
Aerial-BiSeNet:A real-time semantic segmentation network for high resolution aerial imagery
2021-10-27 09:09FangWANGXiaoyanLUOQixiongWANGLuLI
CHINESE JOURNAL OF AERONAUTICS 2021年9期
Fang WANG, Xiaoyan LUO, Qixiong WANG, Lu LI
a School of Electronic and Information Engineering, Beihang University, Beijing 100083, China
b Image Processing Center, School of Astronautics, Beihang University, Beijing 100083, China
c AVIC Aerospace System Co., Ltd., Beijing 100028, China
KEYWORDS Aerial imagery;Deap learning;High resolution;Image segmentation;Real time
Abstract The aircraft system has recently gained its reputation as a reliable and efficient tool for sensing and parsing aerial scenes. However, accurate and fast semantic segmentation of highresolution aerial images for remote sensing applications is still facing three challenges: the requirements for limited processing resources and low-latency operations based on aerial platforms, the balance between high accuracy and real-time efficiency for model performance, and the confusing objects with large intra-class variations and small inter-class differences in high-resolution aerial images. To address these issues, a lightweight and dual-path deep convolutional architecture,namely Aerial Bilateral Segmentation Network (Aerial-BiSeNet), is proposed to perform realtime segmentation on high-resolution aerial images with favorable accuracy. Specifically, inspired by the receptive field concept in human visual systems,Receptive Field Module(RFM)is proposed to encode rich multi-scale contextual information. Based on channel attention mechanism, two novel modules, called Feature Attention Module (FAM) and Channel Attention based Feature Fusion Module (CAFFM) respectively, are proposed to refine and combine features effectively to boost the model performance.Aerial-BiSeNet is evaluated on the Potsdam and Vaihingen datasets, where leading performance is reported compared with other state-of-the-art models, in terms of both accuracy and efficiency.
1. Introduction
Owing to the recent technological advances in the remote sensing domain, the availability of high spatial resolution aerial imagery has significantly increased.High spatial resolution(i.e., high-resolution) aerial images are expecting to provide abundant geospatial information and exhibit multiple finestructured objects in a surveyed area, which allows a better interpretation for the land observation.
The need for high-resolution aerial imagery has motivated the employment of aircrafts in the remote sensing community.The aerial platform, especially Unmanned Aerial Vehicle(UAV), has shown the merits of cost effectiveness, flexible maneuverability, and high-resolution image photographing.Notably, both manned and unmanned aircraft systems integrated with updated airborne sensors are able to produce high-quality aerial images with much higher ground sampling distance, which makes the aerial platform an attractive and promising solution for reliable acquisition of high-resolution aerial imagery in a wide range of applications,including military surveillance,traffic monitoringand intelligent agriculture.
In remote sensing missions, aerial platforms are generally required to implement tasks of object recognition and sense parsing. As a basic functional module to interpret objects and scenes from aerial images, semantic segmentation (i.e.,semantic labelling), with the aim of inferring every pixel in the image with the semantic category of the object to which it belongs,has great significance on a variety of remote sensing applications.
The aircraft system is considered as a capable sourcing tool for high-quality remote sensing data, and in the meantime semantic segmentation algorithms running on the aerial platform are receiving significant interest. However, there still exists some extreme challenges relating to the segmentation models for high-resolution aerial images,and their deployment on airborne hardware of the aircraft platform.
Firstly,from the perspective of aerial platforms,it is vital to deal with data sourced from airborne sensors with low latency in order to make decisions or react accordingly in real time.However, the high model complexity and low computation efficiency of semantic segmentation methods often conflict with the requirements for real-time operations, and limited computational capabilities of aerial platforms, including UAV.Therefore, the lightweight and real-time semantic segmentation model with efficient algorithmic optimization,which is suitable for deployment on airborne hardware, offers a promising and efficient solution. Nevertheless, the excessive computational workload and resulting high latency of computer vision algorithms, such as various novel Deep Convolutional Neural Network (DCNN) based approaches, require computing resources with powerful processing capabilities.Thus, many of the DCNN-based models are unable to exceed the limit of constrained computational resources on aerial platforms, and these algorithms would not be effectively implemented in aircraft-based remote sensing applications.
Secondly, from the perspective of semantic segmentation models, achieving excellent balance between segmentation accuracy and real-time inference is another challenging issue,especially for various remote sensing applications. On the one hand, novel algorithms, especially DCNN-based methods,have made great achievement in improving the quality of aerial image segmentation. However, these approaches require a large amount of parameters to achieve satisfactory accuracy,which leads to high memory consumption and low inference speed. On the other hand, lightweight segmentation methods are often designed to achieve real-time inference speed at the cost of decreasing accuracy and generating incoherent segmentation results.Consequently,both of these two scenarios make current segmentation models running on embedded processors insufficient or unsuitable for various real-time aircraft-based applications.
Thirdly, from the perspective of remote sensing images,high-resolution aerial imagery, which generally contains the narrow spectral bands of visible light, is widely used in the remote sensing community.In contrast,the utilization of aerial imagery with high spectral resolution, such as multi- and hyper-spectral data,is practically limited by high cost of available sensors for data collection, and inefficient access to highdimensional data. The spectral resolution of high-resolution aerial imagery is inherently lower, making it very difficult to distinguish the object categories solely by its limited spectrum bands. In addition, objects with small sizes, detailed boundaries, various colors and small-scale surface textures become obviously visible, which results in a high diversity of ground objects and complex scenes in high-resolution aerial image.Besides, the impacts of imaging distortions, scale variations and interference of cast shadows on objects in the highresolution images would be taken into account, since aerial photographing is often conducted at different weather and lighting condition. As a result, the increasing spatial resolutions of aerial images incur the confusing objects that have large intra-class variations and small inter-class differences.The large intra-class variation means that objects with the same class may show different appearances, such as various shapes, scales and colors. Meanwhile, the small interclass difference is described that objects of different categories would present very similar visual characteristics. For highresolution images, the confusing objects intensify ambiguity and inaccuracy of semantic segmentation results in aircraftbased missions. In Fig. 1, we depict some examples of the issues of large intra-class variations and low inter-class differences. Fig. 1 is a high-resolution aerial image with its ground truth.In the case of large intra-class variations,we can see that cars have different colors and models, but they belong to the same car category. In the meantime, due to the interference of shadows, buildings and impervious surfaces, each of which belongs to the same class separately, vary in appearance. As for low interclass differences, under the influence of shadows,buildings and impervious surfaces are very similar in appearance.To conclude,both of these two issues pose extreme challenges for accurate and coherent segmentation of the confusing objects in high-resolution aerial imagery.

