
基于MSE与PSO−SVM的机车轮对轴承智能诊断方法
2021-10-20 01:00张龙彭小明熊国良王良黄婧胡俊锋
铁道科学与工程学报 2021年9期
张龙,彭小明,熊国良,王良,黄婧,胡俊锋
(1. 华东交通大学 机电与车辆工程学院,江西 南昌 330013;2. 中国铁路南昌局集团有限公司 科学技术研究所,江西 南昌 330002)
机车轮对轴承的工作环境复杂,非平稳载荷和系统内部非线性因素会导致轴承振动信号表现出非平稳性和非线性。振动信号的特征可以在时域、频域以及时频域进行提取,然而传统的信号处理方法难以有效地处理这种随时间变化的非平稳信号[1]。经验模态分解(Empirical Mode Decom‐position, EMD)和小波变换等时频分析虽然可以处理振动信号中的非平稳性,但并不能提取信号的非线性特征信息。许多非线性参数如近似熵、分形维数等被广泛应用于机械设备的故障诊断,然而,近似熵的一致性较差[2];分形维数的计算依赖数据的长度,且比较耗时,不适合在线监测[3]。RICHMAN 等[4]提出了另一种表征时间序列复杂性的测度方法—样本熵(Sample Entropy),样本熵是一种通过非负数来度量时间系列的非线性和复杂度,其对于自身数据的匹配程度要优于近似熵,且度量准确度远高于近似熵。然而样本熵只能反映时间序列在单一尺度上的复杂度,对振动信号特征提取的效果不理想。在样本熵的基础上,COSTA 等[5−6]提 出 了 多 尺 度 熵(Multiscale Entropy,MSE)的概念,用来反映时间序列在不同尺度下的自相似性和复杂程度。机车轮对轴承不同故障类型会导致振动信号的复杂度不同,而信号的复杂度体现在不同尺度上。因此,多尺度熵可作为特征参数表征信号在不同尺度上的复杂性,能有效解决单一尺度下振动信号特征提取的局限性问题。利用人工智能技术实现滚动轴承的智能诊断成为近年来的研究热点。张龙等[7]利用时序模型和自联想神经网络实现对齿轮故障程度的评估。李笑梅等[8]提出一种基于集合经验模式分解(EEMD)和径向基函数神经网络(RBFNN)相结合的滚动轴承故障诊断方法,实现对列车滚动轴承的故障识别。赵春华等[9]通过鲸鱼优化算法(WOA)的支持向量机(SVM)对滚动轴承故障类型进行识别。SVM 是一种以统计学理论为基础的机器学习方法,其克服了神经网络过拟合和过度依靠经验基础来确定结构类型的缺点,在分析处理局部极小、非平稳性和非线性等问题时表现出强大的优越性[10],在解决小样本问题时表现出独特的优势和良好的应用前景[11−13]。