
基于近红外光谱和SSA-ELM的苹果糖度预测
2021-10-12 00:37乔正明
食品与机械 2021年9期
乔正明 詹 成
(1. 常州纺织服装职业技术学院,江苏 常州 213164;2. 苏州科技大学,江苏 苏州 215000)
随着近红外光谱技术与化学计量方法的快速发展,近红外光谱技术被广泛地应用于农产品品质分析领域[1]。苹果糖度是苹果质量的重要评价指标,运用预测相关系数(correlation of prediction,CP)Rp预测均方根误差(root mean square error of prediction,RMSEP)σp作为苹果糖度预测结果的性能评价指标,很多学者利用近红外光谱技术进行了苹果糖度预测研究。赵杰文等[2]提出运用傅里叶变换近红外光谱仪采集苹果光谱,建立了基于偏最小二乘(partial least squares,PLS)的苹果糖度预测模型,其中Rp和σp分别为0.938 7和0.505 4。Zhang等[3]运用Nexus FT-IR光谱仪为苹果光谱采集仪器,建立了基于PLS的苹果糖度预测模型,Rp和σp分别为0.906和0.272,该方法主要用于测试套袋评估的精度,且要求苹果颜色均匀,因此整体预测精度不高。刘燕德等[4]运用Antaris FT-IR光谱仪采集苹果光谱,建立了基于遗传—偏最小二乘的苹果糖度预测模型,Rp和σp分别为0.954和0.797,该方法可以有效解决苹果颜色对于预测精度的影响,但是光谱冗余信息造成的误差过大。夏阿林等[5]建立了基于遗传—区间偏最小二乘的苹果糖度预测模型,运用Nexus 670 FT-IR光谱仪采集苹果光谱,Rp和σp分别为0.932和0.384,该方法虽然对比以往研究整体的预测精度有大幅提升,且算法的执行效率较高,但对于光谱冗余信息的处理仍然是个难题,整体收敛性差,复杂度较高。
为了进一步改善苹果糖度预测模型的精度,研究拟提出一种基于小波包变换的特征波长筛选和樽海鞘算法(salp swarm algorithm,SSA)改进极限学习机(extreme learning machine,ELM)的苹果糖度预测模型,以期为苹果糖度预测提供新的方法。
1 试验仪器
试验仪器采用美国Thermo Fisher公司的型号为Antaris II的近红外检测仪。该仪器集成了透射、反射、漫透射以及漫反射等不同检测模块,采用了Nicolet专利的高光通量、高速动态准直电磁式干涉仪,可以实现不同状态下的样品高效的、精准的检测与分析。
