
一种改进变换网络的域自适应语义分割网络
2021-10-12 11:57张峻宁苏群星李一宁
上海交通大学学报 2021年9期
张峻宁, 苏群星, 王 成, 徐 超, 李一宁
(1.陆军工程大学, 石家庄 050003; 2.陆军指挥学院, 南京 210000;3.国防大学联合作战学院, 石家庄 050003; 4.32181部队,西安, 710032;5.军事科学院防化研究院, 北京 102205)
语义分割是指标记图像中每个元素的类别信息,完成从低级到高级的推理,最终形成像素级的语义标注图像.国内外学者提出众多语义分割方法,主要分为传统和基于深度学习的两大类方法[1-3].传统法[4]一般依靠图像自身的低阶视觉信息实现图像分割,但是无法应用于复杂的分割任务.近年来,随着深度学习技术的发展,语义分割技术也飞速发展,并广泛应用于包括自动驾驶[5]、视频监测[6]以及医学图像分析[7]等领域.2014年,Jonathan等[8]首先提出了全卷积层网络(Fully Convolution Network, FCN)的像素级语义分割.文献[9]提出了基于“编码器-解码器”的语义分割网络SegNet,该方法在全卷积层上分别结合低层的位置特征与高层的语义信息,有效提高了图像语义分割的精度,但是模型容易丢失信息.之后,Azadi等[10]通过优化网络结构,提高了卷积层感受野的独立性,实现了多任务的生成对抗网络(Generative Adversarial Vetwork, GAN)网络风格变换.最近,Chen等[11-13]提出了一系列语义分割模型(DeepLab v1、DeepLab v2及DeepLab v3),分别从像素密度预测、多尺度分割以及特征分辨率方面提高全卷积网络的分割精度.但是上述模型都需要通过具有像素级标签的大型数据集训练.然而,手动标注数据集的语义信息成本十分昂贵,直接用于本地化场景的语义分割是十分困难的.
研究人员用计算机自动标注的虚拟图像替代真实场景数据集,利用体量更小、代价更低的域自适应语义分割模型去解决手工标注数据集语义信息成本高的问题[14].由计算机模拟生成的场景分割图(源图)训练真实场景图(目标图),主要分为两个步骤:① 图像变换模块.将模拟图像(源图)域变换到真实图像(目标图)的域.② 建立模拟图像的语义分割网络,并用于分割真实场景,例如虚拟合成的GTA5数据集.此类方法根据数据集之间的相似性,利用虚拟数据集训练真实场景的语义分割网络,但是分割模型非常依赖于虚拟图像到真实图像的变换质量.一旦变换后图像与真实图像的语义未对齐或对齐性差,则语义分割网络的性能急剧降低.为了提高语义分割中图像的变换质量,域对应[15-19]和非监督域[20-23]的图像变换方法迅速发展.文献[15]通过建立特征分辨器缩小域间隙.文献[16]分别从全局和局部角度匹配域.在此基础上,文献[17]提出超像素的特征域匹配,实现了更细的像素分割.之后,文献[18]在域鉴别器中通过多层次的特征域差异计算,以缩小数据集之前的域间间隙.文献[19]对图像的前目标和后背景分别域匹配和语义分割,提高了不同类别的语义分割精度.但是上述网络需要配对好的图像作为模型的输入,而实际当中并没有大量匹配好的源图与目标图用于训练.
相比于域对应的图像变换,基于非监督域的图像合成无需匹配的数据集,具有成本低,体量小的优势.文献[20]首次将源图像到目标图像视为图像合成的过程,通过变换未匹配图像的域分布,消除了不同风格图像的域间隙.文献[14, 21]提出了双通道对齐网络,在图像生成器和分割网络中执行通道特征对齐,在网络中保留了空间结构和语义信息.之后,文献[8,22]加入域匹配的约束关系,进一步限制图像间的差异.文献[10]提出了图像生成和分割网络的双向学习框架,基于自我监督和感知损失建立图像合成和分割的联系,相互提升了各自模块的性能.在此基础上,文献[9]进一步提出一种双向学习的图像语义分割框架.该框架以闭环的形式相互学习各模块,相互促进了各模块的性能.尽管如此,由于真实场景的复杂性,在生成的虚拟场景中存在一些与真实场景(目标)的域间间隙差距大的源图,这些源图不仅与目标图的语义对齐性差,还会在训练中影响其他源图的变换质量.此外,同样的问题还会存在源图中的某些像素上.例如,源图某些像素由于受到噪声和相似风格物体的混淆,被模型错误理解为同类目标,最终影响了整个源图的图域变换,使得实际场景语义分割的精度降低.
