
基于音视频信息融合的目标检测与跟踪算法
2021-09-27 02:48黄战华陈智林张晗笑曹雨生申苜弘
应用光学 2021年5期
黄战华,陈智林,张晗笑,曹雨生,申苜弘
(天津大学 精密仪器与光电子工程学院 光电信息技术教育部重点实验室,天津 300072)
引言
基于视觉的目标跟踪技术广泛应用于视频会议、智能监控、智能机器人等领域。现今常用的目标跟踪算法包括粒子滤波(particle filtering)、均值漂移(meanshift)、卡尔曼滤波(Kalman filtering,KF)等[1-3]。基于视觉的目标跟踪精确度较高,但容易受到遮挡、光照等因素影响,因此存在一定的误跟现象。声源定位技术[4]可以测得声源的位置信息,虽然声源定位的精度相对较低,但不受视觉场景的影响并且测量范围更宽。考虑到单一使用视频或音频跟踪定位的缺点,试图将音频信息和视频信息融合,综合两种模态的信息实现目标检测与跟踪,使系统具有更高的准确率和鲁棒性。
视频信息与音频信息是两种不同模态的信息。多种模态的信息既能实现互补,也能提高信息的可靠性。音视频信息的融合就是一种多模态融合的方向之一。通过音视频信息的融合,可以实现复杂环境下的目标检测与跟踪。文献[5]采用序列蒙特卡洛方法融合头部轮廓和声源定位信息,实现说话人的定位。文献[6]提出一种融合目标轮廓、颜色、声源位置的说话人跟踪算法,得到稳定的跟踪效果。国内相关研究起步较晚。文献[7]采用重要性粒子滤波实现在智能教室环境下对演讲者的跟踪。文献[8]将均值漂移算法嵌入到粒子滤波算法中,将音视频跟踪结果通过粒子滤波算法融合,得到融合跟踪的结果。
本文在重要性粒子滤波算法的基础上,提出一种基于同源音视频信息融合的目标检测与跟踪框架,并设计了实现相关功能的硬件系统。实验结果表明,该算法可以有效利用音视频信息进行检测与跟踪,相较单一模态算法具有更高的准确率。
1 算法总体框架
算法总体框架如图1所示,包括视频检测与跟踪、声源定位、音视频信息融合跟踪3个模块。本系统先分别从视频和音频2个底层层面实现目标的跟踪定位,最后在决策层将视频和音频跟踪的结果融合,得到基于音视频融合的跟踪定位结果。

图1 算法总体框图Fig.1 Block diagram of algorithm
视频检测与跟踪模块采用YOLOv5m算法对人等生活中常见的运动目标进行检测,通过无迹卡尔曼滤波(unscented Kalman filtering, UKF)跟踪算法对多目标进行跟踪预测,再通过匈牙利匹配算法将检测结果和跟踪结果匹配,得到视频跟踪结果。
声源定位模块采用基于时延估计(time difference of arrival, TDOA)的定位算法,用广义互相关函数(generalized cross correlation, GCC)和相位变化加权函数(phase transform, PHAT)估算出各个麦克风接收到声源信号的时间差,再结合麦克风阵列的空间拓扑结构计算出声源的方位角,最后将方位角投影至相机二维像面,得到声源定位结果。
音视频信息融合跟踪模块在决策层构建音视频信息的似然函数和重要性采样函数,将视频跟踪结果和声源定位结果融合,最后采用重要性粒子滤波算法对融合信息进行跟踪定位,实现对目标状态的最优估计。
1.1 视频目标检测与跟踪算法
基于视觉的目标检测与跟踪算法可以在没有遮挡的情况下,实现精确度较高的多目标检测与跟踪。研究人员在卷积神经网络的基础上提出一系列目标检测算法[9-12]。为了兼顾模型在复杂环境下的检测能力,同时需要满足系统的实时检测需求,采用YOLOv5m作为视频目标检测算法,模型结构如图2所示。图像统一缩放至640×640×3像素输入,经过特征提取网络和特征金字塔(FPN)后得到80×80、40×40、20×20像素3个尺度的高层特征。经过非极大值抑制(NMS)处理,得到最优的检测框。

