
融合衣服特征迁移的行人重识别方法
2021-09-13 01:02:26苑春苗
计算机与生活 2021年9期
苑春苗,牛 瑛,郭 涛,李 鑫
1.天津工业大学 天津市自主智能技术与系统重点实验室,天津300387
2.天津工业大学 计算机科学与技术学院,天津300387
3.天津工业大学 电子与信息工程学院,天津300387
4.天津工业大学 经济与管理学院,天津300387
在进行跨摄像头人物匹配时,由于人脸识别技术广泛存在后脑勺和侧脸的情况,做正脸的人脸识别就很困难;另外,由于相机分辨率和拍摄角度的缘故,通常无法得到质量非常高的人脸图片,匹配效果经常失效。因此,跨摄像头人物匹配通常采用行人重识别(person re-identification,Re-ID)[1]技术。Re-ID即在非重叠摄像头中人物匹配的过程,一般可以表述为图像的排序问题:给定一个人的查询图像(query image),需要根据其相似性对所有的库图像(gallery image)进行排序。该技术可广泛应用于智能视频监控、智能安保等领域。
对于目前行人重识别存在的一些挑战,近几年来国内外学者主要通过以下三个方向进行研究:第一是通过局部特征提取[2-4]方法;第二是通过距离学习方法[5-6];第三是通过深度学习方法[7-10]。这些Re-ID方法在匹配过程时,目标人物的服装信息在局部特征中占有较大的比重,而当目标行人在查询库和图像库中衣服特征发生改变的时候,这些算法的性能都将会下降,不能准确地将更换衣服后的行人匹配出来。
由此可见,行人重识别的方法严重依赖于服装信息。在实际应用中,查询图像中的人和图像库中的人可能穿不同的衣服。例如,一个罪犯可能会穿上不同的衣服,以避免在他或她离开犯罪现场后被跟踪;并且人们会隔几天换一次衣服,因此当查询图像和图像库不在同一天拍摄时,目标人物的衣服信息可能不同。
在上述讨论的基础上,本文提出了基于衣服特征迁移的行人重识别模型,主要解决同一个目标行人穿着不同衣服进行行人重识别的问题。模型主要分为三个模块:行人检测模块、衣服特征迁移模块、行人匹配模块。该模型的基本思想是:给定一个目标人物的查询图像,通过衣服特征迁移算法,将图像库中所有人物的衣服特征都更换成与目标人物的衣服特征一样,目的是消除在匹配过程中衣服特征差异,最后通过人物肢体特征来进行匹配。
本文的贡献主要包括三部分:(1)这是一次研究目标人物在查询图像和图像库中穿着不同衣服的Re-ID 问题;(2)为目标人物在查询图像和图像库中穿着不同衣服的Re-ID 问题开发了第一个公共数据集;(3)为了消除人物匹配过程中的服装差异,提出了一种基于查询图像中目标人物的服装特征,在图库图像中更换人物服装的新方法。
1 相关工作
行人重识别最初用于多摄像头跟踪。Gheissari等人[11]设计了一种提取视觉线索的时空分割方法,并使用颜色、显著边缘进行前景检测。该工作将基于图像的行人重识别定义为特定的计算机视觉任务。近年来,行人重识别通过手工设计识别特性[12]、跨摄像机视图学习特性转换和学习距离度量来解决这个问题。除此之外,许多研究者提出了各种基于深度学习的方法,共同处理所有行人检测和人的识别。
深度学习方法:Li等人[13]为Re-ID设计了特定的CNN(convolutional neural networks)模型。这个网络利用裁剪过的图像,并采用二进制验证损失函数来训练参数。Deng等人[14]和Chen等人[15]利用三联体样本对CNN进行训练,最小化同一人的特征间距离,最大化不同人之间的距离。
