
融合奖惩学习策略的动态分级蚁群算法
2021-09-13 01:02:18莫亚东游晓明
计算机与生活 2021年9期
莫亚东,游晓明+,刘 升
1.上海工程技术大学 电子电气学院,上海201620
2.上海工程技术大学 管理学院,上海201620
旅行商问题(traveling salesman problem,TSP)是经典的组合优化问题。该问题主要描述为:一位旅行商人从任意起始城市出发,由一个城市移动到另一城市,要求能够不重复遍历整个国家的所有城市最终回到起始出发点,且构成的回路之和最小,即构成最小哈密顿回路。目前解决TSP问题有很多方法[1-3],研究表明蚁群算法由于其自身正反馈性及分布式运行等优点是最有效的方法之一。
蚁群算法[4](ant colony optimization,ACO)是意大利学者Dorigo等人受自然界中蚂蚁觅食的启发而提出的群智能算法,主要思想是蚂蚁能够利用自身信息素更新机制有效地往返食物源与巢穴之间。其算法提出之后引起了人们的很大关注,并开启了探讨蚁群算法的性能应用等方面的研究。针对传统蚁群算法收敛速度慢,求解精度不高等缺点,Dorigo 等人[5]又提出了蚁群系统(ant colony system,ACS),它通过每次迭代中对最优蚂蚁所生成的路径上的信息素进行更新,加强了最优信息的正反馈作用,进一步提高了算法的收敛速度,但由于对最优解的强化,易使算法陷入局部最优。Stutzle 等人[6]提出了最大-最小蚂蚁系统(max-min ant system,MMAS),该方式将信息素的取值设定在固定区间内,限制了信息素的累加及挥发,在一定程度上避免了算法停滞,提高了种群多样性,但当解的分布较为分散时,算法的收敛速度将会降低。后来众多学者结合自身领域需求对该算法进行了更进一步的改进与研究,例如,在算法应用方面,利用蚁群算法求解路径规划[7-10]、密集型网络及云计算虚拟机布局[11-12]等问题;在算法改进方面,提出了融合其他智能算法优化蚁群算法[13-14]、优化算法参数及改进路径构建规则[15-16]等改进方式。文献[17]在解决TSP 问题中提出了一种面向对象的多角色蚁群算法,使得不同角色的蚁群针对不同的城市执行相应的搜索策略,实验表明该方法能够改善解的精度,但其求解过程较为复杂,不易实现。文献[18]提出了一种改进信息素二次更新局部优化的蚁群算法,通过对贡献度较大的路径进行二次信息素更新,加速了算法收敛,但过快的收敛速度使得算法易陷入局部最优。文献[19]利用自然界中“优胜劣汰”的进化策略,增加满足进化的路径上信息素浓度,提高收敛速度,同时采用随机进化因子以增强算法跳出局部最优能力,但文中只是应对小规模TSP 问题,未能对大规模问题进行测试,其求解TSP 问题规模有限。文献[20]结合狼群算法引入独狼视角机制及独狼逃跑策略,使得蚁群具有较好的收敛速度与高效的全局寻优能力,存在的问题为该改进策略在复杂环境下求解精度及其稳定性有待进一步提高。
