
农用地土壤重金属污染调查最优网格尺度及布点优化方法
2021-09-19 10:35秦旭芝郑涵文何瑞成丁文娟张军崔冠男史沛丽谢云峰
环境工程技术学报 2021年5期
秦旭芝,郑涵文,何瑞成,丁文娟,张军,崔冠男,史沛丽,谢云峰*
1.广西壮族自治区生态环境监测中心 2.桂林理工大学环境科学与工程学院 3.生态环境部土壤与农业农村生态环境监管技术中心
土壤重金属污染来源多样,由于重金属具有难降解、难迁移等特点,一旦形成污染会在土壤中长期存在,并且在空间分布上呈现出明显的异质性和不连续性,加大准确判断土壤中污染物空间分布的难度[1]。现有技术条件下缺乏直接确定土壤污染物空间分布的方法,只能基于采样调查数据通过数学模型进行空间插值[2-4],而这种研究方法的准确性受前期采样调查结果的影响很大。大量研究表明,对于空间分布变异性很大的污染物,布点方案是影响污染调查结果准确性的重要因素,如Jenkins等[5]对土壤中三硝基甲苯空间分布变异性的研究发现,95%的变异性来源于采样位置;Argyraki等[6]发现由采样位置造成的不确定性占整个污染物含量估计的不确定性的50%。结合调查区域的历史背景、地理环境,科学有效地制定布点方案能大幅提高土壤污染调查的准确性[7-9]。目前常用的布点方法主要包括两大类[10]:1)基于模型的布点方案,如网格布点法、随机布点法等[11];2)基于设计的布点方案,研究者基于调查区域的环境背景及土地利用历史等对可能存在污染的区域进行加密布点[12]。Brus等[13-15]对2种布点方案进行了详细论述和比较。
实际案例中多种布点方案常协同使用[16-20],但如何确定最优采样密度是土壤污染调查的重点和难点问题[21-24]。谢志宜等[25]在开展珠三角区域耕地土壤质量研究时发现,布点密度越大,调查区域土壤质量刻画越细致,但调查成本也越高,8 km×8 km的网格,能较好地保证调查结果的准确性,同时也能够有效降低调查成本。工业场地土壤通常具有重金属污染严重、污染重金属单一且分布较为均匀等特点[26-29],重金属污染调查尺度较小,调查时通常先采用系统布点法,排查整个调查区域内可能存在的土壤环境风险,然后结合分区布点法和专业判断法对可能存在环境风险的区域进行重点调查。兰鹏鹏等[30]以40 m×40 m网格对湖南某冶炼场地进行分区布点,结果发现场地污染主要在1.0~2.5 m深层空间内。