图2 YOLOv5m模型结构图Fig.2 Structure diagram of YOLOv5m model
YOLOv5m卷积层特征提取的流程图如图3所示。
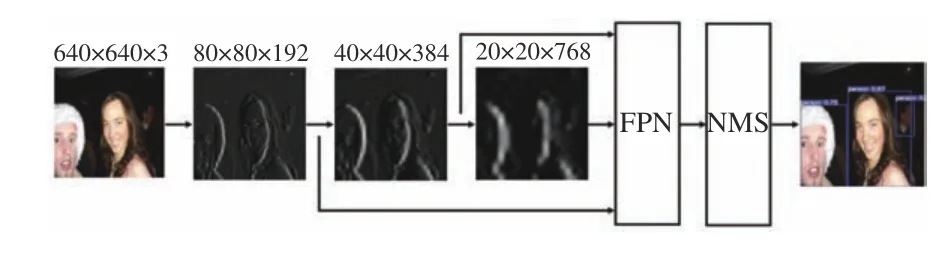
图3 YOLOv5m特征提取流程图Fig.3 Flow chart of YOLOv5m feature extraction
目标跟踪算法可以根据目标当前状态预测下一时刻的状态,从而实现目标跟踪任务。为兼顾对非线性目标的跟踪能力,同时考虑到实际应用场景中多目标跟踪任务的实时性需求,本文采用无迹卡尔曼滤波作为基于视频的目标跟踪算法。UKF在KF的基础上,采用UT变换(unscented transformation)得到Sigma点集,计算概率分布的均值和协方差,实现对非线性概率密度分布的近似,具有精度高、计算量较小等优点[13]。
多目标跟踪任务中需要将经过UKF得到的跟踪结果和目标检测结果匹配。本文采用基于GIoU(generalized intersection over union)的匈牙利匹配算法进行匹配。GIoU可用来衡量2个框的相交程度,设检测框为D,跟踪框为T,I为能将D和T包含的最小封闭图形,则D与T的GIoU可用G表示为
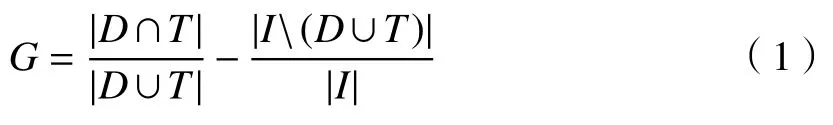
根据GIoU可将检测框与跟踪框按如下关系匹配:

式中:(Di,Ti)表示第i个配对的检测框和跟踪框;Q为总配对数;t为判定检测框与跟踪框可以配对的阈值。
1.2 声源定位算法
视频目标检测与跟踪可以从视觉层面确定目标的位置,而基于音频的声源定位可以具体确定发出声音的目标,并且可以在目标受视觉遮挡时辅助目标的跟踪定位。本文采用TDOA算法进行声源定位[14-15],相比于其他声源定位算法,基于TDOA的算法具有计算量小、实时性高、硬件易于实现等优点。
假设存在2个麦克风M1和M2,2个麦克风接收到的音频信号为x1(t)与x2(t),由GCC-PHAT算法估算出x1(t)与x2(t)的时延τ12为