基于以上分析,针对DF4 型内燃机车轮对轴承单一和复合故障在内的7种不同健康状态的识别问题,本文用MSE 提取轴承原始信号的多尺度非线性特征信息,然后使用PSO 优化后的SVM 对轴承不同故障进行类型识别。该方法结合了MSE的信号非线性特征提取和SVM 在小样本复杂非线性分类方面的优势。为验证所提方法在机务段轴承检测中的应用效果,将DF4 型内燃机车轮对轴承实际故障数据用于本次实验研究。
1 多尺度熵(MSE)
1.1 样本熵算法
时间序列{x(i)|1 ≤i≤N}由N个数据组成,样本熵的求解过程如下:
1) 选定一组维数为m的矢量序列Xm(1),Xm(2),…,Xm(N-m+ 1)
其 中:Xm(i) ={x(i),x(i+ 1),…,x(i+m+ 1)}1 ≤i≤N-m+ 1。
2) 定义向量Xm(i) 与Xm(j) 之间的距离d[Xm(i),Xm(j)]为两者对应元素中最大差值的绝对值,即:
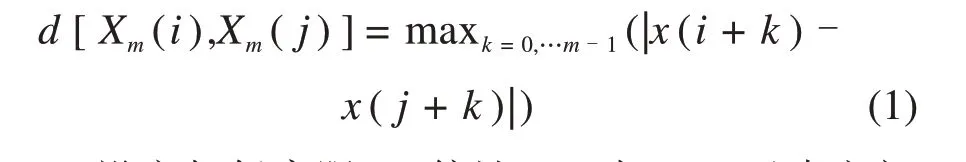
3)设定相似容限r,统计Xm(i)与Xm(j)元素之间距离不大于r的j(1 ≤j≤N-m,j≠i)的数目,记为Bi。对于1 ≤i≤N-m,定义:

1.2 多尺度熵算法
MSE 能够反映不同尺度下时间序列的自相似性和复杂程度,其实质就是计算多尺度下的样本熵值[3]。多尺度熵的计算过程如下。
1)对于时间序列{x(i)}=x(1),x(2),…x(N),利用下式定义粗粒化序列P(τ):

1.3 仿真实验
MSE与4个参数的取值密切相关,即嵌入维数m,尺度因子τ,样本点数N和相似容限r,正确选取各参数是获得理想的特征提取效果的前提[14]。嵌入维数m一般取值为1 或2[4];另外,文献[16]研究表明,在MSE 应用中,需要保证每个时间尺度下有足够的数据量,嵌入维数m通常取为2,设置m=2。在实际应用中尺度因子取值过大会丢失信号中的重要信息,计算效率低下;取值较小则不能完全提取振动信号的信息,无法完整反映时间序列的复杂度[3],设置最大尺度因子τmax=20。为研究数据长度N和相似容限r对MSE算法的影响,特进行以下仿真实验。
