
嵌入自注意力机制的美学特征图像生成方法
2021-09-13 01:02:24邹亚莉
计算机与生活 2021年9期
马 力,邹亚莉
西安邮电大学 计算机学院,西安710061
随着互联网技术的发展,图像在社交媒体平台上被广泛地传播与分享,但因拍摄时光线、设备等因素影响,获取的图像质量不高、美观度低,不能满足人们的审美需求,影响欣赏者愉快的视觉效果。图像美化对普通用户而言,学习工具使用方法和了解图像美化专业知识的过程复杂,人们希望通过计算机模拟人类审美思维,辅助人类完成图像美化[1]。因此,在计算机科学范畴提出了可计算图像美学(computational image aesthetics)[2-3]概念,它是指让计算机模拟人类视觉及审美思维对图像进行美学决策,建立计算机与视觉艺术作品之间的桥梁,其研究结果可应用到图像美学质量评估[4-5]、艺术作品鉴赏和图像美学分类[6]等方面。
面对海量图像数据美观感不足,不能满足人们对于美学的需求的问题,计算机为图像数据增加美观度仍具有很大的挑战;并因与美学相关的美学数据集相当稀缺,也为可计算美学的研究带来了难题。那么研究如何利用先进的图像生成技术去生成具有美学特征的美学图像,具有十分重要的研究意义。自Goodfellow 等[7]在2014 年提出生成对抗网络(generative adversarial networks,GAN)后,相关研究十分火热,其应用领域有图像生成[8]、图像风格转换[9-10]、图像修复[11-12]、目标检测[13]和图像超分辨率[14-15]等。由于生成对抗网络训练不稳定,容易发生模型坍塌,WGAN(Wasserstein GAN)[16]抛弃了传统GAN 的JS散度(Jensen-Shannon 散度)[17]定义,采用EM 距离(Earth Mover 距离)计算两个分布的距离,解决GAN模型坍塌问题。谱归一化生成对抗网络(spectrally normalized GANs,SN-GANs)[18]将谱归一化引入鉴别器,提高了模型训练稳定性。进化生成对抗网络(evolutionary GAN,E-GAN)[19],引入进化学习的生成模型,提升了GAN 训练的稳定性得到更好的生成效果,并解决模式崩溃问题。基于自我注意力生成对抗网络(self-attention GAN,SAGAN)[20]将自注意力机制引入生成器和判别器中,图像生成的全局性和图像的几何结构上更加合理,提升了GAN图像生成能力。
现有图像生成模型生成图像质量较好,但生成的图像结构单一,缺乏美感,鉴于此,本文以进化生成对抗网络为基础模型,提出嵌入自注意力机制的美学特征图像生成方法(aesthetic feature image generation method embedded with self-attention mechanism,ASAEGAN),所提方法创新之处主要为以下两点:
(1)将图像美学评价模型与进化生成对抗网络模型相结合,通过图像美学评价模型设计相应的美学损失,在生成器中引入美学损失,从美学角度优化生成模型;通过VGG网络特征提取构建内容损失,生成器中引入内容损失,确保生成图像和原图像在内容上具有一致性,同时采用Charbonnier 损失代替L1损失,提高网络性能和模型收敛速度,具有更高的鲁棒性。
(2)生成网络和判别网络中分别引入自我注意力模块,解决生成模型图像远距离空间局部细节不清晰问题和训练稳定性,得到高清晰度、细节特征更丰富的图像,同时在生成网络中引入密集卷积块,加强特征传播,缓解梯度消失问题。
1 相关工作
1.1 图像美学