Fig. 1 Examples of the issues of large intra-class variations and low inter-class differences.
Nowadays, the DCNN-based model has become the mainstream method and achieved great success in the field of semantic segmentation, where multiple convolution, pooling,and normalization layers are hierarchically stacked to learn features automatically in a data-driven scheme. Fully Convolutional Network (FCN)becomes the first end-to-end,pixel-to-pixel DCNN-based semantic segmentation network.Subsequently, a variety of DCNN-based segmentation networks are further studied, and these models are quickly dominating the remote sensing applications. For instance, two methods termed as SNFCN and SDFCNequip FCN with dense shortcut blocks, and an overlay strategy is adopted as the post-processing module. U-Netutilizes a symmetry U-shape encoder-decoder architecture concatenating the feature maps generated from the encoder part with the upsampled ones in the decoder via multi-level skip connections.SegNetproposes an encoder-decoder model wherein pooling index information is utilized to perform non-linear upsampling for better results. Global Convolutional Network(GCN)applies the large convolution kernel and global convolution operation to improve the classification and localization accuracy. Context Aggregation Network (CAN)utilizes an encoder-decoder architecture with efficient aggregation of multi-scale contextual information,as well as channel attention based multi-level feature fusion. For preserving spatial resolutions of feature maps while enlarging receptive fields,the atrous or dilated convolution is leveraged in DeepLab variantsand PSPNetfor aggregation of multi-scale contextual information. Discriminative Feature Network(DFN)selects more discriminative features by using the channel attention block along with the global average pooling layer, and refines the semantic boundary by making bilateral features of boundary distinguishable. Despite their favorable performance, DCNN-based semantic segmentation approaches often involve high model complexity and computational overhead, and hence become resource-demanding and time-consuming, both of which violate some tight constraints imposed on aerial platforms including low computational cost,low memory consumption and low-latency on-board processing.
In order to satisfy the requirements of remote sensing applications based on aerial platforms, some lightweight and realtime DCNN-based segmentation models have been proposed.Among these solutions,the dual-path structure is state-of-theart, and it is effectively utilized in Refs.. Particularly,Bilateral Segmentation Network (BiSeNet)adopts the dual-path architecture comprising the spatial path,the context path and the fusion module which are utilized to extract spatial features, encode semantic information, and fuse these two types of features, respectively.
Although BiSeNet to some extent achieves some satisfactory results,there still exists several shortcomings that make this real-time model less applicable to semantic segmentation of high-resolution aerial imagery.Besides low-latency processing,low model complexity,and good balance between segmentation accuracy and efficiency, great attention should also be paid to tackling the issue of confusing objects in highresolution aerial images with high intra-class variations and low inter-class differences.Firstly,multi-scale contextual information is essential to categorize targets with large intra-class variances.However,the spatial path of BiSeNet encodes insufficient multi-scale contextual information and therefore generates less discriminative features for decreasing intraclass variances. Secondly, semantic information ought to be exploited to discriminate objects with similar appearances but belonging to different semantic categories.Nevertheless, the context path of BiSeNet is less capable of exploring channel-wise semantic information, which leads to weak category-dependent features. Thirdly, the fusion module,which combines the feature representations at different levels learned from the dual paths,still needs to be further improved to boost the model performance.
In this paper,we propose a lightweight end-to-end DCNNbased architecture,namely Aerial Bilateral Segmentation Network (Aerial-BiSeNet), to segment high-resolution aerial images in real time,paving the way for remote sensing applications on aerial platforms. Specially, to meet the requirements for real-time operations and resource limitations,a lightweight dual-path framework is proposed, which is appropriate to deployment on the aircraft system.The framework,which consists of a spatial path and a semantic path, achieves favorable segmentation accuracy with real-time inference speed simultaneously.In the spatial path,we propose Receptive Field Module (RFM) to deliver strong representational power for multiscale contextual information to decease high intra-class variations, which utilizes multi-branch structure with varying convolutional kernels corresponding to receptive fields of different sizes,as well as dilated convolution layers with different dilation rates to control their eccentricities.In the semantic path, we propose a Feature Attention Module (FAM) based on channel attention mechanism to encode the enhanced discriminative semantic features, which would alleviate the low inter-class difference problem.Likewise,we propose a Channel Attention based Feature Fusion Module(CAFFM)to fuse the spatial feature and the semantic information from the dual paths, which are different in levels of feature representations,to efficiently improve the model performance.To demonstrate the efficiency and effectiveness of our proposed method, we evaluate Aerial-BiSeNet on the ISPRS Potsdam and Vaihingen datasets. On these two representative remote sensing datasets,Aerial-BiSeNet shows the favorable performance regarding accuracy and efficiency simultaneously, compared to other state-of-the-art segmentation networks. The main contributions of this work are:
(1) We propose Aerial-BiSeNet for real-time semantic segmentation on high-resolution aerial imagery to systematically improve the segmentation performance in terms of accuracy and efficiency,wherein we take advantage of the lightweight dual-path structure to satisfy the requirements for low model complexity and low-latency processing.
(2) We design RFM to encode rich multi-scale contextual information dependent on the sizes and eccentricities of the receptive fields, which are controlled by the convolution kernels and dilated convolutions, separately.
(3) We propose FAM for discriminative semantic feature selection and CAFFM for efficient fusion of the spatial and semantic features, both of which are based on the channel attention mechanism.
The rest of this paper is organized as follows. Section 2 explains our proposed Aerial-BiSeNet in depth. Section 3 and Section 4 provide the details on the experiments and discussion, respectively. Section 5 concludes the paper.
2. Methodology
In this section,we first elaborate on the overall network architecture. Then, we describe the notions of our proposed RFM that is inspired by the receptive field concept,and FAM which is based on the channel attention mechanism, respectively.Finally, we explain detailed information regarding CAFFM.
2.1. Network architecture
The model architecture of our proposed Aerial-BiSeNet is shown in Fig. 2. Aerial-BiSeNet is based on the dual-path architecture that is widely used in the segmentation tasks of high-resolution aerial images.Similar to BiSeNet, the dual-path structure of our model is extremely lightweight and consists of two parts: the spatial path and the semantic path.The lightweight dual-path structure would achieve favorable segmentation accuracy without involving too much computational overhead, which is beneficial for the accurate and real-time semantic segmentation, under the restriction of limited computing resources provided by aerial platforms.
To be specific,the spatial path firstly adopts three convolution layers,each of which has a kernel size of 3×3 and a stride of 2,to generate the feature map whose spatial resolution is 1/8 of the original image.Then RFM is proposed for encoding the abundant multi-scale contextual information, in order to further extract the rich and detailed high-resolution low-level spatial information.
While in the semantic path, Xception39,a light-weight backbone network, is explored to extract high-level semantic information. And a global average pooling layer is appended on the tail of Xception39 to provide the global context information. Moreover, channel attention based FAM is proposed to select the discriminative high-level semantic features from the last two stages of the semantic path. Finally, we deploy the right-half U-shape structureto step-wise combine the upsampled output feature maps from the global average pooling layer and the last two stages of the semantic path.
After the extraction of the spatial and semantic features from the dual paths, we propose CAFFM to fuse both kinds of features to obtain the joint spatial-semantic features for the final segmentation result. Identical to BiSeNet,the principal loss function is introduced to supervise the output of Aerial-BiSeNet, and another two auxiliary loss functions are explored to supervise the outputs of the last two stages in the semantic path. All the loss functions are the Softmax loss,as Eq. (1) shows.