将不同点数(设N分别为3 000,4 000和5 000)下的白噪声和1/f噪声分别用于数据长度N对MSE算法影响的分析。设置MSE 算法的嵌入维数m=2,相似容限r=0.15×SD(SD 为原始序列的标准差),最大尺度因子τmax=20。由图1 可知:不同点数N下的白噪声和1/f噪声,其熵值曲线较为接近,表明样本点数N对MSE算法影响较小。另外,从文献[15]可知,样本熵的计算过程中含有循环嵌套,随着样本点数的增加,计算量呈指数增加;样本点数过小则不能完全提取信号的全部信息,因此本文取N=4 000。
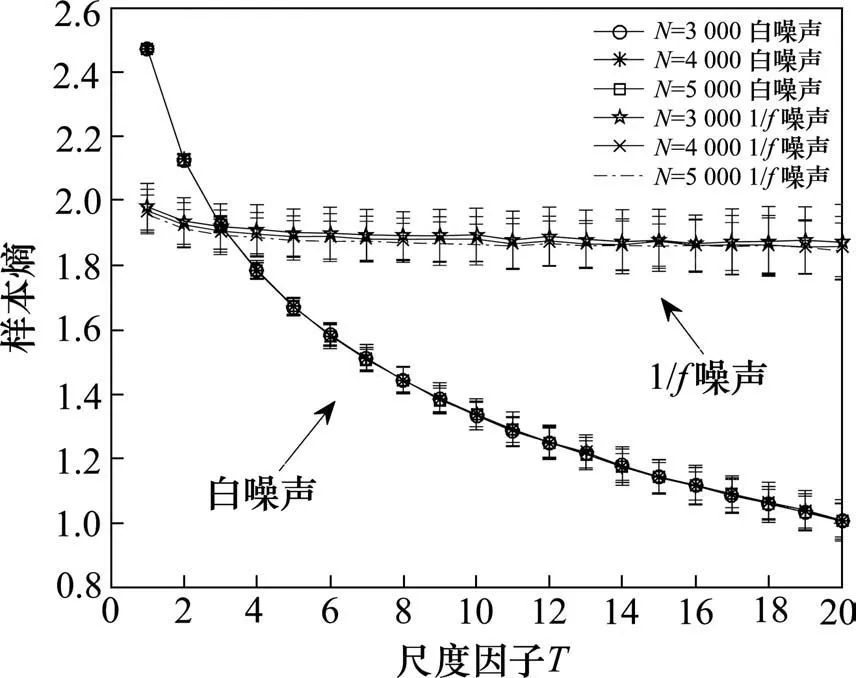
图1 不同长度N下MSE算法对2种噪声分析结果Fig.1 Analysis results of two kinds of noise by MSE with different N
将不同相似容限(设r分别为0.1×SD,0.15×SD,0.2×SD)下的白噪声和1/f噪声分别用于相似容限r对MSE 算法影响的分析。结果如图2 所示,其中,设置MSE 算法的嵌入维数m=2,样本点数N=4 000,最大尺度因子τmax=20。由图2可知:r对MSE算法结果影响较大,当r较小时,匹配的模式特征较多,因此熵值较大;当r较大时,匹配的模式特征较少,故熵值较小。通常为使样本熵与其反映的时间序列关联性更大,r一般取值为(0.1~0.25)×SD[5]。r过大会使大量模式特征满足相似条件,有效信息中混杂着大量冗余信息,难以获得理想结果;r过小则符合相似条件的模式少,难以正确反映信息时间序列的本质。故本文选择r=0.15×SD。
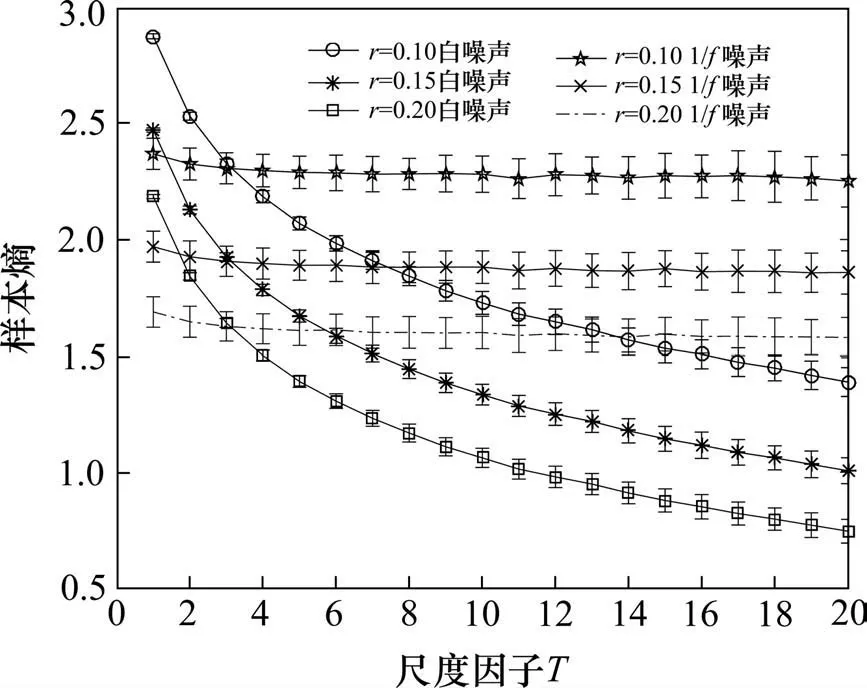
图2 不同r条件下MSE对2种噪声分析结果Fig.2 Analysis results of two kinds of noise by MSE with different r
2 故障诊断方法模型
2.1 PSO-SVM算法的实现步骤
以RBF 为核函数的SVM 需要确定2 个参数,分别为惩罚因子c和参数g(RBF 核函数中的方差),其中惩罚因子c用于控制样本超出误差的惩罚程度。参数c和g对SVM 分类准确率起着主要影响,利用PSO 对上述2 个参数寻优,从而可以提高SVM分类的准确率。PSO寻优公式如下所示:
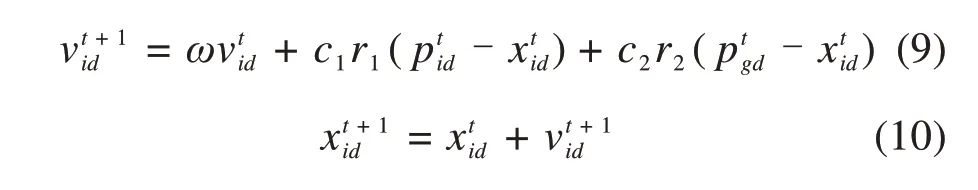