虽然基于域适应的语义分割成本低,但是语义分割精度也低.分析原因主要是真实场景和虚拟场景中的部分物体的差异限制了源图到目标图的变换质量,影响了源图到目标图的语义对齐.为此,本文在双向学习的图像语义分割框架的基础上,分别通过分阶段训练和可解释蒙版消除域间间隙差距大的源图和像素,提出一种改进变换网络的域自适应语义分割网络.首先为了提高变换网络对源图的场景理解,在训练集中挑选出与目标图域间隙大的源图集,并提出分阶段的变换网络训练策略,以提升源图的变换质量.其次,针对源图中部分像素语义对齐性差的缺陷,提出可解释蒙版以标记域间隙置信度高的像素,使网络在训练过程中仅关注这些像素,而忽略语义对齐性差的像素对模型性能的影响.
1 域自适应语义分割模型的机理
给定计算机自动标注的虚拟图片集(源图S)以及未标注的实际场景数据(目标图T),利用域适应的语义分割模型可实现目标图T的语义分割任务.该模型包括两个子网络:① 源图S到目标图T的变换网络F.②对目标图T的场景分割子网络E,如图1所示.图中:S′为利用变换子网络将S变换为与T域分布相近的合成图,变换后的S′与源图具有相同的语义标签LS;ΓF为变换网络的训练损失;ΓE为语义分割网络的训练损失.然后通过分割网络M同时分割S′和T.其对应的变换网络训练损失为ΓF
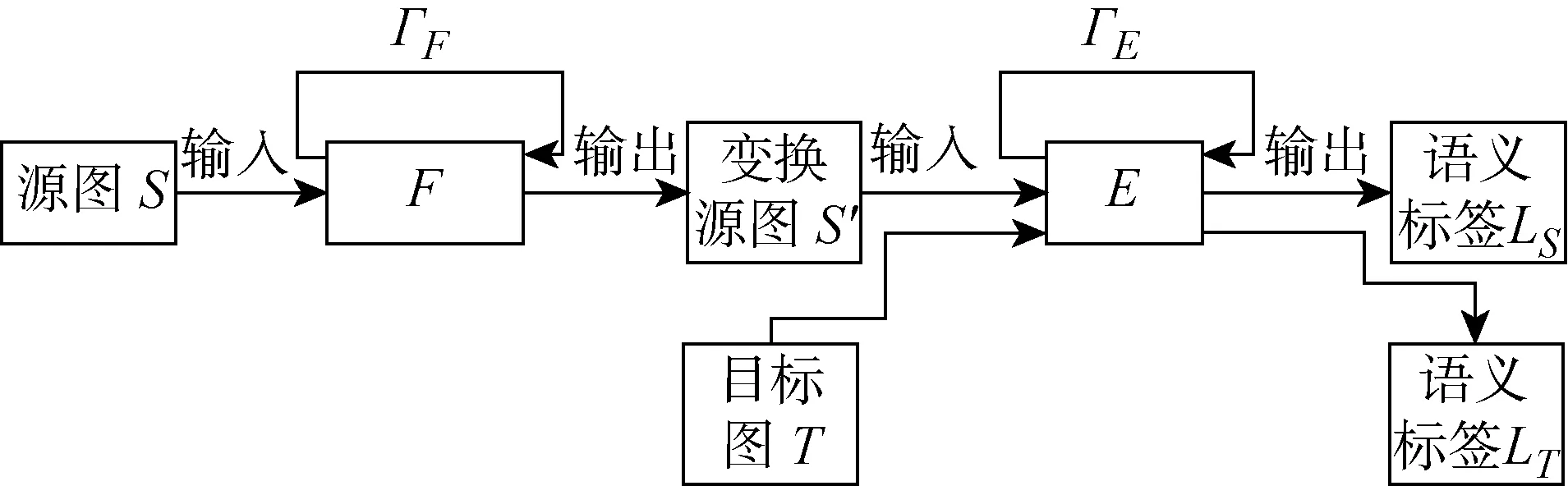
图1 域自适应语义分割的框架
ΓF=ζ(F(S′),F(T))+λSζ(F(S′),LS)+
λpζ(F(S′),F(S))+λpζ(F(T′),F(T))
(1)
式中:ζ为域分布损失,用于计算源图S与目标图T之间的特征差异;λS、λp分别为对应权重.由于只有源图的标签,模型中只计算源图S的语义分割损失.为了保证目标图的语义分割精度,变换后源图像的域与目标图像域需保持一致.只有当源图与目标图的语义对齐性较好,目标图的分割精度才更高.