where P is the prediction output of the network before Softmax, and y∈{1,2,...,C} is the correct pixel labelling for the i-th sample. C and N represent the number of the categories and the training samples, respectively.
The final joint loss function of our proposed network is listed below:

where Lossis the final joint loss function, and Lossis the principal loss for the fused output of the dual paths. The two auxiliary loss functions Lossand Lossare used to supervise the outputs of the last, as well as the second last stages of the semantic path, respectively.
2.2. Receptive field module
In high-resolution aerial imagery,multi-scale contextual information is essential for resolving the issue of large intra-class variation.Inspired by the concept of receptive fields in human visual systems, and motivated by the previous successful work of RFBNet,we propose RFM in the spatial path to produce the strong representational power for multi-scale contextual information. The structure of RFB is illustrated in Fig. 3.
It is stated by neuroscientists that in the visual cortex, the size of the receptive field is a function of the eccentricity in the retinotopic map of human, and the receptive field size at the appropriate eccentricity is effective in highlighting informative regions.Inspired by this discovery, the study on RFBNetproposes that the convolutional kernel size and dilation rate have a similar positive functional relation as that of the size and eccentricity of the receptive field in the human visual cortex.As a result,RFBNet takes advantage of multibranch deep convolutional layers with varying kernels corresponding different sizes of the receptive fields, and applies dilated convolution layers with different dilation rates to control the corresponding eccentricities to improve the performance of object detection models.
The construction of our proposed RFM relies heavily on the concept of RFBNet. The structure of RFM stimulates the relation between the receptive field size and eccentricity.RFM employs three parallel branches, each of which comprises the convolution layers with different kernel sizes covering multiple receptive fields, together with the dilated convolutions with varying dilation rates to accordingly adjust the eccentricities.