式中:ω为惯性因子,通过调整ω的大小,可以对全局寻优性能和局部寻优性能进行调整;d=1,2,3,…,D;i=1,2,3,…,n;t为当前迭代次数;vid为粒子的速度;c1和c2为非负常数,称为加速常数,用于调节学习的最大步长;r1和r2为分布于[0,1]之间的随机数,用于增加搜索的随机性。
PSO-SVM 算法的主要步骤如图3 所示。首先确定适应度函数,然后初始化种群和速度,计算适应度函数值,若满足终止条件,则输出最优解;否则继续更新个体和速度,直至找到全局最优解,算法终止。
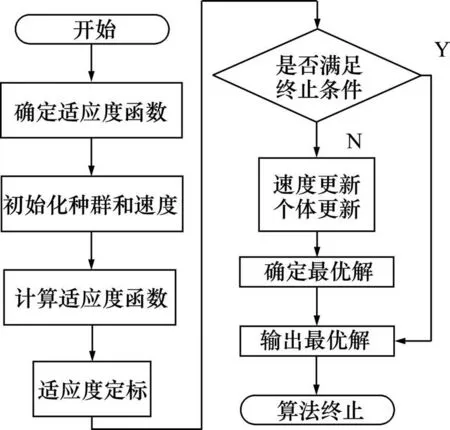
图3 PSO-SVM算法流程图Fig.3 Procedure of PSO-SVM
2.2 所提故障诊断方法流程
基于多尺度熵的机车轮对轴承PSO-SVM 故障诊断方法流程如图4所示,主要步骤如下:

图4 所提故障诊断方法的流程图Fig.4 Flow chart of the proposed fault diagnosis method
1) 分别采集DF4 型内燃机车包含单一和复合故障在内的7种不同健康状态的轮对轴承试件的振动信号数据。
2) 对输入的特征向量进行归一化处理,除去样本集中的奇异样本,从而减少误差。
3) 将MSE 特征提取后的特征样本作为PSOSVM模型的训练和测试样本。
4) 利用PSO 对SVM 的径向基核函数(RBF)参数g及惩罚因子c寻优。
5) 利用PSO 优化后的SVM 对测试集进行分类,确定机车轮对轴承的故障类型。
3 实验研究
3.1 实验数据来源与介绍
实验在南昌铁路局机务段完成,实验轴承为NJ2232WB系列圆柱滚子轴承,轴承内外径分别为160 mm 和290 mm。图5 为本次实验所用的包含单一和复合故障在内的轴承试件,均是从DF4 型内燃机车上拆卸下来的实际故障轮对轴承。在进行实验前,所有的机车轮对轴承均进行了清洗,以免影响实验效果。实验过程中,轴承由图6所示的JL-501 型机车轴承检测台驱动。检测台主要由主轴箱、电气系统、液压系统和台身组成。主轴箱是试验台的关键部分,待测机车轮对轴承的检测安装和旋转等过程都需要通过主轴箱来实现,主轴转速范围为120~1 200 r/min;液压系统主要是对待测机车轴承进行径向加载和卸载。

图5 机车轮对轴承6种故障类型实物图Fig.5 Six wheelset bearings with various faults

图6 JL-501机车轴承检测台Fig.6 JL-501 test bench for locomotive bearings