为此,文献[10]通过图像重构损失ζr和生成式对抗网络的损失提升图像的翻译质量,其语义分割网络的训练损失ΓE如下:
ΓE=λG[ζG(S′,T)+ζG(S,T′)]+
λr[ζr(S′,F-1(S′))+ζG(T,F(T′)]
(2)
式中:λr、λG为对应的损失权重;ζG为生成式对抗网络损失,用于评价变换源图S′与目标图像T的域分布距离;F-1是F的逆变换,以约束图像变换网络的图像合成.
虽然上述模型可以实现非监督的语义分割任务,但是由于实际场景的复杂性,导致变换后的图像与目标图像的域分布存在差异.例如,源图与目标图在视觉上的差异(灯光、比例、对象纹理等).
2 域自适应语义分割模型的改进
为了克服域间隙大的源图和像素对语义分割网络训练的影响,本文提出一种改进变换网络的域自适应语义分割网络(DA-SSN).具体而言,为了弱化源数据集中大间隙源图对变换网络训练的影响,本文提出分阶段训练变换源图的训练策略.其次,通过一种可解释蒙板标记图像中视差差异较大的像素区域,并在训练损失计算中忽略对应像素的损失,以消除间隙大的像素对模型训练的影响.
2.1 变换网络的分阶段训练
如果源图与目标图风格相似,或者二者的域分布规律性强,则通过CycleGAN模型就可以实现源图与目标图的语义对齐.然而,GTA5数据集中存在一些与目标图(城市场景)风格差异大的源图.变换网络为了得到整个训练的最小化训练损失,忽略部分正确的语义对齐源图,以满足全部源图变换的最小训练损失梯度训练网络参数.因此,该部分大间隙的源图降低了整个场景的语义分割精度.本文通过分阶段训练变换网络,以获取目标图域间隙小的源图.具体变换网络训练策略如下.
输入:S,T
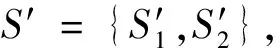
训练轮次K=1时,初始化变换网络训练步骤.
(1)基于式(3)和CycleGAN初始化网络,设定判断阈值ϑ:
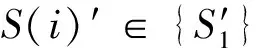
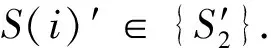
训练轮次K=2时,第2阶段源图变换网络优化步骤:
(3)更新剩余源图,组成最终的变换源图S′.
综上所述,该网络训练由两阶段构成.第1阶段基于CycleGAN网络[9]训练全部源图到目标图的语义对齐;第2阶段对第1阶段中变换效果差的源图迭代训练.具体来说,通过第1阶段的变换网络,可以筛选出域间间隙大的源图集,然后将该数据集作为第2阶段网络的输入.因为数据集减少了,变换网络将全部注意力集中到剩余数据集上,再基于这些源图的训练损失最小化变换源图.如此迭代,相比于初始阶段的训练,则间隙大的源图变换更接近于目标域.为此,将变换网络的训练损失修改为
ΓF=λr[ζr(S,F-1(S′))+ζr(T,F(T′))]
(3)
式中:λa为对应的分阶段训练的损失权重.
本文将源图的对抗网络损失ζG(S′,T)作为评价源图与目标图的间隙差距,并在第一阶段训练中设置阈值ϑ,筛选出ζG(S′,T)>ϑ的源图.当分辨器ζG(S′,T)>ϑ时,可以认为该变换后的源图域目标图域间隙差距大,需要重新收集该数据集,并作为第二阶段的变换网络的输入;反之,则认为所得源图与目标图是语义对齐的.
2.2 基于可解释性蒙板的像素级图像变换
虽然通过分阶段训练变换网络提高了域间隙大的源图的语义对齐性,但是不可忽视的是,一张图片(一个场景)中也会存在域间隙大的物体.例如GTA5和Cityscapes数据集之间的空间布局差异.对于GTA5,远处天空中存在大量的高大型树木,而城市景观则不同.对于这部分风格差异较大的源图像素,原始的CycleGAN网络处理效果不佳.为此,在模型训练中迫切需要将域间隙大的源图部分像素区域忽略,以避免此类区域对其余像素区域的干扰.
2.2.1蒙版结构的构建 文献[23]在估计场景深度时,针对空间几何推理无法解释的像素区域,提出了一种可解释蒙板忽略该区域.在本文中,为了避免大间隙图像像素对模型性能的影响,训练了一个可解释性预测网络蒙板(MaskNet),与变换和分割网络同时进行,该网络输出源图像素对应的解释掩码,其中掩码表示对应像素从源图到目标图间隙缩小的可信度.MaskNet的具体网络结构如图2所示.