美学是以艺术为主要对象,研究美、丑等审美范畴和人的审美意识、美感经验,以及美的创造、发展及其规律的科学[21]。美学的目的是获得美感,人们在看到一幅图像时,会根据图像的光影、清晰度、色彩、内容、构图、亮度、对比度、趣味等多个方面判断图像的美感如何,进而产生愉悦的美感。当两幅同样的图像放在一起,图像美感的高低与清晰度有一定的关系,可以发现图像清晰度越高,细节越丰富,给人越多的愉悦美感。色彩是美学特征研究中必不可少的一类特征,图像的美学分数高低一定程度上取决于图像色彩分布是否和谐,图像色彩分布和谐,则图像美感越高。构图特征毋庸置疑也是美学特征中不可或缺的,对于自然景观图像,一般将主体景观作为图像美感主要表现区域,非自然景观一般将拍摄对象为支点,构建整幅图像的布局结构,达到提高图像美感的目的。亮度特征对于图像美感的高低也有一定程度的影响,一幅图像如果色彩、构图、清晰度等美学特征都有,而亮度较低也会使整幅图像美感降低,因此,图像中的美学特征是相辅相成,缺一不可,都对图像美感高低有着直接影响。
1.2 图像美学评价模型
人类对于图像美感的评价存在多种形式,例如“美”与“丑”,给出数值评分、语言评分等。图像美学质量评价除了具备一定的客观性之外,还具有很强的主观性,因此图像是否具有美感,可以通过主观和客观两种方式进行判断。从主观上来说,评价一幅图像是否具有美感是具有主观性的,每个人的审美观不同,对同一幅图像的评价结果不同。因而,评价一幅图像美感高低,完全依靠人的主观评价是不够的,借助计算机进行图像美观度评价成为了一个研究课题,也就是从另一方面来对图像进行客观评价。图像的美学评价[22-23]是指从美学质量的角度对所获得的图像进行精确而客观的评价,仅仅依靠人类自己所拥有的审美能力对图像做出相应的美学评价不够专业;Datta 等人[24]设计了56 维的美学特征去理解图片,增加了图像中的特征提取项,实现了图像高低美感分类和图像美学分数的自动评估;Dhar等人[25]从布局、内容和光照的角度学习图像的高层可描述性,以达到预测输入图片的兴趣性,进而提高图像美学评判的准确性。Kong等人[26]设计的图像美学评价模型,提出了一种新的卷积神经网络(convolutional neural networks,CNN)结构,基于8 种不同的美学因素实现二分类评价,通过提取图片内容特征以及自定义的属性标签特征来辅助判断图像美观度,评估美学质量。本文采用的是Talebi 等人[27]设计的图像美学评价模型NIMA(neural image assessment),介绍了一种新颖的方法来预测图像的技术和美学质量。该模型提出通过CNN 预测图像质量得分的分布,网络用ImageNet预训练权重,在训练数据集中,每张图像都与人类直方图相连接,将分数的分布作为直方图来预测。同时根据人类对图像的评价概率分布,计算出EMD-basedloss,进行反向传播。最终一张图片的综合评价则是由分数概率分布的均值与标准差来决定的,均值代表了这张图片的质量分数,标准差代表了非常规程度,即对图像进行1~10分的打分,并直接比较同一主题的图像。
1.3 进化生成对抗网络
EGAN设计了一个判别器D和生成器“种群”之间的对抗框架。生成器G不再以个体的形式存在,而是以“种群”的形态与判别器D进行对抗。从演化的角度,判别器D可以被视为演化过程中不断变化的环境,根据优胜劣汰的原则,生成器“种群”中表现不好的个体被不断淘汰,只有表现优异的个体才会被保留以进一步地适应环境与判别器D进行对抗。这样,每次更新产生的生成器G都将是当下所有策略中最优的选项,不必维持训练过程中D和G的平衡,避免了梯度消失、模式崩溃等一系列训练不稳定的问题。EGAN的原理示意图如图1所示。
从图中可以看出,每一次训练对抗过程生成器的演化过程分别是变异、评估和选择三个步骤。