本文借助该检测台实现轮对轴承的驱动和加载,设置转速500 r/min,径向载荷当量1.4 MPa。通过由磁座安装在轴承外圈的3 个CA-YD-187T 型加速度传感器和NI USB-4431型采集卡完成振动信号采集,采样频率设置为20 kHz,本文分析数据来自垂直方向传感器B。
表1 为正常(无故障)及图5 所示包含单一和复合故障在内的6 种故障状态共7 种不同健康状态机车轮对轴承的故障信息和样本数量,并依次编号为1~7。实验过程中分别采集7种不同健康状态机车轮对轴承试件的振动信号,每个样本包含4 000个数据点,每种轴承健康状态各有样本数为100。图7 为7 种轴承状态的信号时域、频域波形图,从图7可以明显看出,正常轴承的振动较故障轴承更平稳,外圈故障和内圈故障都能较明显地看到周期性故障冲击,但仅从时域波形中无法判别具体的故障类型。在频域波形图中,故障轴承信号和正常轴承信号的能量都主要集中于2 000~4 000 Hz,仍然无法从频域中区分故障类别。因此,需要进一步对机车轮对轴承振动信号进行分析处理,提取出能表征信号类型的特征向量。
3.2 特征提取
尺度因子τ=20,得到20 个粗粒向量序列,计算每个序列的样本熵,可以得到一个20 维的特征向量作为PSO-SVM 的输入。图8给出了图7中7种状态信号对应的MSE 计算结果,从图中可以看出随着尺度的增加样本熵呈现逐渐下降的趋势,不同机车轮对轴承振动信号的MSE 值在第20 个尺度时基本没有交叉重叠,区分较为明显。若选择超过20 个尺度的MSE 作为振动信号的特征向量,会造成特征信息冗余,影响故障特征的分类识别精度;而若只选择较小的尺度因子上的MSE 值构建故障特征向量,则无法完全反映轮对轴承振动信号中蕴含的故障信息,最终故障识别准确率会较低。同时,可以看出单个尺度上的熵值曲线存在交叉重叠,无法有效区分故障类型,需要在多个尺度上进行分析。由此说明,多尺度熵能够综合多个尺度上的熵值信息,从而能更好地区分机车轮对轴承的运行状态。
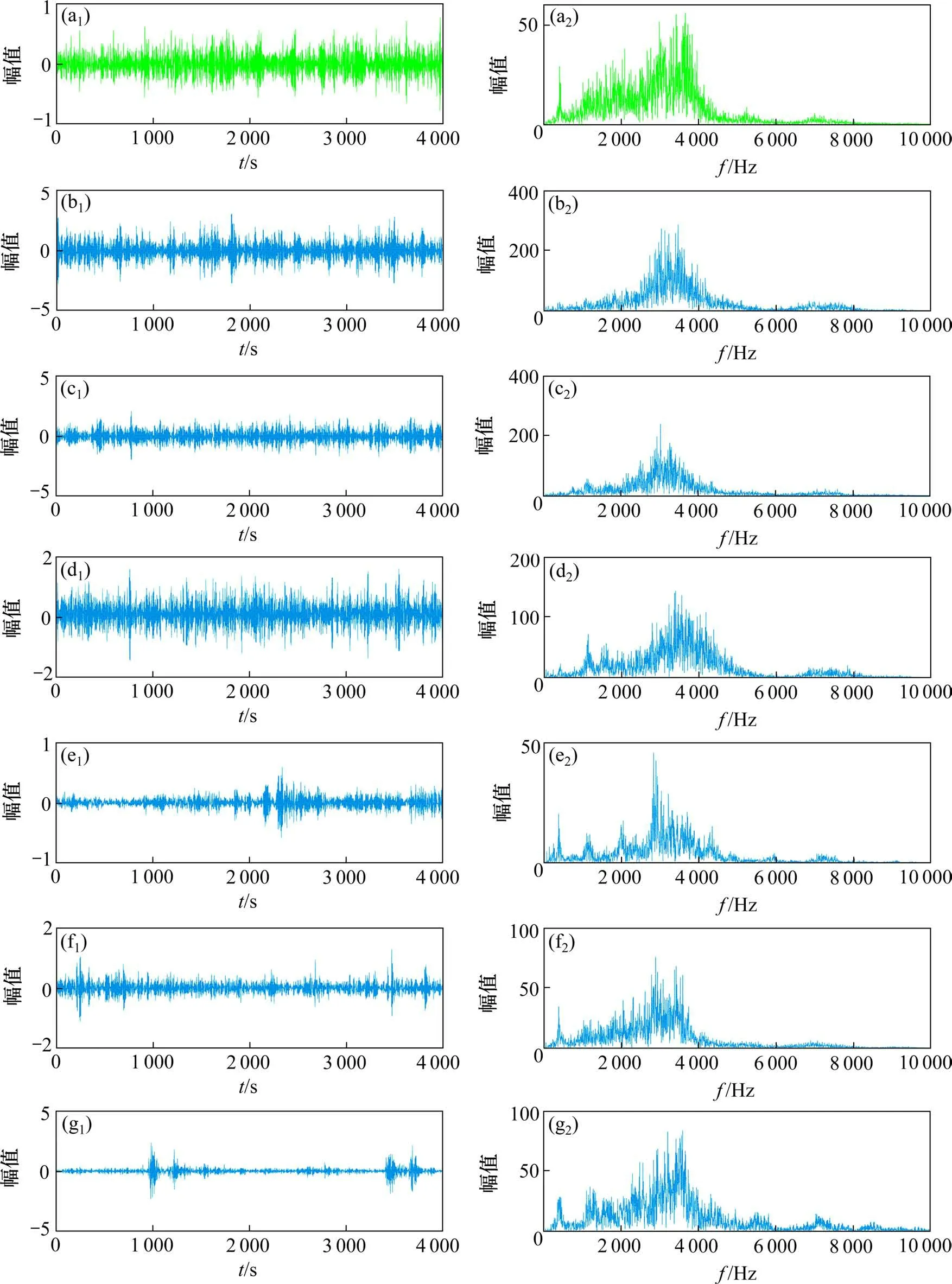
图7 机车轮对轴承7种健康状态的时域和频域信号Fig.7 Time and frequency signals of 7 health conditions
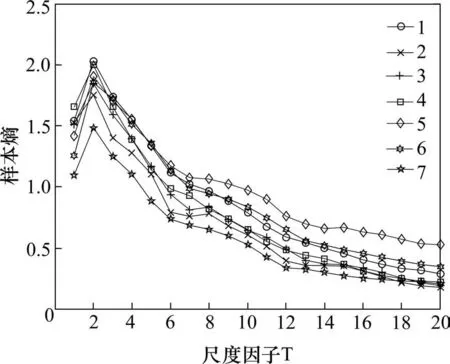