式中:X1(ω)和X2(ω)分别是x1(t)和x2(t)的傅里叶变换;(.)*表示复共轭;R12(τ)为x1(t)与x2(t)的广义互相关函数。
算得阵列中各个麦克风之间时延后,就可以结合阵列的空间结构计算声源的方位。本系统采用十字型阵列,如图4所示。
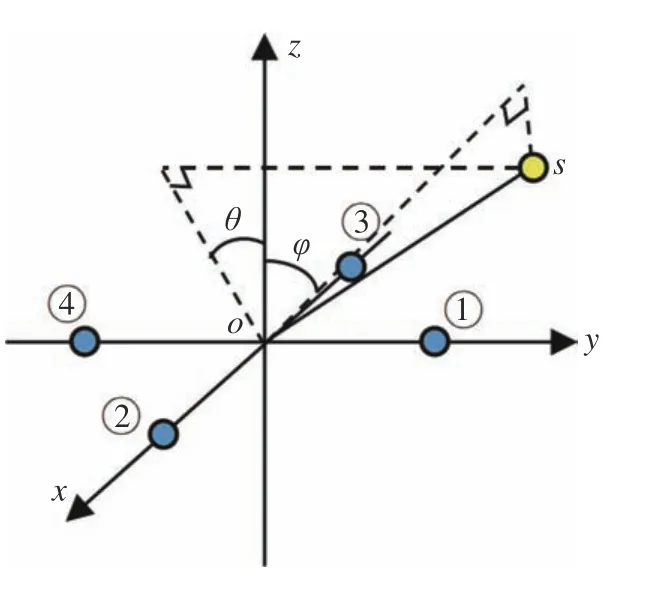
图4 麦克风阵列空间结构Fig.4 Spatial structure of microphone array
图4中,①、②、③、④分别表示阵列的4个麦克风,坐标分别为(0,a,0)、(a,0,0)、(−a,0,0)、(0,−a,0),4个麦克风在空间内呈十字型分布,摄像头位于原点o处。声源为s,其直角坐标表示为(x,y,z);os在平面xoz的投影与z轴的夹角为θ,取值范围为(−90°,90°);os在平面yoz的投影与z轴的夹角为φ,取值范围为(−90°,90°)。设声音在空气中传播的速度为v,且通过GCC-PHAT算法计算得到麦克风④与麦克风①的时延为τ41=τ4−τ1,麦克风③与麦克风②的时延为τ32=τ3−τ2。
通过τ41和τ32来计算声源的方位角θ和φ:τ41和τ32可以确定声源s分别在平面xoz和平面yoz的投影在2个双曲线上。当|os|≫2a时,可认为声源s在平面yoz和平面xoz的投影位于对应双曲线的渐近线上,由此可计算出θ和φ为

然后将声源方位映射到相机靶面上,设相机靶面的长宽分别为lx和ly,像素尺寸为lp×lp,焦距为f,则可得声源在最终所拍得图像的坐标(X,Y)为

1.3 音视频信息融合跟踪算法
视频检测与跟踪的精度较高,但易受遮挡等因素影响;声源定位不受视觉场景的影响,但精度较低且易受到噪声的干扰。只采用单一模态对目标进行跟踪存在缺陷,如果同时捕捉被检测目标的视频信息和音频信息,将两种不同模态的信息互补,可以实现精确度更高且更可靠的目标跟踪定位。
由于重要性粒子滤波算法不局限于线性高斯系统,且具有优良的可扩展性和普适性,本文采取重要性粒子滤波[16]作为信息融合方法,基本思想是基于后验概率抽取状态粒子来表示目标概率密度分布,通过对粒子群的加权均值来近似跟踪目标的位置。实际应用中从后验概率抽取样本非常困难,因此引入重要性采样(importance sampling),通过重要性采样密度函数抽取样本。
为了将音视频信息融合,首先需要构建音视频信息的似然函数。假设视频似然函数和音频似然函数相互独立,则可通过概率相乘的方式构建音视频信息融合的似然函数为

式中:λv和λa分别是视频重要性函数和音频重要性函数的权值,用来衡量2个重要性函数可靠程度。当单一模态失效时,重要性函数仍然可以基于另一模态计算,系统是稳定可靠的。k时刻的可靠因子λv和λa可由(8)式计算:

式中:在k时刻第i个粒子的权值。当视频或音频重要性函数与后验分布有更多重叠时,说明该模态的信息更加可靠,其可靠因子的值也会更大。
整个重要性粒子滤波算法流程如下:
1)k−1时刻的粒子集为分别表示k−1时刻第i个粒子的状态和权值,N表示粒子个数。
2)转移至k时刻,通过k−1时刻计算的可靠因子,利用(7)式计算重要性采样函数zk),视频重要性函数和音频重要性函数选用UKF重要性函数。由重要性采样函数采样得到k时刻粒子集
3)系统观测,由视频和音频似然函数计算融合似然函数:
① 视频似然函数为
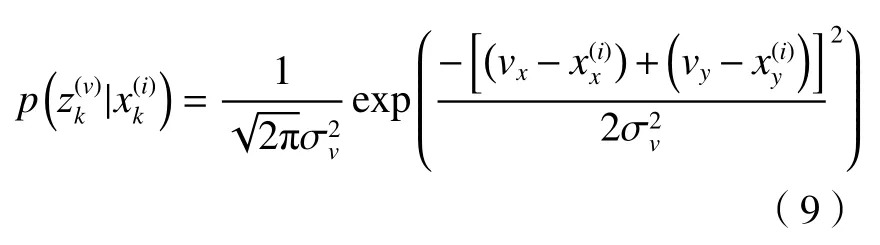
式中:(vx,vy)是经过UKF算法得到视频跟踪目标的二维坐标;是目标跟踪的观测方差;是第i个粒子的二维坐标。
② 音频似然函数为
式中:(ax,ay)是声源定位结果映射到摄像头像面的二维坐标;是声源定位的观测方差。
③ 由(6)式计算音视频融合似然函数。
4)更新粒子的权值

