
基于联合损失和恒等映射的动态人脸识别
2021-09-10 07:16刘成攀
传感器与微系统 2021年9期
刘成攀, 吴 斌, 杨 壮
(1.西南科技大学 信息工程学院,四川 绵阳 621010;2.特殊环境机器人技术四川省重点实验室,四川 绵阳 621010)
0 引 言
视频动态人脸识别不需要识别对象配合,具有体验更好、准确率更高、响应速度更快、实时反馈等特点。但同时,由于它是非限定情况下的人脸识别,外界非可控的复杂干扰因素会造成人脸识别精准度急剧下降,不能适应实际条件下的任务需求。
近年来,涌现出许多基于深度学习的人脸识别方法,而损失函数是深度学习神经网络中的重要部分,对其的设计与优化也一直是研究热点。目前使用最为广泛的损失函数是SoftMax Loss,其表达简洁,没有其他超参数,最早在DeepID1中使用,而后在DeepFace等其他方法中也继续沿用。SoftMax Loss对提取的特征分别映射到区间内,根据所得的概率完成图像分类任务[1]。但在人脸识别任务,需要计算未知类别样本的相似度,此时仅仅保证已知类别分类正确是不够的。为了更好地泛化性能,还需要诸如类内样本差异小和类间样本差异大这样的良好性质,而这些并不是SoftMax Loss的直接优化目标。
鉴于SoftMax的局限性,有必要针对它进行优化约束类内距离,扩大类间距离。为了加强网络模型对特征的识别度,ECCV 2016上提出的中心损失(centre Loss)[2],在结合SoftMax损失和中心损失后,类内紧凑性显著增强,但是仅仅使用SoftMax损失作为类间约束是不够的,因为它只是鼓励特征的可分离性。因此,Deng J等人提出边际损失Marginal Loss与SoftMax Loss联合监督的方式[3]。
本文受SoftMax Loss,Center Loss以及Marginal Loss启发,提出了一种联合损失(Joint Loss)函数,并且在网络模型中加入恒等映射模块[4],实验表明算法更具有鲁棒性。
1 算法原理
1.1 神经网络结构
将Resnet34[5]作为基础网络进行优化。去掉第一个卷积层后的最大池化层,减少池化造成的位置信息缺失。缩小第一个卷积层的卷积核尺寸,由 7×7 变为 3×3,步进由2变为1,缩小卷积核可以获取更多人脸特征信息。改进后的Resnent34_new结构如图1,其中,卷积核大小为3×3,通道数为64,步长为1。
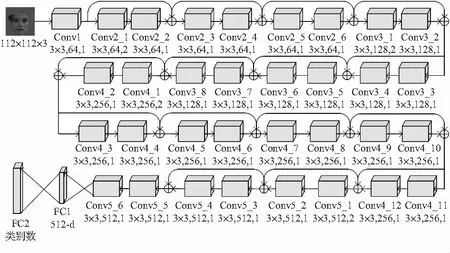
图1 Resnet34_new神经网络结构
改进所使用的残差(residual)模块,为使输出分布稳定进而能够在较大学习率下加快收敛,在模块的输入处增加了一个批标准化层(batch normalization)[6]如图2。
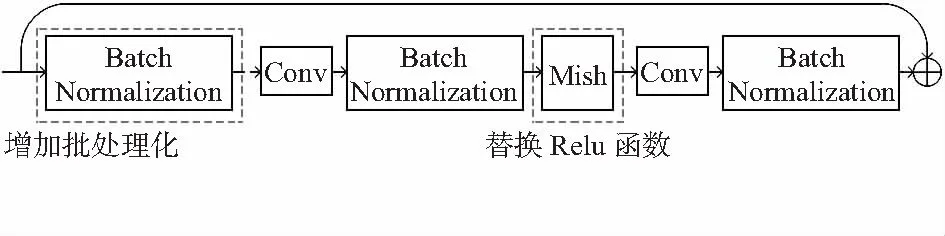
图2 改进的残差模块
1.2 联合损失函数
结合三种损失函数特点,Center Loss用于加强类内距,SoftMax Loss和Joint Loss用于改进类间的分离度,具体来说SoftMax负责保证分类的正确率,而Joint Loss优化类间距。整个损失公式如下
L=LS+αLC+βLJ
(1)
式中α和β为调整Center Loss和Joint Loss的超参数。
Joint Loss公式如下
(2)
通过Center Loss得到的类中心位置,Joint Loss再筛选所有基于阈值的类中心对,对于距离小于阈值的类中心对,会相应地加入惩罚因子到损失值中。其中,K是一个批次的类数目,ci和cj分别为第i类和第j类的中心,M代表指定的最小边距。在每一个训练批次里,Center Loss根据下式更新类中心