为确保调查区域内污染物空间分布的准确性,常需采用分阶段的方式对研究区域进行调查,主要包括基础信息调查、初步调查和加密调查等环节。场地污染物空间分布调查的误差主要来源于污染物空间分布插值结果不确定性较大的区域[31-34],污染程度高估会导致调查费用和修复费用的增加,污染程度低估会导致环境风险无法得到有效控制。点位优化的目的在于在寻求降低调查结果不确定性的最佳样本量,同时有效降低调查成本。本研究旨在探索农用地土壤重金属污染调查最优布点密度及布点优化,以提高土壤污染调查方法对污染区范围和污染程度的估计精度,并为土壤污染调查提供方法学支持。
1 材料与方法
1.1 研究区域
研究区域位于中南某老工业园区周边的农用地,地处111°58′E~113°05′E,27°20′55″N~28°05′40″N,调查区域面积约75万m2,所在区域总体地貌轮廓北、西、南地势高,中部、东部地势低平,但地势起伏较为和缓,高程为52.17~79.69 m,高差不大,地貌类型多样,山地、丘陵、岗地、平原、水面俱备(图1)。区域四季分明,降水充沛,盛夏高温,冬季寒冷。年均降水量为 1 425 mm,4—7月降水较集中,期间多有洪水发生,年均气温为17.5 ℃。冬季多西北风,夏季多东南风。研究区域周边的工业园区具有50多年的化工生产历史,工业企业数量多,“三废”排放量大,污染物种类多,对周边农用地土壤环境影响较大。

注: 红色表示高程较高;黄色表示高程中等;绿色表示高程较低。图1 研究区域内地形地势示意Fig.1 Map of terrain within the scope of study
1.2 土壤采集与分析