Fig. 2 Network architecture of Aerial-BiSeNet.

Fig. 3 Structure of the proposed RFM.
In Fig. 3, for instance, the first (left-most) branch consists of a stack of two 3×3 convolution layers in replace of one 5×5 convolution kernel, and one 3×3 dilated convolution kernel with the dilation rate set to 5 accordingly to match the receptive field size of 5×5. Furthermore, the second branch consists of one convolution layer with the kernel size of 3×3, and one dilated convolution kernel with the dilation rate set to 3 to match the receptive field size of 3×3.Similarly,the third branch consists of one convolution layer with the kernel size of 1×1, and one dilated convolution kernel with the dilation rate set to 1 to match the receptive field size of 1×1. The residual connection is also applied to introduce the identity mapping.
Eventually,the feature maps with diversified receptive fields from all three branches and the identity mapping are concatenated altogether to provide sufficient multi-scale contextual information, which would alleviate the issue of large intraclass variations for segmenting confusing objects, and thus improve the model performance.
2.3. Feature attention module
In order to obtain the intra-class consistent prediction in highresolution aerial images,it is vital to encode the discriminative semantic features and inhibit the indiscriminative features.Each channel contains a specific semantic feature response,and different channels have different semantic features.Notably, the channel attention mechanism can capture channel-wise dependencies, and emphasize the salient objects to alleviate the inaccuracy caused by the redundant features in channels.
Motivated by SE-Blockwhich captures the global context of the feature and computes an attention vector to guide the feature learning, we propose FAM to exploit the interchannel relationship,magnify advantageous semantic features,and suppress the useless ones at the channel level in order to lower the inter-class similarities of confusing objects in highresolution aerial imagery. The structure of FAM is depicted in Fig. 4.
Our channel attention module FAM firstly generates two 1D feature maps by using two kinds of pooled feature vectors simultaneously: F∈Rand F∈R, each of which denotes the average-pooled feature and the maxpooled feature respectively.And these two types of pooled features are both generated from the input feature map F∈R, where H, W and Cdenote the height, the width and the number of channels of the input feature map,respectively. The global average pooling can be expressed as:

Then, both Fand Fare concatenated and projected into a reduced dimension Rby using a 1×1 convolution,where Cdenotes the number of channels of the output feature map,to integrate and compress the feature map across the channel dimension.The reduction ratio r is set to 16 in this paper. A ReLU is applied after the channel reduction operation to introduce non-linearity, and the 1×1 convolution is utilized differently as the dimensionality-increasing layer to return to the channel dimension C. A sigmoid function is applied to activate the convolution result to learn a 1D attentive weight vector W∈R, and in the meantime constrain the value of the attentive weight vector Wbetween 0 and 1. This can be formulated as:where Conct(·) denotes the concatenation operation, W(·)and W(·) represent the dimensionality reduction and expansion transformations implemented by the two 1×1 convolutions respectively, γ(·) denotes the ReLU activation function,and Sig(·) represents the sigmoid activation function.

To explore the relationship between each channel of the feature map, we multiply the weight vector Wby the corresponding F∈Rto generate the final output feature map F∈R.Note that Fare produced by Fpassing through the 1×1 projection layer, which is used to calibrate the number of channels. The final output Fcan be represented as:

where ⊗denotes the channel-wise multiplication between the attentive weight vector W∈Rand the feature map F∈R.
Different from SE-Block,we not only introduce the global-pooling operation to capture the global context of the feature, but also apply the max-pooling operation due to the consideration that the max-pooling module can extract the local distinctive information to better infer the channelwise highlights of the feature maps. Therefore, by combining the global context and local statistic provided by the globalpooling and max-pooling modules separately, we empirically conclude that using both of the pooling operations simultaneously greatly improves the representational power of the network.
2.4. Channel attention based feature fusion module
The feature outputs from the dual paths have different levels of feature representations. The spatial feature captured by the spatial path mainly contains the detailed low-level spatial information. In contrast, the output from the semantic path mostly encodes the high-level semantic information. Due to the gap between the spatial and semantic information,it is less effective to fuse features of different levels directly.
Therefore, we propose CAFFM to ensure the effective fusion for the features of different levels to narrow the gap between the spatial-level and semantic-level features. Similar to FAM, our proposed CAFFM is also based on the channel attention mechanism, and its structure is shown in Fig. 5.

