
面向信息与通信技术供应链网络画像构建的文本语义匹配方法
2021-09-14 09:21:42罗森林杨俊楠潘丽敏吴舟婷
北京理工大学学报 2021年8期
罗森林, 杨俊楠, 潘丽敏, 吴舟婷
(北京理工大学 信息与电子学院,北京 100081)
随着全球化进程的发展,信息和通信技术供应链(information and communications technology supply chain management,ICT供应链)具备全球分布性以及供应商多样性等特点,与此同时也带来了供应中断、信息泄露等安全隐患[1].自2019年5月以来,美国商务部分别将华为及其旗下累积达144个附属关联公司列入出口管制的“实体清单”,对我国信息通信技术相关产业的经济发展带来巨大冲击.因此,加强ICT供应链管理已成为关乎国民经济和国家安全的重要工作[2].为有效管控ICT供应链的安全风险,需要充分挖掘多层级供应关系,在安全事件发生时,及时开展关联分析、评估事件影响范围.各行业招投标平台网站、供应商官网和国家企业信用信息网等公开数据可以为ICT供应链网络多层级关系挖掘提供了可行性,而基于公开数据挖掘ICT供应关系需要完成的首要任务是ICT招投标项目文本和供应商产品文本的正确匹配.
文本匹配是自然语言处理中的一项基本技术[3],用于确定两个文本的关系.在释义识别任务中,文本匹配用于确定两个文本是否释义[4].对于自然语言推理任务,文本匹配用于判断是否可以从前提语句中推断假设语句[5].在问答任务中,文本匹配用于判断两个问题句是否意义相同,并指向同一个答案.目前文本匹配方法主要分为两种框架,第一种框架是基于句子单独编码的方法[6-7],在此框架中,将神经网络编码器(例如CNN或LSTM)分别应用于两个输入文本,将两个文本编码为相同嵌入空间中的表示向量,仅基于两个表示向量做出匹配决策,例如THYAGARAJAN[8]和HUANG[9]等的工作.第二种框架是增加句子交互机制的匹配方法.该框架首先对两个文本的单词或者上下文向量进行匹配,然后将匹配结果通过CNN或LSTM等编码器编码为向量,以给出最终匹配结果.这种匹配框架捕获了两个文本之间的交互信息,相对于第一种框架,性能有明显改进.目前的研究工作大都使用注意力机制作为交互层来表达词汇或短语级别的对齐方式[10-11].例如ESIM[11]使用注意力机制,采用双向LSTM作为编码器和聚合器.在此基础上,研究人员主要采用三种方法来进一步提高性能.首先是使用更丰富的语法或手工设计的特征.HIM[11]使用语法分析树,也有研究使用POS标签,包括TAYETAL[12]和GONG等[13]等的研究.在GONG[13]和KIM等[3]的工作中,包含词性标注和字向量注意力机制等密集交互的方法得到了较为精准的匹配结果.第二种方法是使用更多元的匹配机制.ABCNN[4]采用了3种不同的注意力方案来融合序列间不同的交互特征.增强模型的第三种方法是为匹配结果构建后处理层.DIIN[13]用DenseNet作为深度卷积特征提取器,以从匹配结果中提取信息.除以上3种方法之外,也有研究通过序列间的多次匹配来构建更有效的模型.DRCN[3]堆叠编码和对齐层,它连接所有先前对齐的结果,但是必须使用自动编码器来处理特征空间爆炸的问题.RE2[14]保留原始的词向量特征、先前的对齐特征和上下文特征3个关键特征以进行序列间比对,并通过增强残差连接所有特征.这些常见文本匹配方法一般针对以句子匹配为目标的数据集,其输入为形式相同的句子级短文本,未对输入数据的结构化特征进行考虑.
ICT领域文本匹配的输入数据源种类更多,形式复杂,目前没有针对性的解决方案.招投标平台公开的招投标项目是基于功能描述的实体级项目名称(如图1(a)、(b)),而供应商官网产品页面信息包含实体级的产品名称和文档级的产品描述(如图1(c)、(d)).其中,实体级的产品名称,其命名方式分为基于功能命名(例如“动环监控系统解决方案”)和基于型号命名(例如“雷米微服务云平台-RayMix”).文档级的产品描述内容较长,通常包括产品结构、功能、性能和使用说明等多方面描述.针对ICT输入数据源的文本特点,常见文本匹配方法不支持ICT招投标项目与供应商产品文本匹配的原因有以下两点.