按照70 m×70 m网格设计要求,共布设168个表层土壤(0~20 cm)采样点,现场利用GPS获取采样点经纬度,使用木铲进行表层土壤采样,低温保存于密封袋中带回实验室。土壤样品经风干去除杂物后,研磨过100目尼龙筛。采用HNO3-H2O2消解法进行样品预处理,采用石墨炉原子吸收光谱法测定土壤Cd浓度。每个样品设3组平行样,选10%的样品做重复测试,并进行空白试验,测定过程中添加国家标准物质(GSS-6)进行质量控制。同时测定土壤理化性质(表1)。另外还检测了其他5种重金属(Cu、Ni、Pb、Hg、Zn)浓度。检测结果显示,除Ni外其他重金属均存在超标情况,其中Cd超标点位最多,其他重金属仅个别点位超标。

表1 土壤理化性质参数Table 1 Physical and chemical properties of soil
1.3 子样本的抽取
将调查区域分为70 m×70 m、100 m×100 m、160 m×160 m和200 m×200 m 4种网格尺度。先随机抽取18个点位作为独立验证集〔图2(a)〕,构建除70 m×70 m尺度外的其他3种尺度网格,将距离网格中心点最近的点位作为该尺度下的采样点,最终得到100 m×100 m尺度网格点位数87个,160 m×160 m 尺度网格点位数37个,200 m×200 m尺度网格点位数24个(图2)。
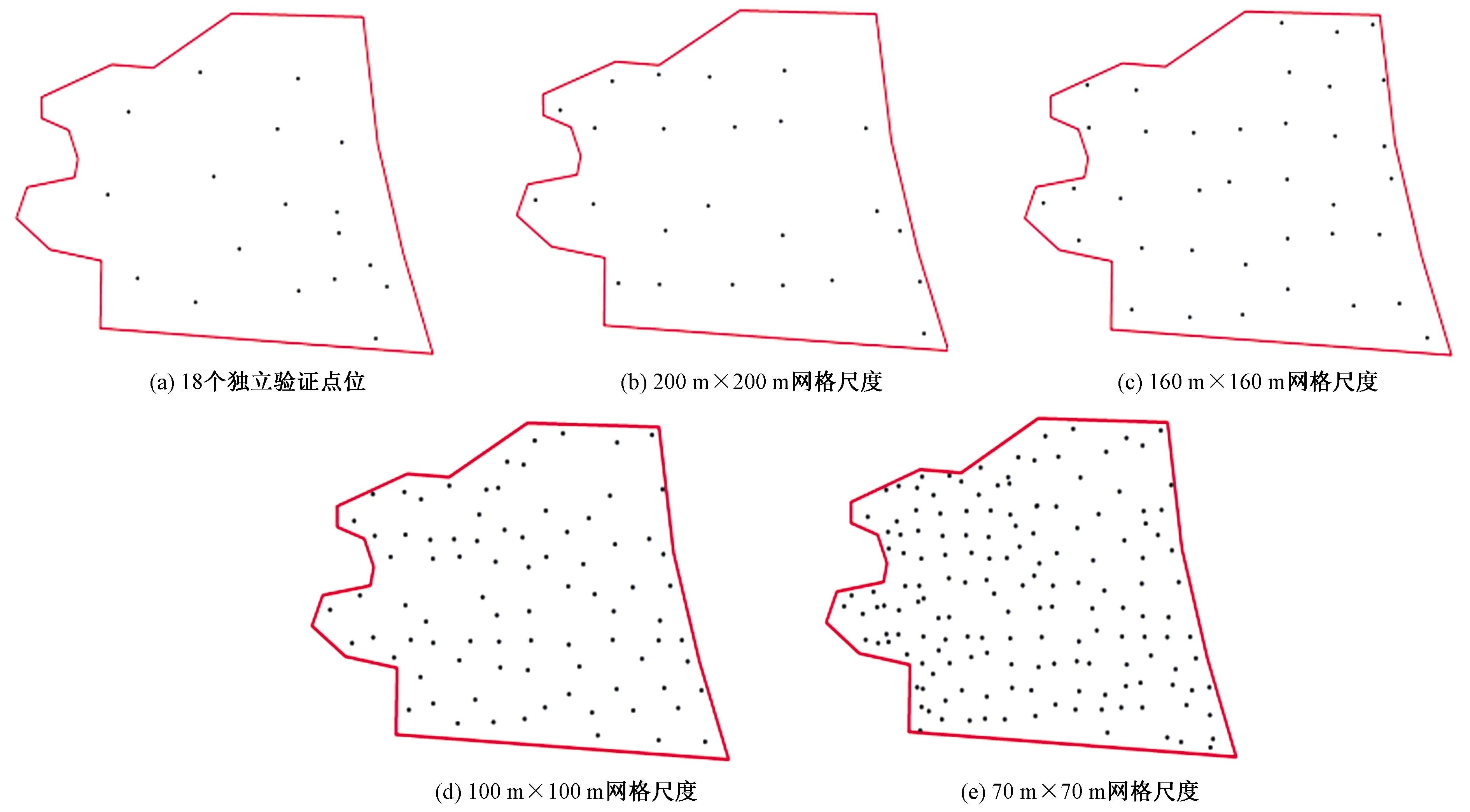
图2 抽取样本子集及其验证点位分布Fig.2 Sampling subset and distribution of verification points
1.4 土壤Cd浓度空间插值及其精度评价
利用ArcGIS 10.5软件对不同调查尺度下土壤Cd浓度进行空间分析,利用Matheron矩估计法,以权重最小二次方拟合理论半方差函数模型。采用克里格(Kriging)法对4种采样尺度测定结果进行插值,分析不同采样尺度检测结果的精确度。由于4种采样尺度土壤中Cd浓度均不符合正态分布,使用BOX-COX变换进行数据转换,经K-S 检验后符合正态分布。评价结果采用半方差函数及交叉验证确定最佳精确度。结合调查区域土壤pH,根据GB 15618—2018《土壤环境质量 农用地土壤污染风险管控标准(试行)》,采用0.6 mg/kg作为区域内Cd污染评价标准。
2 结果与评价
2.1 不同采样尺度下土壤Cd浓度变异性