5)状态估计为

6)随机线性重采样,缓解粒子退化问题。
7)当既没有获得视频信息,又没有获得音频信息时,算法结束;否则返回第2步。
2 系统硬件设计
系统硬件如图5所示,硬件部分包括视频采集模块、音频采集模块、数据转接模块和上位机。硬件部分实物图如图6所示。

图5 系统硬件设计框图Fig.5 Block diagram of system hardware design

图6 硬件部分实物图Fig.6 Physical drawing of hardware part
视频采集模块采用1080 P摄像头,感光芯片型号为HM2131(1/2.7″),像素尺寸为3 μm×3 μm,焦距为4.262 mm,视场角为77°,帧率为30 fps,输出USB 2.0信号。
音频采集模块采用4个硅麦克风作为拾音器件。麦克风阵列采集音频信号,经由放大电路初步放大后,再经过AC108芯片二次放大并将模拟信号转化为数字信号输出(I2S信号)。整个音频电路板的逻辑控制、时序控制由LC4064芯片控制。通过LC4064芯片将AC108芯片输出音频数据存储于72V05芯片。当72V05半满时,LC4064芯片读取72V05芯片中的数据,再通过I2C总线的SDA线传输到FT4222芯片。FT4222芯片将I2C信号转化为USB2.0信号输出。
数据转接模块采用GL3520芯片将视频采集模块输出信号和音频采集模块输出信号转化为USB3.0信号输出,实现音视频信息的同步传输。最后将数据传输至上位机进行处理。
上位机硬件环境为Intel(R) Core(TM) i5-8300H CPU,主频2.30 GHz,内存16 G,显卡为GTX 1060 6G。软件环境为Windows10操作系统,算法在Python3.7环境下运行,深度学习框架为PyTorch1.5.1。
3 实验结果与分析
3.1 视频目标检测模型训练
考虑到应用场景中需要对生活中常见目标进行检测,因此选用VOC2007数据集作为训练集和测试集。数据集包括人、狗等20个类,随机选取7000张图片作为训练集,剩下2963张图片作为测试集。
训练环境:处理器为Intel(R) Xeon(R) CPU E5-1620 v2,主频3.70 GHz,内存32 G,显卡为NVIDIA 1080 Ti。软件环境为Windows10操作系统,算法在Python3.7环境下运行,深度学习框架为Pytorch1.5.1。
YOLOv5m模型在训练中迭代次数epoch设置为150次,模型初始学习率为0.0001,采用GIoU_Loss作为损失函数。模型训练结果随迭代次数增加在测试集上的表现如图7所示。GIoU_Loss、mAP50分别表示训练的模型在测试集上的GIoU损失和平均准确率。从图中可以看出,在前50个epoch,模型的mAP50整体处于上升态势;当训练至第50 epoch后,模型整体趋于稳定。mAP50达到了86.9%,虚警概率为14.9%,模型训练效果良好。
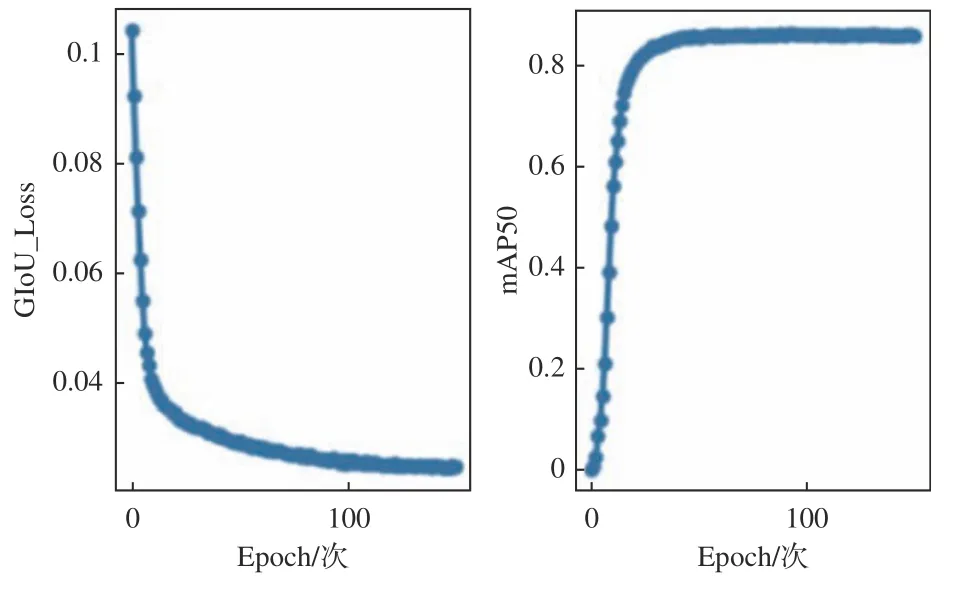
图7 YOLOv5m训练结果图Fig.7 Training result chart of YOLOv5m
目标检测效果如图8所示.

