
基于PDF 版式特征的文献篇章结构细粒度抽取方法研究
2021-10-17 13:21:08赵婉婧刘敏娟刘洪冰段飞虎
农业图书情报学刊 2021年9期
关键词:分类号
赵婉婧,刘敏娟*,刘洪冰,王 新,段飞虎
(1.中国农业科学院农业信息研究所,北京 100081;2.农业农村部农业大数据重点实验室,北京 100081;3.同方知网数字出版技术股份有限公司,北京 100192)
1 引言
随着大数据时代的到来,各学术领域的科研人员在面对海量学术资源的同时,也承受着信息泛滥带来的困扰。以篇级文献为最小单位的信息服务方式已无法满足用户日益精准的多粒度信息服务需求,用户在信息检索时真正需要的是文献中具有挖掘价值的 “微信息”“知识元”等细粒度[1]片段信息。基于文献级粗粒度的知识组织方式,存在着数据加工程度低、语义关联性差等问题,而知识组织的颗粒度直接决定了信息的检索方式和服务效果。李伟、冯儒佳等[2,3]提出传统的科技论文组织方式没有实现对论文多粒度的组织,大多着眼于篇级的显性信息,研究者们在获取学术信息时无法检索出多粒度的知识,将信息检索深入到文献的内容层次,向用户提供细粒度的信息、精确的知识是一种必然趋势。
在这一背景和需求下,传统的科技期刊出版方式开始逐步转型,数字出版模式应运而生。科技期刊数字出版是对期刊内容进行数字化转换,碎片化、结构化存储,建立数据库,通过二次开发实现多平台查询、在线阅读、传播,知识信息高效共享的过程[4]。目前,国外期刊媒体的数字化发展已经度过了初期载体形式的转变,不仅实现了信息内容在电子终端上的全文显示,而且实现了论文标题、作者信息、图表以及参考文献等的模块化处理,能够将论文以多渠道、多方式、多粒度更加快捷地呈现给读者,大幅增强了信息传播的实效性。相较之下,中国期刊媒体的数字化发展整体相对滞后,依旧延续着传统的编辑出版模式,处于转型过程,形成了传统出版与数字出版并存的局面,在编辑出版的整个流程体系中还是传统模式占据主流[5],但中国的数字出版产业也正处于高速增长的阶段。颇具代表性的有玛格泰克的XML/RichHTML 加工服务利用智能算法技术,实现了全文内容生成标准的XML 文件。北大方正书畅系统采用云计算技术,基于XML 结构化数据标准,为出版单位构建一个基于互联网环境的一体化数字化生产平台。虽然发展势头良好,但由于类型单一、投资规模限制,仍然有很大一部分传统出版企业停留在数字出版的传统模式,仅实现了载体形式的变化,而非产品内容结构的变化,没有对资源进行结构化处理[6]。
因此,本文研究的文献篇章结构细粒度抽取方法针对尚未实现数字出版的文献资源以及大量历史存量资源的结构化处理,具有一定现实意义和应用价值。本方法也可延伸应用到特种文献[7]、灰色文献、电子档案等同样具有细粒度抽取和组织需求的其他资源类型。结构化、碎片化后的文献可以用于各类语料库的构建,作为知识计算与挖掘的细粒度语料。对细粒度信息进行组织揭示,突破了传统基于整篇文献组织揭示的方法和深度,并按照新的知识组织体系进行重组,满足用户多元化利用的需求。
2 相关研究
文献资源篇章结构的细粒度抽取[8]是实现知识细粒度组织与检索发现的首要前提和关键步骤,因此篇章结构的分析与识别方法研究应得到进一步关注。国内学者曹树金等[9]提出由于期刊论文各级标题清晰地反映了论文的研究思路和结构,因此利用标题标识的节段单元可以认为是有价值且可操作的细粒度单元。陆伟等[10]认为布局分析是通过对原始PDF 文档转化而来的图片进行分析,将图片分割成为具有相同成分的片段。逻辑结构分析是使用位置特征、字体特征、布局特征以及OCR 之后的文字特征判断出上述片段所属的类别(标题、正文、作者、页头、页尾等)。万里鹏[11]对非结构化到结构化数据转换方法进行了比较研究,提出一种非结构化到结构化数据转换模型,从理论和实践上基本实现了非结构化数据到结构化数据的转换,但支持的文件结构比较单一,不能对结构复杂的文件完成数据转换。宋艳娟[12]对基于规则的信息抽取方法进行了研究,实现了基于XSLT 规则的HTML 文档的信息抽取,设计实现了一个基于XML 的PDF 文档信息抽取原型系统,但仅是一个原型系统,功能还需进一步完善,而且对抽取对象进行了假设,抽取规则不具备普适性。
一些国外学者利用机器学习的方法在文本结构化分析与识别领域开展了相应研究,SIMONE 等[13]探讨了人工神经网络在文本图像分析与识别(DIAR-Document Image Analysis and Recognition)以及版面布局分析与结构化方面的应用。MINH-THANG 等[14]借助学术论文丰富的文本特征,使用条件随机域模型(CRFConditional Random Field)开发了一个发现工具,显著提高了分类性能。
目前,未实现数字出版的文献资源和非结构化的历史存量资源多以PDF 格式进行存储,PDF 文档内容的抽取方式主要有两种:一种是通过分析PDF 文档的格式,直接将其内容抽取出来,进而获取需要的信息和数据;另一种是将PDF 文档转换成其他文档格式,通过间接抽取中间文档内容的方法抽取PDF 文档中的内容[15]。传统研究大多围绕第一种直接抽取的方法,基于规则重点关注于文献元数据的抽取,并且获得了较好的效果。然而,针对篇章形式结构的识别和抽取,由于学术论文的排版过于复杂多样,直接抽取方法多数情况下的效果并不理想。
为此,本文研究提出一种基于PDF 版式特征的文献篇章结构细粒度抽取方法,并设计构建一套数据处理系统,通过对文档的版式特征进行分析计算,根据加工精确度的需要,采取机器自动或人机结合的手段对PDF 文档的篇章结构进行细粒度的碎片化处理。该方法具有较强适应性,不需提前制定规则,为实现文献资源细粒度的组织揭示、挖掘计算奠定基础。
3 基于PDF 版式特征的文献篇章结构细粒度抽取方法
3.1 研究思路
针对非结构化文档分析与识别的关键核心步骤就是对文档的版面结构和版式特征进行分析,这种版面分析的方式很大程度上提高了对非结构化文档的自动化识别效率[16]。
本文按照文章的逻辑结构与阅读顺序对一篇PDF文档的章、节、段、图、表进行细粒度拆分、抽取和重组,并保留上下文顺序和层级关系。首先利用基于机器学习的版面识别算法,由系统自动抽取文章中各级章节标题和图表并预判层级关系,然后根据章节标题在页面的坐标定位,将正文内容以段落为最小颗粒度自动匹配至相应位置,最终实现文档全文结构的细粒度识别、抽取和重组。处理过程中,可贯穿适度人工干预,确保抽取结果的精确度,保证经碎片化处理的数据可投入实际应用。
3.2 算法流程
基于机器学习的版面识别算法是将非结构化的PDF 文档转换生成为有行文结构的XML 文件的过程,如图1 所示,主要分为以下3 个步骤。
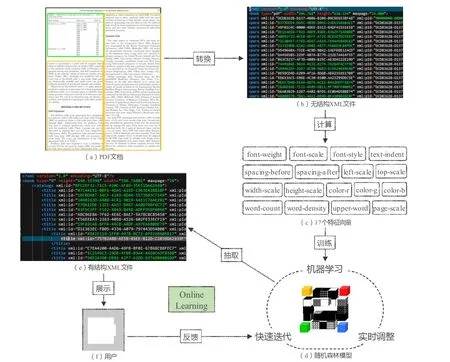
图1 基于机器学习的版面识别算法流程图Fig.1 Layout identification algorithm flow chart based on machine learning
(1)将PDF 文档(a)内部的所有文本、图表的页码位置、字体大小(以像素数表示)、段间距等信息抽取出来。然后,按照 《国家农业图书馆文献资源碎片化XML 描述标准》 将其统一转换为无章节标题、正文段落等行文结构的XML 文件(b)。该标准由本单位设计制定,遵循XML1.0 标准,对文献内部篇、章、节、段、图的版式特征信息进行规范化、数字化描述,基于此标准描述的文献信息可以通过解析转换为结构化数据以便机器学习和处理。XML 由一个根节点book构成,book 节点下包含两个子节点,分别是catalogs和parts,catalogs 表示文章的标题树,parts 表示文章的内容树,部分数据样例见图2。