对4种采样尺度下土壤Cd进行半变异分析,结果如图3和表2所示。从图3看出,4种采样尺度的采样点间距离均小于空间相关距离,说明4种采样尺度均适用于空间变异分析,但不同尺度下的空间相关距离存在差异。从图3还可看出,土壤Cd浓度均表现出了一定的线性趋势,说明存在较好的半方差结构,且采样尺度越小线性趋势越明显。块金值通常被认为是代表随机变异的量,而基台值代表变量空间变异的结构性方差,二者比值为块金系数。当块金系数小于25%时,表示变量具有强烈的空间相关性;块金系数为25%~50%,表示变量具有明显的空间自相关;块金系数为50%~75%,表示变量具有中等的空间自相关;块金系数大于75%时,表示变量空间自相关性较小。从表2可知,70 m×70 m、100 m×100 m、160 m×160 m、200 m×200 m 4种采样尺度下土壤Cd浓度的块金系数分别为65.82%、46.40%、58.65%和45.37%,均在25%~75%之间,表明研究区土壤Cd浓度具有中等空间相关性,受结构性因素和随机因素影响。
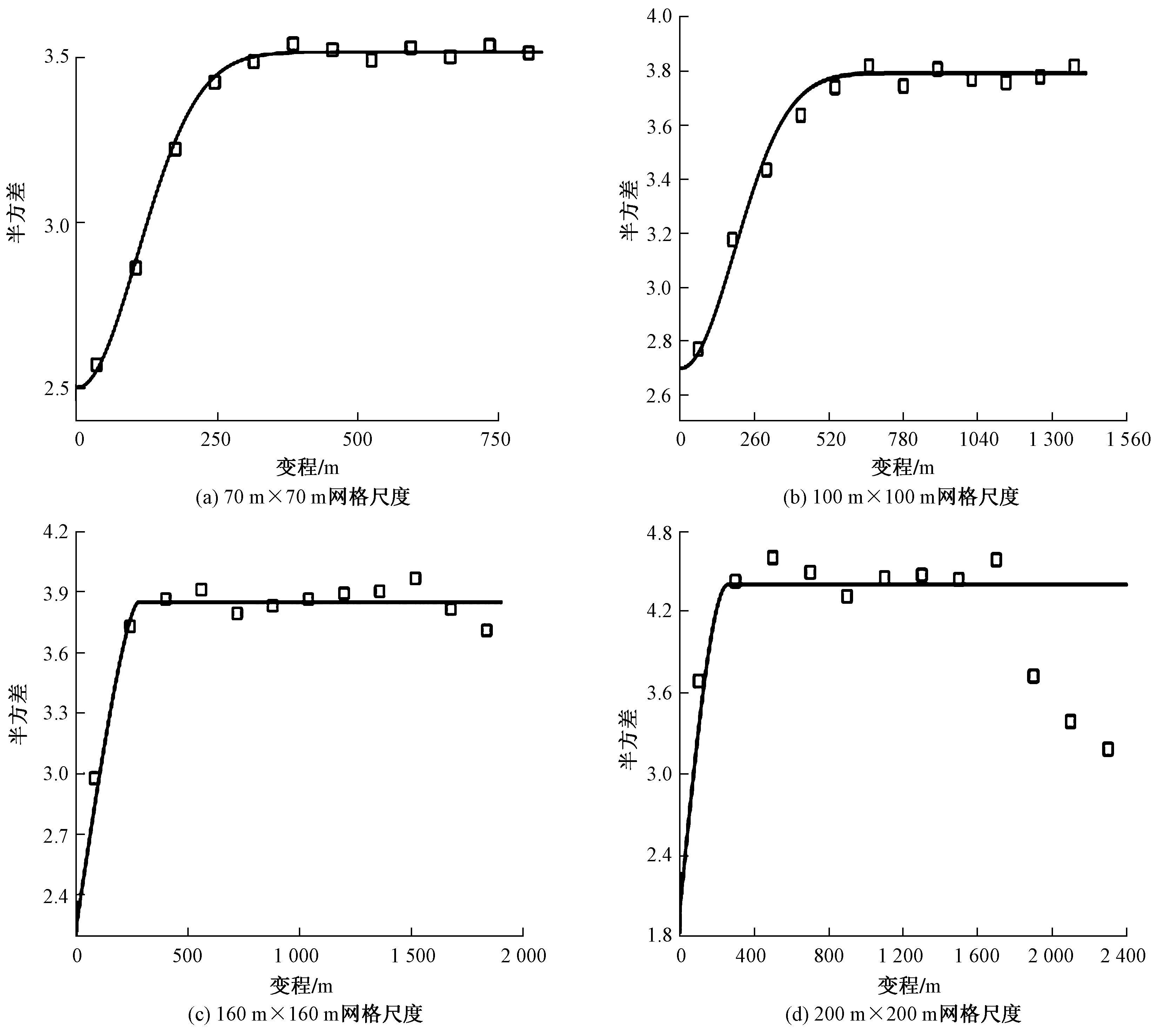
图3 不同采样尺度下土壤Cd浓度半方差分布Fig.3 Semi-variance distribution of Cd content in soils at different sampling scales

表2 不同采样尺度下土壤Cd半变异函数参数Table 2 Semi-variant function parameters of Cd in soils at different sampling scales
2.2 土壤Cd浓度空间预测精度比较
将4种网格尺度下土壤Cd浓度克里格插值进度交叉验证(Cross Validation),结果见表3。由表3可见,总体而言4种采样尺度下采样网格越小,平均误差(ME)绝对值越小。70 m×70 m和100 m×100 m 采样尺度的均方根误差(RMSE)和平均标准误差(ASE)较小且接近,表明70 m×70 m和100 m×100 m网格采样精度接近,且能较好地满足预测要求,预测值与真实值相近。