(1)变异其实在对抗过程中,为了可以持续更新并得到合适的G,首先需要对现有的生成器“种群”进行变异操作,并产生新的后代。由于不同的损失函数具有不同的功能,采用不同的变异操作得到不同的后代,在对抗过程中三种变异操作被采纳,分别用到三种不同的目标函数:
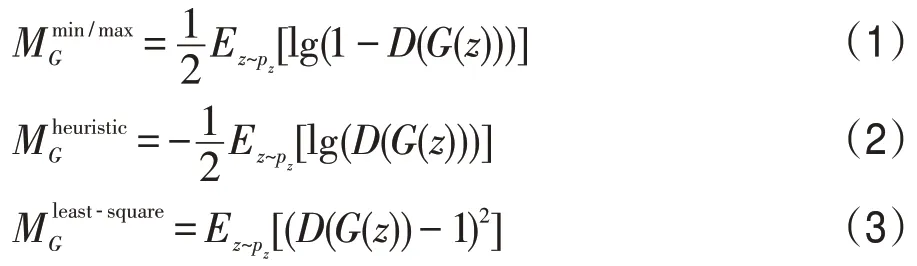
(2)对变异后得到的新子代,先对其生成性能进行评估,并量化为相应的适应分数F=Fq+γFd,其中质量分数Fq=Ez[D(G(z))]衡量了生成器在变异过程中生成的子代质量,多样性分数Fd=-lg||∇D-Ex[lgD(x)]-Ez[lg(1-D(G(z)))]||衡量了根据候选生成器,再次更新D时所产生梯度的大小。
(3)在衡量所有子代的生成性能后,根据优胜劣汰的原则择优选取更新过后的G进行新一轮训练。
1.4 DenseNet
随着网络深度的加深,梯度消失问题会愈加严重,因此提出了密集网络(dense convolutional network,DenseNet)[28]解决梯度消失问题。DenseNet具有密集连接机制,每一层都会接受其前面所有层作为其额外的输入,直接连接来自不同层的特征图,通过特征在通道上的连接实现特征重用,提升效率。DenseNet网络结构如图2所示,x0是输入,H1的输入是x0,H2的输入是x0和x1,主要由DenseBlock(密集块)和Transition(过渡层)组成。在密集块中,每层特征图大小一致,密集块中的非线性组合函数由BN(batch normalization)、ReLU、Conv(convolution)组成。由于密集连接的方式,DenseNet提升了梯度的反向传播,使得网络更容易训练,参数量变小且计算更高效,缓解了梯度消失问题,在数据集较小时可以起到减少过拟合的作用。
1.5 自我注意力生成对抗网络
传统的生成对抗网络都使用了卷积操作,但是在处理长距离依赖时,使用小的卷积核很难发现图像中的依赖关系,使用大的卷积核就丧失了卷积网络参数与计算的效率,导致卷积的效率很低。SAGAN模型的整体框架与传统的GAN是一样的,都是由一个生成器和一个判别器组成,不同之处是SAGAN 在生成器和判别器网络结构内部分别加入了自我注意力模块(self-attention mechanism)[29],对卷积结构进行补充,有助于对图像区域中长距离、多层次的依赖关系进行建模,生成图像时利用所有位置的特征来帮助生成图片的某一细节,使生成的图片更加逼真。SAGAN 中的自我注意力模块的结构图如图3所示。
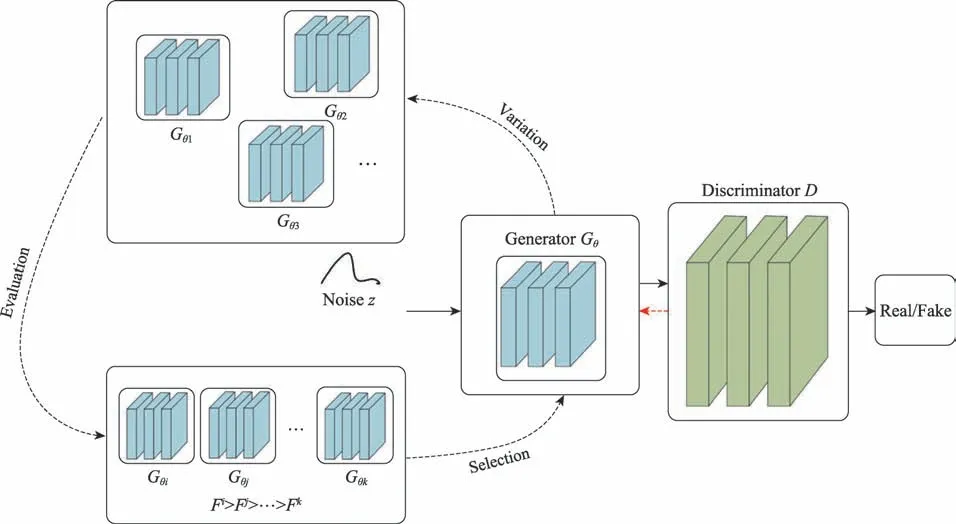
Fig.1 EGAN model structure framework图1 EGAN模型结构框架
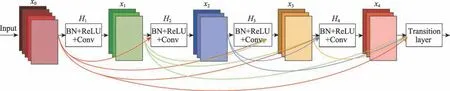
Fig.2 DenseNet network structure图2 DenseNet网络结构
Fig.3 Self-attention mechanism module diagram图3 自注意力机制模块图
图3 中⊗表示矩阵乘法,每一行都用softmax 归一化。对于某一个卷积层之后输出的特征图(图3中的x),分别经过三个1×1 卷积结构的分支f(x)、g(x)和h(x),特征图的尺寸均不变,f(x)和g(x)改变了通道数,h(x)的输出保持通道数也不变;将f(x)的输出转置后和g(x)的输出矩阵相乘,经过softmax 归一化得到一个注意力特征图;将注意力特征图与h(x)的输出进行矩阵相乘,得到一个特征图,经过一个1×1 的卷积结构,得到此时的特征图(图3 中的o);最终输出的特征图为yi=γOi+xi,yi表示全局空间和局部信息的整合,γ参数初始值为0,目的是让模型从领域信息学起,逐渐将权重分配到其他远距离特征细节上。该网络的损失函数在最小化对抗性损失的前提下进行交替训练,G和D交替训练的表达式为:
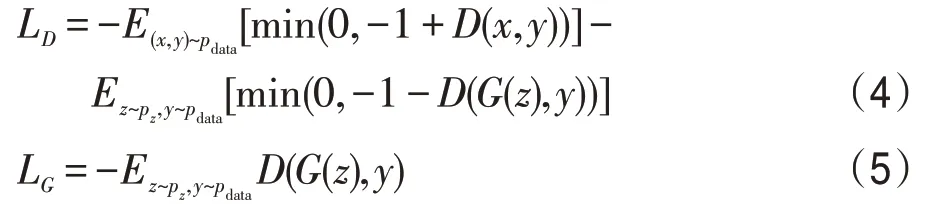
1.6 图像美学与生成对抗网络
关于图像美学研究领域,较多学者的研究内容与图像美学评价有关,将图像美学与生成对抗网络相结合的研究内容较少。徐天宇等[30]以文本生成图像GAN 模型-StackGAN++为基础,将图像美学评价模型融入StackGAN++的生成模型中,选定美观度评判模型构造美学损失,通过增加美学损失的方式改造生成器,从而以美学角度优化生成模型,引导模型生成美观度更高的结果,实验结果证明生成图像在色彩对比度、整体色调背景虚化简单化等方面均有一定优势,图像美学分数得到了有效的提高,并且IS(inception score)也有所提高。受到此方法的启发,鉴于人们对于审美的需求越来越高,并且美学数据集相当稀缺,现有生成模型存在生成图像纹理特征不明显、美观感不足等问题,提出嵌入注意力的美学特征图像生成方法。针对传统生成模型的生成图像结构单一、清晰度低、色彩感不足、缺乏美感等问题,通过图像美学评价模型定义美学损失,使得模型训练过程中受到美学控制因素影响,间接提高生成图像的美观感,从而扩充图像美学数据集;同时将内容损失加入生成器,保证生成图像与真实图像语义内容上的一致性;生成器和判别器中加入自注意力机制,并在生成器网络引入自注意力模块之前,加入了DenseNet中的密集块,充分提取深层特征,减少网络中的参数量,缓解梯度消失问题,模型高效地获取更多特征内部的全局依赖关系,提高生成图像的质量和清晰度,增加图像细节特征,并且图像的纹理细节更加明显,解决现有生成模型生成图像纹理特征不明显、清晰度低、局部细节不清晰等问题。
2 嵌入自注意力机制的美学特征图像生成方法
2.1 模型设计思想
现有图像生成模型所生成的图像在图像美观感方面存在不足,影响图像美观感的因素有光影、色彩、配色、构图和模糊等,如何在图像生成过程中为图像增加较多的美学特征具有一定难度。为引导现有的图像生成模型去生成美观度较高的图像,本文的设计思想是:以进化生成对抗网络(EGAN)作为图像生成模型,针对现有生成模型生成图像色彩感不足、亮度低、对比感不鲜明等问题,根据图像美学评价模型的测度,在生成器中引入美学损失,以美学角度使得生成模型朝着丰富图像色彩、提高颜色对比感的方向生成图像,进而使得生成图像具有一定的美学特征;为保证生成图像保留真实图像的语义内容,将真实图像和生成图像输入到VGG 网络构建内容损失;将美学损失、内容损失和进化生成对抗网络的对抗损失以加权形式组合,引导与优化生成器生成具有美学特征的图像。针对生成图像的清晰度低、纹理模糊等问题,在生成网络和判别网络中,分别引入自注意力机制,并在生成网络中引入密集卷积块,充分提取图像深层特征,使得模型可以高效地获取更多特征内部的全局依赖关系,提高生成图像的质量和清晰度,图像纹理特征丰富,并且图像的纹理细节更加明显;另一方面由于密集卷积块的引入,可以减少网络训练参数量,缓解网络训练中梯度消失问题。
基于上述处理思想,本文设计了嵌入自注意力机制的美学特征图像生成方法(ASA-EGAN),其逻辑框图如图4所示。