针对大规模TSP问题,本文提出融合奖惩学习策略的动态分级蚁群算法(dynamic hierarchical ant colony system based on reward and punishment learning strategy,DHL-ACS)。首先将蚁群动态划分为帝国蚁、殖民蚁及国王蚁。帝国蚁与殖民蚁执行局部信息素更新,国王蚁执行全局信息素更新,其中帝国蚁执行较大权重系数,负责对较优解的开发保证算法的收敛速度,殖民蚁执行较小权重系数,负责对次优解的探索提高算法多样性,并且在每轮迭代对殖民蚁与帝国蚁的解进行评判,利用二者交换优质解的方式提高解的精度。同时引入改进的学习策略,将每只帝国蚁按照自身国力值分配得到不同的殖民蚁,通过奖励每只帝国蚁及其附属殖民蚁的公共路径,实现较优解的同化作用,提高算法的收敛速度。进一步当算法停滞时,在国王蚁中引入反馈算子,缩短当前路径与次优路径的信息素的差距,增强算法跳出局部最优的能力。实验结果表明,本文提出的改进算法比传统蚁群算法在TSP问题上取得更好的实验结果,有效改善了算法全局搜索能力与收敛速度的矛盾。
1 相关工作
1.1 蚁群算法(ACS)工作原理
1.1.1 路径构建规则
ACS 较AS(ant system)的不同之处在于ACS 采用了全局更新与局部更新两种更新方式,并且在节点概率选择过程中引入伪随机概率状态转移规则,其公式如式(1)所示:
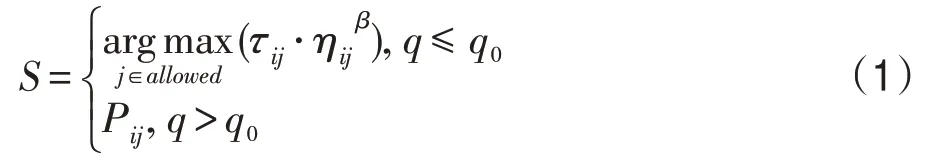
式中,τij表示节点i到节点j上的信息素;ηij代表了算法的启发式信息,其值为ηij=1/dij,其中dij为节点i到节点j的距离值,其表达式为allowed内部存储的是蚂蚁在该时刻未被访问的节点集合;β为启发式因子,其大小代表了启发式信息的影响程度;q0是一个固定的参数,其值范围在[0,1]之间,大小由人为设定;q是一个均匀分布在[0,1]之间的随机数;Pij为传统蚁群算法的概率状态表达式,即采用轮盘赌的方式构建路径,其表达式如式(2)所示:
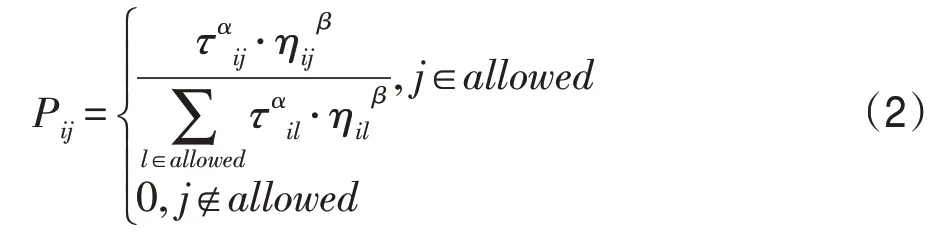
式中,α为信息启发因子,其他因子与式(1)作用相同。
1.1.2 信息素更新规则
(1)局部更新规则
当每只蚂蚁完成一次路径构建时其走过的边上信息素的浓度都要降低,此更新方式让后来的蚂蚁选择该条路径的可能性降低,进而增强算法的全局搜索能力,主要更新公式如式(3)所示:

式中,ξ为信息素的挥发率,其范围在0~1 之间;τ0为信息素初始浓度,经实验研究发现τ0=1/(n⋅ln)时算法性能较好,其中n为城市数,ln是由最近邻域法得到的路径值。
(2)全局信息素更新
在信息素的累加中,ACS与传统的AS相比改变了不同路径上的信息素累加程度,ACS 利用全局信息素更新机制,使得每次运行完后只有至今最优的路径上的信息素会增加,其更新机制如式(4)所示:
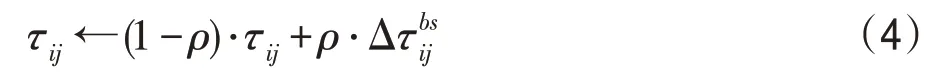
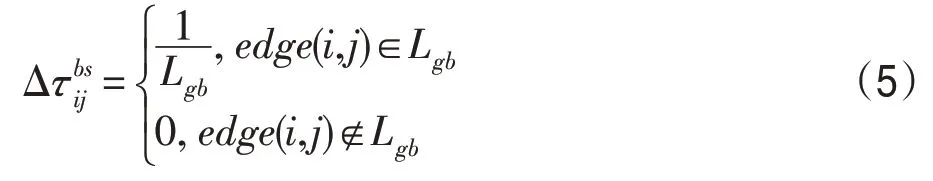
1.2 3-opt算子
对蚁群优化算法的其中一个改进就是引入局部搜索,其中k-opt 是较为常见的一种局部优化方式。例如3-opt 算子就是其中效果较好的一种方法,该方法通过对每次蚂蚁得到的最优路径进行打开重组,以此来提高解的精度,其主要流程为:
(1)首先得到本次算法的最优路径,即构成最短的哈密顿回路;
(2)任意选取该条路径的三个节点,依次进行打开重组,形成闭合回路;
(3)判断是否有新的更短路径产生,若有则替代原来的路径,若无则依旧选择原来的路径。
2 改进的蚁群算法(DHL-ACS)
2.1 动态分级机制
在动态分级机制中首先将蚁群划分为帝国蚁与殖民蚁,不同的蚁群执行不同的信息素更新,并在每次迭代中在帝国蚁与殖民蚁中选出一个国王蚁,并且只有国王蚁才能执行全局路径更新,如图1所示。