图2 含有版式信息的XML 数据样例Fig.2 A sample of XML data with layout information
(2)针对XML 文件中所有的文本块进行数据分析,将每一篇论文XML 中的标题、段落等结构版式信息解析转换为机器学习所需要的特征向量(c)[17],关于特征向量的选定下文会进行详细阐述,根据机器学习模型和精确度评估合理选择特征向量,用以训练随机森林模型(d)。
(3)由步骤(1)转换而来的XML 文件是没有任何分类信息与行文结构的,通过对全部PDF 转换生成的XML 文件进行分析计算,得出每个文本块的特征向量,将特征向量的计算结果输入到步骤(2)训练完成的模型中,利用模型对目标文档的全部文本块进行预测分类,根据各个文本块的分类重新生成包含章节标题信息、图表信息及其层级结构信息的XML 文件(e)。
为了优化机器学习算法的适应性,采用Online Learning 的算法理论确保算法精确度,Online Learning能够根据线上反馈数据,快速实时调整模型,反映线上变化,提高线上预测的正确率。Online Learning 的主要流程包括:将模型的预测结果通过可视化界面展示给用户(f),用户借助可视化工具对预测结果进行人工干预,系统自动收集用户反馈数据,加入到训练集中,对模型进行迭代训练,使模型能够线上自动调整,形成闭环系统,从而达到不断提高算法识别正确率,降低人工干预的目的。
3.3 特征向量的选定
文献篇章结构的细粒度抽取本质上就是根据版式特征对文档内的全部文本块进行自动分类赋予标签的过程,通常学术论文PDF 文档的篇章结构大致可以分为文章标题、作者信息、摘要、关键词、分类号、各级章节标题、正文段落、参考文献以及页眉页脚等。
从版式特征角度分析文献篇章结构可以发现,区分上述类型的主要依据就是文本块的位置、字体、字号和行距等格式因素。因此,本方法中选定了与文本块格式相关的17 个特征向量(图3),作为判断文本块是否为章节标题的主要依据,表1 为17 个特征向量的具体表现形式和判断标准。