整个网络模型采用对抗的方式进行训练,两个网络交替训练,生成器通过训练得到生成图像,判别器负责判断输入的图像是真实图像还是生成图像。训练开始首先固定判别器开始训练生成器,将输入图像和随机噪声z送入生成器,生成器得到生成图像,随后将生成图像送入美学评分模型,根据图像美学评价模型对生成图像的美学评价分数设计美学损失Laes,进而以美学角度优化生成模型;再将生成图像与真实图像输入到VGG网络中,通过VGG网络对生成图像与真实图像做高级特征映射,构建内容损失Lcon,确保生成图像与真实图像在语义内容上保持一致性。最后将美学损失、内容损失和对抗损失以加权的形式组合,引导生成模型生成具有美学特征的美学图像,增加图像美学特征,直到生成的样本达到想要的效果。固定生成器开始训练判别器,生成图像、真实图像作为判别器的输入,判别器判断输入图像的真假。
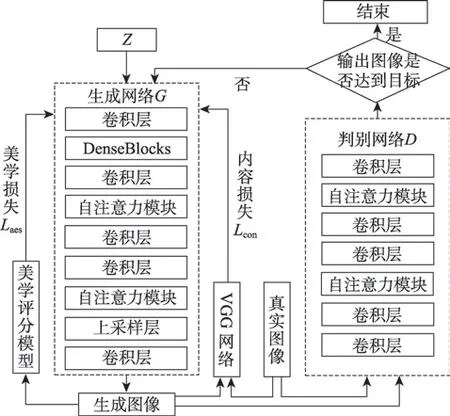
Fig.4 ASA-EGAN framework图4 ASA-EGAN逻辑框图
2.2 生成器模型
生成器主要任务是进行特征提取,在生成网络中引入密集块,由于在每一个密集块中,任意两层之间都是直接连接,可以充分提取深层特征,加强了特征传播,极大地减少了网络中的参数量,缓解了梯度消失问题。生成器中加入自注意力机制的目的是促使生成模型在生成图像过程中,生成模型高效地获取特征内部的全局依赖关系,提高生成图像的质量和清晰度,从而图像的纹理细节更加明显,从图像纹理、亮度、清晰度等方面提升图像美感。
进化生成对抗网络(EGAN)生成器的生成网络变异之后的子代的结构基本一致,在此只介绍G1 的结构如图5所示。
生成器执行流程:设定批处理样本个数为64,输入噪声维度为100,初始噪声样本像素为1×1,这三个参数组成四维张量(64,100,1,1),经过一个全连接层再经过卷积核为4×4,步长为2的卷积层,数据大小为(64,512,4,4);之后通过三个密集块进行深层特征提取保持网络输出维度不变,再经过一个卷积层变为(64,256,8,8);接着进行第一次self-attention 运算,得到自注意力特征图(64,256,64),之后经过两层卷积层变为(64,64,32,32),进行第二次self-attention运算,得到自注意力特征图(64,64,1 024);最后经过上采样层和一个卷积核为3×3,步长为2的卷积层变为(64,32,64,64),生成器输出图像的大小为64×64。
2.3 判别器模型
判别器加入自注意力机制的目的是利用远距离的细节约束当前合成图像的细节,使得生成图像在内容上更加真实,内容特征更加丰富,从图像内容构图方面提高图像美感,进而提高图像美学分数。
判别器的主要功能是与生成器不断地对抗学习,提升自己辨别真假图像的能力,判断输入的图像是来自真实图像还是生成图像。所提方法中,判别网络由一系列的卷积层和注意力模块构成,网络结构如图6所示。
判别器执行流程:判别网络设定参数每批次大小为64,初始维度为3,输入图像大小为64×64;经过两层卷积层,图像通道大小不断增加,尺寸逐渐减小,由输入数据(64,3,64,64)变为(64,128,16,16);之后经过self-attention 层,得到注意力特征图为(64,128,256),经过两层卷积层变为(64,512,4,4),再经过一个self-attention 层,得到注意力特征图为(64,512,16);最后经过一个卷积层变为(64,8 192,1,1),判别器输出一个长度为8 192的向量。
2.4 损失函数设计
2.4.1 生成器损失函数
为使生成图像具有一定的美学特征,由图像美学评价模型得到图像美学分数,定义美学损失Laes。生成器中引入美学损失Laes辅助生成模型训练过程中受美学因素影响,从而以美学角度优化生成模型,间接提高图像美观感。为了去掉冗余信息特征,采用L1范数实现特征稀疏,加快收敛速度,损失函数定义如下:
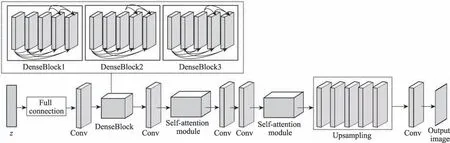
Fig.5 Generator network structure图5 生成器网络结构
Fig.6 Discriminator network structure图6 判别器网络结构
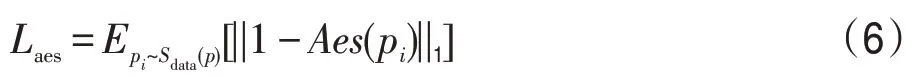
Aes函数表示使用图像美学评价模型计算生成结果pi的美学分数。在计算美学损失时,对图像美学评价模型返回的美学分数进行判断,该损失实际计算了生成器生成图像的美学分数与1之间的差距,代表生成图像美学质量的提升。
为保证生成图像和真实图像在内容上具有一致性,使得生成图像不会丢失过多真实图像的特征,将真实图像和生成的美学图像输入到VGG网络中提取图像特征。在VGG网络的高级特征映射做内容损失Lcon,同时采用Charbonnierloss[31]可以提高网络性能,提高模型收敛速度,具有更高的鲁棒性。内容损失函数定义如下:
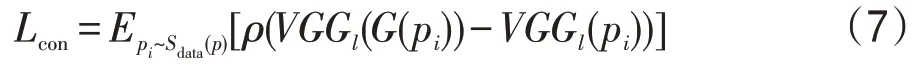
其中,ρ(x)=是Charbonnier 惩罚函数,δ为超参。
生成器除自身的对抗损失外,由于在生成器中引入了自注意力机制,还需要将原始的自我注意生成对抗网络中的生成器目标函数引入本文生成模型的生成器的对抗损失中,以保证生成器高效地获取特征内部的全局依赖关系,提高生成图像的质量和清晰度,丰富图像纹理特征,损失函数定义如下:
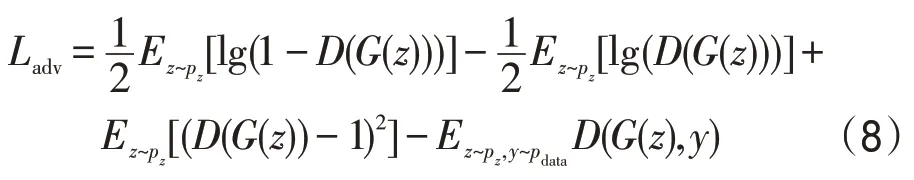
鉴于在生成器中引入了美学损失、内容损失,因此生成器的损失函数定义为:

其中,α、β为平衡不同损失项的权重系数,美学损失和内容损失的作用是引导G生成美观度更高的美学图像,并确保生成图像与真实图像语义内容的一致性。而对抗损失是控制整个训练过程以及生成结果,保证生成器能够生成图像美学分数较高的关键。α、β的取值应该保证在训练过程中美学损失、内容损失起到的调控作用不会超过对抗损失前提下对生成结果的图像美感产生影响。经实验验证,表1为α、β为不同取值时,生成图像的图像美学分数。可以看出,当0.5<α<1.0,0.5<β<1.0 时,生成图像的图像美学分数较低;当α、β值在0~0.5时,图像美学分数较高,生成图像不仅保留的美学特征较多,在语义内容上与真实图像也保持一致;当α、β的取值分别为0.2、0.1时,图像美学分数最高,并且生成图像效果最好。因此,实验时α、β取值分别为0.2、0.1。
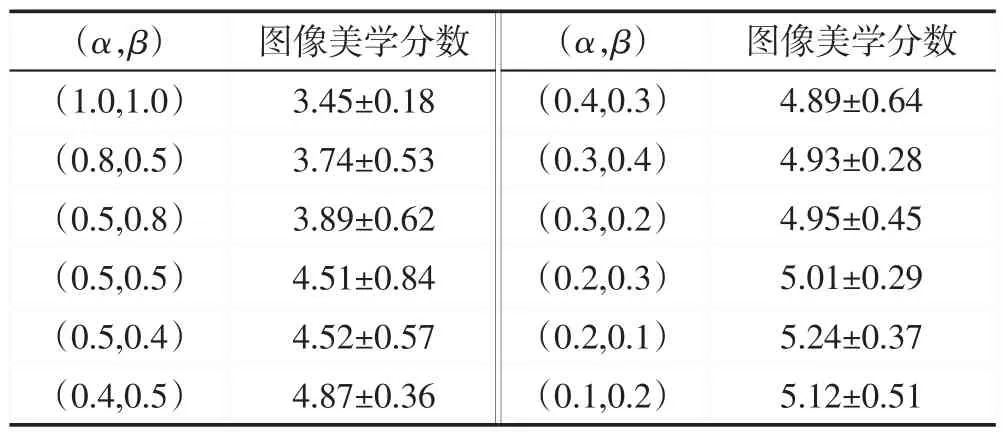
Table 1 Image aesthetic scores corresponding to different values of α and β表1 α、β不同取值对应的图像美学分数值
2.4.2 判别器损失函数
判别器根据真实样本x以及进化后生成器生成的样本y进行更新,从而保证判别网络的训练不落后于生成网络。同时给生成器不断提供自适应的损失,以推动其种群进化,以产生更好的结果。并在判别器中引入自注意力机制,利用远距离的细节来约束当前合成图像的细节,使得生成图像细节特征丰富,内容真实,判别器损失定义如下:

3 实验
实验在Cifar10 数据集和香港中文大学图像质量CUHKPQ(Chinese University of Hong Kong-Photo Quality)数据集上进行;在Intel®Xeon®CPUE5-2620v4@2.10 GHz 处理器,1 块NVIDIATeslaP100 GPU显卡,TensorFlow环境上进行。
3.1 Cifar10数据集
3.1.1 数据集预处理