Fig. 4 Structure of the proposed FAM.
Given the different feature levels, we first element-wise add the output feature of the spatial path X∈R,and that of the semantic path X∈R, where H, W and C denote the height,the width and the number of channels of the feature map, respectively. This preliminarily fused feature map Xcan be formulated as:

The attentive weight vector Wfor CAFFM is provided following the same process as FAM, except that we adopt Fully-Connection (FC) layers instead of 1×1 convolutions to perform the dimensionality reduction and expansion transformations.The reduction ratio r is also set to 16.The process can be represented as:

where W(·) and W(·) represent the two FC layers that perform the dimensionality reduction and expansion transformations respectively, γ(·) denotes the ReLU activation function,and Sig(·) represents the sigmoid activation function.
To fulfil the goal of improving the quality of feature representations, the attentive weight vector W∈Ris explored to reweight the Xand Xto guide the feature selection,respectively.The feature selection can be viewed as a process of adaptively selecting the important or salient information and suppressing the redundant information from the spatial-level and semantic-level features, separately.
Because the preliminarily fused feature map Xis utilized to produce the attentive weight vector W, we argue that after the feature selection, the gap between the reweighted Xand Xis significantly narrowed, and both of the reweighted features are more suitable for the feature fusion. Lastly, we concatenate the reweighted Xand Xmto produce the final fusion output X, as shown below.
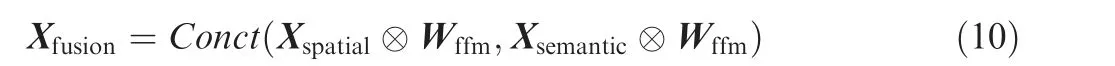
where ⊗and Conct(·) denote the channel-wise multiplication and the concatenation operation, respectively.
3. Experiments
3.1. Datasets
To evaluate the performance of our proposed method, intensive experiments are conduced based on the ISPRS Potsdam and Vaihingen datasets.There are six object categories in both of the datasets,comprising impervious surfaces,buildings,low vegetation, trees, cars and clutter/background. The clutter/background class includes ground objects like water bodies,containers, tennis courts and swimming pools.
The Potsdam dataset consists of 38 image patches, each of which has a resolution of 6000 pixel×6000 pixel. There are three types for patches, comprising True Ortho-Photo(TOP), Digital Surface Model (DSM) and normalized DSM(nDSM) files. Each TOP image tile consists of red (R), green(G), blue (B) and near-infrared (IR) bands. But we only focus on the three-channel RGB data in this study. The spatial resolution of both TOP and DSM files is 5 cm. 24 out of 38 patches are labelled with ground truth, and only these 24 TOP tiles are used for training and validating the proposed approach in this paper.
The Vaihingen dataset contains totally 33 image patches with a spatial resolution of 9 cm. Each patch has two types of data, TOP and DSM. There are 3 bands in the TOP image tiles which are IR, R and G channels, and we explore the IRRG tiles in our experiments. Particularly, 16 out of 33 patches involve labeled ground truth. These 16 TOP tiles are utilized to train and validate the semantic segmentation model proposed in this study.The dimensions of the image tiles in the Vaihingen dataset are roughly 2000 pixel×2000 pixel.
3.2. Evaluation metrics
To assess model performance for accuracy and efficiency comprehensively, we use five metrics including the Intersection over Union (IoU), mean IoU (mIoU), Overall pixel Accuracy(OA), inference speed and model complexity.

Fig. 5 Structure of the proposed CAFFM.
Specially, IoU, mIoU and OA are utilized as the accuracy metrics. We define IoU as follows:

where TP, FP, TN, FN are the number of true positive, false positive, true negative, false negative separately.
The remaining two metrics are used for the efficiency evaluation. The inference speed is evaluated in frame per second(fps), and the model complexity is represented regarding the number of parameters in the model.
3.3. Experimental protocols
We follow the protocolto construct the training and validation sets. For the Potsdam dataset, 18 out of 24 TOP image patches labelled with ground truth are selected for the model training. The remaining 5 images (with tile IDs 02–12, 03–12,05–12, 06–12 and 07–12) are employed for the model validation. Note that the tile 04–12 is discarded due to its possible mislabeling.For the Vaihingen dataset,11 out of 16 annotated TOP images are used to train the network. The remaining 5 image tiles (with tile IDs 11, 15, 28, 30 and 34) are employed to validate the model accuracy and efficiency.
In the Potsdam and Vaihingen dataset, the original largesized images are cropped into the tiles in a non-overlapping fashion with the dimensions of 512 pixel×512 pixel and 256 pixel×256 pixel respectively, for both of the training set and validation set. We employ random scales on the input images to augment the datasets during the training process.The scales contain {0.75, 1.0, 1.25, 1.5, 1.75, 2.0}. After scaling, we randomly crop the images into the fixed-size tiles for the model training. We train all the models from scratch. The maximum number of training epochs is set to 200 for Potsdam,and set to 400 for Vaihingen in our experiments.
We conduct experiments using Pytorch framework of version 1.1.0, together with Python of version 3.6.5. All experiments are performed on a 64 bits Intel i7-9700 K machine with 3.6 GHz clock speed and 16 GB RAM memory. One Graphics Processing Unit (GPU), GeForce GTX 1080Ti with 11 GB memory under CUDA of version 10.1, is employed in this work.Ubuntu of version 18.04 is utilized as the operating system.