(3)
(4)
式中γ为学习率,t为迭代次数,δ为一个条件函数,如果条件满足则δ=1,如果条件不满足则δ=0。
在神经网络中,通过联合的损失函数学习步骤如下:输入数据为输入训练样本{fi},初始化的卷积层参数θC,最后的全连接层参数W,初始化的n类中心{cj|j=1,2,3,…,n-1,n},学习率μt,超参数α和β,类中心学习率γ和迭代次数t←1。输出为参数θC。对所有样本训练时会循环以下步骤:
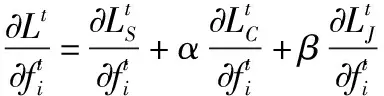

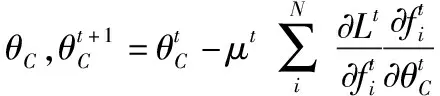
6)t←t+1。
1.3 恒等映射模块
侧脸和正脸之间存在一个映射,并且它们在人脸表示特征空间中的差异能够用恒等映射联系起来。通过侧脸的特征获取映射后的正脸特征,从而提高神经网络在侧脸的识别效果。假定正面人脸的数据为xf,侧面人脸的数据为xp,把卷积神经网络看作是一个函数φ(x),要寻找一个映射函数Mg,使得Mgφ(xp)≈φ(xf)。如式(5),式中γ(xp)∈[0,1],类似于一个门控机制,如果说图片是正脸,则γ(x)=0
φ(gXp)=Mgφ(Xp)=φ(Xp)+γ(Xp)R(φ(Xp))
≈φ(Xf)
(5)
如图3,在原始网络的特征向量输出后,加上了残差恒等映射的分支,对原始的特征表示进行映射,得到最后的表示。残差恒等分支分为两个部分,一个是残差分支,一个是头部旋转估计分支。
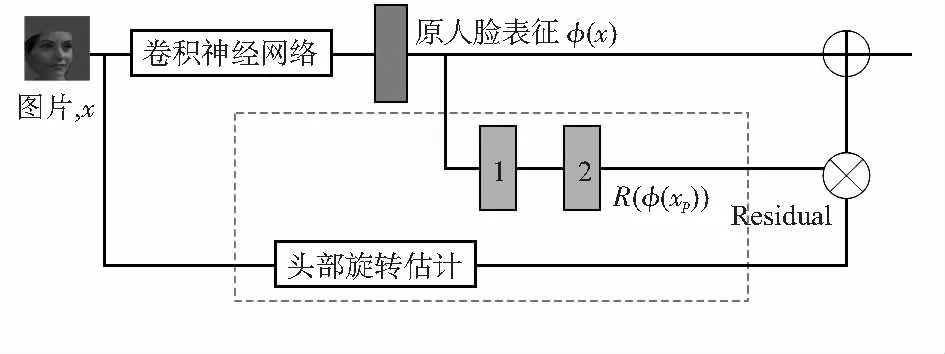
图3 恒等映射模块
残差分支为上图Residual分支,用来产生式中的R(φ(X)),其中方块1,2为用Mish激活函数的全连接层,这个分支是与主干网络分开训练的,训练的目的是为了减少侧脸与其匹配的正脸的欧氏距离。具体如式(6),ΘR表示R的参数
(6)
使用头部旋转估计器来计算上式中的Y(x),即当前图片相对于正脸的偏离角度。首先用人脸标准对齐得到人脸关键点,然后使用EPnP等算法计算人脸旋转的角度,得到旋转的角度后,使用函数σ(4/π)y-1)来把正的角度值映射到0~1之间,σ是Sigmoid函数,如果人脸转的角度超过45°,这个γ(x)的置信度会迅速达到1。
选择先端对端训练再重新训练恒等映射模块的方法,先共同训练恒等映射模块和卷积神经网络,再使用正脸—侧脸对训练恒等映射模块。
2 实验与结果分析
2.1 实验参数设置
采用训练步数学习率逐渐衰减的学习策略,在初始时学习率设置为0.1,分别在 40 000步和60 000步将学习率调整为原有的0.1倍,批量大小(batch-size)设置为128,使用Adam[7]来作为网络优化方法。对损失函数进行L2正则化处理防止过拟合[8],如式(7)
(7)
式中J0为原始损失函数,λ为权重衰减系数(设置λ为0.000 2)
2.2 损失函数超参数的选取
在实验中,通过不断尝试去寻找较为合适的参数以达到网络模型的最佳效果,具体方法为控制变量法。例如先将α设置为8,β设置为6,M分别取0,50,100,150,200,250,300,350,400,训练后在LFW上作人脸验证,其准确率如表1。

表1 α设置为8,β设置为6,M不同取值下准确率变化
如表1可以看出,在M设置为250时比其他数值设置能得到更高准确率。再将M设置为250,α设置为8,将β分别取1到10,训练后LFW上作人脸验证,对比发现β设置为6时,比其他数值设置能得到更高的准确率。最后将M设置为250,β设置为6,将α分别取1到10,训练后在LFW上作人脸验证,寻找α的最佳设置。