2 研究方法
2.1 建模思路
基于近红外光谱的SSA-ELM的苹果糖度预测模型的建模思路如图1所示。
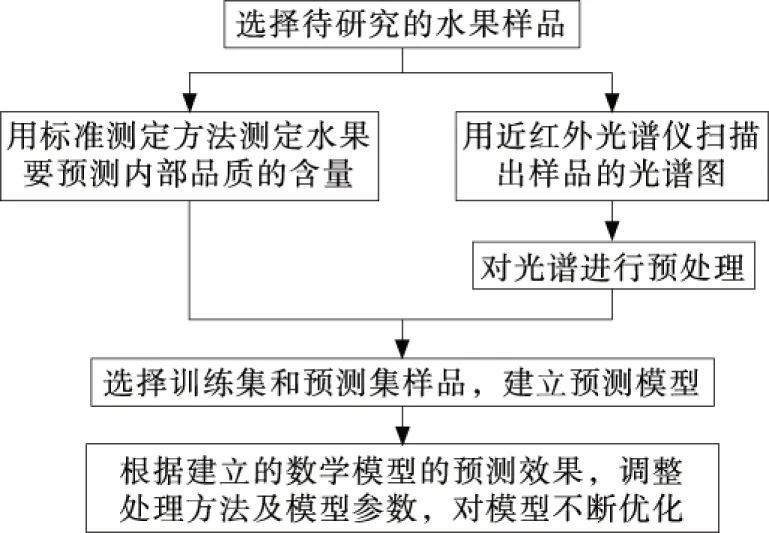
图1 苹果糖度预测建模流程Figure 1 Apple sugar content predictive modelingprocess
2.2 SSA算法
2.2.1 种群初始化 在标准SSA算法中,樽海鞘算法的种群规模为N,搜索空间维数为D,樽海鞘的位置为X=[Xn1,Xn2,…,XnD]T,n=1,2,…,N,食物位置为F=[F1,F2,…,FD]T,搜索空间上限为ub=[ub1,ub2,…,ubD]T、搜索空间下限为lb=[lb1,lb2,…,lbD]T,樽海鞘算法的种群随机初始化公式为[6]:
XN×D=R(N,D)×(ub-lb)+lb,
(1)
式中:
XN×D——樽海鞘位置向量(向量维数为N×D);
R(N,D)——N×D维的随机向量。
2.2.2 更新领导者位置 在标准SSA算法中,领导者引领整个樽海鞘群体的移动,用来搜索食物,这一操作的主要目的是使得领导者位置更新方式具有很强的随机性,领导者更新策略按式(2)计算:
(2)
式中:
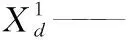
ubd,lbd——引领者个体在d维上的搜索上限和搜索下限;
c1、c2——随机数,处于[0,1];
c3——搜索平衡因子(主要用于平衡全局搜索和局部搜索能力,增强引领者的随机性和多样性)。
收敛因子按式(3)计算:
c1=2e(-4t/T)2,
(3)
式中:
c1——收敛因子;
t——樽海鞘算法的当前迭代次数;
T——樽海鞘算法的最大迭代次数。
2.2.3 更新追随者位置 根据文献[7]可知,初始位置、速度和加速度直接关系到追随者的位置,跟随者根据牛顿运动方程更新位置:
(4)
(5)
(6)
式中:
a——加速度;
v0——初始速度;
ta——迭代步长;
R——运动距离;
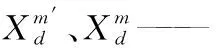
2.3 基于SSA-ELM的苹果糖度预测模型的建立
2.3.1 极限学习机 与传统的神经网络相比,ELM模型结构如图2所示[8]。