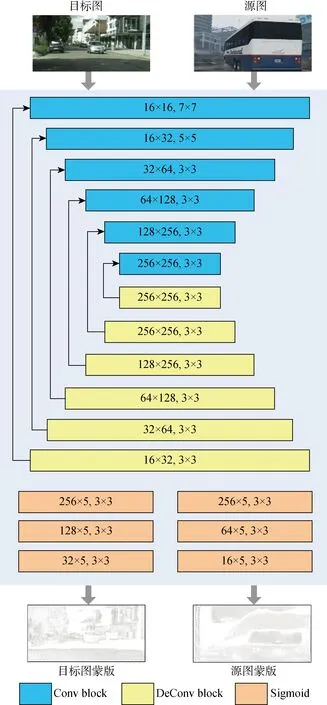
图2 蒙版网络结构
经分析,该网络是编码器-解码器架构,其中编码器由6个卷积层组成,输出层及卷积核的参数分别是:(16×16,7×7)(16×16代表输出层参数,7×7代表卷积层参数,下同)、(16×32,5×5)、(32×64,3×3)、(64×128,3×3)、(128×256,3×3)、(256×256,3×3),解码器是6个上卷积层,输出层及卷积核尺寸参数是:(256×256,3×3)、(256×256,3×3)、(256×128,3×3)、(64×128,3×3)、(64×32,3×3)、(32×16,3×3),且在每个层中都有ReLU激活函数,同时预测层使用sigmoid函数,其对应的输出层、卷积核尺寸参数如下:(256×5,3×3)、(256×5,3×3)、(128×5,3×3)、(64×5,3×3)、(32×5,3×3)、(16×5,3×3).
2.2.2基于MaskNet的损失函数 基于构建的MaskNet重新定义图像变换损失,具体为
ΓF=λG[MS′ζG(S′,T)+MT′ζG(S,T′)]+
λr[MS′ζr(S,F-1(S′))+MT′ζr(T,F(T′))]
(4)
ζG(S′,T)=EIT~T[DF(IT)]+
(5)
ζrecon(S′,F-1(S′))=
(6)
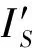
由于蒙板网络MaskNet并没有直接的监督机制,所以模型在训练中会直接将MaskNet全部预测为0,以实现训练损失的最小化.为了防止此类情形的出现,在损失函数中设置一个正则化项,通过最小化与常量标签“1”的交叉熵,来实现Mask的非零预测,具体公式为
ζmask(S′)=γf(MS′,1)
(7)
式中:ζmask为蒙板损失;γ为该项损失权重;f(MS′,1)为交叉熵函数,“1”是与Ms尺寸相同,全部元素为1的常量蒙板.
综上所述,本文利用GAN和图像重构损失函数鼓励网络最小化变换源图域目标图的差距,但通过蒙板Mask允许一定数量的松弛来避免域间隙大的像素区域的影响.
3 本文算法框架
文献[10]所提的域适应分割模型是全新的非监督语义分割网络,对目标场景的语义分割性能显著,但是其中变换网络存在大间隙源图变换质量较差的问题.针对此问题,本文在变换网络中通过可解释蒙板MaskNet和分阶段训练等改进,提升了源图到目标图的语义对齐性能.然后将所得源图LT训练语义分割网络,最终提出一种改进变换网络的域适应语义分割模型,具体步骤框架图如图3所示.