3.4. Results and comparisons with state-of-the-art methods
In this section, we evaluate our model on two high-resolution aerial image segmentation datasets: the ISPRS Potsdam and Vaihingen datasets.We report the state-of-the-art performance achieved by our proposed Aerial-BiSeNet with respect to the favorable segmentation accuracy, real-time inference speed and low model complexity, all of which would satisfy the requirements of aircraft-based applications. Notice that the clutter/background class accounts for very little percentage of pixels,making it negligible.In order to decrease the interference from clutter/background,we only select the other five categories from both datasets in our experiments.
We compare the performance of our Aerial-BiSeNet with four other state-of-the-art DCNNs-based approaches, including BiSeNet,FCN-32s,U-Netand CAN.In the experiments, Xception39is adopted as the context path of BiSeNet, and the base models we select for FCN-32s and CAN are ResNet101 and ResNet50,respectively. For UNet,the default number of channels is set to 16,and the transpose convolution is utilized as the upsampling operation.
3.4.1. Experimental results for accuracy evaluation on Potsdam
Experimental results on the Potsdam dataset are shown in Table 1. Our Aerial-BiSeNet achieves the highest results with respect to the overall accuracy metrics of mIoU and OA,which are 76.07%and 86.92%respectively.In the meantime,the proposed model outperforms the others in terms of per-class IoU on the categories of impervious surfaces, buildings and low vegetation. U-Net obtains the best values in terms of perclass IoU on the remaining two categories of trees and cars.From the perspective of accuracy evaluation, the leading results on Potsdam solidly validate the effectiveness of our Aerial-BiSeNet.
3.4.2.Experimental results for accuracy evaluation on Vaihingen Experimental results on the Vaihingen corpus are presented in Table 2. Compared with the Potsdam dataset, the dataset of Vaihingen supplies less amount of image data for the model training. Therefore, lightweight models would avoid the over-fitting and obtain better results. In Table 2, we can see that our Aerial-BiSeNet is the best model that outperforms the other advanced models by a considerable margin on the overall accuracy metrics of mIoU and OA, as well as perclass IoU on the category of cars. Meanwhile, Aerial-BiSeNet ranks the second for per-class IoU on the categories of impervious surfaces, buildings, low vegetation and trees,and these results are very close to the best values.The superior results on Vaihingen again firmly validate the effectiveness of our Aerial-BiSeNet.
Consequently, the accuracy results on both Potsdam and Vaihingen show that our Aeral-BiSeNet is the successful and powerful framework for semantic segmentation of highresolution aerial images.
3.4.3. Experimental results for efficiency evaluation
Both of the inference speed and model complexity are crucial factors for semantic segmentation algorithms with respect to aircraft-based remote sensing applications. For a fair comparison, we randomly choose input images with the resolution of512 pixel×512 pixel from the Potsdam dataset. We conduct our experiments for the efficiency comparison using the images with such resolution.

Table 1 Experimental results for accuracy evaluation on Potsdam.

Table 2 Experimental results for accuracy evaluation on Vaihingen.