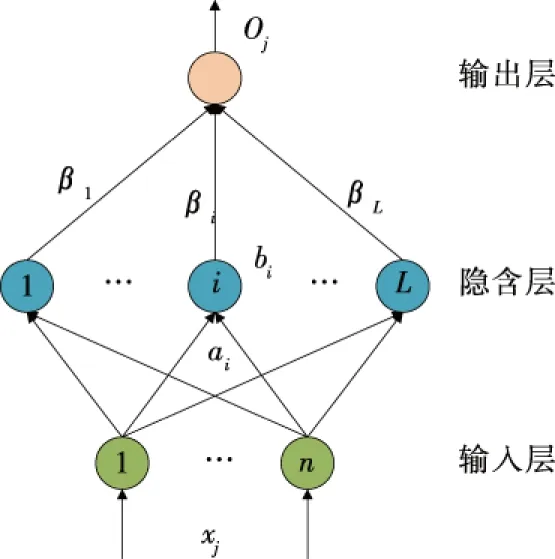
图2 ELM模型结构示意图Figure 2 ELM model structure diagram
对于N个训练样本(Xi,Ti),ELM模型的输入向量Xi=[xi1,xi2,…,xin]T∈Rn,ELM模型的目标向量Ti=[ti1,ti2,…,tin]T∈Rm,X为n×Q的矩阵,T为m×Q的
矩阵,Q为训练样本数量。因此,L个隐含层神经元的ELM模型输出为[9]:
(7)
式中:
Wi——ELM模型的输入权重,Wi=[wi1,wi2,…,win]T;
Wi·Xj——Wi和Xj的内积;
βi——ELM模型的输出权重;
g(x)——激励函数;
bi——ELM模型的第i个隐含层神经元的偏置。
ELM模型训练目的就是使式(8)的误差最小[10]。
(8)
由式(7)和式(8)可知,存在一组参数βi、Wi和bi使得式(9)成立。
(9)
式(9)的矩阵形式为[11]:
Hβ=T,
(10)
式中:
H——ELM模型的隐含层神经元的输出;
β——ELM模型的输出权重矩阵。
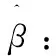
例2Alice在社交应用上发布了一条消息,消息中有“教师”这个词汇,她的朋友Bob(在Alice的社交应用中属于“朋友”这一访问者类型)要访问这条消息。首先,社交应用中的访问控制模块会对Bob的请求进行拦截,然后检查分配给“朋友”这一访问者类型的隐私规则,以确定Bob的访问水平(教育工作者),然后调出含有“教育工作者”的这一支(图3),“教师”节点在“教育工作者”节点下面,最终,访问控制模块将消息中的“教师”替换成“教育工作者”(Bob的访问水平)发送给Bob。
(11)
(12)
2.3.2 适应度函数 ELM模型的性能直接取决于初始输入权值Wi和隐含层偏置bi的选择。为提高ELM模型的性能,运用SSA算法优化选择ELM模型的初始输入权值Wi和隐含层偏置bi,将均方差作为适应度函数,即当均方差误差最小时,所对应的初始输入权值Wi和隐含层偏置bi作为ELM模型的最优参数:
(13)
式中:
n——训练样本数量;
x(i)和xp(i)——第i个样本的实际值和预测值;
[Wimin,Wimax]与[bimin,bimax]——ELM模型第i个初始输出权值W和第i个隐含层偏置b的上下限值,且W∈[-1,1]和b∈[-1,1]。