二维姿态估计方法:关节式人体位姿通常采用一元项和图形结构[16]或图形模型,身体部分混合[17-19]的组合建模。随着深度姿势[20]的引入,将姿态估计问题转化为使用标准卷积架构的回归问题,人类姿态估计的研究开始从经典方法转向深度网络。例如,Wei等人在文献[21]中引入了对身体各部分空间相关性的推论。Newell等人提出了一个堆叠的沙漏网络[22],使用重复的下池化和上采样过程来学习空间分布。
人体分割方法:最近,许多研究都致力于人体分割[23-30]。例如,Liang 等人[24]提出了一种新颖的Co-CNN 架构,将多个层次的图像上下文集成到一个统一的网络中。为了在先进的CNN架构的基础上捕捉丰富的结构信息,常用的解决方案包括将CNN 和条件随机场(conditional random fields,CRF)[31]结合起来,采用多尺度的特征表示[25]。Chen等人[15]提出了一种注意机制,该机制学习对每个像素位置的多尺度特征进行加权。
基于图像的服装合成:最近的几项研究[9-10]解决的问题与本文相似。Lassner等人[7]提出了一种方法,生成同一个人在相同姿态条件下任意服装的图像。文献[8]提出了一种框架,可以在保持服装不变的同时修改图像中人物的视点或姿势。文献[9]试图将一件独立的衣服转移到一个人的图像上,而文献[10]解决了相反的任务,即在给定人物图像的情况下生成一件独立的衣服。最后,Zhu等人[32]的工作是基于文本描述从给定的图像生成不同的服装,同时保持原始图像的姿势。Yang等人[33]提出了一种不同于生成模型的思路,它包括对三维身体模型的估计,然后进行服装模拟。变换姿态:Ma 等人[8]提出了一个框架修改一个图像里人的角度或姿态,同时保持服装不变。Raj等人[34]提出了一种以无监督的方式从图像中分离出姿态、前景和背景的方法,这样不同的分离表示可以用来生成新的图像。以上的工作并没有解决在保持目标图片身份的同时将服装从源转移到目标的问题,而事实上,在服装的转移过程中往往会丢失身份。另一个不同之处在于,他们通常使用从稀疏的姿态关键点导出的剪影来表示姿态,而本文是使用独立的衣服分割信息来表示姿态,服装分割提供了比姿态关键点更多的特征信号,使本文方法能够更精确地将服装从源转移到目标。
异常图像重识别及识别性能优化:最近的一些工作解决了人们对异常图像的重新识别,如低分辨率图像或部分遮挡图像等识别。他们利用分离检测和重新鉴定的方法与分数重新加权来解决这个问题。Xiao 等人[35]提出了一种两方面共同处理的深度学习框架,开发了一种端到端人员搜索框架,利用在线实例匹配损失(online instance matching loss,OIM)来共同处理两方面,提出了身份嵌入(identification embedding,IDE)方法和置信加权相似度(confidence weighted similarity,CWS)来提高人员识别性能。另一个有效的策略是分类模型,它充分利用了Re-ID标签。Zheng 等人[31]提出了一种识别嵌入(IDE)方法,将重构后的识别模型训练成图像分类,该方法在图像网络预训练模型的基础上进行了微调。Wu等人[36]提出了一种特征融合网络(feature fusion net,FFN),将自己设计的特征融合到CNN特征中。最近,Ma等人[8]提出一种新颖的深度学习方法,用于将现有数据集的标记信息转移到新的看不见(未标记)的目标域中,以便人员重新识别,而无需在目标域中进行任何监督学习。具体来说,引入了可转移的联合属性的标签用于深度学习,同时可转移到新的目标域进行无监督学习的RE-ID任务。
2 方法
提出的框架如图1 所示,本文的模型描述如下,分为三个步骤:
(1)人物检测:给定查询图像和图库图像,目标人物位于给定图像中,包含人物的子图像记为P0。给定图库图像中的所有人都被定位,并记为Pi,i=1,2,…,n。利用Faster RCNN检测子图像P0,P1,…,Pn。