① 供应商产品与招投标项目相关的信息分布于产品名称和产品描述,现有文本匹配方法对不同长度文本无差别编码会引入与招投标项目无关的噪声信息.对于基于功能命名的产品,将产品名称和产品描述无差别地输入到句子级编码器与招投标项目进行匹配,产品描述中结构、性能、使用方法等与招投标项目无关的信息将对包含功能描述的产品名称产生干扰(如图1(a)、(c)),产品编码向量引入大量噪声,降低性能.而基于型号命名的产品,其名称无法体现功能信息,需要从产品描述中提取功能描述信息,与招投标项目进行匹配(如图1(b)、(d)).
② 仅使用单一种类句子级编码器无法有效对产品名称和产品描述进行编码.由于产品名称为实体级的短文本,语义分布集中于词汇或短语,需要有效提取其局部信息;而产品描述为文档级的长文本,内容多且主题分散,为了提取与招投标项目相关的功能描述信息,需要同时考虑产品描述上下文的全局信息和介绍功能的局部重点信息.
面向ICT招投标项目与供应商产品文本匹配任务,针对ICT项目及产品数据种类多、形式复杂,难以提取其语义匹配信息,且现有句子级文本匹配模型对不同长度文本无差别编码会引入噪声导致匹配效果差的问题,本文提出一种融合局部和全局特征的实体-文档级联合匹配模型(entity-document level joint matching model,EDJM),该模型首先构建实体-实体匹配模块,利用TextCNN编码器从不同范围提取招投标项目和产品名称的局部信息进行匹配,消除产品描述中与招投标项目无关信息的影响;再构建实体-文档匹配模块,利用卷积-自注意力编码器提取招投标项目和产品描述的局部和全局信息,并通过对齐层序列间的注意力交互机制增加产品描述中与招投标项目有关信息的权重,然后进行匹配;最后联合决策匹配结果.该联合匹配模型既能兼顾产品名称和产品描述的信息,又能消除产品描述对产品名称的干扰,实验结果表明该模型能有效提高匹配性能,方法已实现直接实际应用.
本文提出了EDJM模型,其主要贡献如下.
① 提出一种融合局部和全局特征的实体-文档级联合匹配模型,通过将产品名称和产品描述与招投标项目进行联合匹配,消除产品描述中与招投标无关信息对产品名称的干扰,并针对不同长度文本的编码要求,选取TextCNN和CNN-SA作为编码器提取文本局部和全局信息,提升匹配性能,方法可直接实际应用.
② EDJM在ICT文本匹配数据集上F1值达到57.18%,优于其他匹配模型.
1 实体-文档级联合匹配模型
1.1 原理框架
针对ICT项目及产品数据种类多、形式复杂,难以提取其语义匹配信息,且现有句子级文本匹配模型对不同长度文本无差别编码会引入噪声导致匹配效果差的问题,EDJM首先构建实体-实体匹配模块,利用TextCNN编码器提取招投标项目和产品名称的局部信息进行匹配,消除产品描述中与招投标项目无关信息的影响;再构建实体-文档匹配模块,利用卷积-自注意力编码器提取招投标项目和产品描述的局部和全局信息进行匹配;最后联合决策匹配结果.EDJM的原理框图如图2所示.

图2 EDJM原理图Fig.2 Principle diagram of EDJM
1.2 实体-实体匹配模块
1.2.1编码层
嵌入层将两个待匹配文本嵌入为固定维度的向量,编码层使用TextCNN利用不同粒度卷积窗口对文本进行特征抽取.xi∈Rk对应于文本中第i个词的k维词向量,那么长度为n的句子则表示为
x1:n=x1⊕x2⊕…⊕xn
(1)
式中:⊕表示拼接操作;xi:i+j表示xi,xi+1,…,xi+j的串联.卷积运算的滤波器w∈Rhk应用于h个单词的窗口以产生新的特征,例如,从词xi:i+h-1产生特征ci
ci=f(w*xi:i +h -1+b)
(2)
式中:b∈r为偏置项,f为非线性激活函数.该滤波器应用于句子{x1:h,x2:h+1,…,xn-h+1:n}中每个可能的单词窗口以生成特征图
c=[c1c2…cn -h +1]
(3)
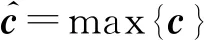
以上为一个滤波器提取实体特征的过程,TextCNN使用多个滤波器来捕获多个特征.所有的特征被馈送进全连接层,输出固定维度向量.