图8 图7中7种机车轮对健康轴承信号的多尺度熵Fig.8 Multiscale entropy of the 7 signals in Fig.7
3.3 PSO-SVM建立和训练
PSO-SVM 的建立首先要求设定相关初始网络参数。将20 个尺度的样本熵作为输入特征向量,由表1 可知每种轴承状态有100 个样本,将100 个样本分为训练集和测试集,随机选取60 个样本作为训练集,剩余40 个样本测试集。PSO 算法参数中设定ωmax=0.9,ωmin=0.4,最大迭代次数设为200,并作为终止的条件。由于需要优化的参数个数较少,将粒子群的规模设为20,加速常数c1=1.5,c2=1.6,最大速度vmax设为3。采用交叉验证(Cross Validation, CV)的方法在一定程度上可以找到SVM 的最优参数,能有效地避免训练过程出现过学习和欠学习。因此,本文以CV 意义下的准确率作为PSO 的适应度函数值,CV 的参数设为3,即测试集分为3部分进行交叉验证。某次PSO算法经过200 次迭代,所得惩罚因子c,径向基核函数(RBF))参数g的最佳参数为:c=3.022,g=2.432。以此参数训练SVM 模型,并将训练后的PSO-SVM模型用于测试样本的判别,某一次的分类结果如图9 所示。模型对280 个测试样本的识别准确率达到99.29%,仅有2 个样本被误判,分别是状态1 和状态4的各一个样本被误判为状态3和状态1。
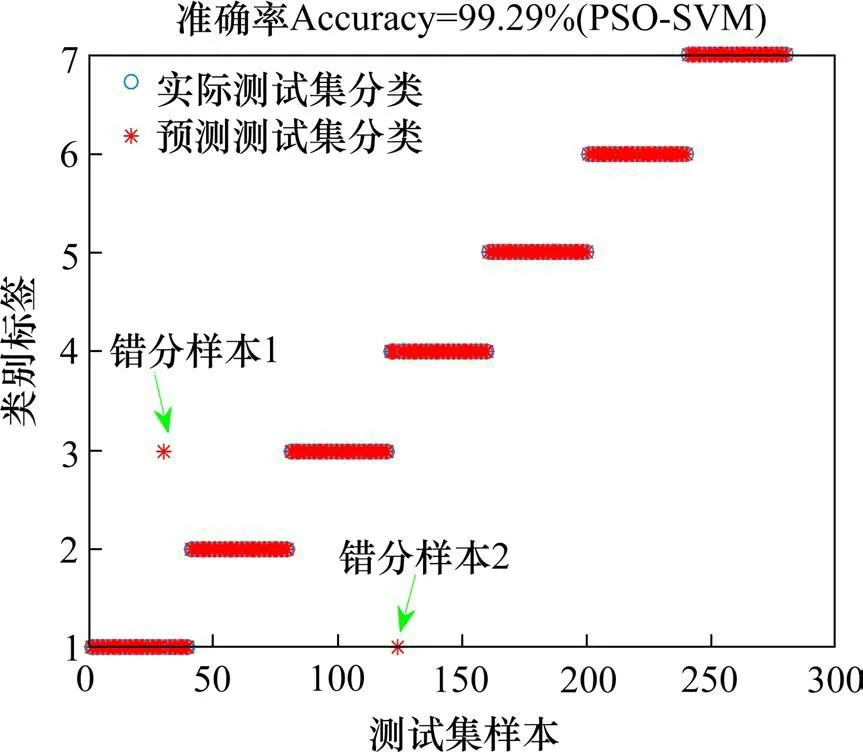
图9 PSO-SVM分类结果Fig.9 PSO-SVM classification results
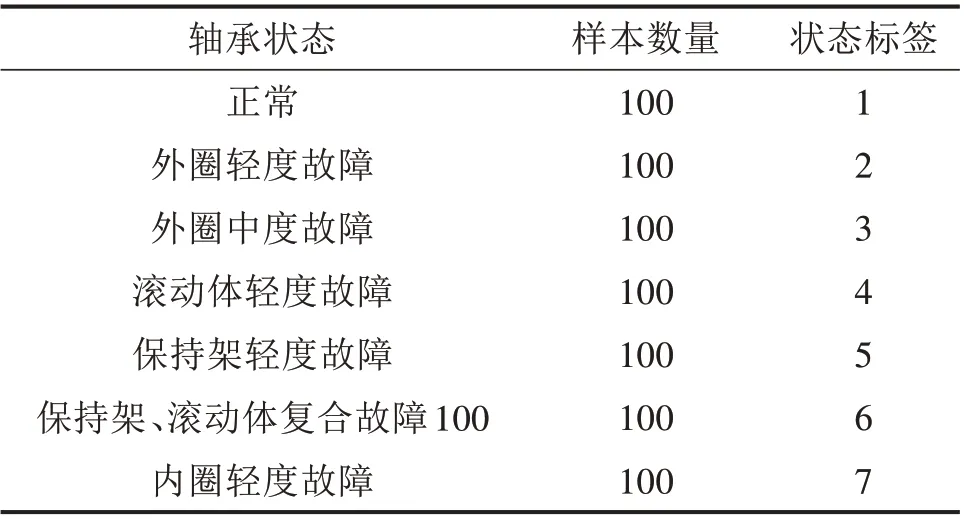
表1 机车轮对轴承故障类型及样本数量Table 1 Fault types and sample size of wheelset bearings
为使实验结果更具严谨性和一般性,重复上述训练和测试过程100次,每次训练和测试样本在样本空间中随机划分,最后PSO-SVM 模型的100次试验的平均准确率为99.15%。实验结果表明,尺度因子τ=20 时,MSE 能够有效地提取机车轮对轴承的故障特征,PSO-SVM 模型对不同故障及不同故障程度能很好区分。表2 给出了100 次测试准确率的平均混淆矩阵,沿矩阵对角线的单元格显示正确分类样本的百分比,而非对角线的其他单元格表示错误分类。以第2行为例,它们显示属于故障类型2 的样本错误地分类为3 类型、6 类型的比例分别为0.45% 和0.02%。另一方面,数值99.53%显示了正确分类样本的比例。因此,对角线处单元格的值越接近100,则意味着分类识别效果越好。