2.3.3 算法步骤
Step1:读取苹果光谱数据和含量数据,预处理并进行特征波长筛选,将数据划分为训练集和测试集,并进行归一化处理;
Step3:计算适应度。针对训练集,将训练集代入ELM模型,按适应度函数式(12)计算每个樽海鞘个体的适应度;
Step4:选定领导者、追随者和食物。计算适应度大小,将适应度最优的樽海鞘位置设定为当前食物位置;剩下的N-1个樽海鞘,将排在前一半的樽海鞘作为领导者,剩下的作为追随者;
Step5:更新领导者位置和追随者位置;
Step6:计算更新之后的樽海鞘个体适应度fs。比较fs与当前食物的适应度ffood,如果fs>ffood,则将fs所对应的樽海鞘位置作为新的食物位置;
Step7:重复Step3~Step6,如果t>T,输出最优食物位置,最优食物位置所对应的结果即为ELM模型的最优初始输入权值和隐含层偏置。将最优初始权值和隐含层偏置代入ELM模型进行苹果糖度预测。基于红外光谱的SSA-ELM的苹果糖度预测流程如图3所示。
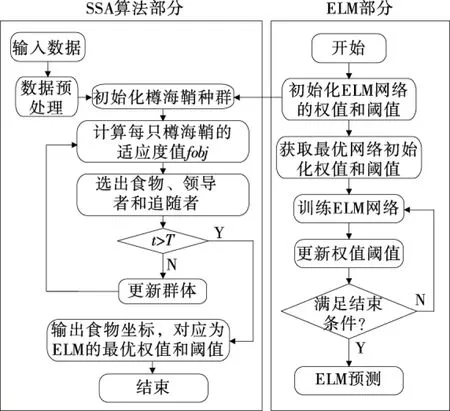
图3 基于红外光谱的SSA-ELM的苹果糖度预测流程Figure 3 SSA-ELM apple sugar content predictionprocess based on infrared spectroscopy
3 结果与分析
3.1 数据预处理
光谱的预处理方法有:一阶导数算法(FD)预处理、二阶导数算法(SD)预处理、标准正态变量变换算法预处理(SNV)和多元散射校正(MSC)预处理[12-13],不同预处理结果如表1所示。苹果原始光谱图像如图4所示。由表1可知,多元散射校正(MSC)处理结果最好。其预处理结果如图5所示。
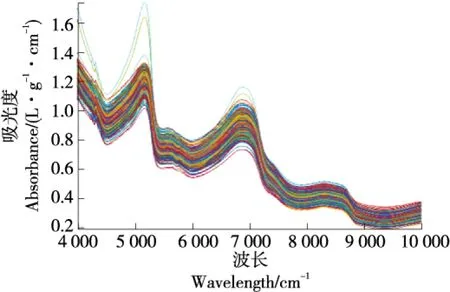
图4 苹果原始光谱Figure 4 Apple’s original spectrum
图5 MSC预处理结果Figure 5 MSC preprocessing result graph
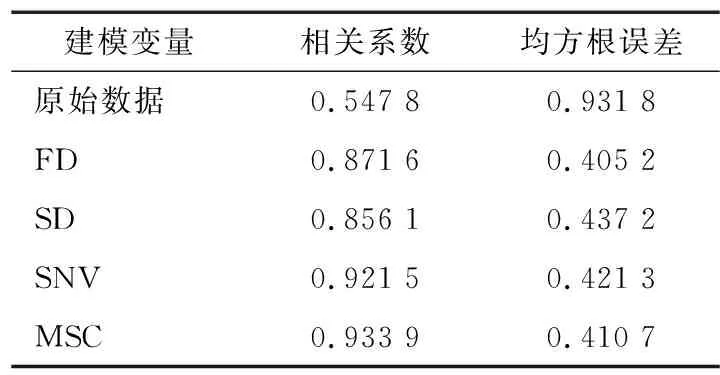
表1 不同预处理建模效果对比Table 1 Comparison of different preprocessing modeling effects