(2)衣服特征转移:人体二维关键点和服装分割特征分别位于子图像P0和P1,P2,…,Pn中。P0的服装特征被转移到P1,P2,…,Pn,并生成新的子图像,其中包含目标人物的衣服重新搭配后的图像P0和
(3)人员匹配:P0与匹配。整个模型框架可以表示为:
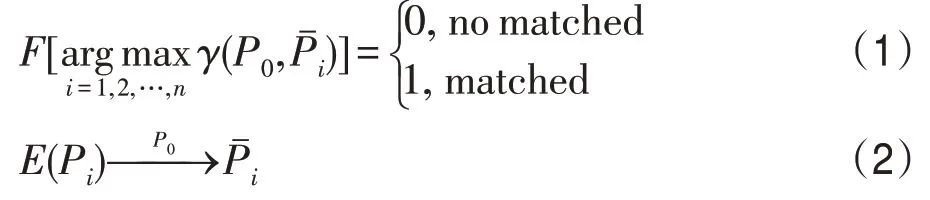
其中,E是将P0衣服特征转移到Pi的迁移函数,并生成新的人物图像;γ是排序函数;F可以评估最大分数是否合理匹配,当输出结果为0 的时候,表示查询行人与图像库中的行人不匹配,当输出的结果为1的时候,表示查询图像和图像库中的行人匹配。
2.1 人员检测模块
给定查询图像和图像库图像的视频帧,目标人物位于给定的查询图像中,包含该人物的子图像表示为P0。给定图像库中的所有人都被定位并表示为Pi(i=1,2,…,n)。使用Faster-RCNN[37]网络检测的子图像分别记为P1,P2,…,Pn。
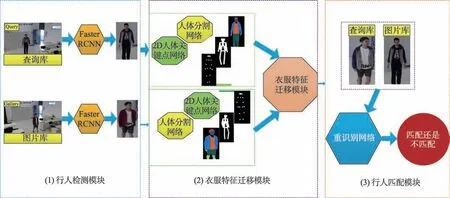
Fig.1 Framework of person re-identification with clothes transfer图1 基于衣服迁移的行人重识别总体方案框架
2.2 衣服特征迁移模块
衣服特征迁移函数(clothing feature transferring function,CFTF)是该方法的核心部分。与CFTF最相关的工作是Zhu等人的论文[32]。本文在基于文献[38]的方法中使用了CFTF模型,但是他们的模型需要手动定位身体的关键点。因此,本文的模型利用文献[39]自动定位二维人体关键点。此外,利用文献[40]提取衣服特征中的查询和图库图像。
2.2.1 二维人体关键点
系统以大小为w×h的彩色图像为输入,生成图像,并自动输出图像中每个人的人体二维关键点。首先,前馈网络同时预测一组二维的人体部位置信度图和一组二维的人体部位相似性向量场,对人体部位之间的关联程度进行编码。集合S=(S1,S2,…,SJ)有J个置信映射,每个部分一个,其中Sj∈Rw×h,j∈1,2,…,J,集合L=(L1,L2,…,LC) 有C个向量场,其中Lc∈Rw×h×2,c∈1,2,…,C中的每个图像位置都编码一个二维向量。最后,通过贪婪推理对置信图和亲和域进行分析,自动输出图像中所有人的二维人体关键点。
图2 是二维人体关键点卷积网络框架。图像首先由卷积网络进行分析(由VGG-19 的前10 层初始化并进行微调),生成一组特征图F,输入到每个分支的第一阶段。在第一阶段,网络产生一组检测置信度图S1=A1(F)和一组局部亲和力场L1=B1(F),其中A1和B1是第一阶段推理的CNN。在每个后续阶段,来自前一阶段的两个分支的预测,连同原始图像特征F,被连接起来,用来产生精确的预测。
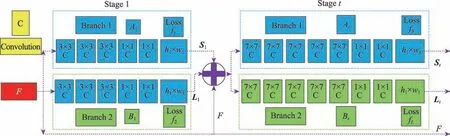
Fig.2 2D human key points convolutional network framework图2 二维人体关键点卷积网络框架
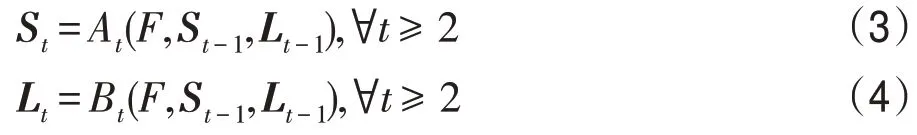
其中,At和Bt为t阶段推理的CNN。
在关键点提取算法中衡量预估值与给定真值间的损失差异使用了欧氏距离L2损失函数。这里,本文在空间上对损失函数进行加权,以解决某些数据集并没有完全标记所有人的问题。其中,两个支路在t阶段的损失函数为:
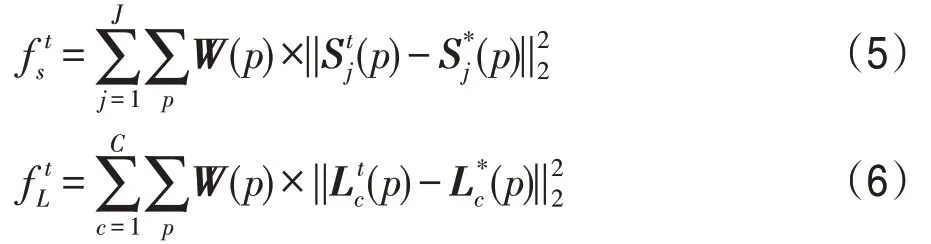