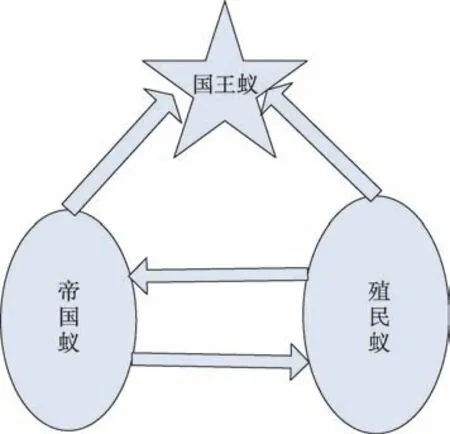
Fig.1 Dynamic hierarchical mechanism图1 动态分级机制
2.1.1 国力评价算子
在TSP 问题中每一只蚂蚁所得的路径长度即为该蚂蚁所得解,在算法运行中蚂蚁所得的解即为该蚂蚁的国力值,其国力评价算子如下式所示:

式中,lengthi为在每次迭代中每只蚂蚁所走的路径长度,lengthmin有两种选择,一种是至今最优路径的解,一种为迭代最优路径上得到的解。经实验表明在城市数小于100的情况下两种结果所差不多,但当城市数大于100 时选择至今最优解比迭代最优解的效果要好很多。
2.1.2 改进信息素更新规则
在蚁群算法中,最主要的是信息素更新机制,通过更新机制的作用使得每条边上的信息素差异不同,但传统蚁群算法中,信息素的差异化不太明显往往使得算法存在收敛速度慢、全局性能较差等缺点,故本文对ACS 中的局部更新策略进行改进,当每只蚂蚁构建完成路径后,将根据自身国力值选择相应的路径构建方式,进而实现不同路径上的信息素更新,具体如式(7)、式(8)所示:
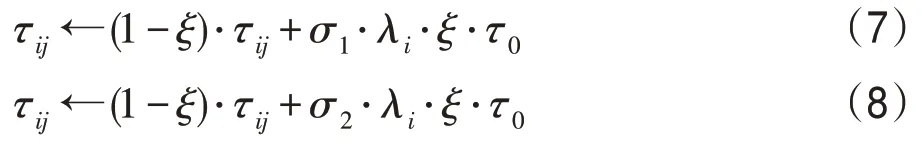
对于蚂蚁该如何选择对应的信息素更新机制,本文设定好阈值μ,当λ≥μ时蚁群为帝国蚁,帝国蚁负责提高解的精度,采用式(7)更新信息素;当λ<μ时蚁群为殖民蚁,殖民蚁负责对次优解的开发,提高解的多样性,采用式(8)更新机制。由此可知,阈值的选取至关重要,本文通过多次实验对比确定阈值,如图2所示(以kroA200为例),过高的阈值(如μ=0.9)会使得种群中殖民蚁数目较多,导致大量的无用搜索,进而影响算法收敛速度;若阈值设定较低(如μ=0.7),此时帝国蚁数目较多,使得算法的搜索路径过于集中而陷入局部最优,进而降低种群多样性,由实验结果可知将阈值设定为0.8较适宜。
在对局部信息素的调整中,将每只蚂蚁的自身国力值引入信息素更新中来,通过对阈值的选取使得在信息素的更新中,将不同蚂蚁所得的解作为判断其选择信息素更新机制的依据,得到较优解的蚂蚁执行较大权重系数,得到次优解的蚂蚁则执行较小权重系数,这样突出了优质解在整个算法运行中的主导作用。当算法陷入局部最优时,能够通过殖民蚁对路径的开发作用保证算法的多样性。
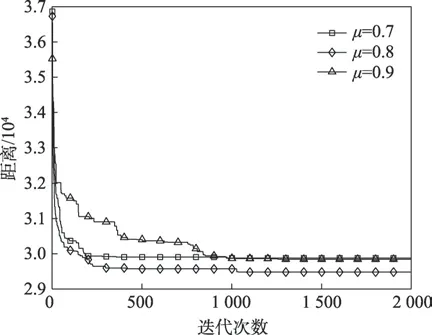
Fig.2 Comparison of experimental results with different thresholds图2 不同阈值实验结果对比
2.1.3 优质解的交换策略
在算法初始时所有蚂蚁完成路径构建后,利用国力评价算子对每只蚂蚁自身情况进行分级,其中优良解(国力值高于阈值)的蚁群为帝国蚁,较差解(国力值低于阈值)为殖民蚁。在下一代根据自身信息素更新机制进行路径构建,在每一代对所有蚂蚁完成求解后,对两种群中所得优质解进行交换,国力值高于阈值的殖民蚁升级为帝国蚁,而国力值低于阈值的帝国蚁则被降格为殖民蚁,这一行为体现了“优胜劣汰”的竞争原则,使得优质解的集合始终保持更新状态以实现求解精度更优,同时殖民蚁依据自身更新机制能够继续探索当前较优路径以外的其他路径,若探索到更优解则帮助算法跳出局部最优,增强了算法全局搜索能力。
2.2 学习机制
