
基于梅尔频率倒谱系数与短时能量的低信噪比语音端点检测
2021-10-22 07:30颜夕宏张生平陈建飞
南京师大学报(自然科学版) 2021年2期
柏 顺,颜夕宏,张生平,陈建飞,张 胜
(1.南京邮电大学电子与光学工程学院,江苏 南京 210023)(2.南京梧桐微电子科技有限公司,江苏 南京 210023)
语音端点检测(voice activity detection,VAD)是指在一段语音信号中区分出话音段和无话音段,并标出起点和终点,其本质上是寻求能够区分话音段和噪音段的特征参数来对其进行准确划分[1]. VAD是语音信号处理领域中至关重要的一环,其性能优劣直接影响语音系统的处理性能. 在低信噪比环境下,噪音会对语音特征参数的提取结果造成极大干扰,从而导致检测准确率大幅下降[2-4]. 优秀的VAD算法可以降低处理时间、适应各种复杂的噪声环境,因此对之进行深入研究具有较高的实用价值.
语音端点检测的方法有两类:一是针对语音的特征参数来讨论的,如能零比[5]、谱熵[6]、频带方差[7]、自相关函数的主次峰值比等,其中短时能量对噪音的敏感度较高,因此常被作为辅助参数使用[8-9];二是基于模型基础,主要方法有支持向量机[10]和神经网络[11]等. 然而,虽然已有大量VAD算法被提出,但在低信噪比环境中VAD准确率仍然较低.
有学者[12]指出MFCC的第一分量的绝对值占据了很高的比重,且具有语音追踪的能力,文章中将其提取并结合谱熵进行端点检测,得到了较高的VAD准确率(约提高了20%). 本文发现MFCC的前3个分量均具有语音追踪能力,为了提高特征参数在端点检测中的敏感度,提出将MFCC敏感度较大的3个分量的绝对值进行累加,再与短时能量进行相比,得到的结果作为端点检测的特征参数(梅尔能量比,记为MFRE),最后利用模糊C均值聚类算法和双门限法进行端点检测[13]. 本文从TIMIT语音库选取语音并使用NOISE_92噪声库中不同类型噪声进行加噪处理,之后对带噪语音进行端点检测. 仿真结果表明,本算法在5 dB、0 dB、和-5 dB的噪声环境下,较传统的MFCC倒谱距离、能零比、谱熵等算法有较高的识别准确率.
1 MFCCa的提取
1.1 MFCC特征
梅尔频率倒谱系数的分析是基于人的听觉机理,即依据人的听觉实验结果来分析语音的频谱,期望能获得好的语音特性[14]. 以Mel为单位的感知频率Fmel与实际频率f的具体关系表示如下
Fmel=1 125log(1+f/700).
(1)
1.2 计算MFCCa
语音信号s(n)经过加窗函数ω(n)分帧处理后得到yi(n),其中i表示分帧后的第i帧.则yi(n)满足:
yi(n)=ω(n)*x((i-1)*inc+n), 1≤n≤L, 1≤i≤fn,
(2)
式中,ω(n)为窗函数,一般为矩形窗或汉明窗,L为帧长,inc为帧移长度,fn为分帧后的总帧数.
(1)对每一帧信号进行FFT变换,从时域数据转变为频域数据:
X(i,k)=FFT[yi(n)].
(3)
(2)对每一帧FFT后的数据计算谱线的能量:
E(i,k)=[X(i,k)]2.
(4)
式中,i表示第i帧,k表示频域中的第k条谱线.
(3)将第i帧语音信号的能量谱E(i,k)通过Mel滤波器并求和,得到的能量S(i,m):
(5)
在频域中相当于把每帧的能量谱E(i,k)与Mel滤波器的频域响应Hm(k)相乘并相加,m是指第m个Mel滤波器.
(4)把Mel滤波器的能量取对数后进行离散余弦变换,即可得每一帧的MFCC倒谱系数:
(6)
式中,n是离散余弦变换(DOC)后的谱线.
MFCC(i,n)是一个i*m维矩阵,i是语音信号帧数,m是滤波器个数.文献[12]将第一个滤波器的MFCC系数定义为MFCC的第一分量,现用MFCC1(i)表示,MFCC1(i)实际上是一个i*1维数组,并对语音有跟踪能力,图1给出了信噪比为0 dB环境下MFCC的前四分量与语音段(直线开始,虚线结束)的波形.
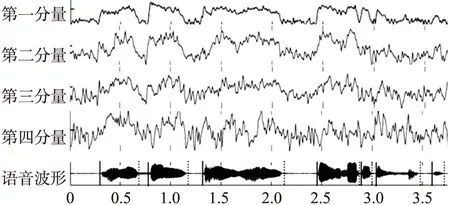
图1 MFCC前4分量与语音段比对图Fig.1 Comparison between the first four components of MFCC and speech segments
从图1可以用肉眼看到不仅第一分量具有语音追踪能力,第二、三分量的波形走势和语音起点、话音段、终点模糊对应,但是第四分量的波形开始紊乱不具备这一特性应舍弃.由于第一分量的幅值均为负数,第二、三分量的幅值绝大多数为负数,可将第二、三的波形向下平移至其幅值的最大值为零,保证所有的MFCC均为负值. 然后,将每一帧所对应的三个滤波器MFCC系数取绝对值后再相加,记为MFCCa(i):
MFCCa(i)=|MFCC1(i)|+|MFCC2(i)|+|MFCC3(i)|.