将查询和图库中的图像输入到二维关键点模块中,输出所有人的二维关键点(p0,p1,…,pi),分别记为k0,k1,…,ki,为下一阶段的衣服特征的转移做准备。
2.2.2 人体分割算法
全卷积网络FCN-8s[41],深度卷积编解码器架构(SegNet)[42],具有无穷卷积和多尺度(DeepLab VGG-16)[43]的深度卷积网,DeepLab ResNet-101 以及注意机制[23](attention)等结构在进行语义图像分割时,均取得了优异的效果。在本文的模型中,为了进行公平的比较,在LIP 训练集上对每种方法进行训练,直到验证性能达到饱和,并对验证集和测试集进行评估。对于DeepLab 方法,本文去掉了后处理的、密集的CRF。和文献[27]一样,本文使用IoU 标准和像素级精度进行评估。
和文献[44]一样,对于每个分割结果和对应的真值,本文计算区域的中心点,得到以热图表示的关节,使训练更加顺畅。然后,本文使用欧几里德度量来评估生成的联合结构的质量,这也反映了预测的分割结果与真值之间的结构一致性。最后,用关节结构损失加权像素级分割损失,得到结构敏感损失。因此,整个人体分割网络在结构敏感损失的情况下变得自我监督。
图3 给出了SS-JPPNet[40]用于人体分割的示意图。对于给定的图像I,定义一个关节构型列表,其中根据分割结果映射计算出第i个关节的热图。同理,,由相应的解析真值得到。这里,N是由输入图像中的人体决定的变量,对于全身图像,N等于9。对于图像中遗漏的关节,简单地将热图替换为填满0的热图。关节结构损失为欧几里德(L2)损失,计算如下:

最终的结构敏感损失(称为Lstructure)是关节结构损失和解析分段损失的组合,其计算公式如下:

其中,Lparsing是基于分割注释计算的像素级soft-max损失。
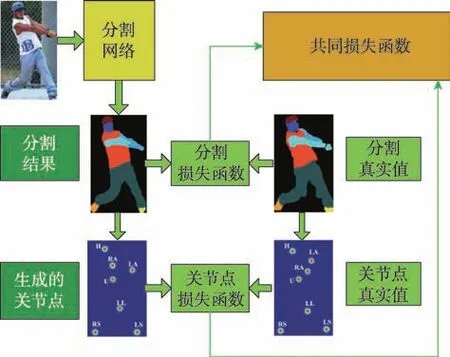
Fig.3 SS-JPPNet for human parsing图3 人物分割的算法SS-JPPNet框图
2.2.3 衣服特征转移
衣服特征转移函数框架如图4 所示。本文提出了一个服装转换系统,可以交换一对图像之间的衣服,同时保持姿势和身体形状不变。本文通过将服装的概念从体型和姿势中分离出来,从而达到这个目的,这样就可以改变人或服装,并重新组合它们。给定一张穿着所需服装的人的图像P0和以目标人体形状和姿势刻画另一个人的图像Pi,本文生成的图像由穿着P0中的所需服装与Pi相同的人组成。注意,P0和Pi描绘了不同的人,不同的体型和姿势穿着任意的衣服。本文的衣服特征迁移网络的整体功能如下:
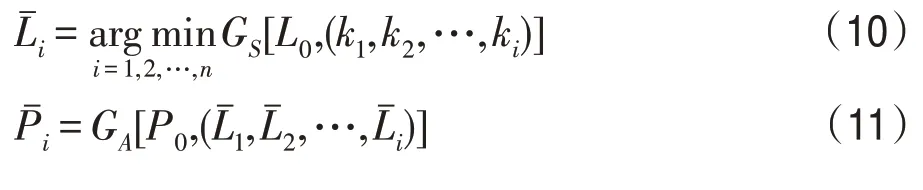
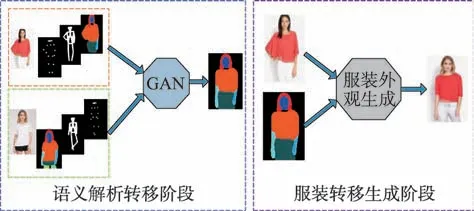
Fig.4 Framework of clothing feature transfer图4 服装特征转移框架
本文提出了一个两阶段的流水线来分别处理语义解析传输和服装传输生成,如图4 所示。具体来说,衣服分割和身体分割提供了一个简洁和必要目标所需的服装和身体。因此,首先在Pi的目标体型和姿态中生成衣服分割,其中衣服在P0中。假设图像P0的衣服分割和图像Pi的二维人体关键点在之前的工作[45]中给出或计算。在第二阶段,本文输入合成的服装分割和想要的服装图像,生成最终的转移结果。
2.3 人员匹配模块
本文采用ResNet-50作为基于CNN模型的网络结构。该模型前面有一个7×7的卷积层(命名为conv1),后面是四个块(命名为conv2 到conv5),每个块分别包含3、4、6、3个残差单元,采用第一层到第四层作为源CNN 部分,给定一张输入图像,输出一个1 024 维的特征图,这个特征图是原图像的1/16,根据特征流,利用卷积层来对行人特征进行转换,接着在特征热图[37]的每个位置利用9 个锚点(源于Faster RCNN[37])和Soft-max分类器进行行人与否的预测,同时还包括了线性回归来调整的锚点位置,在非最大抑制过后保留128个调整后的边界框作为最终的区域提议。