选择均方根误差(ERMSE)和相关系数C2评价苹果糖度预测模型的性能[14-15]:
(14)
(15)
式中:
xk——第k个样本的苹果糖度实际值;
pk——第k个样本的苹果糖度预测值;
n——样本数量;
ERMSE——均方根误差;
C2——相关系数。
3.2 特征波长筛选
由于苹果光谱数据具有维度高而复杂的特点,苹果糖度预测模型建立之前先对光谱数据进行降维处理,文中分别对比全波段和偏最小二乘法、连续投影法和小波包变换等筛选特征波长的结果,最终确定苹果光谱特征波长筛选方法。特征波长筛选后建模效果对比如表2和图6所示。
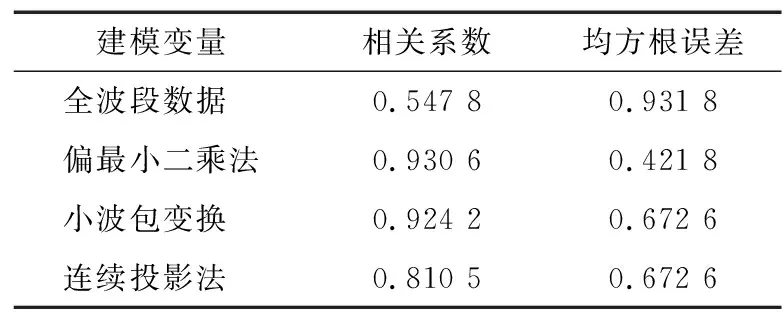
表2 特征波长筛选后建模效果对比
由表2和图6可知,基于小波包变换特征波长筛选之后的建模效果最好,相关系数和均方根误差分别为0.924 2和0.672 6,优于全波段和偏最小二乘法、连续投影法的建模效果。因此选择小波包变换特征波长筛选法进行苹果光谱特征波长筛选。
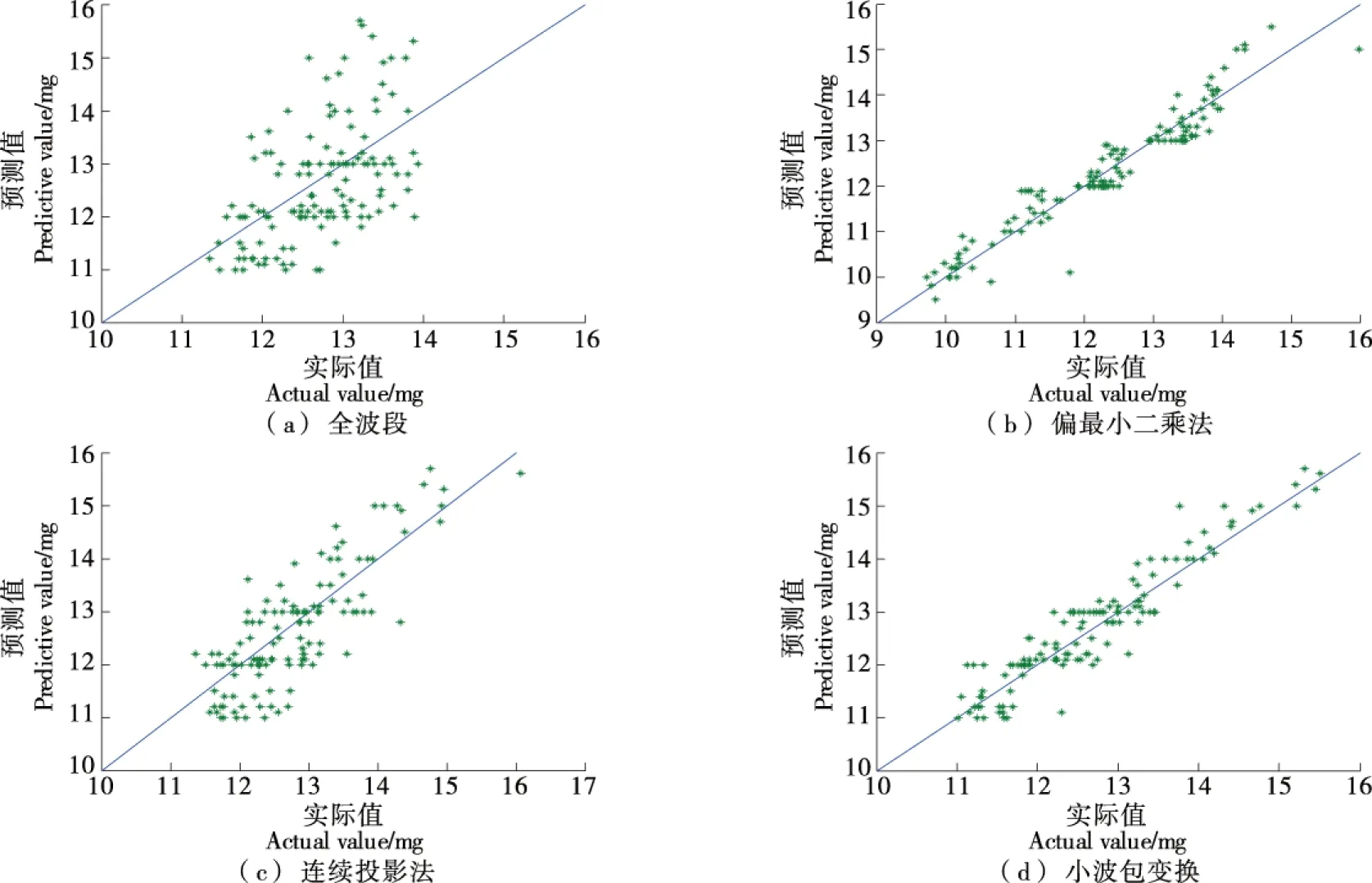
图6 特征波长筛选后建模效果Figure 6 Modeling effect diagram after characteristic wavelength selecting
3.3 模型效果比较
为验证SSA-ELM进行苹果糖度预测的有效性和可靠性,将SSA-ELM与GA-ELM、PSO-ELM和ELM进行比较,参数设定:① SSA算法:樽海鞘种群规模N=10,最大迭代次数T=100;② 遗传算法[16](genetic algorithm,GA)算法:最大迭代次数T=100,种群规模N=10,变异概率pm=0.1,交叉概率pc=0.7;③ 粒子群算法[17](particle swarm optimization algorithm,PSO):学习因子c1=c2=2,最大迭代次数T=100,种群规模N=10,惯性权重w=0.8;④ ELM模型[18-19]:输入层神经元数量N1=2 740、隐含层神经元数量N2=10以及输出层神经元数量为N3=1,一共采集到光谱数据34组,将前25组作为训练集,剩下9组作为测试集,苹果糖度预测结果如图7和表3所示。
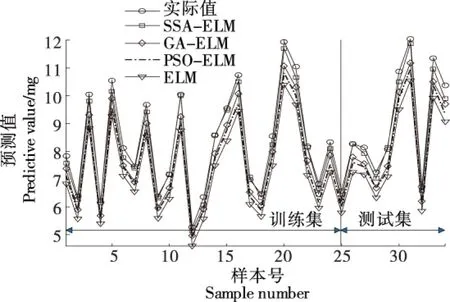