通过实验,发现α设置为8,β设置为6,M设置为250,能较好发挥网络模型的性能。
2.3 实验结果与分析
首先选择LFW,YTF,SLLFW数据集作为人脸验证实验数据集。LFW为非限定条件下的人脸数据集,共13 000多张人脸图片。随机选取其中图像,组成6 000对人脸对,其中正、负样本各占50 %。YTF数据集共1 595个身份,每人大概2个视频。从中随机选取5 000对视频,共计分为10个部分,每部分都包含同标签人的视频对和不同标签人的视频对,均为250个。SLLFW使用与LFW相同的正面人脸对进行测试。但在SLLFW中,3 000个长相相似的人脸对被特意挑选出来,以取代LFW的随机负面人脸对比,给测试增加了难度。如表2给出了各种方法的实验结果。

表2 LFW,YTF,SLLFW数据集人脸验证准确率 %
从表2中可以看出,基于联合损失和恒等映射模块的神经网络在人脸验证实验中准确率最高,分别为99.53 %,95.63 %,96.67 %。在LFW,YTF,SLLFW数据集上,联合损失加上恒等映射模块的方法比SoftMax损失分别提升1.3 %,0.82 %,1.14 %,比Center损失分别提升1.2 %,0.32 %,0.35 %,比Marginal损失分别提升1.17 %,0.27 %,0.29 %,比只用联合损失分别提升0.87 %,0.12 %,0.24 %。
为进一步验证神经网络效果,按照MegaFace Challenge 1要求,MegaFace数据集作为干扰集,而FaceBook数据集作为测试集,进行实验。其中,MegaFace数据集包括100万张人脸,Facesrub数据集包含来自530个身份的10万图像。
实验的CMC曲线和ROC曲线如图4。不同方法在一百干扰下的验证率结果如表3。与其他方法相比,在识别和验证测试中,联合损失加上恒等映射的方法性能更好,进一步证明该方法的有效性。
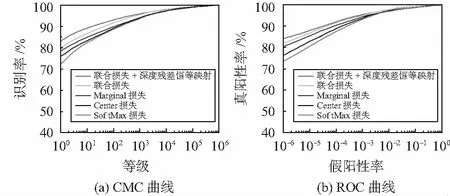
图4 实验的CMC曲线和ROC曲线
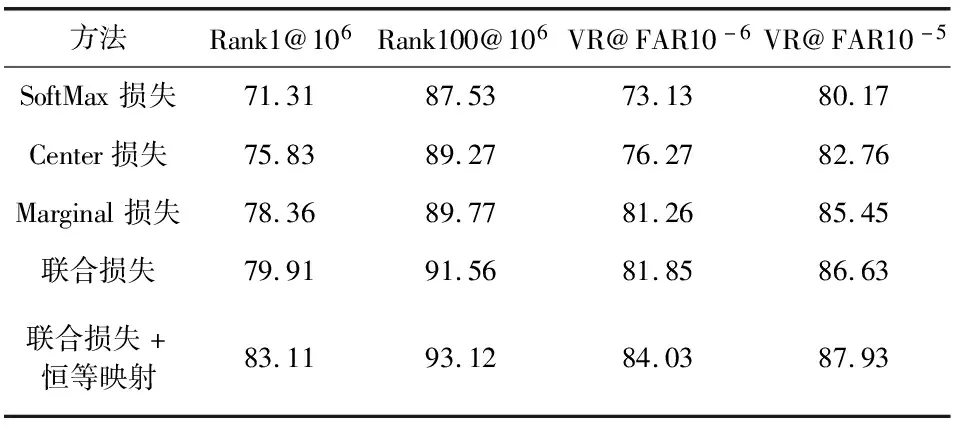
表3 在一百干扰下不同方法在MegaFace和FaceScrub数据集上的识别率与验证率 %
2.4 视频动态人脸识别系统
实验平台系统为Ubuntu18.04,GPU为i7—8700,GPU为RTX2060,内存为32 G,在平台上搭建视频动态人脸识别系统。视频读取帧,利用MTCNN检测人脸[9]并对齐,将每张人脸的特征向量和数据库里面的特征向量比对输出Label标签和相应的概率,再用跟踪算法Deep-Sort[10]进行后续的人脸跟踪。测试了5段视频,来验证在速度上是否能满足实际的需求,检测、跟踪、识别所花费的时间大概为原视频事件的2.5倍,速度大约为原来的0.4,在实际运行中,平均帧率也能够稳定在30 fps以上,肉眼无卡顿现象,能够满足实际的需求。
3 结 论
本文提出了基于联合损失和恒等映射的动态人脸识别算法。选择Resnet34为基线网络,通过卷积核改变等对网络进行优化,在同样的训练条件下,对本文算法在内的5种方法进行有效性评估。实验表明:基于改进的的联合损失函数加上深度残差恒等映射模块的人脸识别算法在5种方法中表现最好。并在实验平台上搭建了动态实时人脸识别系统,达到了预期的效果。
猜你喜欢
作文中学版(2022年1期)2022-04-14
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
动漫星空(2018年9期)2018-10-26
北京航空航天大学学报(2018年1期)2018-04-20
奇闻怪事(2014年5期)2014-05-13