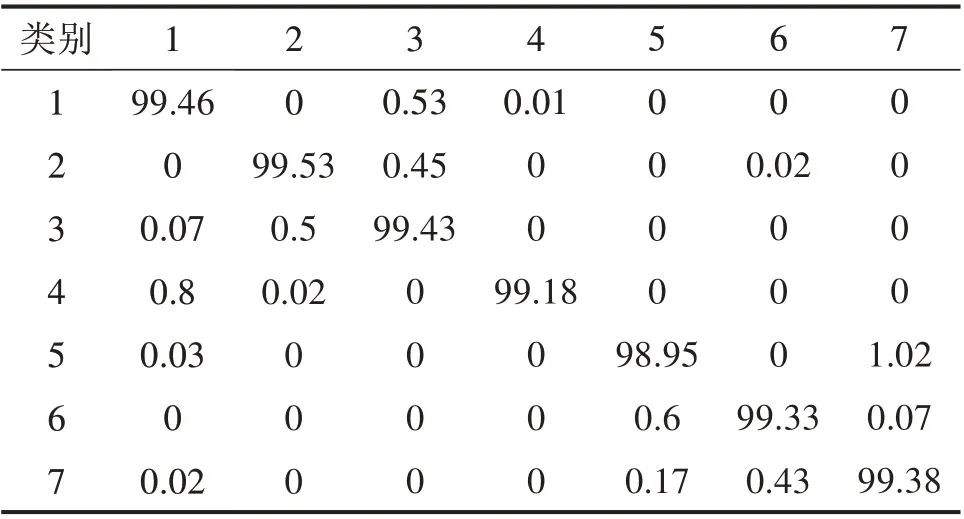
表2 100次测试的平均混淆矩阵Table 2 Averaged confusion matrix of 100 tests %
值得注意的是,不同的错误分类会导致不同的风险,可通过敏感性和特异性等统计指标进行评估。
1)敏感性=正确分类的正样本数/实际正样本数
2)特异性=正确分类的负样本数/实际负样本数
分类性能的统计指标值见表3,表3 中最重要的项目是轴承状态类型1的敏感性和特异性,因为该敏感性越小,表明故障漏诊的风险更高。另一方面,类型1的特异性越小,表明健康状况被误诊为故障的可能性越高,这将导致不必要的停车检查。表2中的其他单元格主要表示各种轴承状态之间错误分类的可能性,由于与故障和健康状态之间的错误分类相比,各种故障状态之间的错误分类风险相对较小,因此它们的重要性不大。由表3可知,该模型对类型1 具有较高的敏感性和特异性,健康状况被误诊为故障的实际风险相对较低。

表3 混淆矩阵中各类别的统计指标值Table 3 Statistics of confusion matrix %
3.4 方法对比
将MSE 特征输入到参数不经优化的SVM 模型中进行故障分类识别,惩罚因子c,径向基核函数(RBF)参数g按人为经验一般设为:c=2,g=1[11]。同样取SVM 模型运行100 次后的平均准确率为实验的最终识别准确率,得到平均准确率为98.86%。再将MSE特征输入到参数网格寻优法Grid-SVM模型中进行故障分类识别,c和g的取值范围设置为2−10:0.2:10(指数步长均为0.2),分类准确率采用3 折交叉验证,最优参数得到100 次平均准确率为98.92%。不同SVM 模型的分类结果如表4 所示,显然经过粒子群优化的SVM 优于参数未经优化的SVM 和参数网格寻优法的Grid-SVM,PSO 的参数寻优能力更佳。由此表明,PSO-SVM 的模式识别能力强,分类准确率更高,尤其在样本基数大的时候,其漏诊和误诊的风险更低。