在学习机制中,如图3 所示,采用殖民蚁向帝国蚂蚁学习模式,在每次迭代划分种群后,位于帝国中的蚂蚁根据自身国力值获取相应的殖民蚁,在殖民蚁中通过对比与其所属帝国蚁的解路径得到二者的公共路径,并相应地增加公共路径上的信息素量,进而达到对公共路径奖励的作用。
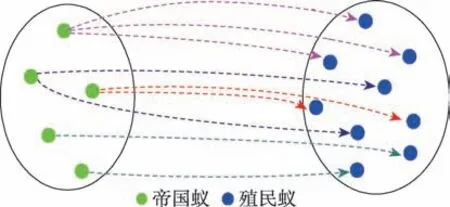
Fig.3 Learning mechanism图3 学习机制
2.2.1 分配殖民蚁
通过上节划分得到不同蚁群,并根据每只蚂蚁的国力值从大到小进行排序,设蚂蚁总数M个,帝国蚁数目为Nim,其余Nco个蚂蚁为殖民蚁,其中Nco=M-Nim,则每个帝国蚁依据下式分配得到殖民蚁:
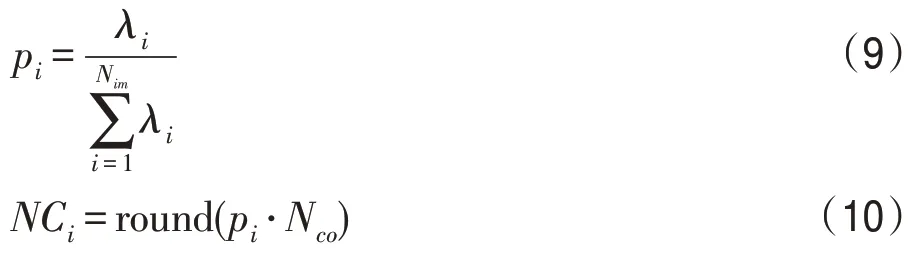
为更合理地分配蚁群,首先采用式(9)对帝国蚁的国力值进行标准化,其中pi为第i个帝国蚁的标准国力值,NCi为第i个帝国蚁分配到的殖民蚁数量,round函数为四舍五入取整。
2.2.2 种间学习
在完成蚁群分配后,在每次迭代中帝国蚁对其附属的殖民蚁进行同化操作,设第k只帝国蚁所分配得到殖民蚁数为n个,则第t次迭代中第k个帝国蚁与其所属殖民蚁的公共解路径为:

第k只帝国蚁对其殖民蚁的同化作用可表示为额外奖励公共路径上的信息素,如下式所示:

故殖民蚁中公共路径的信息素更新为:
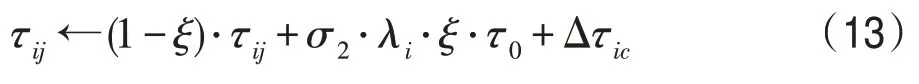
由上述同化过程可知,对于公共路径的信息素奖励程度不仅取决于帝国蚁自身国力值,同时也受城市数目与迭代次数影响,并且每只帝国蚁群体中都会得到相应的公共路径。当一条路径被蚁群共同选择时,可以认为该路径为最优路径的一部分或者在其附近存在最优路径。由式(12)可知在算法前期奖励共同路径的信息素较多,增大蚂蚁选择公共路径的概率,避免其他无用搜索,提高收敛速度,后期随着迭代次数的增加奖励逐渐减少,保证算法后期的多样性。
2.3 反馈算子
ACS中全局信息素更新使得算法能够更快地收敛,但易使算法停滞陷入局部最优,故本文中对国王蚁的全局信息素更新的改进为:
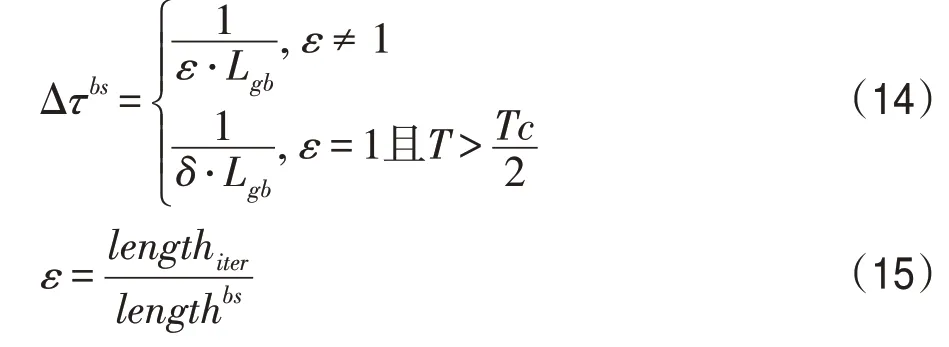
式中,ε与δ为全局更新的反馈系数,T为当前迭代数,Tc为最大迭代数,lengthiter为本次迭代中得到的最短路径,lengthbs为在本次迭代前所得到的全局最短路径。当lengthiter
当算法运行到中后期时,信息素的累加会使得大多数蚂蚁选择的路径过于同质化,进而易陷入局域最优,数值上表现出来的情况为长期的lengthiter=lengthbs,即ε=1。为应对此情况,本文引入反馈系数δ来进一步惩罚当前最优路径,其中设定δ>1,则Δτbs减小进而缩小当前最优路径与其他子路径上的信息素量,增强算法跳出局部最优的能力;但若设置过大,将会使得蚁群完全避开当前最优路径,而通常当前最优路径的部分路径也会是全局路径的一部分,此时将导致算法进行大量无用搜索,出现停滞现象。δ的设置情况如图4 所示(kroA100、kroB200 为例),整体来看,采取惩罚操作(如δ取1.5、2.0)的寻优性能较未采取惩罚操作(δ=1.0)的寻优能力均有所提升。而δ设置较高时(如δ=5.0),算法易出现停滞现象,其中对于中小规模的城市(如kroA100),δ取1.5 时性能较好;但随着城市规模增大,每次迭代中未选择的次优路径数目也增多,此时让周围路径以更大的概率被选择到,则需更快地缩短二者之间的信息素差距,才能让选择范围更广,故应将δ设置较大些。由图可知,对于大规模城市(如kroB200),取δ=2.0 效果较好。