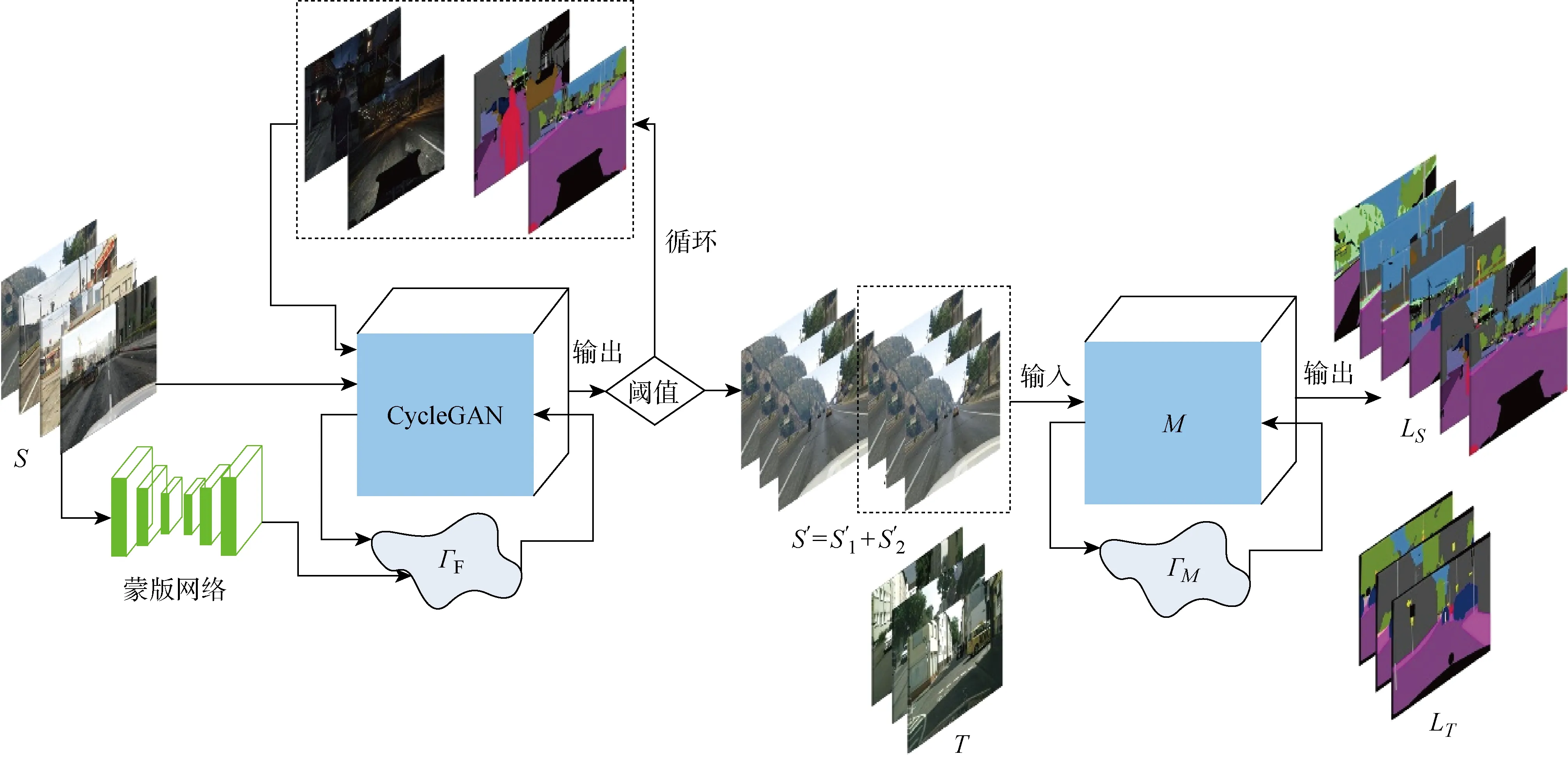
图3 本文算法框架图
4 实验与分析
4.1 网络结构
本文算法分别由变换网络模块和分割网络模块组成,其中CycleGAN作为变换网络模块,本文在此基础上提出了改进变换网络,而Resnet101[24]和DeepLab v2[14]作为分割模型,其被ImageNet网络初始化,对应的分辨器结构是5个卷积层,网络参数分别是:卷积核4×4;各层通道数64、128、256、512、1;步长2,且每层之后连接1个ReLU层.
4.2 数据集
实验数据分别来自于GTA5[25]和Cityscapes[26]数据集,其中GTA5作为源图数据集,该数据集包含 24 966 张图片,其分辨率为 1 914 像素×1 052 像素,与Cityscapes数据具有相同的19个类别.而Cityscapes数据集作为目标数据集,分为训练集、验证集以及测试集.在测试集下验证本文算法的性能,但是由于官方并未提供测试集的真值,所以将验证集作为测试集(500张图片).为了保证测试的公平性,要求训练集和验证集中不包含相同场景的图片.
4.3 实验细节
在实验中,变换网络训练图片分辨率随机设为452像素×452像素,训练轮次为20.模型学习率为 0.000 2,且前10轮学习率逐渐降低为 0.000 1,之后保持不变.损失权重设为λG=1,λr=10,λa=1,分割网络的实验参数与文献[10]相同,所有实验均是在Ubuntu18.04系统Pytorch 平台下完成.电脑配置如下:CPU(2.0 GHz Intel i7),运行内存为 32 GB,GPU(2080Ti).实验主要做了两方面验证:① 验证本文改进算法的有效性.② 比较不同算法的语义分割性能,分析本文算法的优势.
