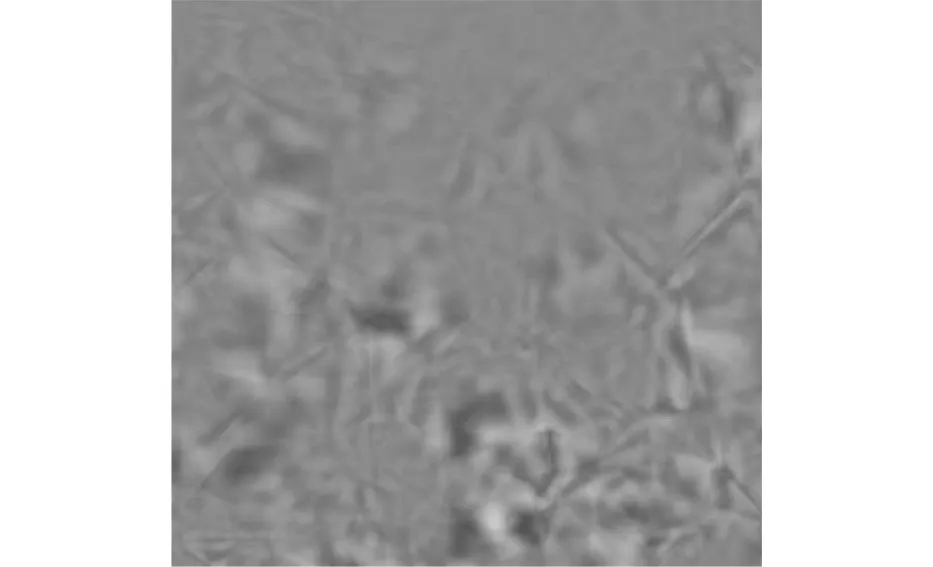
(a)R分量

(b)G分量

(c)B分量图5 自然语言文本数字水印输出
测试加密性能,得到对比结果如图5所示。分析图6得知,本文方法对自然语言文本数字水印处理的输出峰值信噪比较高。

图6 自然语言文本数字水印处理的输出峰值信噪比
结语
结合对自然语言文本数字水印图像的边缘轮廓分析,建立自然语言文本数字水印图像编码模型,提高自然语言文本数字水印检测和加密能力,本文提出基于遗传优化的自然语言文本数字水印加密方法。构建自然语言文本数字水印图像分组检测像素样本序列加密的密钥信息,采用随机线性组合控制,使用Feistel结构加密,构建自然语言文本数字水印的向量量化分解模型,通过先验知识特征分解,实现水印的密钥控制。分析得知,本文方法对自然语言文本数字水印加密的性能较好,峰值信噪比较高。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:17:56
北京电子科技学院学报(2020年2期)2020-11-20 01:44:06
电子制作(2019年20期)2019-12-04 03:51:30
太原科技大学学报(2019年3期)2019-08-05 01:18:18
信息安全研究(2018年1期)2018-02-07 01:44:43
电信科学(2017年6期)2017-07-01 15:45:06
信息安全研究(2016年10期)2016-02-28 20:18:19
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:11
电子设计工程(2015年17期)2015-02-27 12:08:03
华东师范大学学报(自然科学版)(2014年1期)2014-04-16 02:54:52