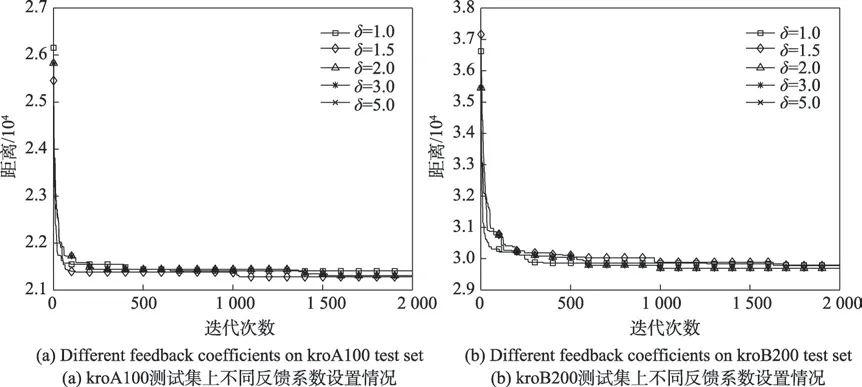
Fig.4 Comparison of experimental results with different feedback coefficients图4 不同反馈系数实验结果对比
2.4 DHL-ACS算法流程
本文改进算法(DHL-ACS)的算法流程如下所示:
算法1DHL-ACS算法框架
DHL-ACS Algorithm for TSP


2.5 DHL-ACS算法复杂度分析
从算法1 可知,在求解过程中算法可分为两部分,其中第一代蚂蚁依据ACS进行路径构建,故算法复杂度为O(1 ⋅m⋅(n-1)),从第二代开始蚂蚁进行身份划分,并且两类蚁群相互独立,则此阶段的DHLACS 算法复杂度为O((nc-1)⋅m1⋅(n-1)+(nc-1)⋅m2⋅(n-1))。式中m1与m2分别为每次迭代中帝国蚁与殖民蚁的数量,蚂蚁总数为m,故DHL-ACS 总体复杂度为O(m⋅(n-1)+(nc-1)⋅m1⋅(n-1)+(nc-1)⋅m2⋅(n-1)),即O(nc⋅m⋅n),与传统ACS 的算法复杂度相等,故DHL-ACS并没有增加整体算法的时间复杂度。
3 实验测试分析
本文基于Windows10 系统,Matlab2016b 版本的仿真环境对算法进行性能测试,选取国际标准TSP数据库中多组不同数据集进行实验分析。
3.1 实验参数设置
本文在ACS[5]的基础上,通过多次实验,测试了不同参数对算法性能的敏感性作用。统计对比其结果发现,公共参数设置如表1 所示效果更好,且对三种对比算法实验结果分析时,采用相同的参数设置也更为合理,其中m为蚂蚁数,μ为阈值,Tc为最大迭代次数;表2中δ为反馈系数,σ1、σ2分别为帝国蚁与殖民蚁的信息素更新权重系数,其作用为调控路径上的信息素浓度,增加种群多样性。为应对算法在求解大规模TSP问题时多样性较差等问题,本文通过调整权重系数将不同路径的信息素差距拉大,以实现对不同路径的区分作用,进而增加算法多样性。若将其设为一致,则在大规模TSP问题中算法无法跳出局部最优,故本文根据城市规模设置不同的权重参数。表3、表4 中算法误差率=(算法最优解−测试集最优解)/测试集最优解×100%[17]。

Table 1 Common parameters setting of DHL-ACS表1 DHL-ACS的公共参数设置
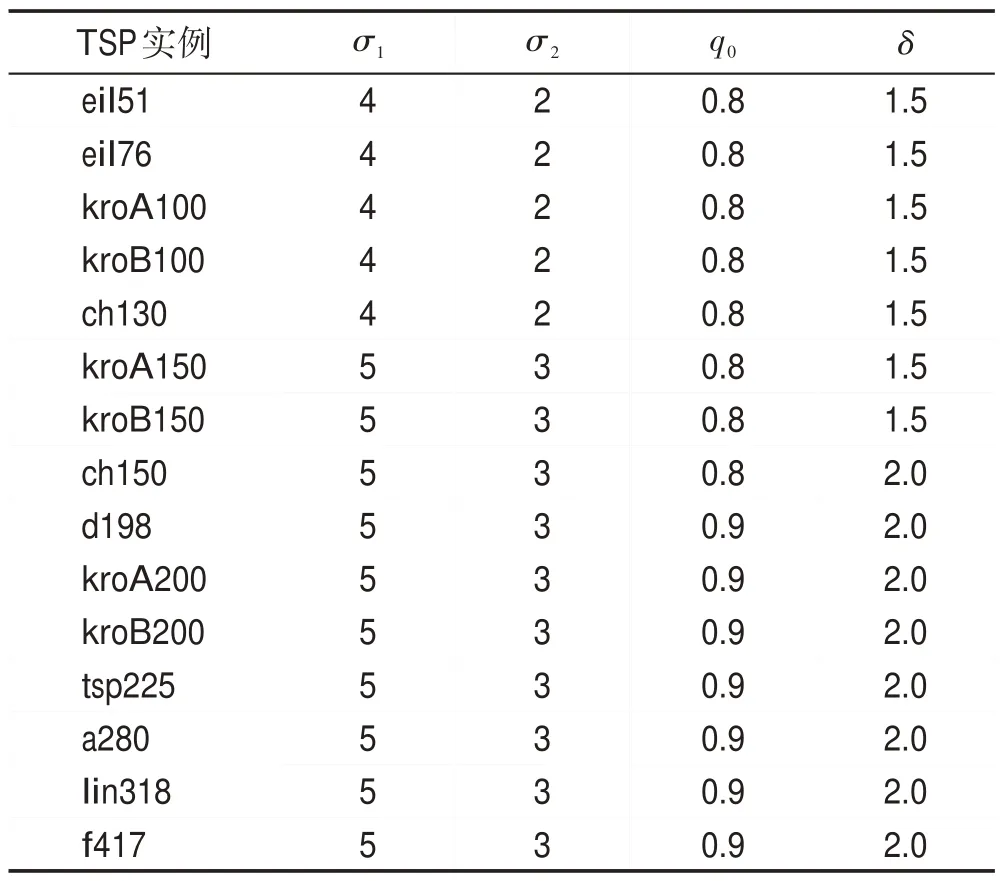
Table 2 Parameters setting in each test set of DHL-ACS表2 DHL-ACS在各个测试集中的参数设置
3.2 改进算法(DHL-ACS)性能分析
3.2.1 DHL-ACS策略性能分析
本小节主要验证上文所提出的DHL-ACS算法性能,由于学习机制是以动态分级机制为前提,故将对比ACS分别在加入动态分级机制、动态分级+学习机制及原始ACS算法的优化结果,其测试结果如表3所示。
表3为ACS加入动态分级机制、动态分级+学习机制的实验统计结果(kroB100、kroA200、a280 测试集,算法运行15 次),能够看出算法加入动态分级机制、动态分级+学习机制的求解质量与收敛速度均得到了改善,并且可以明显看出ACS加入动态分级+学习机制比单纯加入动态分级机制更具优越性。以kroA200 为例,加入动态分级+学习机制的算法不仅在收敛速度上优于对比算法,并且在求解过程中找到了标准最优解。其中标准差代表了算法的稳定性,通过其比较也显示了本文算法有较好的稳定性,故改进算法能够较好地平衡算法全局搜索能力和收敛速度之间的关系。