4.4 本文改进的有效性验证
4.4.1模型训练损失变化 图4所示为模型改进前后随着训练轮次的训练损失变化曲线.分析可知,全部模型随着训练轮次的增加,训练损失逐渐降低,并且在轮次 105左右收敛.相比于原始模型,本文所提的改进模型训练损失缩减幅度更大,最终训练损失从0.17降低至0.013.表明了本文所提出的改进降低了源图到目标图的间隙差距,提高了源图到目标图的语义对齐性.
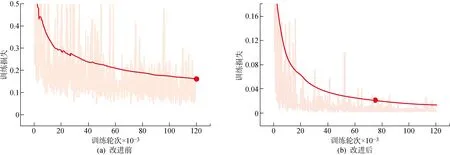
图4 模型改进前后的训练损失
为了全面验证本文改进的效果,本文训练和评估了多种模型,其中每个模型都是原始模型的基础上加入了不同的改进,包括D1(在原始F上加入源图语义标签),D2(分阶段训练原始F),D3(在训练损失计算中利用可解释蒙版.
4.4.2分阶段训练策略的有效性研究 针对域间间隙大的源图,本文采用了分阶段的训练策略,以得到与目标图语义对齐性更高的变换源图.为了定量说明分阶段训练的意义,表1对比了分阶段训练前后的域间间隙和目标图的语义分割精度.可以发现,分阶段训练源图对于改善大间隙源图的语义对齐性和提高语义分割精度具有重要作用.
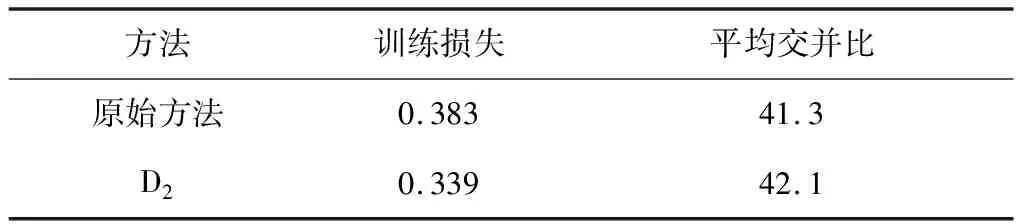
表1 分阶段训练前后的性能对比
分阶段训练的关键是基于间隙阈值筛选大间隙的源图数据集.为了进一步研究不同阈值对模型性能的影响,表2给出了不同阈值对变换源图间隙损失和语义分割精度的影响.
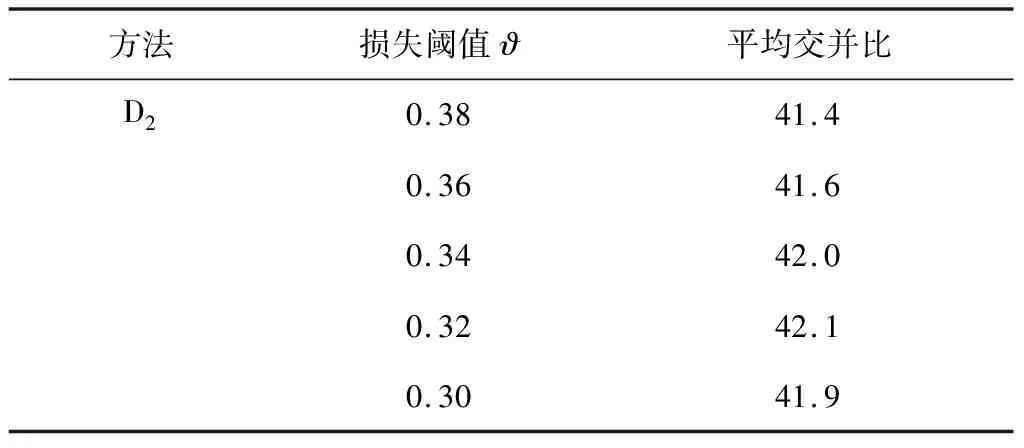
表2 不同阈值的模型性能变化
经分析,当0.38>ϑ>0.32时,随着阈值的降低,模型的语义分割精度更高.这是因为随着阈值的增加,大间隙的源图集被逐步筛选出来,再对这些源图进行重复训练也再次提高了该源图集的变换质量,因而进一步提高了整体的语义分割的精度.但是,当ϑ<0.32时,模型的精度逐渐降低,这可能是因为阈值门槛的降低将不需要分阶段训练的源图集也被重复训练,造成再次训练的源图集的域间间隙距离增大,因而模型的精度进一步下降.因此,本文将筛选源图集的阈值设定为ϑ=0.32.但是需要指出的是,不同阈值的分阶段训练都要比原始的变换网络训练效果要好,语义分割精度更高,由此证明了所提的分阶段训练策略的有效性.