为了在这些区域提议里找到目标行人,建立了识别网络来提取肢体特征,并与目标行人进行对比。首先利用卷积层从特征热图中得到的区域(对应于每个提议区域),接着将它们送入ResNet-50 的第四至第五层,再利用整体平均层将其整合为2 048维的特征向量。一方面,行人预测网络不可避免地会包含一些错误的警报(也就是边界框里包含的不是行人)和错位,利用soft-max 分类器和线性回归来拒绝非行人区域并完善区域提议的位置;另一方面,本文将特征投影到经过欧式距离L2 正则化后的256维向量子空间中(这里进行低维投影是因为OIM 容易过拟合),计算它们和目标行人的余弦相似度。在训练阶段,本文用提出的OIM损失函数来监督,与其他用于检测的损失函数一起,整个网络以多任务学习的方式联合训练,而不是使用文献[35]中的替代优化。
2.4 匹配损失函数
有三种不同类型的预测,即有标记身份、未标记身份和背景混乱。假设训练集中有L个不同的目标人员,当一个预测与目标人员匹配时,称其为标记身份的实例,并为其分配一个类别ID(从1到L)。还有许多预测可以正确预测行人,但并不属于目标人群。在这种情况下,称其为未标记身份。在提出的损失函数中,仅考虑标记和未标记的身份,而其他预测则不予考虑。
本文的目标是区分不同的人,因此本文的模型要尽量减少同一个人实例之间的特征差异,而最大限度地增加不同人之间的差异。为了实现这个目标,需要记住所有人的特点。这可以通过对所有训练图像进行离线的前向网络训练来完成,但在使用随机梯度下降(stochastic gradient descent,SGD)进行优化时是不可行的。因此,在本文方法中,选择在线近似代替。在一个小批处理中x∈RD表示标记身份的特征,其中D为特征维,维护一个查找表(LUT)V∈RD×L来存储所有标记身份的特征。在正向传播过程中,通过VTx计算了小批样本和所有标记恒等式之间的余弦相似性。在反向传播时,如果目标类id是t,将更新t列附近地区的vt←γvt+(1-γ)x,γ∈[0,1],然后将vt缩放L2-norm 个单位。
除了有标记的身份,许多未标记的身份对于学习特性表示也很有价值。它们可以安全地用作所有标记身份的负样本。使用一个循环队列来存储这些在最近的小批中出现的未标记身份的特性。用U∈RD×Q表示这个循环队列中的特征,其中Q为队列大小,还可以用UTx计算它们与小批量样本的余弦相似度。在每次迭代之后,将新的特征向量推入队列,而取出过时的特征向量以保持队列大小不变。
基于这两种数据结构,定义了一个soft-max函数来确定x被识别为类IDi的标识的概率。
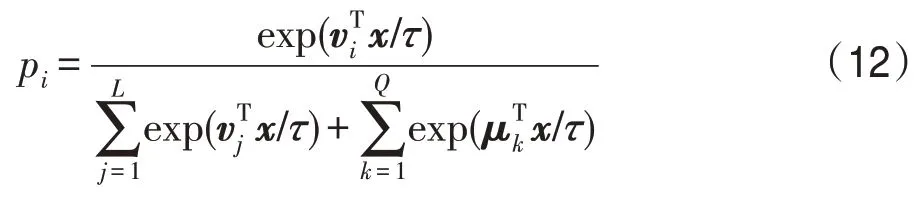
更高的温度τ将会导致更柔和的概率分布。同样,在循环队列中被识别为第i未标记标识的概率为:
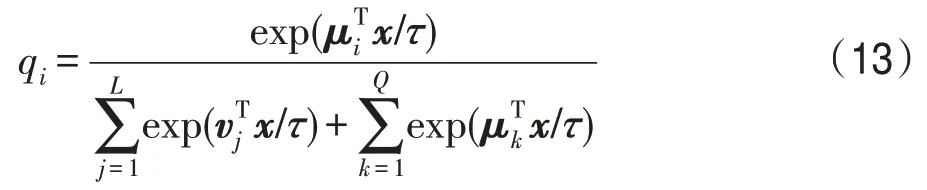
OIM的目标是最大化预期的对数似然率:

可以看出,本文方法的损失有效地将小批样本与所有标记和未标记的身份进行了比较,使得底层特征向量与目标向量相似,同时将查询图像中的底层特征向量与图像库中的其他特征向量差异增强。
3 实验
3.1 PRDDC数据集的标注描述