表1 特征向量与特征描述Table 1 Feature vectors and feature descriptions

图3 与文本块格式相关的17 个特征向量Fig.3 Seventeen feature vectors associated with the format of text block
通过对步骤(1)中获取的XML 进行分析计算,得出每个文本块(para)的上述17 个特征向量,将这17 个特征向量中不是数字的特征向量用标记编码器将其转换为数字,不同属性使用不同标记编码器。如font-style 属性可以取3 个不同值,需要建立一个懂得给这3 个属性编码的标记编码器,从而得出特征向量的数组x,对不同的文本块作相应的标记,作为机器学习的训练数据。本方法主要获取文章的章节标题,相应标记为 “0”代表文本块为正文,“1”代表文本块为文章一级标题,“2”代表文本块为文章二级标题,“3”代表文本块为文章三级标题,以此类推,从而得出对应的标记y。
经实测,17 个特征向量对于模型的训练均有贡献,但重要性有大有小,这些特征差异有助于机器学习对文本块分类进行正确的推断和预测。17 个特征向量的权重主要依赖于标注的训练样本通过随机森林机器学习算法得出,不同训练样本的17 个特征向量的权重不一样,因此通过训练不同的模型可以实现对版式特征各异的文档章节标题的识别与抽取。
4 实验与分析
4.1 数据来源
为了验证方法的可行性和有效性,我们通过采集和购买手段分别从EIU、SAGE、OECD、IMF、World Bank 等平台或出版商获取到1.6 万学术论文、科技报告的PDF 全文数据作为训练集,验证算法的精确度和自动碎片化模板的实际应用效果。
4.2 实验过程
EIU 来源的PDF 全文版式特征较为独特统一,页面左侧留白,章节标题多位于留白区域;SAGE、OECD、IMF、World Bank 来源的PDF 全文版式特征高度近似,均为常见的通栏或分栏排版,章节标题居左或居中。因此,我们根据PDF 全文的版式特征将全部样本大致分为两类,EIU 来源的样本作为EIU 模板的训练集进行单独训练,SAGE、OECD、IMF、World Bank 来源的样本构成一个训练集,用以训练通用模板。
本算法中随机森林采用sklearn 库的算法模板进行训练。

可以通过改变n_estimators 和max_depth 参数的值,提升分类器的准确性,这两个参数被称为超参数(hyperparameters),分类器的性能由它们决定,根据实验样本测得n_estimators 取值180、max_depth 取值23能让分类器的性能达到理想效果。
4.3 结果分析
由图4 可以看出,随着迭代训练次数和训练样本数量的增多,模板的精确度得到有效提升,两个模板在实际应用中均效果良好,以节点为计算单位(节点指一个标题、段落或图表),自动抽取的平均正确率可达到80%以上,图5、图6 分别为两个模板自动抽取的可视化效果。在训练模板前,依据数据来源或版式特征对目标PDF 做一个大致的分析和分类,并据此分别构建训练集,分类训练机器学习模板,可以达到更高的精确度。在训练集构建方面,需要注意的是,训练集规模过小的情况下极易导致过拟合现象,但如果选择较大规模的训练集,则会消耗更多的样本。因此,训练集规模的投入和选择也需结合计算能力和实际情况进行综合考虑。
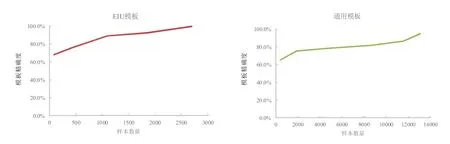
图4 模板精度与样本数量的关系Fig.4 Relationship between model accuracy and sample size