编码层在全连接层之前采用权重向量的L2范数约束进行正则化,在前向传播中以dropout概率随机删除隐藏单元参数来防止过拟合
y=w*(z°r)+b
(4)
其中[°]为逐元素相乘运算符.
1.2.2匹配层
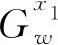
(5)
这使得TextCNN在训练过程当中完全捕获待匹配实体的语义差异,避免用复杂的学习器来修正TextCNN形成的向量造成语义损失.
由于训练的早期阶段,基于L2范数的模型无法纠正错误,而基于欧几里得距离的模型则由于梯度消失问题,将语义不同的句子错误判断为相同,因此论文选择基于曼哈顿距离的g函数作为相似性度量函数,从经验上看[8],基于曼哈顿距离的g函数性能更优.
1.3 实体-文档匹配模块
在实体-文档匹配模块中,两个文本被嵌入为向量表示,然后由N个结构相同的连续构建块通过增强的残差连接进行连续处理,每个构建块参数独立.在每个块内,CNN-SA编码器首先计算文本的上下文特征(图2中的实心圆圈),然后连接编码器的输入和输出,将其馈送进对齐层,对两文本之间的对齐和交互进行建模.融合层融合了对齐层的输入和输出,其输出即为构建块的最终输出.最后一块的输出输入到池化层,并转换为固定长度的向量.预测层将两个向量作为输入并预测最终目标.损失函数使用交叉熵损失[14].
1.3.1增强残差连接
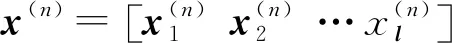
(6)
式中[;]表示拼接操作.在增强残差连接下,对齐和融合层的输入中包含全程保持不变的原始点状特征(嵌入向量),由先前块处理和优化的先前对齐特征(剩余向量)以及上下文编码器层的特征(编码向量)[14].
1.3.2编码层
编码器读取残差块的输入x(n),然后通过以下方式获得输出a(或者b)
a=F(x(n))
(7)
式中:F代表模型编码器的函数;a=[a1a2…ala].编码器由3层网络堆叠:多层卷积层,自注意力层和前馈层,并在每一层之间进行标准化处理,编码器的结构如图3所示[15].

图3 CNN-SA编码器Fig.3 CNN-SA encoder
多层卷积层使用深度可分离卷积而不是传统卷积,因为深度可分离卷积存储效率更高且通用性更好,这一层将堆叠多层卷积.对于自注意力层,本文采用多头注意力机制,其计算过程如图4所示.

图4 多头注意力机制Fig.4 Multi-head attention
其中,图4的虚线框部分为按比例缩放的点积,其计算公式如下
(8)
应用卷积运算将输入矩阵x(n)映射为Q,K和V三个矩阵,并使用h个并行的头来关注向量的不同部分.对于第i个头,可以获得3个矩阵Qi,Ki,Vi.缩放点积注意力用于计算Qi和Ki与最终向量表示Hi之间的相关性;最后,将由h个并行头产生的所有向量拼接在一起形成一个向量.这个向量是多头注意的结果.计算公式为
MultiHead(Q,K,V)=Concat(H1,H2,…,Hh)
(9)
对于前馈层,论文使用两种传统的卷积操作.编码器中的这些基本操作(卷积、自注意力、前馈)位于残差块中,对于给定的输入x和给定的运算f,残差块的输出为
x=f(layernorm(x))+x
(10)
其中,layernorm表示层归一化处理.
1.3.3对齐层
对齐层采用基于注意力机制的对齐方式,将两个文本序列的特征作为输入,以计算的对齐表示作为输出.假设第一个实体序列长度为la,表示为a=(a1,a2,…,ala),第二个实体序列为lb,表示为b=(b1,b2,…,blb).ai和bi之间的相似性得分eij由二者的投影向量点积计算而得
eij=F(ai)TF(bj)
(11)
F是单层前馈网络.输出向量a′和b′通过对另一文本序列的表示进行加权求和来计算[14].该总和由当前位置与另一个序列中相应位置之间的相似性分数加权
(12)
(13)
1.3.4融合层
融合层从3个角度比较局部以及对齐层的表示,然后将它们融合在一起.第一个序列的融合层的输出如下
(14)
(15)
(16)
(17)
其中G1,G2,G3和G是具有独立参数的单层前馈网络,而[°]表示逐元素乘法.减法运算突出显示两个向量之间的差异,而乘法则突显相似性.b的计算方式与a相同,不再赘述[14].