Table 3 Experimental results for efficiency evaluation.
Table 3 presents the comparisons of speed and number of parameters between our methods with other approaches during the validation process. It shows that our framework achieves the lower model complexity and real-time inference speed compared with the other state-of-the-art networks.There is a significant decrease in the number of parameters(only 765×10parameters) for Aerial-BiSeNet, which makes our model extremely lightweight. In addition, the inference speed of our method is about 132 fps which is very close to the result of BiSeNet (135 fps), and this real-time inference speed achieved by Aerial-BiSeNet is much more efficient than FCN-32 s, U-Net and CAN.
Accordingly,the advantages of our Aerial-BiSeNet,including the competitive segmentation accuracy, low model complexity and low-latency inference, simultaneously satisfy the requirements for accurate,efficient,as well as real-time semantic segmentation of aerial imagery based on aircraft platforms.
4. Discussion
In this section,we first discuss how our approach improves the segmentation results of the confusing objects in highresolution aerial images. Then, we step-wise decompose our model to conduct the ablation study of each module,including the proposed RFM, FAM and CAFFM. In the following experiments, we evaluate all the comparisons on both of the Potsdam and Vaihingen datasets.
4.1. Segmentation of confusing objects in high-resolution aerial images
In Fig.6,image patches(a)and(b)are selected from the Potsdam dataset, while patches (c) and(d)are from the Vaihingen dataset. Aerial images acquired with high spatial resolutions exhibit a high diversity of objects, which often incurs visual confusion. For the cases of objects with large intra-class variations, cars have different colors and models in patch (a) and(c),and buildings have different shapes and colors in patch(d).For the cases of objects with small inter-class differences,areas of low vegetation and trees in patch (b), together with impervious surfaces and cars in patch (c) are similar in appearance.
To alleviate the problem of large intra-class variations,enlarging receptive fields for acquisition of more contextual information would effectively improve the segmentation accuracy.In addition,enhanced semantic information is vital in lowering inter-class similarities.
Therefore, firstly, RFM is proposed in the spatial path to encode rich multi-scale contextual information by means of expanding the sizes of receptive fields using the cascaded convolution kernels, as well as adjusting the eccentricities controlled by dilated convolutions with different dilation rates.Secondly, channel attention based FAM is proposed to represent more discriminative semantic information in the semantic path.Due to the reinforced representational power of contexts and semantics, our Aerial-BiSeNet is able to resolve both issues of high intra-class variations and low inter-class differences.Thirdly,CAFFM makes the fusion of the spatial feature and semantic information from the dual paths more effectively to improve the model performance.
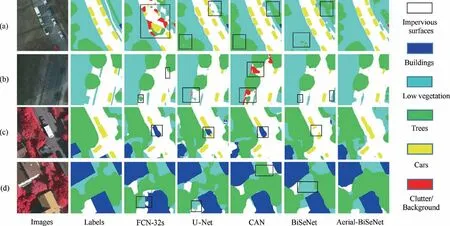
Fig. 6 Visual presentation of example segmentation results.
Fig.6 illustrates the visual presentation of the segmentation results outputted by Aerial-BiSeNet. In tile (a), various cars with large intra-class variations are clearly segmented by Aerial-BiSeNet, but FCN-32s fails to do so. U-Net, CAN and BiSeNet are unable to clearly classify the areas of low vegetation and trees which are similar in appearance, whereas Aerial-BiSeNet obtains the better segmentation results. In tile(b), FCN-32s fails to segment the black car sheltered by trees.U-Net generates more blurring segmentation edges, and CAN misclassified impervious surfaces as clutter. BiSeNet achieves similar segmentation accuracy as Aerial-BiSeNet does, however, it misclassifies the areas of low vegetation and trees.For tile (c), only Aerial-BiSeNet succeeds in segmenting the white car which is similar to the building roof or impervious surfaces.In tile(d),we observe that the areas of low vegetation and trees are more correctly segmented by Aerial-BiSeNet,and its segmentation results on buildings are more coherent and accurate. Visualization analysis demonstrates the effectiveness of Aerial-BiSeNet with respect to semantic segmentation of the confusing objects with high intra-class variations and low inter-class differences in high-resolution aerial images.
4.2. Discussion on RFM
Similar to RFBNet,our proposed RFM consists of three components: (A) the three parallel branches of convolution layers with different kernels covering multiple receptive field sizes, (B) the dilated convolutions with varying dilation rates to stimulate the relation between the receptive field size and eccentricity,and(C)the residual connection.The effectiveness of the fixed receptive field size and eccentricity has been verified in the study on RFBNet.Therefore, we further explore the effects of different dilation rate sets on the segmentation accuracy, and the experimental results are shown in Table 4.In detail, we select anouther two dilation rate sets that mean the assignment of different eccentricities to the corresponding parallel branch, including {3, 2, 1} and {7, 6, 5}, to compare with the dilation rate set{5,3,1}we choose to represent the proper relation between the receptive field size and eccentricity. Table 4 shows that our selected dilation rate set{5, 3, 1} achieves the best performance with respect to mIoU on both of the Potsdam and Vaihingen datasets, as well as OA on Potsdam. Therefore, it is verified that the dilation rate set {5, 3, 1} is the preferred solution.
4.3. Discussion on FAM
We show the effectiveness of FAM by replacing it in the model with two alternative channel attention modules, including SEBlockand ARMrespectively, while keeping other parts of Aerial-BiSeNet unchanged. Particularly, SE-Block merely utilizes the operation of global average pooling to squeeze the global spatial information into a channel descriptor, then it captures the channel-wise dependencies through the excitation operation.ARM is proposed in BiSeNetwhich could be considered as a simplified version of SE-Block. The experimental results are listed in Table 5.
For the Potsdam dataset, FAM achieves the best accuracy results in terms of both mIoU and OA. For Vaihingen, FAM obtains the highest value in terms of mIoU and the second highest values in terms of OA.Similarly,for the Potsdam dataset, SE-Block obtains the same best value of 86.92% on the OA metric as FAM does,and it also achieves the highest result regarding OA on Vaihingen.Although SE-Block could achieve some satisfactory results, concerning the comprehensive accuracy evaluation on both datasets, FAM is the most powerful and effective channel attention module for semantic segmentation of high-resolution imagery.
The global-pooling operation in FAM is applied to capture the global context of the feature, and the max-pooling operation extracts the local distinctive information of the feature.Therefore, we believe that the concatenation of both average-pooled and max-pooled features is able to encode more discriminative channel-wise attentive features.

Table 4 Ablation study on RFM for different dilation rate sets (%).

Table 5 Comparisons of FAM with other channel attention modules (%).