图7 苹果糖度预测对比Figure 7 Apple sugar content predictioncomparison chart
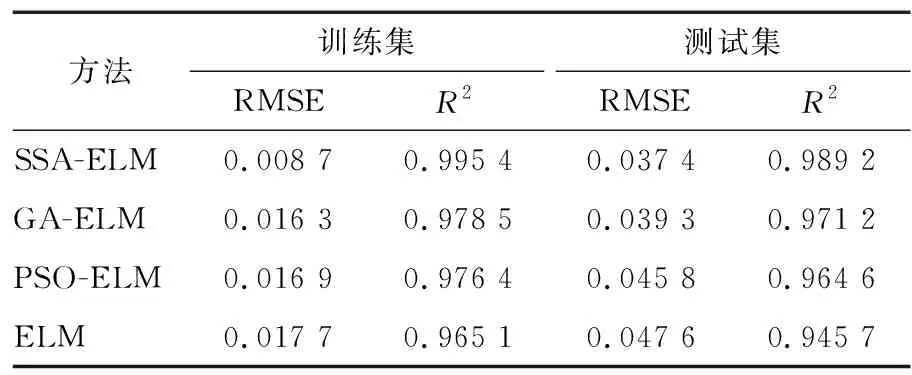
表3 苹果糖度预测结果对比Table 3 Comparison of apple sugar content prediction results
对比图7与表3可知:① 在训练集和测试集上,SSA-ELM模型的苹果糖度预测结果优于GA-ELM、PSO-ELM和ELM模型的苹果糖度预测结果,SSA-ELM模型的苹果糖度预测评价指标RMSE最小且相关系数R2最大,由此证明SSA-ELM模型的苹果糖度预测值和苹果糖度实际值关联程度最高,苹果糖度预测效果最好;② 通过SSA、GA和PSO等算法对ELM模型的初始输入权值和隐含层偏置的优化选择,SSA-ELM、GA-ELM和PSO-ELM模型的苹果糖度预测精度优于ELM模型,说明通过智能算法优化ELM模型的参数可以有效提高ELM模型的苹果糖度预测精度。
4 结论
为提高苹果糖度预测的精度,提出了一种基于红外光谱的樽海鞘算法改进极限学习机的苹果糖度预测算法。针对极限学习机模型预测性能受其初始权值和阈值的影响,运用樽海鞘算法对极限学习机模型的初始权值和阈值进行优化选择。将苹果的红外光谱吸光度作为极限学习机的输入,苹果糖度作为极限学习机的输出,建立红外光谱的苹果糖度预测模型,其对苹果糖度预测的精度高于遗传算法改进极限学习机、粒子群算法改进极限学习机和极限学习机。通过智能算法优化极限学习机模型的参数可以有效提高极限学习机模型的苹果糖度预测精度。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
热带作物学报(2022年8期)2022-09-16
今日农业(2022年13期)2022-09-15
文萃报·周五版(2021年30期)2021-09-05
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
郑州大学学报(工学版)(2018年2期)2018-04-13
北京航空航天大学学报(2017年6期)2017-11-23
安徽农学通报(2016年21期)2016-12-22
分析化学(2015年6期)2015-06-18
舰船电子工程(2010年1期)2010-04-26