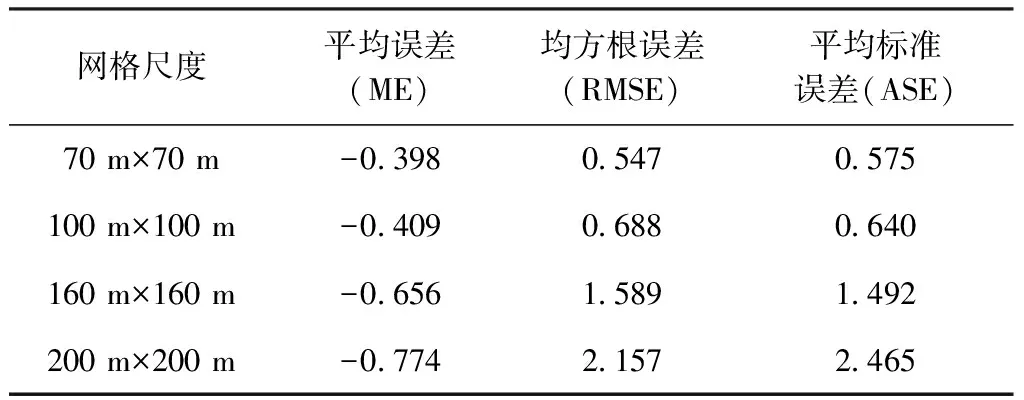
表3 不同采样尺度下克里格法插值精度估计Table 3 Estimation of Kriging interpolation accuracy at different sampling scales
图4为不同采样网格尺度下克里格插值方法土壤Cd浓度的独立验证结果。由图4可知,网格密度越小,克里格插值预测精度越高,且4种采样密度下|RMSE-ASE|随采样网格尺度的增大而增大,说明采样网格越小,插值预测的结果越接近真实值。200 m×200 m网格尺度下精度远小于其他较小的网格尺度。总体而言,采样网格越大,土壤Cd的预测越平滑,对细节反映能力越弱,结合半方差函数分析及ME、RMSE、ASE 3项指标,100 m×100 m网格能较为准确地反映场地Cd浓度分布状况。
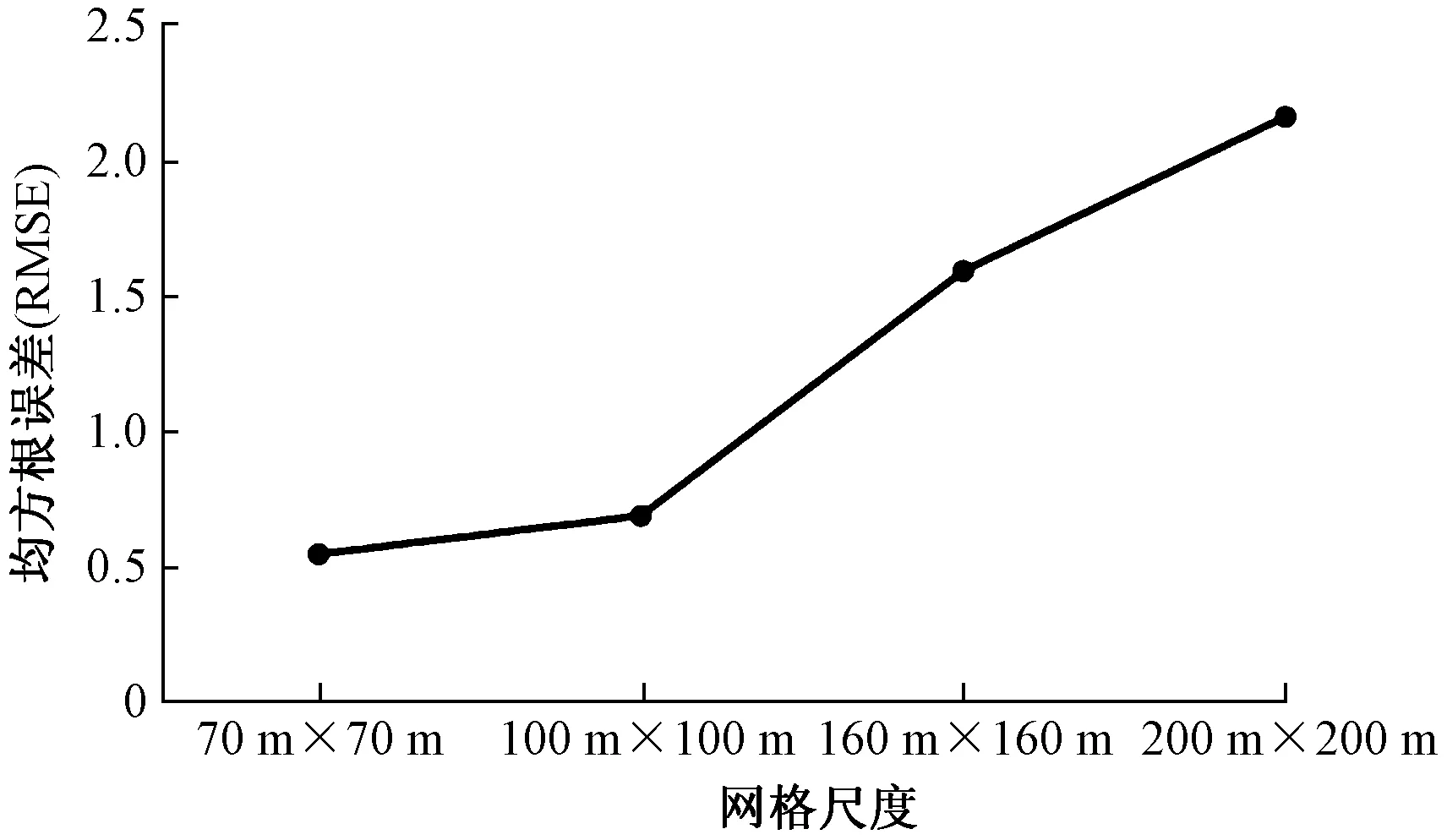
图4 不同采样网格尺度下土壤Cd浓度克里格 插值的独立验证结果Fig.4 Independent validation results of Kriging interpolation of Cd content in soils at different sampling grid scales
2.3 污染范围预测不确定性分析
污染范围界定得准确与否以及对预测不确定性区域的量化对场地的修复治理边界以及相关决策的制定具有重要影响,污染范围界定过大,将实际未污染的区域插值预测为污染区域,会过多地耗费人力、物力,加大修复成本,造成一定的经济负担;而污染范围界定过小,将实际污染的区域插值预测为非污染区域,导致场地污染风险不能有效降低或消除。
利用污染预测标准误差图,量化不同空间位置预测结果的不确定性。结果显示,采样点周边位置的误差通常很小,预测标准误差大的区域主要集中在样点较为稀疏且有高值点的区域。为进一步明确预测结果的不确定性区域,将污染范围预测图和预测标准误差图进行空间叠加计算,假定将预测值与误差值之差大于0.6 mg/kg的范围划分为污染区域,二者之和小于0.6 mg/kg的范围划为未污染区域,其他为不确定性区域,划定结果见图5。