Table 6 Comparisons of CAFFM with other fusion methods(%).
4.4. Discussion on CAFFM
In this subsection, in order to show the effectiveness of CAFFM, we compare CAFFM with four other fusion methods separately, including the element-wise summation, concatenation, FFMand a modified version of CAFFM (m-CAFFM). Specifically, FFM is proposed in BiSeNetwhich is also based on the mechanism of SE-Block. Compared with CAFFM, m-CAFFM explores the concatenation of both average-pooled and max-pooled features which is adopted in FAM, rather than utilizing the average-pooling operation alone at the squeeze stage. The experimental results are presented in Table 6.
The results suggest that CAFFM achieves the highest results with respect to OA together with the second best results with respect to mIoU for both of the Potsdam and Vaihingen datasets.Although m-CAFFM and FFM obtains the best values regarding the mIoU metric on Potsdam and Vaihingen respectively, CAFFM has the most noticeable improvement in the segmentation performance for the comprehensive assessment.
Concatenation of both average-pooled and max-pooled features has already proven its effectiveness in FAM,however,we argue that the max-pooling operation would extract the distinctive information from outputs of the dual paths,and focus more on the difference between the spatial and semantic features, which is not suitable for the feature fusion module.Therefore,we state that m-CAFFM containing the concatenation operation of both average-pooled and max-pooled features is less applicable to Aerial-BiSeNet than our proposed CAFFM in which the average pooling is utilized alone.
4.5. Discussion on the light-weight dual-path structure
To achieve the requirements for high segmentation accuracy,real-time inference speed, low model complexity, and high computation efficiency for semantic segmentation of highresolution images based on aerial platforms, there are mainly three key concepts for the light-weight and dual-path structure of Aerial-BiSeNet:
(1) The spatial path shall have shallow layers with the strong capability for encoding multi-scale contextual information to resolve the issue of high intra-class variances. And the channel capacity of the spatial path ought to be carefully devised to avoid increased complexity as well as loss of accuracy.
(2) The semantic path could directly use matured lightweight networks (e.g., Xception) with deep layers. The novel channel attention module would be explored to capture channel-wise dependencies for enhanced categorical semantics, to mitigate the low inter-class difference issue.
(3) An efficient fuse module is proposed to combine both types of features representations, which are low-level spatial features and high-level semantics, respectively.Simple or direct fusion,such as summation and concatenation, ignores the diversity of both types of features,resulting in worse performance and hard optimization.We successively use the preliminary fused features to guide the lower-level feature maps to include semantic predictions, as well as to assist the higher-level feature maps to restore spatial details, by means of channel attention mechanism. This effectively fills the gap between the spatial and semantic features, and makes the fusion of the features at different levels more effective.
5. Conclusions
The lightweight dual-path structure is becoming a leading choice for real-time semantic segmentation of high-resolution aerial images. The biggest concern with this technique is the design of the overall lightweight architecture,the feature encoder module for capturing sufficient contextual information,the feature attention module for selection of discriminative semantic features, and the feature fusion module for the heterogeneous outputs from the dual paths. However, the existing deep networks usually ignore the inconsistency of different types of the data outputted from the dual paths, and in the meantime fail to balance the segmentation performance between accuracy and efficiency,due to their high model complexity and weak representational capability. Therefore, it is quite necessary to further explore a more efficient and effective dual-path framework for semantic segmentation of highresolution aerial images.
In this paper, a notable Aerial-BiSeNet model is presented for accurate and real-time semantic segmentation of highresolution aerial images. With the aid of lightweight and dual-path architecture comprising RFM for encoding multiscale contexts, FAM for discriminative semantic feature selection and CAFFM for efficient feature fusion,Aerial-BiSeNet is able to meet the requirements for (A) low-latency operations,(B)limited computing resources on aerial platforms,(C)excellent balance between accuracy and speed for the model performance, as well as (D) the improved segmentation accuracy of the confusing objects in high-resolution aerial images.Through experiments, we have confirmed that the proposed Aerial-BiSeNet achieves the superior performance with respect to both accuracy and efficiency simultaneously on the ISPRS Potsdam and Vaihingen benchmarks.
We derive a lightweight model in which spatial features are learned with enlarged receptive fields as well as multi-scale contexts, and a novel channel attention based fusion module combining the spatial feature and semantic information. We hope that our architectural prototype will be utilized as a basis for real-time semantic segmentation networks in the remote sensing domain. Although our real-time model achieves the leading results with respect to accuracy and model complexity,the inference speed of the method is slightly lower than BiSe-Net. In our future work, we will consider devising more lightweight and efficient contextual feature encoder module,feature attention module and feature fusion module to improve the model. In addition, we will continue to apply our real-time method into other computer vision tasks based on aerial platforms, such as the flying bird detectionand the target detection from SAR images.
Declaration of Competing Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Acknowledgements
This work was co-supported by the National Natural Science Foundation of China (Nos. U1833117 and 61806015), and the National Key Research and Development Program of China (No. 2017YFB0503402).
 CHINESE JOURNAL OF AERONAUTICS2021年9期
CHINESE JOURNAL OF AERONAUTICS2021年9期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Optimal trajectory and downlink power control for multi-type UAV aerial base stations
- Effects of flow parameters on thermal performance of an inner-liner anti-icing system with jets impingement heat transfer
- Effects of wing flexibility on aerodynamic performance of an aircraft model
- Aerodynamic performance enhancement of co-flow jet airfoil with simple high-lift device
- Adaptive fuzzy terminal sliding mode control for the free-floating space manipulator with free-swinging joint failure
- Influence of longitudinal-torsional ultrasonicassisted vibration on micro-hole drilling Ti-6Al-4V