图8 目标检测效果图Fig.8 Renderings of object detection
将YOLOv5m检测结果作为系统量测值,对目标进行UKF跟踪。目标状态向量的初始化为误差协方差矩阵初始化为P0, 过程噪声矩阵为Qk,量测噪声矩阵为Rk,有:

(13)式中x0和y0为量测坐标。状态转移矩阵F为

利用UT变化获得Sigma点集,通过F传播后得到新Sigma点集的预测与协方差矩阵,最后利用量测更新系统状态和误差协方差矩阵。
在室内环境对算法性能进行测试,如图9所示。
图9中蓝色框为检测框,绿色框为跟踪框。采用基于GIoU的匈牙利算法将跟踪框与检测框匹配,设置(2)式的匹配阈值t= 0.3,匹配结果如表1。

表1 跟踪框与检测框匹配效果Table 1 Matching effect of tracking box and detection box

图9 YOLOv5m+UKF实验效果Fig.9 Experimental effect of YOLOv5m + UKF
在室内环境下录制8 min的音视频,对其中视频信息进行基于YOLOv5m+UKF的检测与跟踪实验,统计得检测框与跟踪框的匹配率为98.7%。
3.2 声源定位实验
为了验证图2所设计麦克风阵列在声源定位任务中的性能,设计如下实验。为了兼顾定位精确度和整个阵列轻便性,设置a = 28.28 mm,即4个麦克风呈正方形排布。由于麦克风阵列呈对称排布,只需在三维空间的第一象限设置声源验证系统性能即可。声源分别设置在(0,0,500)、(0,0,800)、(0,200,400)、(0,500,500)、(200,0,500)、(200,500,500)、(150,400,200)共7处,单位为mm。将喇叭放置于声源点位播放语音对话,每组录制10段音频。采样率为48 kHz,信噪比约为15 dB。以声源位于(0,0,500)其中一次实验为例,给出麦克风①④所接收的音频信号波形以及二者的GCC函数波形,如图10所示.


图10 音频信号波形图Fig.10 Audio signal waveform
由图10(c)可得时延为0.05个采样点,也就是1.042×10−6s。采用1.2节声源定位算法计算得方位角θ和φ,并统计θ和φ误差的绝对值均值,如表2所示。
由表2所示,2个方位角中φ表示水平方位角,θ表示俯仰角。从整体上看,平均误差在2°~3.5°之间,定位精度整体上满足系统需求。

表2 方位角θ和φ平均误差Table 2 Average error of azimuth θ and φ
3.3 音视频信息融合的跟踪实验
为了验证音视频融合跟踪算法的效果,使用图4所示的摄像头与十字型麦克风阵列(a= 28.28 mm),在室内复杂环境下录制总时长为8 min的音视频。视频中包括诸如多人对话、两人重叠、杂物遮挡目标等场景;音频中存在脚步声、碰撞声等噪声干扰。视频定位观测方差为900个像素,音频定位观测方差为2500个像素,粒子个数为50。
对录制的数据分别进行声源定位、基于视频的检测跟踪(YOLOv5m+UKF)、音视频融合的检测跟踪实验。跟踪结果对比如图11所示。