由图5可见,不确定区域主要分布在西南侧和北侧区域,这2个区域从20世纪60年代至21世纪初先后存在多家从事化工生产活动的企业,因生产条件有限、排污过程的跑冒滴漏会导致地块土壤受到污染,污染物在地下水水力作用的影响下迁移扩散,使得地块周边农田土壤成片受到污染,且西南侧和北侧区域内还存在池塘等使前期该区域采样点较少,即不确定区域主要存在样点稀疏且高值区域。

图5 土壤Cd污染调查点位分布Fig.5 Distribution of samples for investigation of Cd pollution in soils
2.4 不确定性区域加密验证
通过预测标准误差图划定不确定性区域,按初步调查超标点位邻近原则,在不确定区域内的初步调查超标点位周边选取最近点位作为详细调查点位(图5),对初步调查和详细调查Cd浓度结果进行统计分析,结果见表4。从表4可知,100 m×100 m网格初步调查结果空间位置精确度为78.89%,对场地污染范围预测不确定性影响较大的主要是高估区域,占比为14.23%,在不确定性区域加密布点以后,空间位置精确度提高到86.25%,提高了7.36个百分点,且污染高估区域占比明显下降。对污染物浓度统计分析发现,100 m×100 m网格初步调查与详细调查结果差距不大,与所有样点进行对比发现,100 m×100 m网格Cd平均浓度略大于70 m×70 m网格,但二者误差满足HJ/T 166—2004《土壤环境监测技术规范》所规定的25%范围。图6为土壤Cd污染范围预测结果。由图6可见,Cd污染主要集中在场地西侧,100 m×100 m网格加密前和加密后的差异主要集中在不确定性区域范围内。100 m×100 m 网格精确度有明显提升,同时调查点位数量下降了35%。

表4 土壤Cd统计特征Table 4 Statistical characteristics of Cd in soil heavy metals
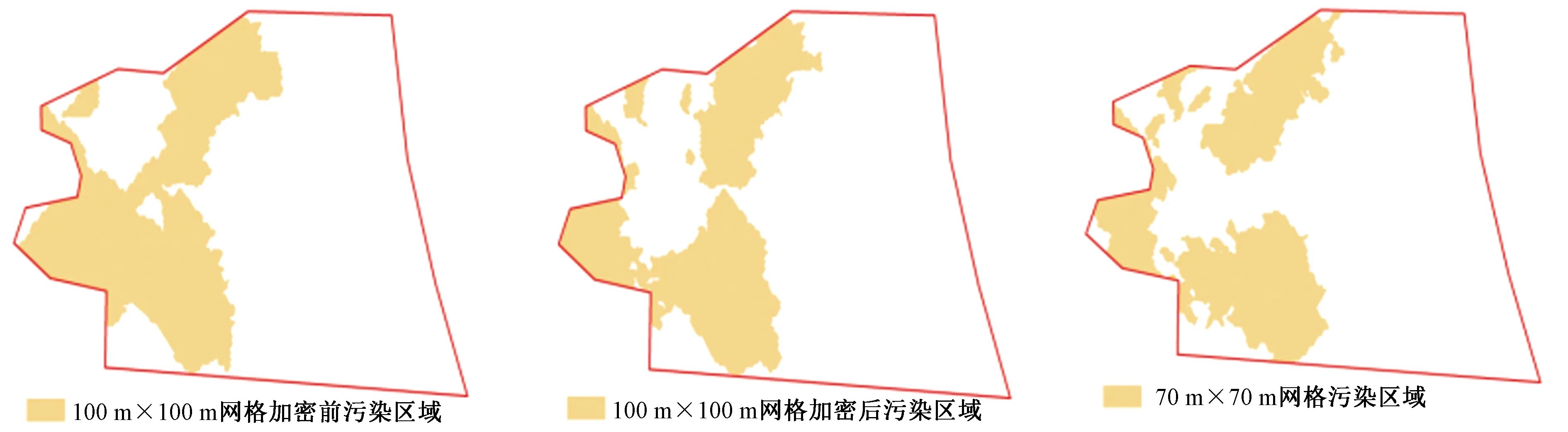