另外,采用多尺度近似熵(Multiscale Approxi‐mate Entropy,MAE)和小波包分解提取机车轮对轴承的振动信号的特征向量,再分别输入到PSOSVM,SVM 和Grid-SVM 模型中,与本文基于MSE 与PSO-SVM 的故障识别方法作对比。MAE的嵌入维数m=2,最大尺度因子τmax=20,样本点数N=4 000,相似容限r=0.15×SD。从每组故障类型中随机选取60 个样本作为训练数据,剩余40 个样本测试集,进行100次的训练测试,识别结果如表4所示;小波包分解中采用Db10小波对100个样本信号均进行3 层小波分解,选取低频到高频8 个自带信号的能量作为特征向量。同样从每组故障类型中随机选取60 个样本作为训练数据,剩余40 个样本测试集,进行100次的训练测试,识别结果如表4 所示。由表4 可知,MSE 的特征提取效果优于MAE 和小波包分解,与本文方法识别准确率99.15%相比,本文基于MSE 与PSO-SVM 的故障识别方法具有一定的优势。
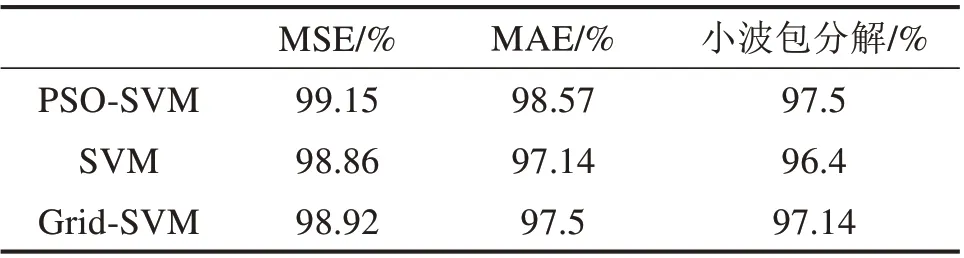
表4 不同方法的分类结果Table 4 Classification results using different methods
4 结论
1) MSE 能有效表征机车轮对轴承振动信号在不同尺度下的复杂性和非线性;采用粒子群算法对SVM 中的参数g和惩罚因子c进行优化处理,避免人为经验选取参数产生的误差,增加了参数选取的准确性和自适应性。
2) 提出一种基于MSE 和PSO-SVM 的机车轮对轴承故障识别模型,经过实验验证,故障识别模型对机车轮对轴承实际故障识别准确率高,并且模型运行稳定、自适应性强,为提高机务段检测机车轮对轴承故障的精度提供了一种有效的方法。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
防爆电机(2021年3期)2021-07-21
数学大王·低年级(2021年2期)2021-02-21
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
汽车观察(2019年2期)2019-03-15
小猕猴智力画刊(2018年7期)2018-08-08
太空探索(2016年5期)2016-07-12
发明与创新·中学生(2016年7期)2016-05-14
时代英语·高三(2014年5期)2014-08-26