1.3.5预测层
预测层将来自池化层的两个序列v1和v2的向量表示作为输入,最终目标预测函数为
y2=H([v1;v2;v1-v2;v1°v2])
(18)
式中:H为多层前馈神经网络.
1.4 决策输出模块
决策输出模块采用分类器投票的方式.假设实体-实体匹配模块的输出表示为y1,实体-文档匹配模块的输出表示为y2,模块交互层表示为
y=y1‖y2
(19)
2 实验分析
2.1 实验数据
实验数据为ICT招投标项目与供应商官网产品文本匹配数据集(ICT数据集),ICT数据集由北京理工大学信息安全与对抗实验中心采用网络爬虫技术,从招投标平台以及各中标公司官网获取,并由25位自然语言处理领域硕士、博士研究生进行3次交叉验证标注,将最终结果进行合并、评估,当多数标注者(两位及以上)认为该文本对具有高度匹配关系时,则认为该文本对是匹配的.
ICT数据集每一条样本包含3个字段:招投标项目名称、产品(包含产品名称和产品描述)、标签,数据集详细信息如表1所示.

表1 ICT数据集详细信息
2.2 评价方法
ICT数据集存在数据不平衡的特点,实验采用准确率,F1值和AUC值对结果进行评价.
若一个实例是正例,被预测成为正例,即为真正例(true postive,TP);若一个实例是负例,被预测成为负例,即为真负例ηTP(true negative,TN)ηTN;若一个实例是负例,但是被预测成为正例,即为假正例(false postive,FP)ηTP;若一个实例是正例,但是被预测成为负例,即为假负例(false negative,FN)ηTN.
准确率α(accuracy)即正确预测的样本总数,公式为
(20)
精确度β(precision)表示被分为正例的样本中实际为正例的比例
(21)
召回率r(recall)表示在所有正例当中,有多少正例被正确地分为正例
(22)
F1值综合考虑了精确度和召回率,计算公式为
(23)
ROC(receiver operating characteristic)曲线是以假正率(FP rate)和假负率(TP rate)为轴的曲线,ROC曲线下面的面积叫做AUC,AUC的值越大,模型性能越好.
2.3 对比分析实验
2.3.1实验目的
为了验证EDJM在ICT招投标项目与供应商产品匹配任务上的效果,在ICT数据集上与7个对比算法进行比较.
2.3.2实验过程
实验采用十折交叉验证方法,将EDJM同7种文本匹配方法进行比较,包括DSSM[11](2013)、MaLSTM[10](2015)、ESIM[9](2016)、ABCNN[4](2018)、DIIN[13](2018)、DRCN[3](2018)、RE2[14](2019),其中ESIM使用原始ICT数据集进行实验表示为ESIM-1,使用下采样之后正负样本比1∶2的ICT数据集进行实验表示为ESIM-2.模型的预训练词向量300维,语料库为中文维基百科,由word2vec中的连续词袋(CBOW)模型进行训练[16],词表大小为961 M.将数据按8∶1∶1分为训练集、验证集与测试集,EDJM的CNN-SA编码器卷积核的数量为128,在一个编码器中卷积层的数量为4,在所有层中,多头注意力的头的数量为5.
2.3.3实验结果
表2的实验结果显示,EDJM在ICT数据集上的准确率、F1值和AUC值均为最佳,优于对比算法.在对比算法中,ESIM模型在ICT数据集上F1值为0,经过下采样后的ICT数据集在ESIM上正常训练,说明模型在极度不平衡的数据集上无法正常训练,EDJM对不平衡数据具有一定鲁棒性.由此可证明,对比算法对不同长度文本无差别编码会引入与招投标项目无关的噪声信息,EDJM将产品名称和产品描述与招投标项目进行联合匹配能够消除产品描述对产品名称的干扰,有效提升匹配性能.