由于当目标人物在图库图像中更换衣服时没有行人重识别数据集,构建了一个名为PRDDC(person RE-ID with different clothes)的数据集。本文的数据集主要分为三种类型:第一种是目标人物在录像中换装,主要是夏装和春装;第二种是收集100个明星,在不同的场合穿不同的衣服(包括娱乐明星、体育明星);最后,目标人物在录像中更换衣服,主要是更换更厚的冬衣。本文的数据集中总共包含12 279帧图像,这些图像是在公共场所收集的。图5给出了在数据集PRDDC图片库中的一些例子,相同的人员身着不同的衣服。数据集有三个子数据集:
(1)单人在同一位置(person Re-ID with different clothes of single people in a fixed position,PRDDCFP),在PRDDC-FP数据集中包含2 235帧。
(2)单人随机姿势(person Re-ID with different clothes of single people in random postpose,PRDDCSPRP),在PRDDC-SPRP数据集中包含6 486帧。
(3)多人随机姿势(person Re-ID with different clothes of multiple people in random postpose,PRDDCMPRP),在PRDDC-MPRP数据集中包含4 058帧。
3.2 实验设置
本文的实验是在操作系统Ubuntu16.04 环境中配置的,其操作系统的位数为64位,使用python编程语言来实现算法模型,用深度学习框架Keras 和Tensorflow作为主要框架,与此同时还使用了Cuda8.0进行GPU 加速操作,由于数据集数量大、训练时间长,本文选择GPU来进行图像特征的提取,这样一来不仅可以提高运算的速度,而且其输出结果的精确度也很高。本数据集训练中数据迭代的次数为160次,训练期间总共耗费的总时间为8 h。

Fig.5 Examples of persons that change their clothes on dataset图5 数据集中更换衣服的人的示例
基于tensorflow 的框架实现了深度Re-ID 模型。采用ResNet-50作为模型的主干,并使用在Image-Net上预先训练的参数对模型进行初始化。固定了前两个残差层来节省GPU 内存。输入图像大小调整为256×128。在训练中,执行随机翻转、随机裁剪和随机擦除来增加数据。Dropout 的概率设置为0.5。在ResNet-50 基础层中以0.01 的学习率训练模型,而在前40个epoch中以0.1的学习率训练模型。在接下来的20 个epoch 内,学习率除以10。采用SGD 优化模式进行训练。将源图像和目标图像的迷你批处理大小都设置为128。初始化更新率的关键记忆α为0.01,随着epoch的增加线性增加α值,即α=0.01×epoch。设置温度β=0.05,候选正样本k=6 和权重的损失λ=0.3。在前5个epoch用样本不变性和摄像机不变性学习训练模型,并在其余epoch加入邻域不变性学习。在测试中,提取第5 个池化层的L2正则化输出作为图像特征,并采用欧氏距离来度量查询图像与图库图像的相似性。
3.3 评价指标
一个好的Re-ID 系统有两个特点:首先,所有的人都精确地定位在每个图像中;其次,给定一个查询图像和一个图库图像,由图库图像捕获的同一个人的所有实例都将在顶级结果中检索。给出一个查询图像P0和一个图库图像Pi,计算它们之间的相似度得分,得到一个排序结果。使用平均精度(mean average precision,mAP)指标来评估人员重新识别的准确性,这是所有查询的平均精度(average precision,AP)值。通过累积匹配特性(cumulative matching characteristic,CMC)和平均精度(mAP)来评估性能。