图11 3种算法跟踪效果对比Fig.11 Comparison of tracking effect of three algorithms
图11为3种算法在一段音视频的效果对比。视频中两人相对走过,从左向右移动的人(称为A)边走边说话,从右向左走动的人(称为B)不发出声音。图11左侧为声源定位结果,用红点表示声源定位,白点表示噪声大致位置;中间为YOLOv5m+UKF跟踪结果,用绿框表示;右侧为音视频融合的检测跟踪结果,红点和黄点分别表示A的声源定位和视觉跟踪结果,蓝点为粒子滤波点集,A的绿框为融合跟踪结果,由于B不发声,B的绿框为视觉跟踪结果。图11中各帧的声源定位、A的视觉跟踪、A的融合跟踪(加权重要性函数)、A的融合跟踪(不加权重要性函数)以及A人工标定的真实位置的具体坐标如表3所示。

表3 3种算法跟踪坐标数值Table 3 Tracking coordinate values of three algorithms
人工标注数据集中被遮挡目标的真实框,用G代表跟踪框与真实框的GIoU,采用1-G衡量跟踪结果与真实结果的误差。由于声源定位结果只有坐标没有跟踪框,因此用该目标视觉跟踪框的尺寸作为声源定位框的尺寸。图11中的音视频67帧~96帧的误差曲线如图12所示。
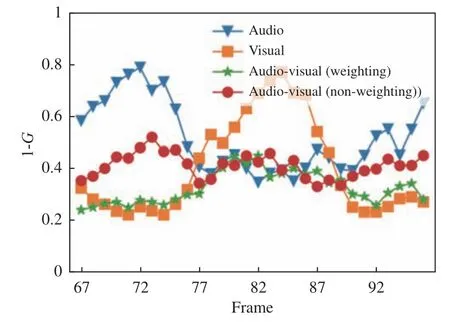
图12 音视频序列误差曲线图Fig.12 Error curves of audio and video sequences
分析可知,声源定位精度相对视频跟踪较低,当噪声较大时会使声源定位结果偏离目标。视频跟踪在没有遮挡时具有较高的精度,但是当目标被遮挡时,跟踪定位的精度会下降。音视频融合跟踪算法可以有效抑制单一模态的失效,增强跟踪系统的鲁棒性。采用加权音视频重要性函数的融合跟踪可以自适应调节音频和视频的可靠度,具有更强的抑制噪声的能力。
当跟踪框与真实框满足:

则认为该目标的跟踪结果准确,否则认为误跟。统计3种算法在所有音视频序列的跟踪准确率和平均每帧运行时间,如表4所示。融合检测跟踪的准确率90.68%远高于声源定位的74.48%和视频检测跟踪的83.46%,平均每帧运行时间29.2 ms小于视频每帧间隔时间33.3 ms。

表4 3种算法性能对比Table 4 Performance comparison of three algorithms
4 结论
本文提出一种音视频信息融合的检测与跟踪算法框架,并设计了音视频采集的硬件设备。采用YOLOV5m作为目标检测框架,使用UKF算法对多目标跟踪,使用匈牙利算法匹配检测与跟踪结果;采用GCC-PHAT作为时延估计算法,采用十字形麦克风阵列实现声源定位;在粒子滤波的基础上,构造音视频似然函数和音视频重要性函数,对音视频信息进行融合跟踪。经验证,算法提高了跟踪的精确度与可靠性,跟踪准确率为90.68%,高于声源定位和视频检测跟踪的准确率。
本算法所采用的声源定位算法只能定位一个声源。当所处环境同时存在多个发声目标时,系统跟踪性能会下降,后续将改进声源定位算法以实现多声源定位。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
家庭影院技术(2019年7期)2019-08-27
电子制作(2019年23期)2019-02-23
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
电子制作(2018年12期)2018-08-01
中国交通信息化(2017年2期)2017-06-06
电子制作(2017年9期)2017-04-17
噪声与振动控制(2016年5期)2016-11-09
人间(2015年8期)2016-01-09