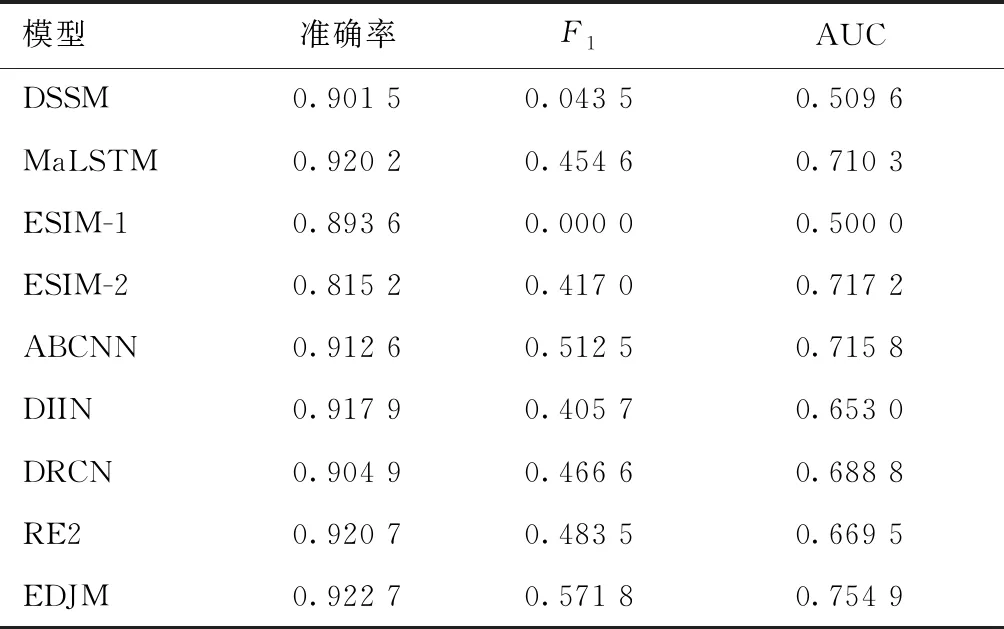
表2 ICT数据集对比实验结果
2.4 模块有效性实验
2.4.1实验目的
为验证EDJM各模块对模型的作用以及各编码器对模块的影响,在ICT数据集上与7种方法或组合进行比较.
2.4.2实验过程
实验设置按照输入分为3类,(1)~(2)组实验仅使用EDJM模型的实体-实体匹配模块完成匹配,它们的输入为:招投标项目名称、产品名称、标签,不同的是(1)组使用双向LSTM编码器,(2)组即为EDJM实体-实体匹配模块,使用TextCNN编码器.(3)~(5)实验仅使用EDJM模型的实体-文档匹配模块完成匹配,他们的输入为:招投标项目名称、产品描述、标签,不同的是(3)组使用CNN编码器,(4)组实验使用双向LSTM编码器,(5)组实验即为EDJM实体-文档匹配模块,使用CNN-SA编码器.(6)~(8)组实验使用联合匹配模型来完成匹配,它们的输入为原始ICT数据集,不同的是(6)组的两个模块都使用CNN编码器,(7)组的两个模块都使用CNN-SA编码器,(8)组即为EDJM模型,实体-实体匹配模块使用TextCNN编码器,实体-文档匹配模块使用CNN-SA编码器.
其中,双向LSTM的隐藏单元为50,句子长度(1)组设置为15,(4)组设置为999.
2.4.3实验结果
表3结果显示,EDJM在Accuracy、F1、AUC上的性能优于仅使用其中一个模块的实体-实体匹配模型和实体-文档匹配模型,EDJM-CNN的性能也优于仅使用其中一个模块的实体-实体匹配模型和基于CNN的实体-文档匹配模型.仅使用招投标项目和产品描述进行匹配,F1值下降近17个百分点,这是由于大部分产品是基于功能命名,只依靠产品描述进行匹配丢失了名称中的功能描述信息;同样,仅使用招投标项目和产品名称进行匹配的实体-实体匹配模型性能也有所降低,这是因为只依靠产品名称无法对基于型号命名的产品进行匹配.因此证明供应商产品与招投标项目相关的信息分布于产品名称和产品描述,EDJM的实体-实体匹配模块、实体-文档匹配模块对于匹配效果均有提升作用.