(7)
此时,MFCCa(i)是一个i*1 维数组,i是帧数.
2 短时能量
由于语音信号的能量随时间而变化,清音和浊音之间的能量差别相当显著.因此对短时能量进行分析,可以描述语音的这种特征变化情况.计算第i帧语音信号的短时能量公式为:
(8)
短时能量在话音段的数值较高,在噪音段的数值较低,依据短时能量可以在高信噪比下区分话音段和噪音段以及在低信噪比作为辅助参数结合其他特征参数进行端点检测.
3 梅尔能量比的计算
虽然MFCCa(i)可以很好地区分有话段和噪音段,对话音段的敏感程度较高,但是在低信噪比环境下效果大打折扣,无法单独作为语音特征参数进行端点检测.针对这一问题,本文将MFCCa(i)与短时能量结合,提出梅尔能量比进行端点检测.MFCCa(i)的幅值在话音段低于噪音段;而能量的幅值在话音段高于噪音段,可将MFCCa(i)与能量逐帧相比得到梅尔能量比:
MFRE(i)=MFCCa(i)/E(i).
(9)
理论上梅尔能量比的值在话音段的值小于噪音段.仿真结果如图2(例句为一段男声“蓝天,白云,碧绿的大海”,信噪比5 dB).

图2 信噪比5 dB环境下梅尔能量比与语音对应关系图Fig.2 MFRE and speech correspondence graph in SNR 5 dB
可以看出梅尔能量比更加突出了话音段和噪音段的差异,且在噪音段的波形平稳整齐,可以作为端点检测的特征参数.
4 结果与讨论
4.1 双门限法高低阈值的计算
上文中提出了使用梅尔能量比进行端点检测具有一定的优越性和可行性.但是使用双门限法还需要进行阈值的确定.模糊C均值聚类(fuzzy C-means clustering,FCMC)算法在众多模糊聚类算法中是应用最广泛且成功的[15],可用该算法可将带噪语音的特征参数分为两类,并根据聚类中心的数值center进一步确定阈值并对其进行端点检测,双门限法的高低阈值TH与TL可由下公式求得:
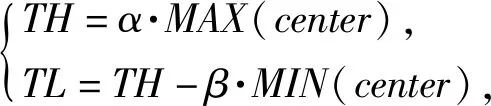
(10)
式中,α与β为经验参数;实验数据表明,随着信噪比的增加聚类中心center1与center2的数值差距成倍的增加,因此,可以根据两个聚类中心的差距调整α与β的数值,进而达到自适应调整高低阈值的目的.
4.2 端点检测正确率的计算
在端点检测的过程中会出现将话音帧误检成噪音帧的情况和噪音帧错检成话音帧的情况[16].本文在计算准确率的时候同时考虑了这两种情况,计算步骤如下:
(1)设语音信号共有X帧.(2)共有P帧话音帧误检成噪音帧,共有Q帧噪音帧错检成话音帧.(3)准确率S=1-(P/X+Q/X).
4.3 实验结果
从TIMIT语音库选取50条语音信号并从NOISE_92噪声库选取不同类型的噪音对其加噪,最后对带噪语音进行端点检测. 测试语音的平均时长为3 s,话音段约为8段. 梅尔能量比(MFRE)的检测结果的准确率与传统的MFCC倒谱距离检测方法、能零比(EZR)、谱熵(SE)进行比对,结果如表1所示.

表1 端点检测准确率比较Table 1 Comparison of VAD
从仿真结果可以看出,使用梅尔能量比在不同类型的噪音下进行的端点检测都表现出优越的性能. 传统的MFCC倒谱距离检测方法会在信噪比为-5 dB失效,而梅尔能量比仍然保持较高的准确率,且高于对照位30%左右. 说明本算法在低信噪比环境下能较好地实现语音端点检测,具有良好的抗噪性和鲁棒性.
5 结论
本文分析了MFCC倒谱距离前3分量具有语音跟踪的特性,结合短时能量提出了以梅尔能量比作为语音特征参数的端点检测算法. 实验结果表明,本方法在瀑布、下雨、机舱运转等复杂噪声环境中,和在低信噪比情况下,其VAD准确率较传统MFCC倒谱距离等方法均有较大的提升.
在实验中发现,会出现对比较明显的话音帧漏检和有规律的噪音帧误检的情况. 这是因为不同的噪音环境,导致高低阈值并不是一直处于最佳值. 后期可以针对这一问题进行进一步讨论.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
红领巾·探索(2019年2期)2019-04-19
畅谈(2018年17期)2018-10-28
物联网技术(2018年6期)2018-06-29
电子技术与软件工程(2016年22期)2016-12-26
爱你(2016年17期)2016-11-26
数字技术与应用(2016年8期)2016-05-14
互联网天地(2015年11期)2015-05-11
阅读(2014年11期)2014-11-07