Cifar10 是一个包含60 000 张图片的数据集,其中每张照片为32×32 的彩色照片,一共包含10 类,每一类包含6 000 张图片。其中50 000 张图片作为训练集,10 000张图片作为测试集。
3.1.2 参数设置
判别网络和生成网络初始学习率均为0.000 2,迭代训练60 个epoch,每个周期的迭代次数为8 000次,批量大小为64。实验中生成器和判别器的损失函数中的权重系数分别设置为α=0.2,β=0.1。训练过程使用Adam 优化算法,其中参数beta1 设置为0.5,beta2 设置为0.9。
3.1.3 实验结果与分析
所提出的ASA-EGAN 模型在Cifar10 数据集上生成效果如图7所示。

Fig.7 Cifar10 generated sample图7 Cifar10生成样本
图7 是模型ASA-EGAN 生成的样本,生成的样本细节特征丰富,物体形状和背景清晰,图像具有鲜明的色彩,且色彩分布舒适。

Fig.8 Comparison of samples generated by Cifar10图8 Cifar10生成样本对比
图8为ASA-EGAN模型与其他生成模型经过60次迭代以后生成的样本图像对比,主要包括DCGAN(deep convolutional generative adversarial networks)、WGAN、EGAN、ASA-EGAN。从图中可以看出,DCGAN 模型生成的样本图像模糊,特征不明显;WGAN 模型生成的样本相比于EGAN,图像较为清晰,图像质量优于EGAN;EGAN 模型生成的样本相比于DCGAN,EGAN 生成的样本图像清晰,特征明显,色彩感较为鲜明;而提出的ASA-EGAN模型生成的样本图像不仅图像清晰,细节特征更明显,而且具有更鲜明的色彩,给人更好的视觉效果,图像质量优于其他模型所生成的样本图像。
为了验证ASA-EGAN模型对于图像分类性能是否有所提高,将ASA-EGAN模型所生成的Cifar10生成样本进行图像分类实验。表2为EGAN、DCGAN、WGAN、ASA-EGAN 模型的Cifar10 生成样本图像分类结果。可以看出ASA-EGAN生成样本的分类准确率均高于其他模型,验证了本文方法对于提高图像分类效果是有效的。
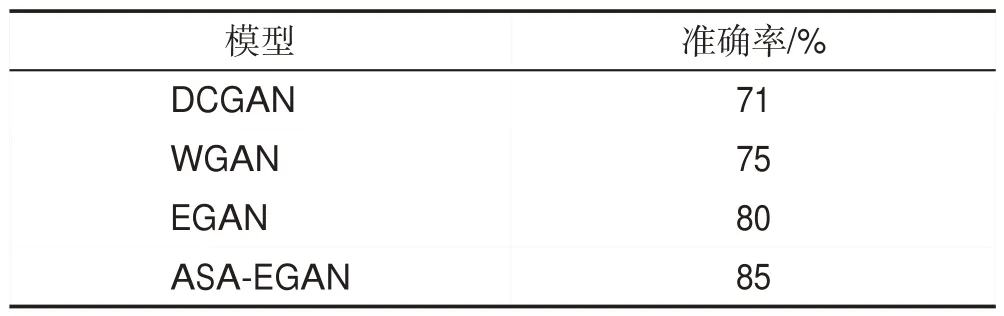
Table 2 Classification results of generated image by different models on Cifar10表2 Cifar10不同模型生成图像分类结果
3.2 CUHKPQ数据集
CUHKPQ 是一个大规模图像数据集,该数据集包含28 410 张图像,分为高美学质量和低美学质量两个分类,包含7 个场景类别,分别是动物、人类、建筑、植物、风景、静态和夜晚。实验将输入图像调整为128×128 像素大小的图像并缩小至64×64 像素,将64×64 像素的图像作为模型输入。
所提出的ASA-EGAN 模型及EGAN 模型在CUHKPQ数据集上生成效果如图9所示。
为验证内容损失的性能,在同等条件下训练了基于EGAN+美学损失生成模型,对应图10。
从图9、图10可看出,ASA-EGAN所生成图像的纹理特征丰富,色彩分布舒适,视觉愉悦感强。未加入内容损失生成图像与ASA-EGAN模型的生成图像相比,较真实图像缺乏内容真实性。

Fig.9 CUHKPQ generation sample图9 CUHKPQ生成样本

Fig.10 EGAN+aesthetic loss generation sample图10 EGAN+美学损失生成样本