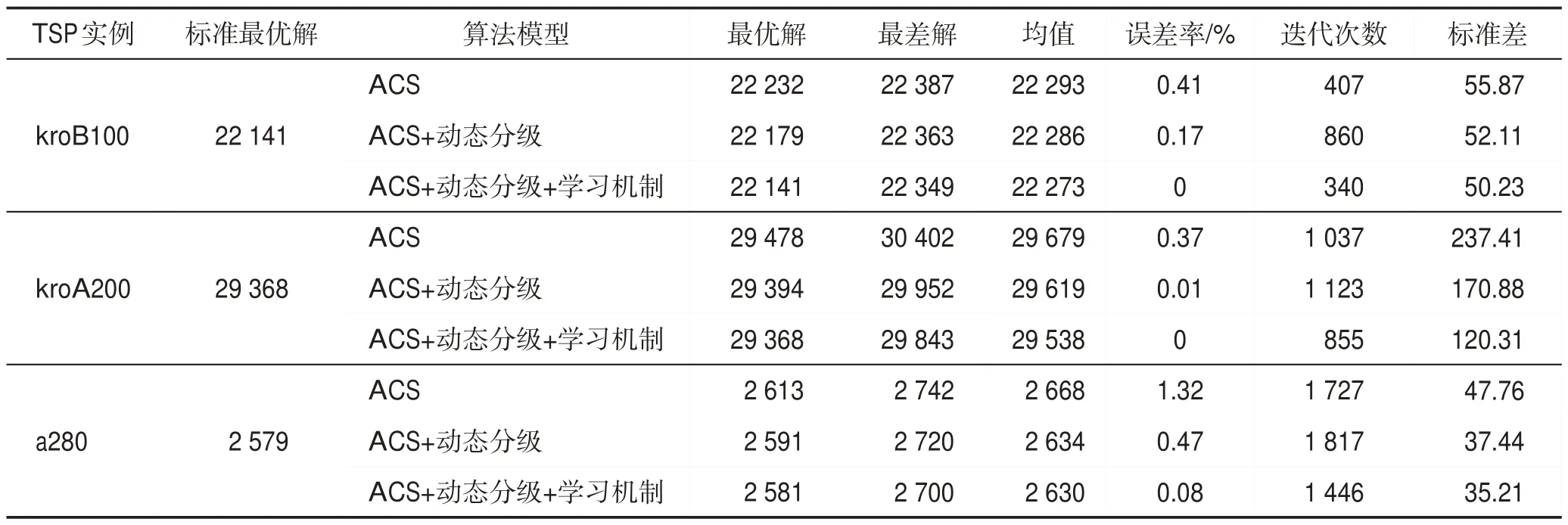
Table 3 Optimization results of ACS with different models表3 ACS加入不同模型的优化结果
3.2.2 DHL-ACS个体分布情况分析
为研究DHL-ACS的蚁群分布情况,本文以eil51为例进行测试,结果如图5 所示,图中第一列为帝国蚁数量,第二列为殖民蚁数量,第三、四列分别为DHL-ACS与ACS在不同时刻的标准差,横轴为迭代次数。由图可得,在200~500 代,帝国蚁与殖民蚁的数目差距不明显,且DHL-ACS 标准差略高于ACS,这是由于算法前期属于探索阶段,所求得的解质量都不太高,从而导致两类蚁群的整体求解结果差距不明显;在500~1 000 代时,DHL-ACS 的标准差开始减少并与ACS 持平,而此时的两类蚁群数目差距开始拉大,这表明算法在慢慢收敛,不同蚁群的求解结果逐渐分化,执行较大权重系数的帝国蚁在算法中起主导作用,并且由于学习机制的作用使得蚁群较为集中地选择目前的优质路径,加快了算法收敛速度,从而使得种群多样性有所下降;但在1 000~1 500代,帝国蚁逐渐减少,殖民蚁越来越多,此时学习机制的作用逐渐减弱,殖民蚁执行探索功能,使得更多的次优路径能够被搜索到,进而提高了DHL-ACS的多样性;在1 500~2 000 代,两类蚁群数目趋于稳定,殖民蚁搜索路径的同时反馈算子的引入降低了当前最优路径的信息素浓度,进一步提升了其找寻新路径的概率,增强算法跳出局部最优的能力,而DHLACS的标准差结果也说明了在后期该算法的多样性并未下降。总体而言,DHL-ACS 在加快收敛速度的同时能够保证种群多样性,进而平衡了二者之间的矛盾。
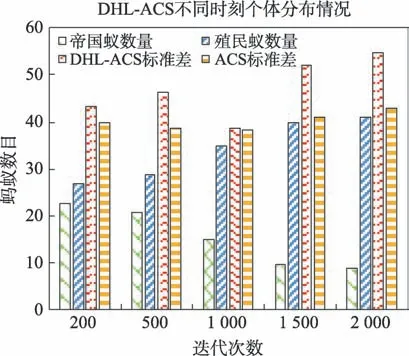
Fig.5 Ants distribution at different time图5 不同时期蚂蚁分布图
3.3 与传统算法对比分析
本节将改进算法DHL-ACS与ACS及ACS+3opt算法进行实验结果对比。测试集中选取15 个城市集,每个城市集运行15次,每轮进行2 000次迭代,实验结果如表4所示。
由表4 可知,对于中小规模城市如eil51、eil76 及kroA100 城市集,各类算法都能找到标准最优解,对于kroB100 城市集,传统蚁群算法未能找到最优解,而DHL-ACS依旧能找到标准解。总体而言,在中小规模城市中三种算法找寻解的精度相差并不大,但DHL-ACS 算法在收敛速度上明显快于对比算法,其中eil51 仅用了30 代便找到了标准最优解,eil76 在160代就实现了最优收敛,kroA100、kroB100则在368代及340 代收敛于标准最优解,均快于对比算法,这是由于在学习机制中,殖民蚁的学习过程突显了较优路径的主导作用,提高了算法的收敛速度。由此可以看出,对于中小规模城市DHL-ACS与传统ACS及ACS+3opt 所得解的精度相差不明显,但DHL-ACS能够更快地收敛,其收敛速度均优于其他算法。