3.4 人员检测评价
本文使用mAP指标来评估行人检测模块的有效性,分别在数据集PRDDC 的三个子数据集PRDDCFP、PRDDC-SPRP、PRDDC-MPRP 上进行评估,使用不同检测算法在三个子数据集的准确率比较结果如表1 所示,从测试结果可以得出如下结论:使用Faster RCNN[37]检测器的性能最好,在三个子数据集上的性能分别为84.3%、86.6%、88.2%,因此选择Faster RCNN[37]网络作为本文的行人检测网络。
本文在子数据集和数据集PRDDC 中检测的结果如图6所示,在视频帧1中主要是对单个目标行人进行检测,从图中结果可以得出行人检测网络能够准确有效地将单个行人检测出来;在视频帧2中主要是对多个目标行人进行检测,从图中结果可以得出行人检测网络能够准确有效地将多个目标行人同时检测出来。综上所述,可以得出如下结论:使用行人检测网络能够准确地将视频帧中的目标行人检测出来。
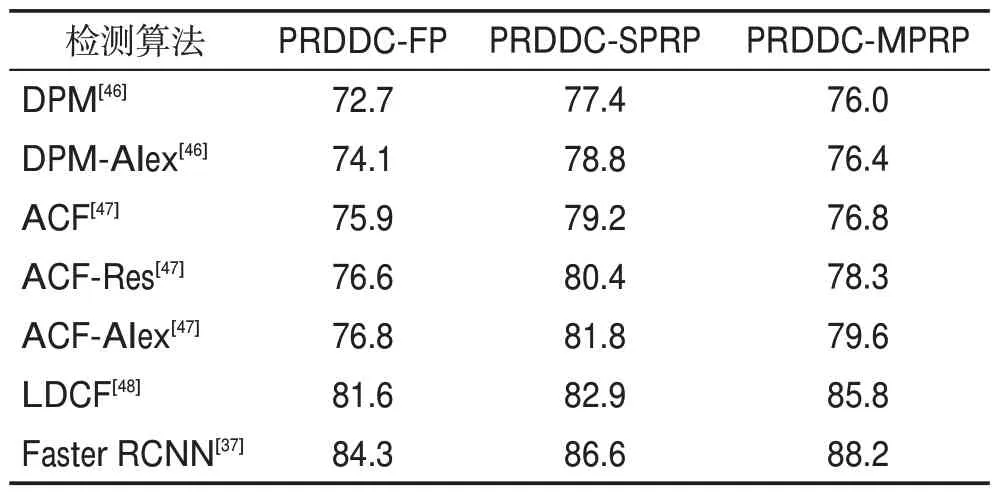
Table 1 mAP of different detectors表1 不同检测算法的平均精度 %

Fig.6 Person detection results on dataset PRDDC图6 数据集PRDDC上的人员检测结果
3.5 服装信息转移功能评价
(1)二维人体关键点。本文使用的关键点提取模型主要是从一张图像中定位人物二维关键点,在服装特征的转移过程中,会利用人的二维关键点。本文工作的创新之处在于可以自动输出二维的人体关键点。这种自动定位方法优于现有的解决方案,可以自动定位人体的二维关键点来进行换衣。
本文在human3.6M 数据集[49]上进行关键点模型训练,该数据集包含360 万个准确的二维人物姿态。本文的工作首先是在这个数据集上进行训练。然后利用数据集PRDDC 测试关键点模型的有效性。在数据集PRDDC上的关键点检测结果如图7所示。实验的主要过程是:首先利用Faster RCNN网络来检测目标人物,然后将检测到的人物传递给关键点模块,自动输出二维的人物关键点。然后利用这些二维人体关键点来传递服装特征。

Fig.7 2D human key points on dataset PRDDC图7 数据集PRDDC上2D人体关键点
(2)人体分割网络。本文评估了PRDDC 数据集上的人体语义分割。图8 给出了中间语义映射和对应的生成图像。进行人物分割实验的流程是:输入图像通过解析网络JPP-Net[50],输出相对应的分割结果。通过计算分割图中相应区域的中心点,包括头部(H)、上半身(U)、下半身(L)、右臂(RA),获得表示为热图关节的生成关节和对应的真实值,分别为左臂(LA)、右腿(RL)、左腿(LL)、右鞋(RS)和左鞋(LS)。利用联合结构损失加权分段损失来产生最终的结构损失函数,为了清楚地观察,在这里将九个热图组合在一个图中。同样地,上衣、外套和围巾合并为上半身,裤子和裙子合并为下半身,其余区域也可以通过相应的标签获得。通过分割网络,在语义上对查询图像和图像库中的人物进行分割,得到人物的衣服特征,为下一阶段中衣服特征的迁移做准备。

Fig.8 Results of human semantic parsing on dataset PRDDC图8 数据集PRDDC上的人类语义分割的结果
(3)衣服特征转移。本文对数据集PRDDC上的衣服特征转移进行了评估。在语义解析转换阶段,整合了查询图像P0、图库图像Pi、二维人物关键点ki、图像P0的语义解析结果生成一个粗略的结果,即服装分割符合期望的姿势。在服装转换生成阶段,利用所需要的服装图像中的服装信息,综合出与前一阶段服装分割一致的服装细节纹理。通过优化和改进,得到了从第一阶段转移到服装特征的最终结果。