Fig.11 Comparison of CUHKPQ generation sample图11 CUHKPQ生成样本对比
图11为ASA-EGAN模型与其他生成模型生成的样本图像对比,主要包括DCGAN、WGAN和EGAN。从图中可以看出,ASA-EGAN 模型生成的样本相比于其他三种生成模型,生成的图像清晰,细节特征更明显,而且具有更鲜明的色彩,给人更好的视觉效果。
图12为CUHKPQ在EGAN、ASA-EGAN模型上的生成样本对比单图。ASA-EGAN模型生成图像从色彩、对比度、亮度、清晰度等方面都优于EGAN 模型,并且纹理特征丰富、内容真实性强。以客观评价指标衡量图像美观度,图中下方数值为该图的图像美学分数。ASA-EGAN模型生成样本的图像美学分数均高于EGAN 模型生成样本,因此从主观和客观两方面来讲,ASA-EGAN模型生成样本均优于EGAN模型,验证了所提方法的有效性。

Fig.12 Comparison of single image of CUHKPQ generated sample图12 CUHKPQ生成样本对比单图
3.3 评价指标
为了定量地评估生成的图像质量,采用弗雷歇距离(Fréchet inception distance,FID)评估标准衡量生成样本的质量。用弗雷歇距离来衡量真实图像和生成图像的相似程度,FID 值越小,说明模型效果越好。表3展示了ASA-EGAN与其他生成模型相比较的最佳FID值。
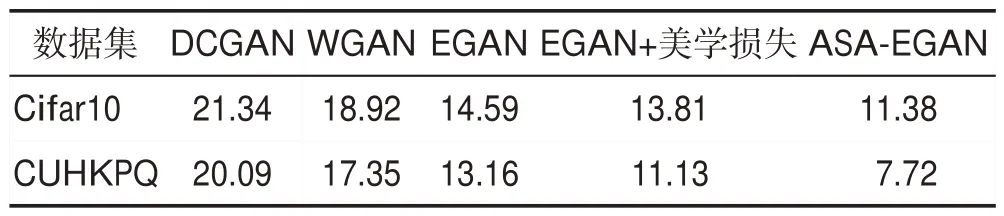
Table 3 Comparison of FID values of different models表3 不同模型FID值对比
从表3 可看出,Cifar10、CUHKPQ 数据集中,ASA-EGAN所生成的图像FID值相比EGAN提高了3.21和5.44,说明ASA-EGAN生成图像细节清晰,纹理特征丰富,具有多样性、质量高等特点。
同时为衡量ASA-EGAN所生成美学图像的美学质量,采用美学评估模型NIMA对生成图像进行美学评分,不同数据集最高评分结果如表4所示。
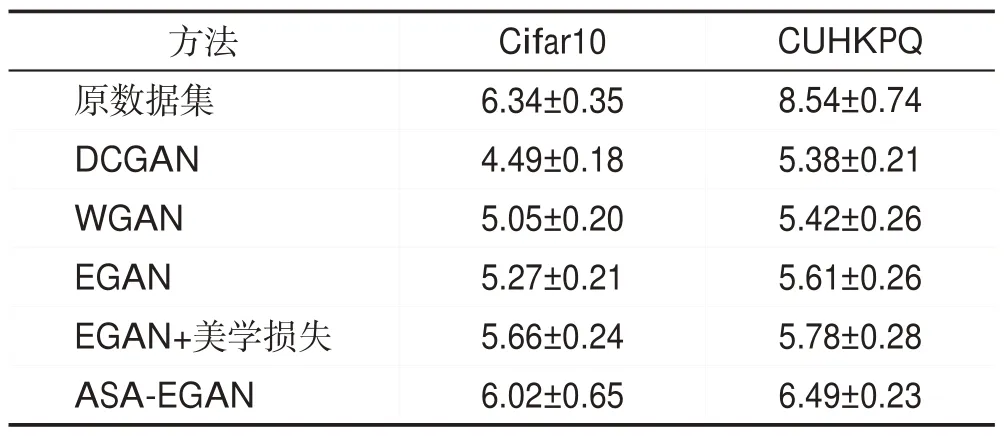
Table 4 Aesthetic evaluation scores of different models表4 不同模型美学评价分数
从表4 中可以看到,ASA-EGAN 在Cifar10、CUHKPQ数据集上所生成图像的美学评分比EGAN分别提高了0.75和0.88,再一次验证了所提方法所生成的美学图像结果在色彩对比度、整体色调等方面均有一定优势,反映了其美观评价相比其他模型有所提升。
4 结束语
针对现有图像生成模型所生成的图像大多数缺乏美观感,难以满足人们对于美学的需求这一问题,提出了一种嵌入自注意力机制的美学特征图像生成方法ASA-EGAN。通过在网络中引入密集块,充分提取图像特征,减少参数量,缓解梯度消失问题;生成器和判别器加入自注意力机制,保证生成图像具有丰富的细节特征,清晰度高;设计美学损失辅助生成模型得到具有一定美学特征的图像;最后加入内容损失确保生成图像不会丢失真实图像的内容。实验在Cifar10、CUHKPQ 数据集上验证了本文方法的有效性和可行性,并采用弗雷歇距离值和图像美学分数衡量生成图像,对所提方法与其他方法进行对比,证明了本文方法生成的样本细节特征丰富,质量高,美观度高等优异表现。但该方法借助图像美学评价模型对生成图像进行整体美学评价,未来考虑从构图、阴影、色彩和谐性等美学属性方面进一步改善生成图像美观感;并且在美学损失、内容损失的权重系数选择上需要不断地尝试才能得到合适的值,在以后的研究中会探索公式化计算方法。