4.4.3可解释蒙版的有效性研究 针对源图中域间间隙大的像素区域,本文提出了可解释性蒙版MaskNet,以忽略源图中语义对齐性差的像素区域.图5可视化了网络预测的可解释蒙版.分析可知,大部分像素在可解释蒙版上呈白色(自信度较高),对应的源图区域确实与目标图风格相似,因而情况相符.相反,蒙版MaskNet对于天空、大树等物体可信度较低(图中呈灰色).事实上,源图的这些区域确实与目标图的风格差异大.在变换网络中考虑这些区域只会降低其他像素区域的语义对齐性,最终导致语义分割的精度降低.本文通过可解释蒙版避免了上述区域对模型的影响.
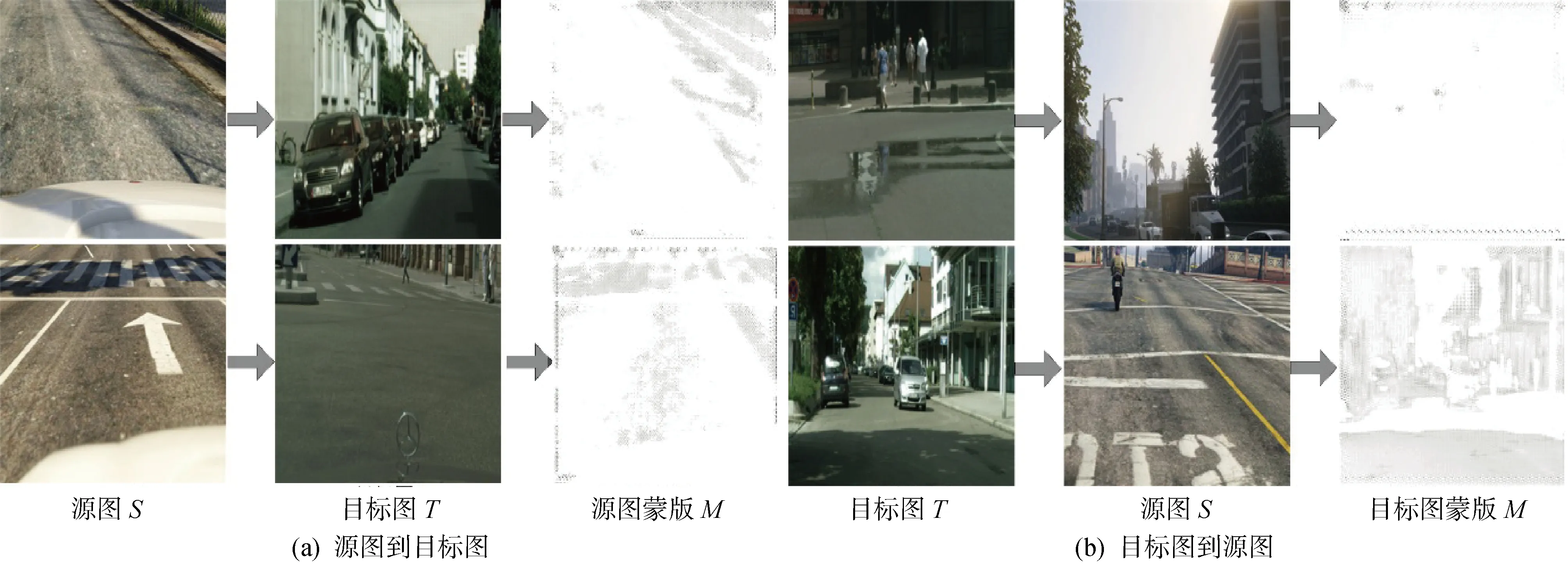
图5 蒙版可视化及目标图和源图生成图
为了定量评价可解释蒙版的作用,表3给出了可解释蒙版应用前后的模型性能变化.可以发现,可解释蒙版的应用直接忽略了间隙大的像素区域,与改进前相比,降低了变换图与目标图的域间损失,语义分割的精度提高至42.2.由此说明了可解释蒙版对提高模型性能的有效性.