通过转移衣服特征模块,将P0的衣服特征转移到P1,P2,…,Pn,以及生成新的子图像主要测试目标人物在一个固定的位置,主要包括正面、左侧和右侧的图像。衣服前后固定位置的特征转移结果如图9所示。

Fig.9 Results of transferring clothes feature图9 服装转移生成的结果
从图9的实验结果可以看出,两阶段服装特征转移可以达到预期的效果,包含的人物特征更丰富。例如,该人的面部和衣服特征的更多细节将转移到生成的结果中,可以为人物和衣服生成正确的颜色和纹理。
3.6 人员匹配模块的评价
通过对服装特征迁移模块与非迁移模块的比较,验证了新模型在子数据集上的有效性。人匹配过程中使用的在线实例匹配函数(OIM)[35]。在图库图像中,有标记身份的人和未标记身份的人用不同的颜色标记。使用一个循环队列来存储有标记身份人的信息,称为LUT的查找表;使用另外一个循环队列用于存储没有标记身份的人的信息,查找表是CQ。当进行查询匹配时,每个标记的ID将匹配所有存储的特性。当没有匹配成功时,它自动根据ID 更新LUT,将新来的目标行人特征推送到CQ,自动进入下一个循环,继续重复上述更新匹配的过程,直到识别出换衣服后的目标人物。
将PRDDC 数据集分为三个子数据集。第一个子数据集是目标人物固定姿势的类型,三个固定姿势是目标人物的前面、左边和右边。第二个子数据集的类型是在视频监控中多人处于任意位置的情况。第三个子数据集类型是一个人在视频监控中的任何姿势。在子数据集上,本文比较了不同Re-ID方法下CFTF 和non-CFTF 的识别精度。Re-ID 方法的比较主要包括CAMEL[51]、TJ-AIDL[52]、PTGAN[3]、SPGAN[14]、HHL[53]等。测试结果如表2所示。
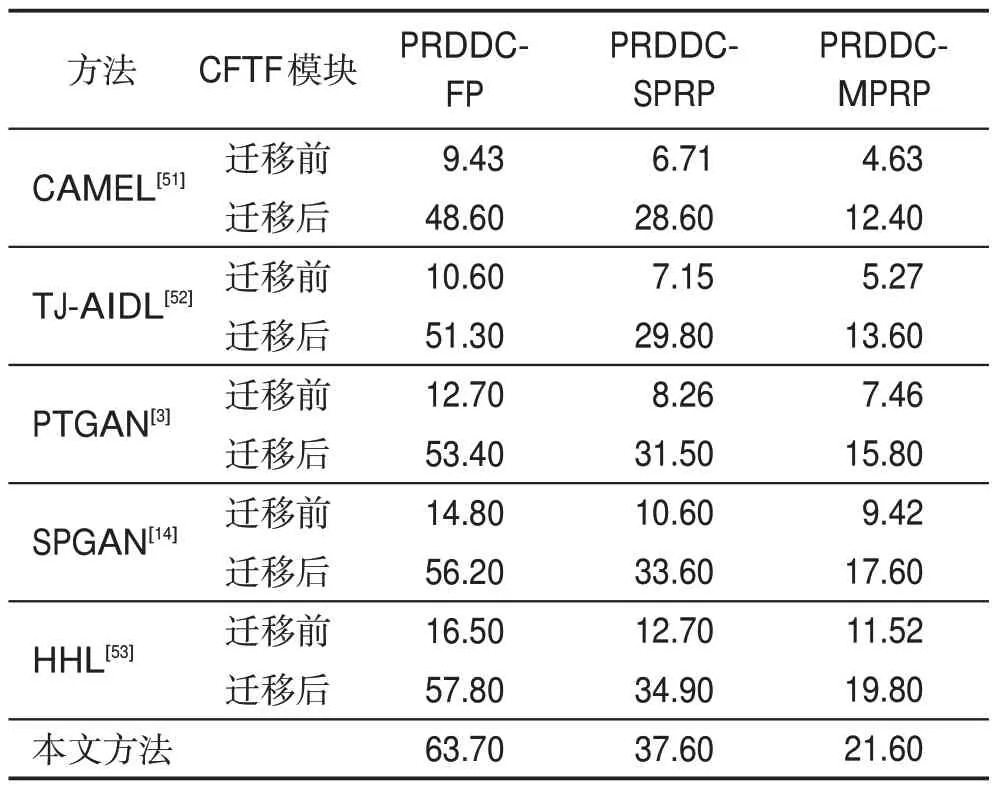
Table 2 Recognition precision on PRDDC dataset表2 PRDCC数据集上的识别精确度 %
本文所做的对比实验是将三个不同子数据集分别通过和不通过衣服特征迁移模块,再运用不同Re-ID方法进行匹配的过程,测试出这三种不同子数据集下Re-ID 的匹配精确度。从表2 中的测试结果可以看出,当子数据集通过衣服特征迁移模块时,其Re-ID 的匹配精确度远高于没有通过CFTF 模块的匹配精确度。例如,当单人固定姿势的子数据集通过衣服特征迁移模块时,运用HHL[53]的方法其Re-ID的匹配精确度为57.80%;当该数据集没有通过衣服特征迁移模块时,运用该方法其Re-ID 的精确度为16.50%。从表2中还可以看出,本文提出的算法在通过不同数据集PRDDC-FP、PRDDC-SPRP、PRDDCMPRP 时,其Re-ID 的匹配精确度分别为63.70%、37.60%和21.60%,都要优于现有其他算法。这些实验结果表明了衣服迁移有效消除了人物匹配过程中服装差异的影响,提高了Re-ID 算法的准确性,同时也体现出衣服特征在识别过程中的重要性以及验证了本文提出模型的有效性。
4 结束语
本文提出了在Re-ID 任务中查询图像和图库图像中出现不同服装的人的问题,该问题在实际应用中是可行的。为了支持这一研究方向,收集了大规模的人衣迁移数据集PRDDC。此外,本文还提出了一种新的模型,将衣服的特征从一个人的图像转移到另一个人的图像,以实现人的匹配。实验结果表明,与没有衣服特征转移模块的算法相比,包含特征转移模块的算法在识别率上有明显的提高。本文尝试解决Re-ID任务中的换衣问题,在以后的工作中将对更复杂的表情变化案例进行研究。