图6 土壤Cd污染范围预测结果Fig.6 Prediction results of Cd pollution range in soils
本研究旨在探索科学合理的农用地土壤污染调查最佳布点密度及点位优化方法,在分析土壤污染物空间自相关性的基础上,利用地统计学方法进行空间分布插值,基于预测误差和污染评价标准,划定调查结果不确定性区域,结合初步调查超标点位和地形、地貌等条件,在不确定性区域中加密布点,从而提高调查精度。该方法依据地统计学基本假设,适用于空间分布具有中等相关性及以上的污染物,胡克林[35-37]等研究表明,表现出较明显空间相关性,但对于空间自相关性较弱,仅在局部区域个别点位超标的重金属、多环芳烃等污染物,该方法的适用性需进一步验证,这与谢云峰等[1]的研究结果类似。本研究采样布点方法与目前概率加密布点法和模拟退火算法的各类加密方法相似[38-39],基于初步调查点位数据进行地统计学分析,判断污染物是否具有空间自相关性,对于具有空间自相关性的污染地块再进行参数化计算,从而优化加密布点区域,做到既有效降低调查成本,又能提高调查精度。
3 结论
(1)对于采用基于模型化采样布点的污染场地调查而言,通过独立验证和交叉验证模型方法,能够对采样网格尺度进行有效优化,本研究中100 m×100 m网格能够在准确反映场地污染程度及范围的前提下,降低采样及分析成本。
(2)基于空间插值预测标准误差与预测值进行运算,能合理确定场地污染的不确定性范围,通过对不确定性区域进行针对性加密布点,能显著提高预测精确度。
猜你喜欢
导航定位学报(2022年3期)2022-06-10
区域治理(2021年34期)2022-01-01
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
新生代(2018年16期)2018-10-21
北京航空航天大学学报(2017年2期)2017-11-24
进出口经理人(2017年11期)2017-09-22
商情(2017年23期)2017-07-27
太空探索(2016年5期)2016-07-12
计算技术与自动化(2014年1期)2014-12-12
时代英语·高三(2014年5期)2014-08-26