图5 EIU 模板自动抽取效果Fig.5 Result of automatic extraction of the EIU model

图6 通用模板自动抽取效果Fig.6 Result of automatic extraction of the common model
4.4 数据处理系统
基于上述研究方法和关键技术,设计构建了一套数据处理系统,已投入实际应用,用以辅助开展方法实效的验证与优化,同步推进日常的文献细粒度抽取相关业务,系统运行的技术路线详见图7。根据业务流程和功能需求,系统主要包含模板训练与管理模块、碎片化自动抽取模块以及人工审校与质检模块[18]等功能模块,可以实现对PDF 文档所包含的全部章节、小节、段落、图表的结构化处理和重组(图8),达到抽取方式自动化、处理流程规范化、业务管理智能化的目标,缩短数据处理流程周期,减少人工干预,有效保障文献细粒度抽取工作的质量和效率。
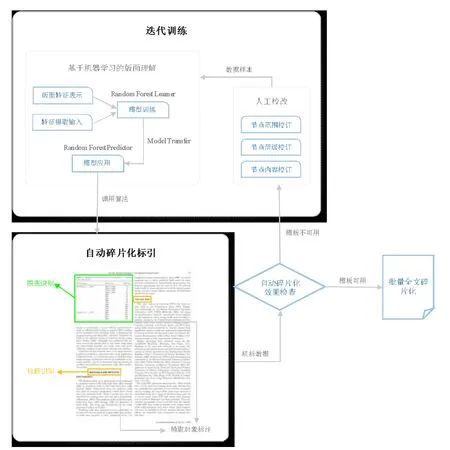
图7 系统运行技术路线Fig.7 Technical route of system operation

图8 细粒度自动抽取流程Fig.8 Process of fine-grained automatic extraction
5 结语
基于PDF 版式特征的篇章结构细粒度抽取,有助于解决基于规则抽取算法精确度低、适应性差的问题,对文献各级章节标题的自动抽取具有较好的效果。此外,根据不同业务精确度的需求,针对机器自动抽取的结果,增设人工审校环节,使正确率可以达到100%,且界面友好易用、操作便捷高效。经实测,审校人员利用校改工具,效率最快可达到每人每日审校提交8 200 个节点,约合2 000 页文献内容,很好地实现了机器自动或人机结合的多元数据处理方式。
然而,本文研究的方法也存在一定局限性,需要在后续研究工作中加以完善和提升。目前,关于自动抽取精确度的评估,仅限于各级章节标题及其层级结构的识别,不包含文中图片、表格的识别情况,当图片、表格被误判为非图片,且图片、表格中的文本恰好完全符合章节标题的特征时,则会直接增加章节标题识别的错误率。此外,由于不同来源的文献资源其PDF 文档版式特征过于复杂多样,基于机器学习的版面识别算法很难以一个或少量通用模板适用于多源异构的海量资源,模板的训练工作无法达到一劳永逸的效果。
针对上述问题,目前较为快速有效的解决方法是利用模板管理工具对版式相似或来源相同的资源进行机器学习模板的分别训练和对应选用。基于细粒度抽取质量与效率的长远考虑,上述问题还需在后续工作中进一步完善和改进,以不断提升文献结构化、细粒度自动识别与抽取的正确率。
猜你喜欢
课程教育研究·新教师教学(2015年24期)2017-09-27 06:15:42
课程教育研究·新教师教学(2015年9期)2017-09-26 16:48:17
课程教育研究·新教师教学(2016年10期)2017-04-10 04:32:17
课程教育研究·新教师教学(2016年1期)2017-04-10 01:48:12
课程教育研究·学法教法研究(2016年8期)2016-06-14 15:21:38
课程教育研究·学法教法研究(2015年7期)2015-05-30 10:48:04
课程教育研究·学法教法研究(2015年11期)2015-05-30 10:48:04
课程教育研究·新教师教学(2014年10期)2014-07-19 07:03:16
课程教育研究·新教师教学(2014年10期)2014-07-19 07:03:16
中国科技博览(2014年14期)2014-04-30 10:07:19