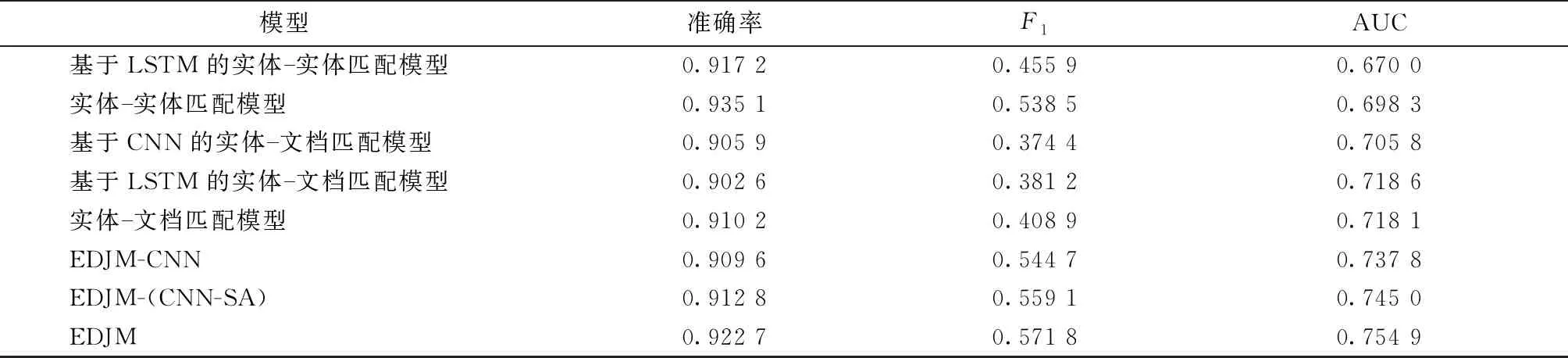
表3 模块有效性实验结果
在(1)~(2)组的实验中,实体-实体匹配模型的性能优于基于LSTM的模型,原因在于产品名称语义分布集中,局部信息对匹配更有效,textCNN可提取产品名称的局部信息,双向LSTM是基于序列的编码器,更侧重于建模全局信息,对局部信息的提取效果不如TextCNN;在(4)~(6)组的实验中,使用CNN或者LSTM作为编码器性能都低于实体-文档匹配模型,原因在于产品描述为主题分散的长文本,CNN无法有效兼顾全局和局部信息,而LSTM对局部信息提取能力弱.(6)~(8)组的实验中,使用单一种类编码器的EDJM-( CNN-SA)和EDJM-CNN表现不如EDJM.因此证明,单一种类编码器无法有效编码产品名称和产品描述,且实体-实体匹配模块的TextCNN能有效提取产品名称的局部信息、实体-文档匹配模块的CNN-SA能有效提取产品描述的局部和全局信息.
3 结 论
面向ICT招投标项目与供应商产品文本匹配任务,针对ICT项目及产品数据种类多、形式复杂,难以提取其语义匹配信息,且现有句子级文本匹配模型对不同长度文本无差别编码会引入噪声导致匹配效果差的问题,论文提出了一种融合局部和全局特征的实体-文档级联合匹配模型.通过构建实体-实体匹配模块,利用TextCNN编码器提取产品名称的局部信息与招投标项目进行匹配,消除产品描述中与招投标项目无关信息的影响;构建实体-文档匹配模块,采用卷积-自注意力编码器提取产品描述的局部和全局信息与招投标项目进行匹配;最后联合两模块匹配信息,投票得到匹配结果.为了评估该模型在文本匹配问题上的效果,将EDJM同ABCNN、ESIM、RE2等文本匹配模型上在ICT数据集上进行对比,依据准确率、F1值、AUC值3个评价指标进行评价,结果表明EDJM模型能够有效提高匹配性能.论文方法已应用于“重点行业ICT产品(或系统、服务)供应链网络画像和安全风险分析实用系统”,其中,EDJM模型实现了招投标项目和供应商官网产品的关联分析,攻克了挖掘ICT供应链多层级网络关系中的关键技术难题.在后续应用中,基于多层级ICT供应链网络开展的关键节点和安全风险分析准确率超过90%.
目前ICT领域文本匹配缺乏大型公开数据集,研究未来将尝试与迁移学习相结合,利用其他领域丰富的标注资源,提高ICT招投标项目与供应商产品文本匹配的性能.
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
校园英语·下旬(2018年12期)2018-02-26 12:48:32
电子设计工程(2017年20期)2017-02-10 03:39:29
信息安全研究(2016年4期)2016-12-01 06:06:54
电子器件(2015年5期)2015-12-29 08:42:24
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
电测与仪表(2014年13期)2014-04-04 12:04:18
河北农机(2013年6期)2013-10-09 11:16:16
河北农机(2013年6期)2013-10-09 10:50:14