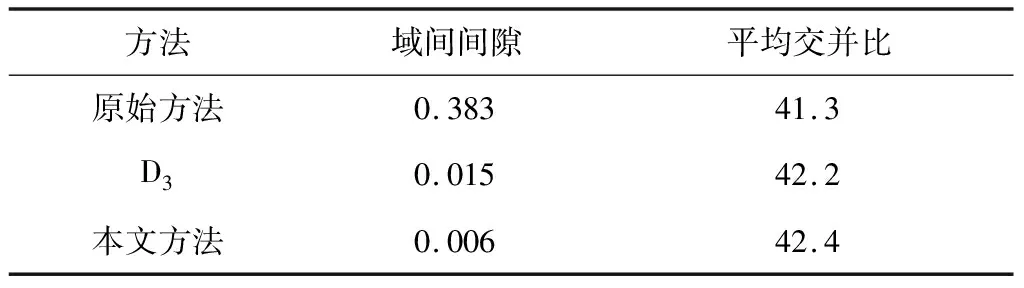
表3 MaskNet应用前后的模型性能对比
4.5 算法性能比较
4.5.1图像变换性能 表5比较了本文算法与原始算法的变换图的域间间隙.经分析,与原始模型的性能相比,本文算法缩小域间间隙性能更显著.图6所示为本文算法与CycleGAN算法的图像变换效果,其中Cityscapes是随机选择的目标图片集,包括不同的城市场景(街道、汽车、建筑物、天空以及大树等).经分析,相比于CycleGAN的变换效果,本文变换的源图在边缘更加完整、轮廓清晰度更高,与Cityscapes数据集的场景风格更为接近.以远方的天空和参天大树为例,CycleGAN算法因为虚拟数据集中的高大树木与远方天空的混合,导致变换风格时产生混淆(见图中红色方框标注),而本文算法在上述对象上保持了对象的各自属性,不会相互受到影响,这是因为本文通过可解释型蒙版对风格差异大的物体(例如易混淆的天空、大树等)进行一定程度的忽略,进而降低了它们对模型的影响,由此说明本文算法的有效性和优势.

图6 源图的变换效果比较
4.5.2语义分割检测性能 图7显示了分别利用Cycada[9]、DCAN[22]、CLAN[27]、BLD[10]、CBST[28]等算法对场景中的街道、汽车以及行人等类别进行语义分割的可视化结果.相比于其他算法,本文的语义分割图毛刺少、边界轮廓更清晰,分割的结果更加与实际真值相符.以图7的汽车和行人分割为例,本文分割的行人和汽车很好地与街道、房屋等物体区分,并且估计的汽车边缘毛刺少、轮廓清晰,其长宽也更接近于实际尺寸.
为了定量评价本文算法的优势,分别在Resnet101[24]和DeepLab v2[14]上比较了所有算法的性能,评价标准是平均交并比指标,结果见表4,其中每一项指标的最高值加粗表示.本文算法在Resnet101[24]和DeepLab v2[14]两种结构上的结果都好于其他流行算法.其中,DCAN[22]采用了自适应训练方法,提高和泛化了不同类别的分割精度,相比于DCAN[27],本文模型性能提高了约17.4%.CLAN[27]通过调整特征域间间隙提高模型性能,但与本文模型相比结果仍相差约14.8%.本文的语义分割框架与DBL[10]相同,相比于DBL[10],本文通过蒙版等一系列改进进一步提高了模型的语义分割精度.由此可见,本文算法相比于其他算法的优势.
5 结语
基于域自适应的语义分割网络是轻量级和易于训练的.针对目前模型缺陷,本文提出一种改进的域自适应的语义分割模型.首先,提出变换网络的分阶段训练策略,以分别训练不同域间隙的源图.在保证小间隙源图的语义对齐的基础上,提高了大间隙源图的语义对齐性能.其次,针对源图中域间隙差异大的像素区域,提出一种可解释蒙版MaskNet,以避免这些像素降低模型的性能.相关数据集的实验表明,相比于目前流行的域自适应语义分割算法,本文算法具有更好的变换质量和更高的语义分割精度.在未来的工作中,进一步利用场景深度信息去提高语义分割精度,这将对本系统的完善十分有意义.
猜你喜欢
今日农业(2022年15期)2022-09-20
北京航空航天大学学报(2022年8期)2022-08-31
小资CHIC!ELEGANCE(2022年2期)2022-01-11
航空发动机(2020年3期)2020-07-24
小天使·二年级语数英综合(2019年10期)2019-11-08
延河(2017年7期)2017-07-19
阳光(2017年7期)2017-07-18
长江学术(2016年4期)2016-03-11
读者·校园版(2015年19期)2015-05-14
长江学术(2015年1期)2015-02-27