在中大规模城市中,本文选取了ch130、kroA150、kroB150、ch150、d198、kroA200 及kroB200 等7 个城市数据集。DHL-ACS 的解均能很好地控制在1%以下,其中在kroA200 城市集上仍旧能找到最优解,而kroA150、kroB200的误差也控制在了0.1%以内,并且无论是平均解还是最差解都要优于ACS 及ACS+3opt。
对于大规模的城市集,本文选取了tsp225、a280、lin318 以及f417 等4 个城市集。在应对大规模城市中传统蚁群算法已经不能很好地实现解的优化,特别是对于ACS已出现失真现象,DHL-ACS虽然未能找到标准最优解,但均能使误差保持在1%以内,并且对于a280,误差达到0.08%,很接近最优解,并且其他城市解的质量同样优于对比算法。综上表明,改进的DHL-ACS 算法性能要优于传统的蚁群算法。各个城市的具体路径图如图6所示,下面将从收敛速度与多样性上分析DHL-ACS 与ACS、ACS+3opt 的差异情况。
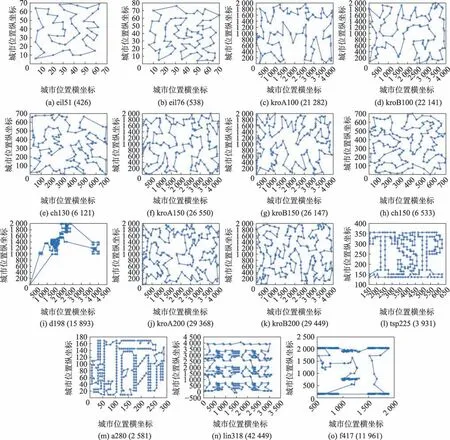
Fig.6 Optimal path/city set(shortest distance)图6 最优路径/城市集(最短距离)
3.3.1 算法收敛性与多样性对比分析
为更加全面地分析改进算法(DHL-ACS)的性能,本小节从收敛速度与多样性两方面进行研究讨论。鉴于小城市的数据集中传统的蚁群算法所得解的质量都较好,本文将分析DHL-ACS与ACS、ACS+3opt在中大规模及大规模城市集的算法性能。对于中大规模城市,本文选取kroA150、d198、kroB200等3个城市集,大规模城市集选取a280和f417两个数据集。
图7(a)、(b)代表kroA150 的多样性,在算法前期,DHL-ACS 与ACS 的多样性波动性差距不明显,但是到了中后期,DHL-ACS的标准差较ACS呈现出上升的态势,这表明DHL-ACS在迭代中不断优化路径值,同时DHL-ACS 的多样性波动逐渐加大,而ACS 的多样性波动性渐渐缩小,这也反映出传统蚁群算法易陷入局部最优的不足。图8(a)、(b)表示d198城市集的多样性,图9(a)、(b)代表了kroB200测试集的多样性。从图中可得,DHL-ACS 的多样性波动性均比ACS 的多样性要大,并且由于殖民蚁的开发作用,使得DHL-ACS在算法后期也能够保持较好的多样性。图7(c)、图8(c)以及图9(c)分别代表数据集kroA150、d198 和kroB200 对应不同算法的收敛曲线。kroA150 中ACS+3opt 能够在500 代左右收敛到最优解,ACS 的收敛速度也较DHL-ACS 快,但其很快陷入了局域解中,而DHL-ACS的收敛速度虽未快于其他算法,却能够提高解的精度。d198、kroB200中DHL-ACS 收敛速度均要优于ACS 与ACS+3opt,其中d198 测试集中在算法的1 800 代后还能跳出局域解,表明了在国王蚁的更新方式中引入反馈算子的惩罚作用,其更快地缩小了当前最优路径与子路径的信息素差距,使得殖民蚁有更大的概率选择未被开发的路径,进而增强算法跳出局部最优的能力。
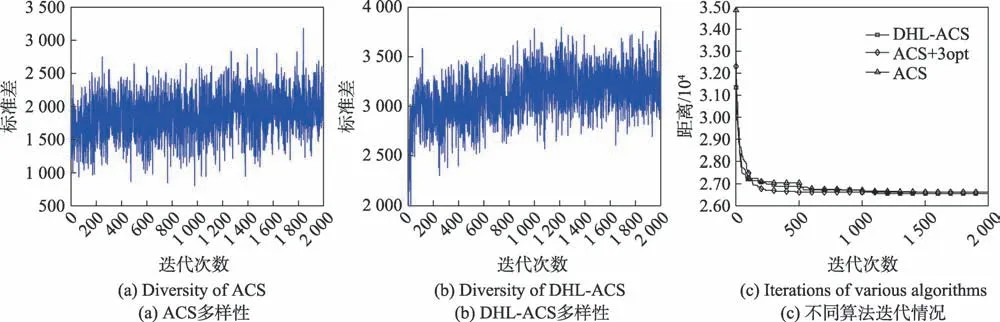
Fig.7 Comparative analysis of kroA150 test set图7 kroA150测试集对比分析
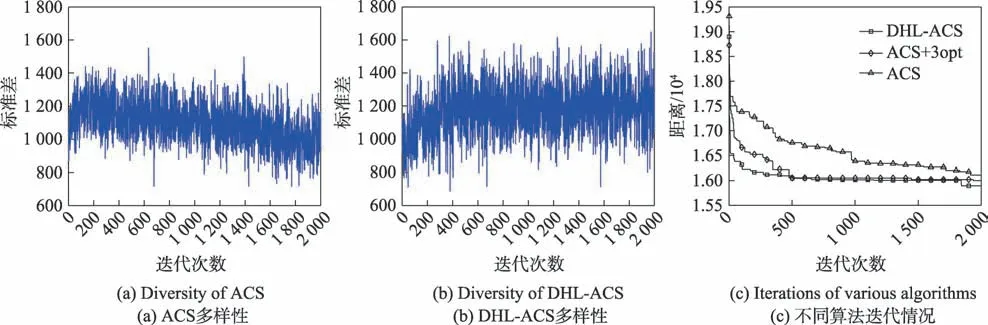
Fig.8 Comparative analysis of d198 test set图8 d198测试集对比分析
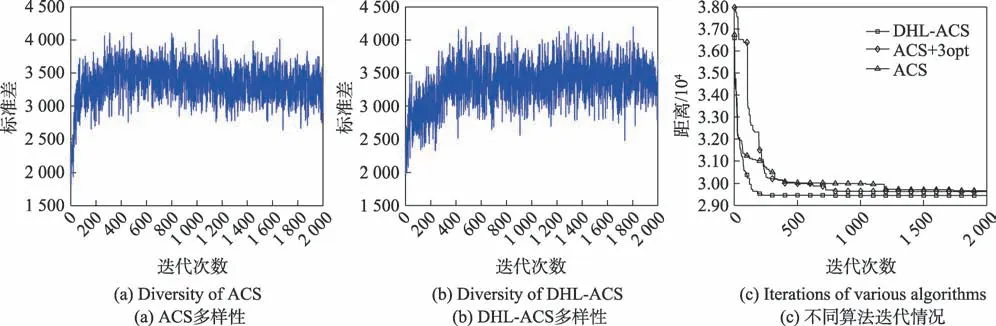
Fig.9 Comparative analysis of kroB200 test set图9 kroB200测试集对比分析
为进一步分析大规模城市问题,本文选取a280(图10(a)所示)、f417(图10(b)所示)进行对比。由图10可以看出,对于大规模城市,ACS在收敛速度方面尚需进一步优化,并且对于解的质量也出现较大误差;ACS+3opt方面能够稍微改善解的精度,所得解的质量比ACS要高,但提升程度不明显,同时收敛速度不如ACS;而综合表4 DHL-ACS 对于不同的数据集其误差率均能保证在1%,有效改善了解的精度;在收敛速度方面,由图10知DHL-ACS的收敛曲线总体上在ACS与ACS+3opt曲线下方,说明了收敛速度较对比算法要好。在f417 测试集中,DHL-ACS在算法1 800 代后也能进一步优化解,表明了改进算法能够较好地跳出局部最优。综上所述,DHL-ACS 能够很好地平衡解的精度与收敛速度。
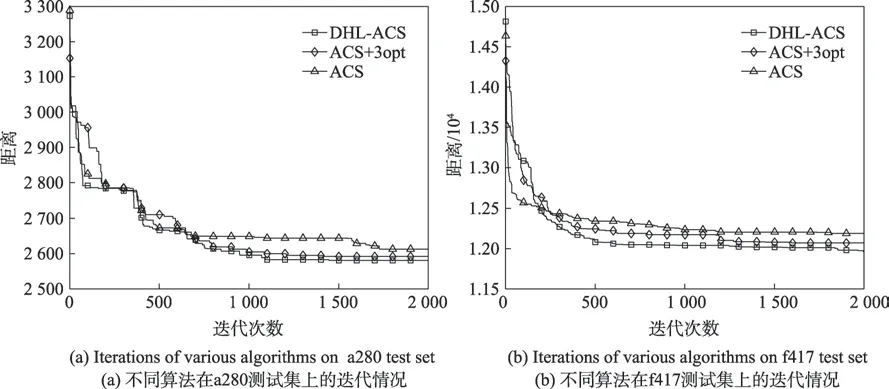
Fig.10 Comparative analysis of large scale test sets图10 大规模测试集对比分析
3.3.2 稳定性分析
本文利用标准差表示算法稳定性,图11 给出了测试的15个城市集的标准差。从图中可得本文算法的标准差均较对比算法的要小,并且在中大规模城市集中更加明显,这体现了DHL-ACS 比ACS 及ACS+3opt更加稳定,故综合表2表明改进算法整体解的精度更高且稳定性更好。
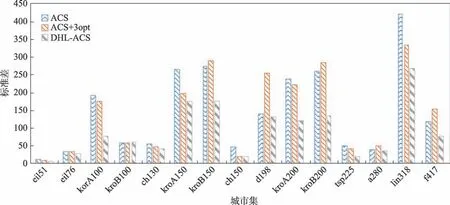
Fig.11 Comparison of algorithm stability图11 算法稳定性对比
3.4 与其他改进算法对比
本文改进算法(DHL-ACS)还与其他改进算法进行比较,结果如表5 所示。其中,改进粒子群算法(IMRGHPSO)数据来自于文献[2],一种求解旅行商问题的新型帝国竞争算法(ICA)数据来源于文献[3],一种面向对象的多角色蚁群算法及其TSP 问题求解(OMACO)来源于文献[17]。从表5中可以看出,DHLACS算法所得解的质量要明显优于对比算法。
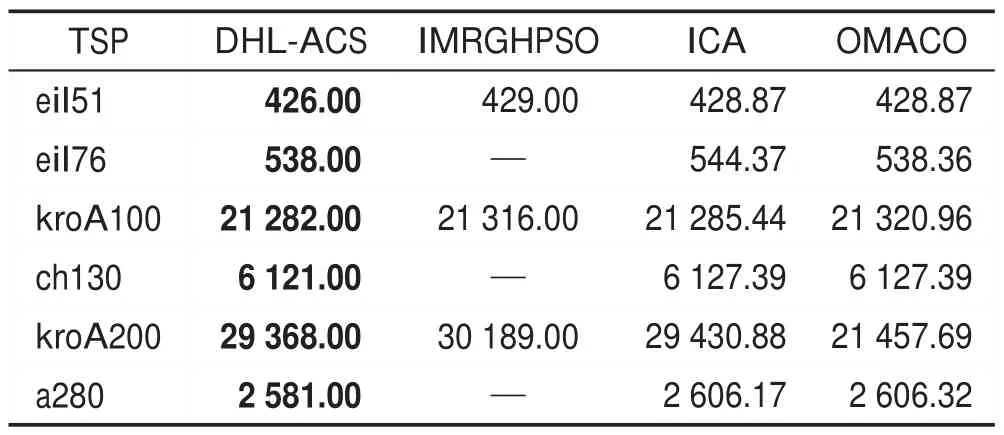
Table 5 Comparison of DHL-ACS with other algorithms on TSP instances表5 DHL-ACS与其他算法在TSP案例上的比较
4 结束语
本文提出了融合奖惩学习策略的动态分级蚁群算法(DHL-ACS),动态调整帝国蚁与殖民蚁的数量,并通过二者交换优质解的方式提高解的精度。同时在学习策略中,将帝国蚁分配得到相应的殖民蚁,通过奖励二者的共同路径来实现双方的合作作用,进而加快了算法的收敛速度。当算法出现停滞时,引入反馈算子,惩罚当前较高信息素的国王蚁,缩短其与次优路径的信息素差距,有效增强了算法跳出局部最优的能力。虽然在实验测试中对比其他算法本文解的效果得到了较大的提升,但在大规模城市集中算法的收敛速度仍待进一步改善,故下一步将尝试改进多种群蚁群算法,以提高算法在应对大规模TSP测试集上的求解能力。
